GaitSet: Regarding Gait as a Set for Cross-View Gait Recognition
作者:Hanqing Chao1,Yiwei He, Junping Zhang, JianFengFeng
AAAI 2019,复旦大学
上海计算机学院智能信息处理重点实验室;脑启发智能科学技术研究所

摘要
作为可以在远处识别的唯一生态特征,步态在预防犯罪、法医鉴定和社会安全等方面有着非常广泛的应用。为了实现步态识别,目前存在的主流方法有两种: 一是步态轮廓图:将步态信息合成一个模板,这种方法无法保留时间信息(帧与帧之间的变化特征)。二是步态序列:将步态信息作为一个序列(按顺序排好的),这种不必要的约束——按顺序排好,在步态识别中丢失了灵活性。在这一篇论文,我们提出了一种崭新的视角:将步态信息视作一个个由独立frame(单个视频中的一帧)组合而成的Set(一种集合)。我们提出了一种名为GaitSet的新网络,在Set中学习到提取特征信息的能力。基于Set的perspective(透明能力),我们的网络可以忽略frames的顺序,还可以非常自然的整合从不同视频中获取的frames(具有跨镜能力)。比如:不同的视角,不同的衣服/携带条件下拍摄的视频,只要是同一个人,在GaitSet看来都是属于同一个Set。
实验展示了在正常行走条件下,我们在仅仅使用GaitSet测试,在CASIA–B步态数据集上达到了95.0%的平均准确率,在OU–MVLP步态数据集上达到了87.1%的准确率。这些结果代表着最先进的步态识别准确率。在多种复杂的情节下,我们的模型表现出了一个显著的鲁棒性。它分别在携带背包和穿着大衣的行走条件下载CASIA–B步态数据集分别实现了87.2%和70.4%的准确率。这些结果相较于当下最先进的方法都有一个大幅度的提升。我们所提出的方法也可以以较小的测试样本中获得令人满意的准确率,例如,在CASIA-B上只使用任意7帧的frame,而忽略其他帧数frames,准确率依旧达到了82.5%。源代码已发布在GaitSet源代码。
1 导言
与人脸、指纹和虹膜等其他生物特征不同,步态是一种独特的生物特征,可以在远距离识别,无需受试者的配合,具有非受控性。因此,它在预防犯罪、法医鉴定和社会保障方面有着广泛的应用。
但是,步态识别很容易受到外部因素的影响。例如:受试者的行走速度、穿衣和携带物品。GaitSet模型在受干扰的情况下保留空间和时间信息的能力比步态模板方法要好。这将会在实验 Sec.4.3.Third被证明。一个结构叫做Horizontal Pyramid Mapping(水平金字塔映射) 被使用将Set级别的特征映射到一个更具有区别力的空间去获得最终的表示。我们提出来的方法优点,总结出来有:
• 灵活 我们的模型非常灵活,因为除了轮廓的大小之外,对模型的输入没有任何约束。这意味着Input可以包含在不同视角和不同行走条件下拍摄的任意数量的非连续剪影。相关实验如第4.4节所示。
• 快速 我们的模型直接学习从Set中提取步态特征的能力,而不是测量一对步态之间的相似性模板或序列。因此,每个样本只需要计算一次,然后可以通过计算两两不同样本之间的一对步态特征之间的欧几里得距离来完成识别。
• 有效 我们的模型在CASIA-B(Yu,Tan and Tan 2006)和OUMVLP(Takemura et al.2018b)两个数据集上的表现有着显著的提高,在不同的视角和不同的行走条件下都展现了超强的鲁棒性,还在大数据上有很高的泛化能力。
2 相关工作
这部分我们会简要介绍步态识别和基于序列的深度学习方法的回顾。
2.1 步态识别
步态识别可以分为基于模板和基于序列两种。而这两种方式皆有两大步骤:步态采集与步态判别。
对于基于模板类的步态采集步骤:
① 首先通过背景减法获得每个帧的人体轮廓:
②剔除无关背景,将图中的人影单个裁剪出来:
③:然后将排列好的轮廓在帧级进行操作以生成步态模板。
对于基于模板类的判别方式:
① 他们通过机器学习方法提取步态的表示,例如典型相关分析(CCA),线性判别分析(LDA)和深度学习。
② 它们通过欧几里德距离或一些度量学习方法来测量表示对(表示对就是输入的图像序列和训练过程中已经存储的一组图像序列)之间的相似性。
③ 最后,他们通过某些分类器,例如,最近邻居分类器,来为(输入的待检测)模板分配标签。
基于模板的步态识别虽然能达到一定预期的效果,但是这种办法无法提取步态信息中的时间特征,难以应付复杂的场景,
对于基于序列类的数据预处理步骤(步态采集)则比较简单:
和基于模板类的数据预处理步骤( 步态采集)一样,但是去掉最后一步合并——然后将排列好的轮廓在帧级进行操作以生成步态模板。需要的是去掉最后一步所得裁剪好的一个序列的连续步态轮廓图。
对于基于序列类的判别方式则有很多种,按照基于提取时间信息的方式,可以将它们分类为基于LSTM的方法和基于3D CNN的方法,简单来讲,他们都是通过神经网络自动提取特征,最后把提取到的特征两两进行比对,选择最相近的两对作为判定结果。这些方法的优点在于:
1)关注每个轮廓以获得更全面的空间信息.
2)可以收集更多的时间信息,因为利用了专门的结构来提取顺序信息。 然而,为这些优势付出的代价是高计算成本。
2.2 无序序列的深度学习
大多数深度学习工作都致力于常规输入表示,如序列和图像。 无序集的概念首先被(Charles et al.2017)(PointNet)引入到计算机视觉中,以解决点云任务。PointNet使用无序序列,可以避免由量化引起的噪声和数据扩展,并获得更好的性能。于是,基于序列的方法被广泛用于点云领域(列举相关文献)。最近,这些方法被引入计算机视觉领域,如内容推荐和图像字幕,用于聚合一个序列的特征。Zaheer等人进一步给出了深度学习任务中的序列描述和排列不变函数。据我们所知,它至今尚未被用于步态识别领域。
3 GaitSet
在这一节,我们描述了我们提出的方法:让模型从一个包含了一组步态轮廓图的Set中学习判别能力。整体的流程如图2所示。
3.1 问题公式化
首先,我们制定把步态视为一个Set的概念。给定一个有N个人的数据集,他们的身份分别是,
,我们假设一个人的一系列步态轮廓图分布为
(根据不同的分布P可以区分不同的人),且每个人的步态都是独特的,只与自己有关。因此,一个人在一个或者多个步态轮廓图序列(大的来说是指一个视频,小的来说是按照顺序排好的步态轮廓图)的全部步态轮廓图可以被视作一个有着
个轮廓的Set:
且
其中
用CASIC-B举列子:CASIC-B一共有124个人,每个人有3种行走条件,每3种行走条件下都有10个视角,假设每个视角下都只有30张轮廓图,那么一个人的步态轮廓图就有n=30*10*3=900个,步态序列(简单理解为一个视频)有3*10=30个。那么,再以第13个人(id为13)作为例子,就是把第13个人30个步态序列中一共900张图片放入Set,这个Set叫做,其中
代表Id为13的个人在Set中的第10张轮廓图。
在此假设下,我们通过3个步骤完成步态识别任务,公式如下:
(1)
其中F是卷积网络,旨在从每个步态轮廓提取帧级特征。
函数G是用于将一组帧级特征映射到一组Set级别特征的排列不变函数——指输入的顺序改变不会影响输出的值。它是由名为集合池化(Set Pooling-SP)的操作实现的。将在第3.2节中介绍。
函数H用于从Set级特征学习辨别不同的能力,此功能由结构实现称为水平金字塔映射(Horizontal Pyramid Mapping-HPM)。将在第3.3小节介绍。
输入 是一个四维张量(Set维,图像通道数维,图像高度维,图像宽度维)。
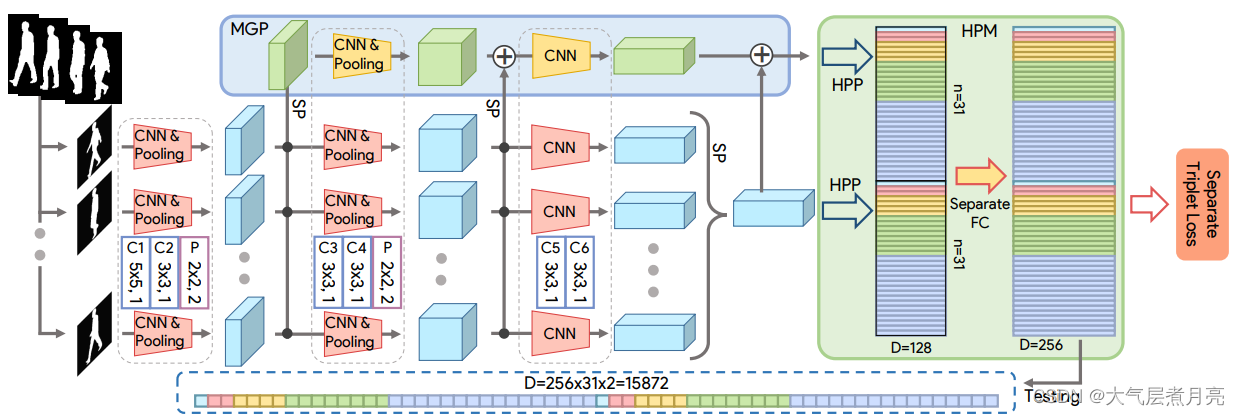
图2:GaitSet的框架。
”SP'表示集合池。梯形表示卷积块和池化块在同一列中具有相同的配置,这些配置由带大写字母的矩形表示。
请注意,在MGP上的块具有与主通道中相同的配置,但参数仅在主通道中的块之间共享。
HPP代表水平金字塔池(Fu等人,2018)。
3.2 Set Pooling
Set Pooling(SP)的目标是去集合Set中元素(Set里面放的是啥?还记得嘛,hah)的步态信息,用公式表达:,其中
表示Set级别的特征,
{
}表示帧级特征。在操作这里有两个限制:
第一是:要将Set作为输入,它应该是排列不变函数(前面3.1中已解释),其公式为:
({
})
({
}) (2)
其中π是任何排列(Zaheer等人,2017)。
第二是:因为在现实生活情节中,一个人步态轮廓的数量可以是任意的,这个函数G应该能够喂入任意基数的Set。接下来,我们将讨论关于函数G的几个实例化。实验将表明,尽管不同的实例化对最终表现有不同的影响,但都影响不大,并且他们所有的表现力都远远超过了基于GEI步态轮廓图的方法,
统计函数 为了满足方程式(2)中不变约束的要求。一个SP的自然选择是在集合维度上应用统计函数。考虑到代表性和计算成本,我们研究了三个统计函数:max(·)、mean(·)和median(·)。比较见第4.3节。
联合函数 我们还研究了两种连接上述3个统计函数的方法:
(3)
(4)
其中cat意味着在通道维度上连接,1_1C意味着(1X1)的卷积层,和max,mean还有median被应用在Set维度。方程式(4)是一个方程式(3)的增强版本——新增了一个1×1卷积层可以学习适当的权重来组合由不同统计函数提取的信息。
注意力机制 视觉注意力机制被成功的应用在大量的任务中,所以这里我们也使用它去提高SP的表现。它的结构在图片3中可以看到。这主要的思想是使用全局信息去学习一个元素关注图,使得网络只关注帧级特征比较重要的部分,从而丢弃不重要的部分,保留精细特征,实现细化。
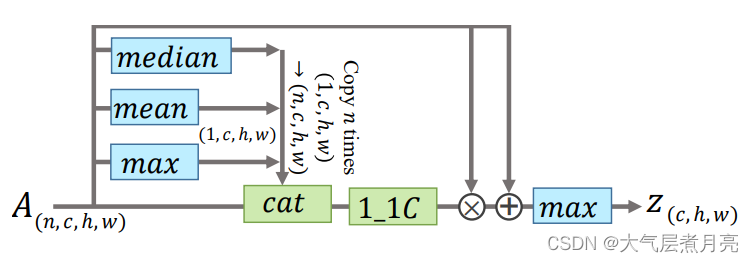
图3:使用注意力的Set Pooling(SP)的结构。
1_1C 和 cat 分别代表1×1的卷积层和连接操作。
信息首先被左边的统计函数收集。然后信息将会伴随着原始特征图被喂入一个1X1的卷积层去计算应该关注的精细特征。这最后的Set级特征将会通过统计函数max提取细化后的精细帧级特征得到。剩余的结构能够加速和稳固网络的收敛。
3.3 Horizontal Pyramid Mapping
特征图分割成条的方式经常用于人的重新识别任务。根据行人大小裁剪图像并将其尺寸调整为均匀尺寸,但辨别部分仍然因图像而异。(Fu et al.2018)提出了Horizontal Pyramid Pooling(HPP) 来处理上述问题。 HPP有4个等级,因此可以帮助深度网络同时提取局部和全局特征。我们改进了HPP使其更适合步态识别任务。
如图4所示,我们对每个池化后的特征使用独立的完全连接层(FC)将其映射到判别空间,而不是在合并后应用1×1卷积层。我们称这样的操作为Horizontal Pyramid Mapping (HPM)。
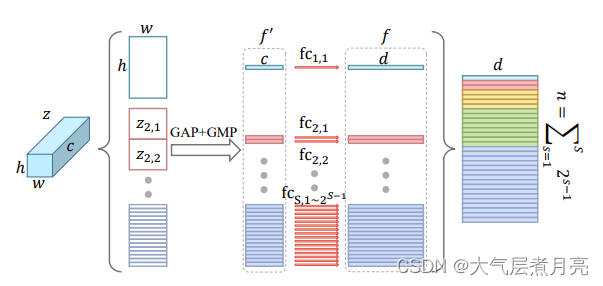
图4:Horizontal Pyramid Mapping的结构
具体而言,HPM具有S个尺度。在尺度上,由SP提取的特征图在高度尺寸上被分成
条,即总共
条。(假如S=3,则一个人的特征在竖直方向上如下图被分割成3种尺度,
=4条,所有尺度的条加在一起一共是1+2+4=7条。)

然后,用一个全局池化将3维条变成1维特征。
对于一个条来说,
代表尺度s种条的索引,也就是说z代表所有条,z有s个尺度,每个尺度有
个条,
代表尺度3的条中第五个条。
全局池化的公式是:
其中maxpool和avgpool分别代表全局最大池化和全局平均池化。
最后一步是使用FC(全连接)将特征f‘映射到辨别空间。因为不用的条在不同的尺度中描述不同的感受野,并且不同的条在每个尺度中描述不同空间位置的特征,因此如图4,很自然会想到用独立的FC。
3.4 Multilayer Global Pipeline
不同层的卷积网络具有不同的感受野。越深层具有越大的感受野。因此,浅层特征更注重细粒度,而深层特征蕴含更多全局粗粒度信息。
SP提取的Set级特征在不同层有相似的属性。如图2所示的主流程,在卷积网络的最后只有一个SP。为了收集不同级别的序列信息而提出Multilayer Global Pipeline (MGP)。最终由MGP生成的特征也被HPM分成条特征。注意:在MGP后面的HPM不会和主通道后面的HPM共享参数。
3.5 训练和测试
Training Loss
如上所述,网络的输出是具有d个维度的个特征。不同视频序列步特征图提取的对应的特征将被用于计算损失。本文中,训练网络使用Batch All(BA+)三元损失。
Testing
给定一个待验证序列Q,目标是在图片序列G中遍历全部序列找到与给定相同的ID。设G中的样本为g。 首先将Q输入到GaitSet网络中生成多尺度特征,然后将这些特征连接起来形成最终表示Fq。如图2所示。每一个样本g都走一遍一样的流程,即输入GaitSet网络并连接起来,生成Fg.最终,Fq与每个Fg计算欧氏距离来判断一次命中的识别正确率。(为什么是欧式距离,别的距离效果会不会有所提升,选择欧氏距离的理论依据何在,其他距离比如曼哈顿距离是否更符合这个判别空间)
4 实验
作者实验包含3个部分:
- 比较GaitSet与其他顶级算法在2个公开数据集CASIA-B和OU-MVLP上的效果。
- 对CASIA-B进行消融实验(类似控制变量)
- 从三个方面研究了GaitSet的实用性:有限轮廓下的表现、多视图和多步行条件下的性能
4.1 数据集和训练细节
CASIA-B
CASIA-B数据集是一个流行的步态数据集。内含124个对象(标记为001-124),3种走路状态和11个角度(0∘,18∘,…,180∘)。行走状态包含正常(NM)(每个人6组)背包(GB)(每人2组)、穿外衣或夹克衫(CL)(每人2组)。也就是,每人有11×(6+2+2)=110 个序列。
由于数据集不存在官方规定的训练和测试部分,作者使用当前文献中流行的3种分配法进行实验。
| train | test | |
| 小样本训练(ST) | 24 | 100 |
| 中样本训练(MT) | 62 | 62 |
| 大样本训练(LT) | 74 | 50 |
所有test集合 NM(#1-4)为gallery,其余6个被分为probe subjects,
即NM(#5-6)、BG(#1 -2)、CL(#1-2)
OU-MVLP
OU–MVLP是迄今为止世界上最大的公开步态数据集。其中包含10307个人,每人14个角度,每个角度2个序列。
一个人(14× 2)=28个序列
训练集(5153个人) 测试集(5154个人)
测试集中 #01 为gallery set 、#00为probe set
训练细节
训练首先是数据预处理,然后是将处理好的数据投入模型中进行训练,对于 训练数据集预处理步骤详细如下:
Step1、从训练集中拿出一个大小是的
,其中
是人数而
是每个人取多少个序列,(一个序列代表一个视频的意思),
Step2 、处理获得每个人的各个序列(视频),得到一个个剪影图列表,最后再一一放入一个Set,在代码中这个Set是一个类,叫做:class DataSet(tordata.Dataset)。
Step3、虽然最后把一个人每个序列都放入一个Set,但实际上训练的时候一个只是挑选其中一个序列随机选取frame_num:30(可改超参)张图片放入网络训练。
特别说明:论文中所有实验,网络输入都是一系列64X44的对齐轮廓图(模糊来讲,人是长方形的)。轮廓图由数据集直接提供并且基于Takemura的方法对齐,看到这里如果有使用过GaitSet源代码的伙伴肯定会疑问了:代码预处理后的轮廓图都是64X64的呀,可为什么论文中明确说明了输入的图片全都是64X44的图片,这究竟是这么一回事呢?
其实,简略的来讲,当数据集输入图片大小为64X64时,代码是会自动把所有要输入网络的图片变成64X44的,那么作者在代码中如何实现的呢?
Step1、(位于utils/data_set.py、17行)
self.cut_padding = int(float(resolution)/64*10) resolution是config.py中‘data'设置的参数:
"data": {
'dataset_path': r"C:\Users\86137\Desktop\GaitSet_train\pretreatmented", # 数据加载路径(预处理时的输出 "绝对" 路径)
'resolution': '64', # 输出轮廓图的分辨率,不用更改
'dataset': 'CASIA-B', # 数据集名称
# In CASIA-B, data of subject #5 is incomplete.
# Thus, we ignore it in training.
# For more detail, please refer to
# function: utils.data_loader.load_data
'pid_num': 73, # 训练集人数,73用于训练,其余用于测试
'pid_shuffle': False, # 是否对数据集进行随机划分,如果为False,则直接选取1-pid_num
},resolution的意思是输入图片是64X64的意思,而self.cut_padding=64/64*10=10,那么这个cut_padding=10具体是用来干嘛的呢?
Step2、(位于utils/data_set.py、49行)
def __loader__(self, path):
return self.img2xarray(
path)[:, :, self.cut_padding:-self.cut_padding].astype(
'float32') / 255.0对,我们可以看到这里有个操作是:
self.cut_padding:-self.cut_padding如果对列表操作熟悉的伙伴应该已经恍然大悟了,没错,这里正是只取图片的中间44像素高,而剪除最高的10像素和最低的10像素,那么64-2X10很明显就等于44啦!
当然如果我们输入的图片大小是128X128的,resolution就要改为128了,那么最后输入网络的图片的尺寸应该会变成:128-(128/64*10)*2=128-40=88,所以最后是尺寸是128X88.
接下来,我们再详细聊一聊这个Takemura对齐的方式:

- 对轮廓图,依据每一行的像素和不为0的原则,找上边和下边。
- 根据上边和下边对轮廓图进行切割
- 对切割后的图进行resize操作,高度为64,宽度保持比例
- 依据每一列的和最大的为中心线原则,找到中心线
- 中心线左右各32像素进行切割,不够的补0
- 得到对齐后的轮廓图
训练集是使用每个人每个序列的30张图片。优化器是Adam,HPM的scale是5.三元组损失BA+的margin设置为2.(这个margin是干啥用的)
训练时用了8个1080TiGPU训练的model
- 在CASIA-B中mini-batch由前面3.5中介绍的p=8,k=16两部分组成。将C1,C2的通道数设置为32,C3,C4的通道数设置为64,C5,C6的通道数设置为128。按照这种设置,模型的平均计算复杂度是8.6GFLOPs。(这是咋算的)。学习率是1e-4.训练时的epoch, ST 50000 MT 60000 LT 80000
- OU-MVLP中比CASIA-B多了20倍的序列,因此使用更深的卷积层(C1=C2=64,C3=C4=128,C5=C6=256)并且训练的batch_size更大(p=32,k=16)前150000轮学习率1e-4,后100000轮学习率1e-5
4.2 主要成果
CASIA-B
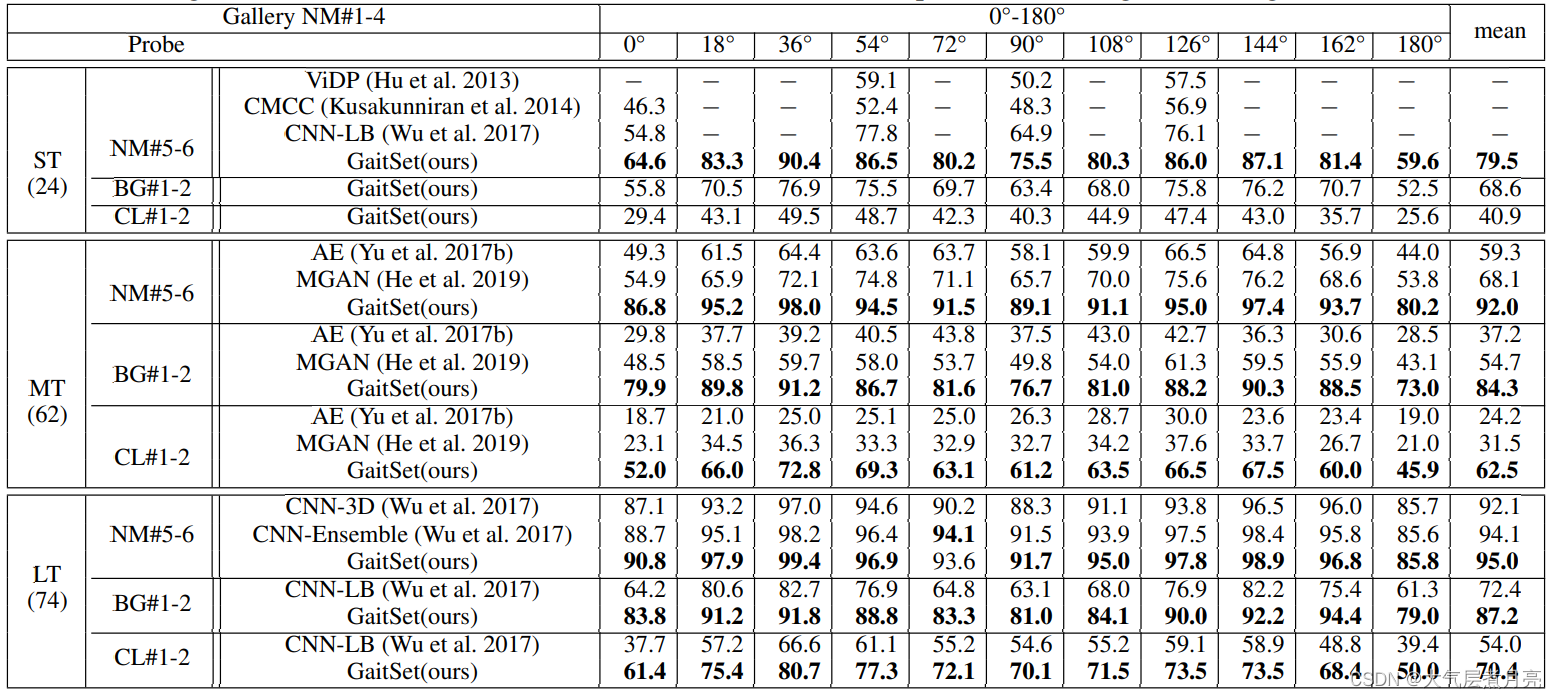
上表展示了Gait Set与顶级算法之间的比较。所有结果均在11个视角中取平均值,并且不包括相同的视角。例如,视角36°探针的正确率是平均了除36°以外的10个视角。从表1中可以看出视角和正确率有一种有趣的关系。除0°和180°外,90°的精度是局部最小值。 90°时总是比72°或108°更差。可能的原因是,步态信息不仅包含与步行方向平行的步幅信息,例如在90°时可以最清楚地观察到的步幅,还包括与行走方向垂直的步态信息,如可以观察到的身体或手臂的左右摆动最明显的是0°或180°。 因此,平行视角(90°)和垂直视角(0°&180°)都会丢失部分步态信息,而像36°或144°这样的视图可以获得大部分信息。
OU-MVLP
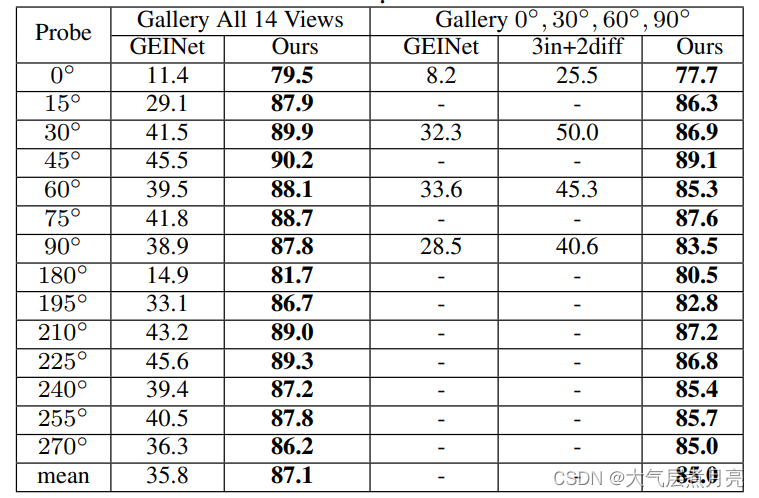
上表显示了作者的结果。由于之前的工作没有涵盖全部14个视角的实验,作者列出了两种图库序列的结果,即14个视角和4个典型视角(0◦,30◦60◦90◦)。所有结果均在全部视角中取平均值,并且不包括相同的视角。结果显示,作者的方法在如此大规模多角度的数据集上仍然具有很强的泛化能力。此外,由于每个样本的表达仅需要计算一次,因此用8块NVIDIA 1080TI GPU测试一次模型(包含133780个序列)只需要7分钟。值得注意的是,由于一些目标错过了几个步态序列并且作者没有从探针中移除它们,因此一次命中率的最大值不能达到100%。如果忽略掉上述有问题的样本,一次命中率会从87.1%提高到93.3%。
4.3 实用性
由于序列的灵活性,GaitSet仍有很大潜力可以挑战更复杂的实际情况。在这部分,通过3个新颖的场景来研究Gait Set的实用性。
- GaiSet能否在输入仅有几个轮廓时表现仍然良好
- 具有不同视角的轮廓是否可以提高识别准确度
- 模型是否可以有效的从一个包含不同行走状态轮廓的序列中提取表达特征
值得注意的是,作者没有在这些实验中重新训练我们的模型。模型时与Sec.4.2中的LT配置完全相同的。
注:所有包含随机选取的实验都运行了10次并报告10次实验的平均精度。
限制输入轮廓数实验
在真实法医鉴定场景中,很多情况下我们无法获取目标的连续步态序列,只有一些断断续续零星的轮廓。作者通过随机选取连续序列中的一些帧来模拟上述场景。下图中显示了每组输入序列轮廓的数量和11个视角的一次命中率之间的关系。
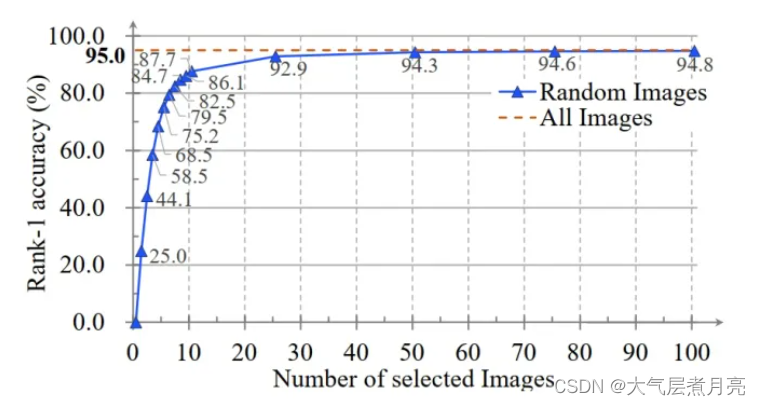
作者的方法在仅输入7个轮廓就可以得到82%的正确率。结果还表明作者的模型充分利用了步态的时间信息。因为:
- 随着轮廓数量的增加,精度单调上升。
- 当样本含量超过25个轮廓后,正确率接近最佳状态。这个数字与一个步态周期所包含的帧数一致。
多视角
有些情况下收集到的是一个人不同视角的步态信息。作者通过从具一个人的相同步态情况不同视角序列中抽取轮廓的方式模拟上述情况。为了消除轮廓数的影响,作者还进行了一个实验,其中轮廓数限制为10。具体而言,在单视角对比实验中,一个输入序列由10个轮廓构成。在2个视角实验中,一个输入序列由每个序列抽取5个轮廓共计10个轮廓组成。值得注意的是,实验中只有probe是如上组成,gallery中其他样本是由一个序列中的全部轮廓构成的。

上表显示了结果。由于需要展示的视角对太多了,作者将每个可能的相差视角结果取了平均值。例如:90°一列6个视角对(0◦&90◦,18◦&108◦,…,90◦&180◦)的平均值。另外,视角差共计有9种可能,大于90°和小于90°部分对称合并求取平均值了。例如:18°视角差和162°视角差的正确率合并在一起计算平均正确率。 可以看出,作者的模型可以聚合来自不同视图的信息并提高性能。这可以通过作者在Sec.4.2中讨论的视图和准确度之间的模式来解释。包含多视角输入序列可以让模型聚集平行视角(90°)和垂直视角(0°&180°)信息,以获得更好的表现。
5 总结
在本文中,作者提出了一个新的观点,即把步态视为一个集合,从而提出了一个GaitSet方法。与现有的将步态作为模板或序列的方法相比,GaitSet能够更有效地提取空间和时间信息。它还提供了一种新的方法,从不同的序列中聚合有价值的信息以提高识别的准确性。在两个基准步态数据集上的实验表明,与其他最先进的算法相比,GaitSet实现了最高的识别精度,并在各种复杂环境下显示出广泛的灵活性,显示出在实际应用中的巨大潜力。在未来,作者将研究一个更有效的集合池(SP)实例,并进一步提高在复杂场景中的性能。
6 引用文献
文章的总体思路还是掌握在我的手上的,但是对于论文中能够直接翻译,无需解释但又很重要的部分,我借鉴了知乎的顾道长生博主。
文章出处登录后可见!