1.论文地址
https://arxiv.org/abs/1905.11946
2.卷积神经网络发展历程
在AlexNet横空出世之后,卷积神经网络被大量应用于深度学习深度学习的研究如雨后春笋般出现;到2013年的图像分类冠军ZFNet,;到2014年的冠军GoogLeNet,季军VGG16(参数量大,大量采用3×3卷积);到2015年的ResNet(何凯明大神),首次超过人类;再到后面的一系列轻量化卷积神经网络,MobileNetV1,MobileNetV2,MobileNetV3,ShuffleNetV1,ShuffleNetV2,SqueezeNet,EfficientNetV1,EfficientNetV2等。
https://blog.csdn.net/sun_shine56/article/details/91969649
MobileNetV1:
https://mydreamambitious.blog.csdn.net/article/details/124560414?spm=1001.2014.3001.5502
MobileNetV2:
https://mydreamambitious.blog.csdn.net/article/details/124617584?spm=1001.2014.3001.5502
ShuffleNetV1:
https://mydreamambitious.blog.csdn.net/article/details/124675932?spm=1001.2014.3001.5502
ShuffleNetV2:
https://mydreamambitious.blog.csdn.net/article/details/124774129?spm=1001.2014.3001.5502
3.EfficientNetV1提出原因
在轻量化卷积神经网络提出之前,高准确率的模型往往是比较大的,网络的深度较深和宽度都较大,就比如GoogLeNet网络结构,堆叠了9个Inception模块,InceptionV2,InceptionV3,InceptionV4都是网络结构比较庞大的,参数量比较多;,VGG16模型最后的全连接层参数量达到了1亿多个,导致模型臃肿,需要更大的算力,;如ResNet残差连接结构的提出,可以让模型很深并且参数量也大大的降低的,模型最后的效果也很不错,虽然以上的模型最终的预测效果都比较不错,但是同时计算量也大大的增加,对硬件的算力要求增加,资源需求增加,同时也需要更大的数据集来训练这些模型;所以传统的模型实际是在增加卷积神经网络的深度和宽度,或使用更大的图像分辨率进行训练以此达到更好的效果。正是由于这些模型在预测效果(准确率)上的已经超过了人类的水平,所以接下来需要做的是给模型“瘦身”,优化一个更轻量化的模型,可以部署到边缘和终端设备上;同时对于硬件的算力要求也更小,但是可以达到和大模型同样差不多的效果。
4.EfficientNetV1优化网络结构的思路
使用一个简单而且高效的复合系数结构化的方式缩放卷积神经网络结构;不使用传统的方式任意的对网络的深度,宽度和分辨率进行调整,而是通过固定的尺度缩放系数统一的缩放网络维度。
5.图表比较
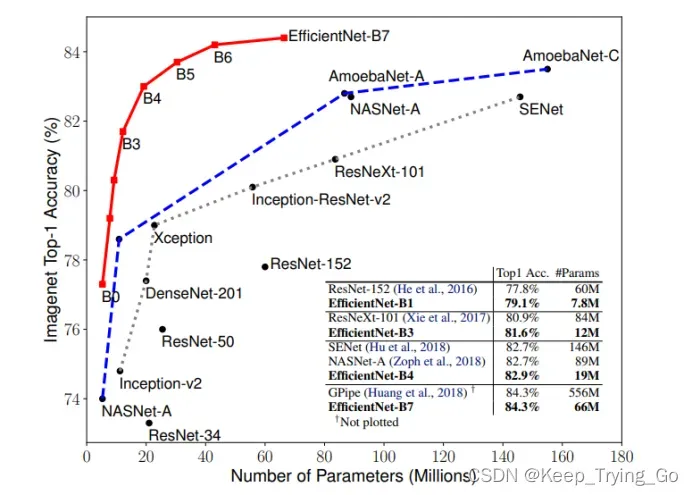
解释:横轴表示参数量,竖轴表示在Top-1上的准确率,图中的所有模型都是单模型,可以看到EfficientNetV1模型比其他的模型表现都要好,尤其是EfficientNet-B7表现最佳,其中Top-1准确率达到了84.3%(最高),而在 CPU 使用方面比以前的 Gpipe 小8.4倍,快6.1倍。EfficientNet-B1在 CPU 使用方面比 ResNet-152 小7.6倍,快5.7倍。
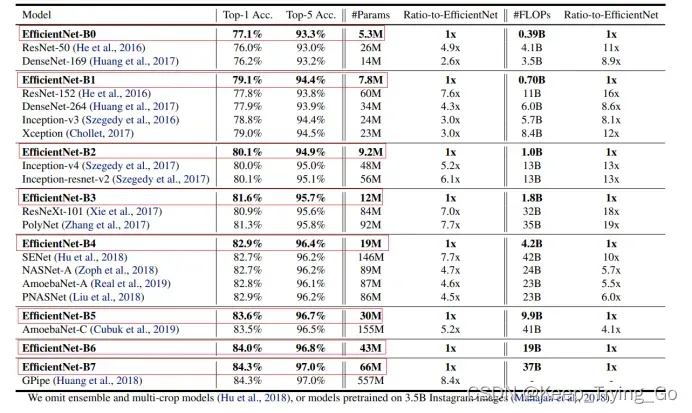
从这张图表可以看出,EfficientNet-B1-B7和当前最好的模型准确率差不多的情况下(有些甚至表现的更好),参数量和FLOPs(浮点运算数)相比其他模型更小,更轻量化。
注:FLOPS: 全大写,指每秒浮点运算次数,可以理解为计算的速度。是衡量硬件性能的一个指标。(硬件)
FLOPs: s小写,指浮点运算数,理解为计算量。可以用来衡量算法/模型的复杂度。(模型) 在论文中常用GFLOPs(1 GFLOPs = 10^9 FLOPs)
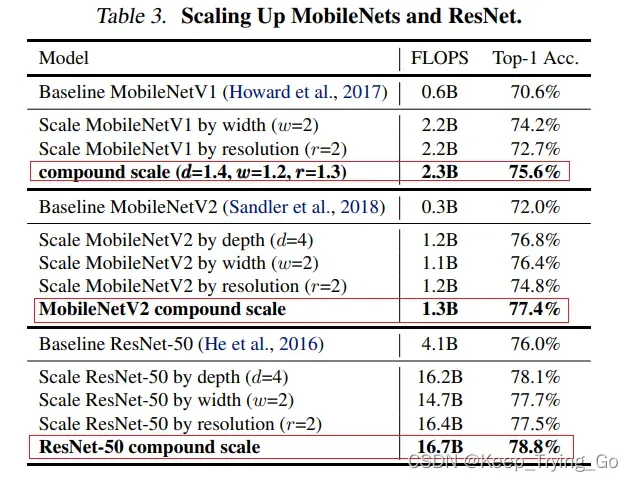
可以从此表中看出,使用复合缩放系数在模型上的表现比原有更佳。
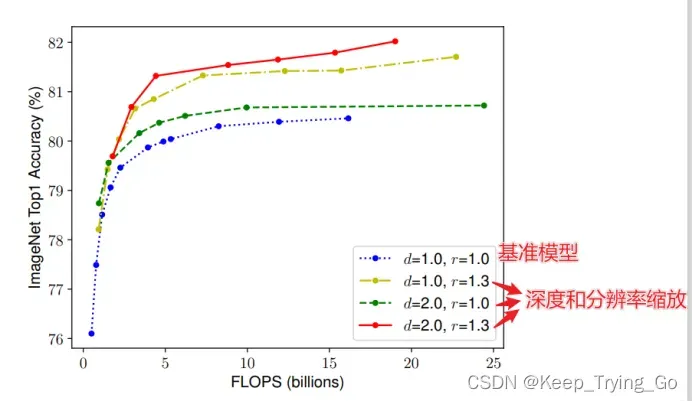
这里的基准模型使用的是18层卷积层,图像的分辨率为224×224,;可以发现通过改变深度和图像分辨率大小,可以显著的提升Top-1的准确率,并且都比基准模型都要好。
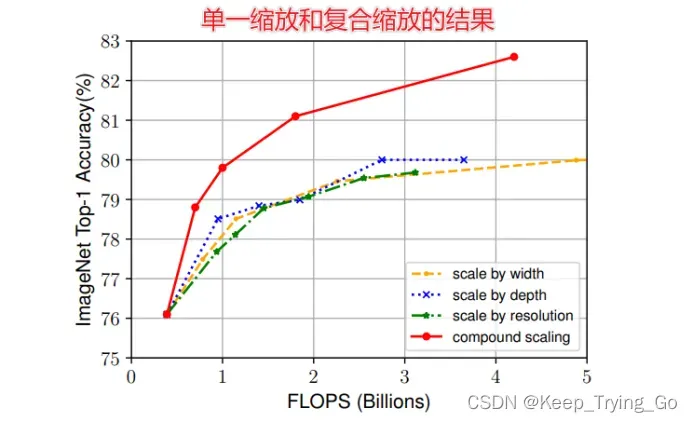
可以发现如果仅仅是对模型的宽度,深度和图像的分辨率单一的缩放的话,模型的效果并且没有复合缩放的效果好;因为模型的深度,宽度和图像的分辨率之间是紧密相关的,比如我们仅仅只改变图像的分辨率的话,而卷积层的深度和宽度不变,那么改变图片的分辨率对卷积层提取特征有很大的影响,因为图像的分辨率升高或者降低,卷积层结构不变,那么后面的卷积核提取特征图的大小也会发生相应的改变,提取到的特征也会受到影响。
从这张图也可以进一步看出,仅仅缩放其中的一种,即网络的宽度,深度或者图像分辨率,那么模型最终的性能将在接近80%的时候达到饱和状态,无法继续提高,所以再一次证明但一的缩放网络宽度,深度或者图像分辨率,最终的结果都不如复合缩放的效果好。
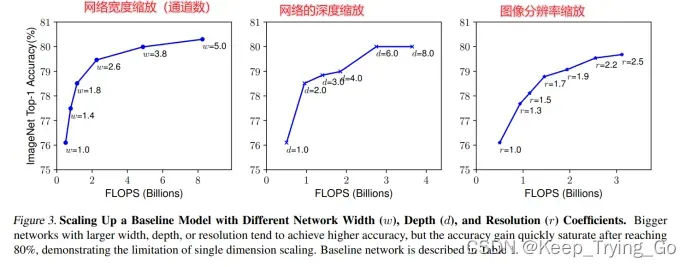
6.depth,width,resolution调整图
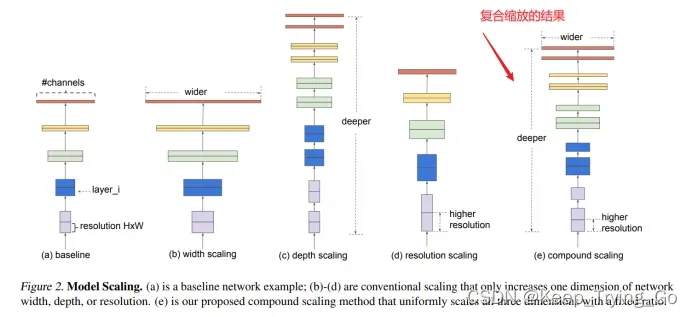
7.depth,width,resolution的缩放
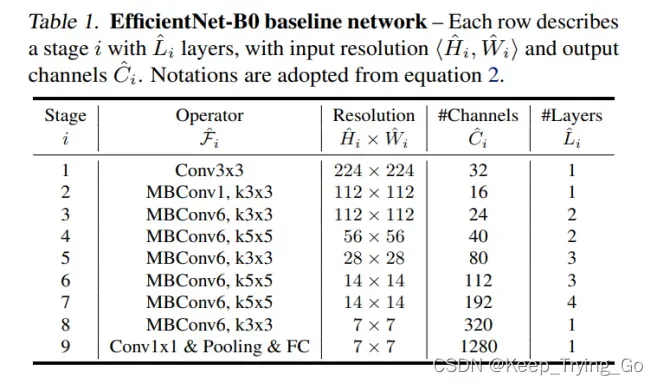




8.实验结果
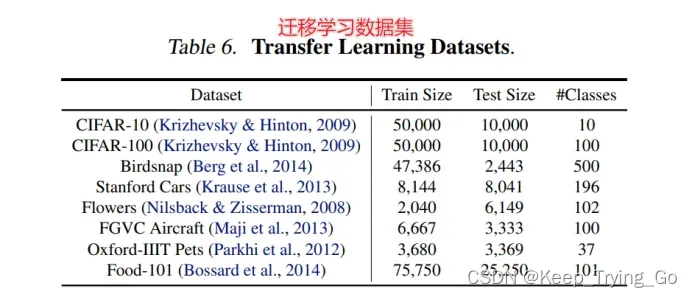
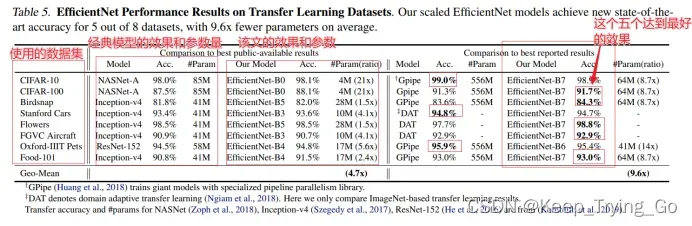
从上面的图表可以看出,使用ImageNet作为预训练模型,在新的数据集微调迁移学习,和经典模型最好的结果相比,efficientNet在准确率差不多(效果要好一点)的情况下,efficientNet的参数量明显要少很多,对计算量的要求更少,更轻量化;而且在8个数据集中,其中在5个数据集上达到了最好的效果。
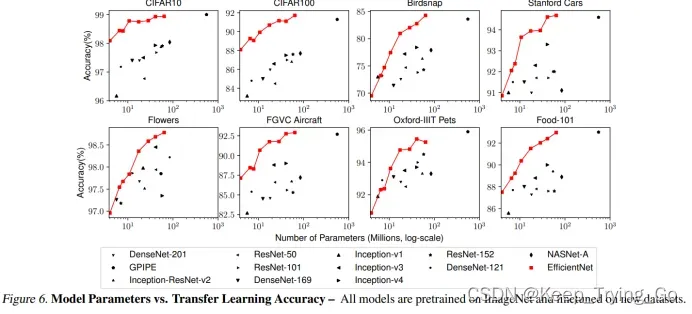
这张图表进一步说明了efficientNet性能的优越性,在8个数据集上所有的训练结果将其他所有的模型都包围在其中。
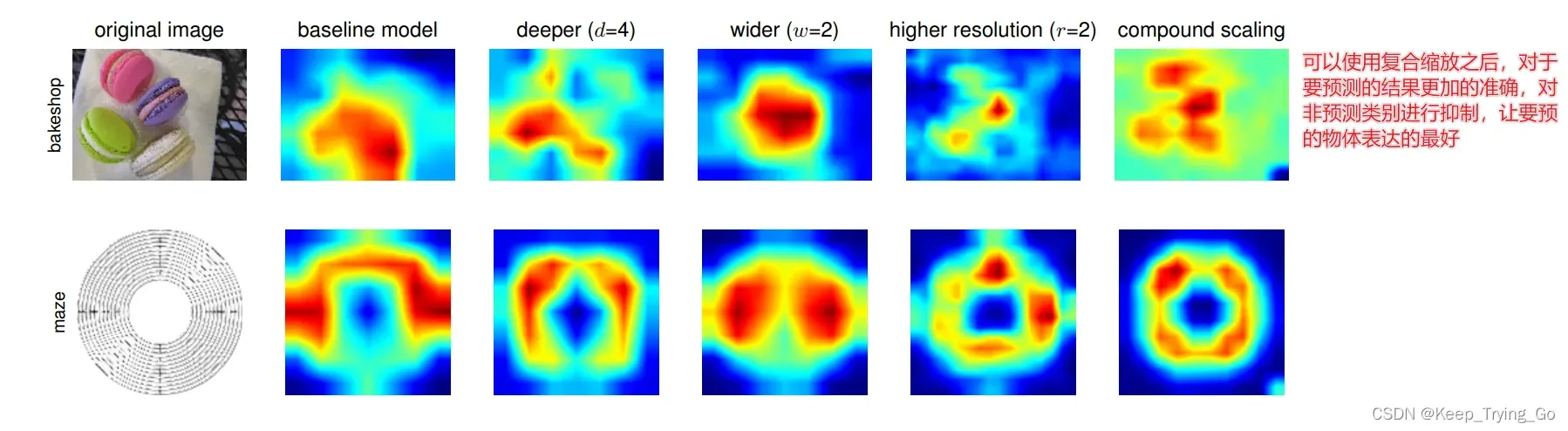
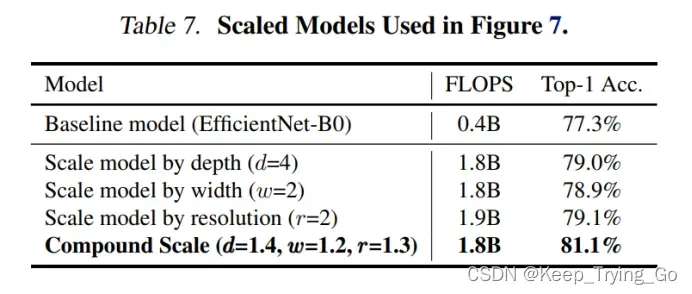
为了更进一步说明说明缩放的效果,做了一个更加直观的实验进行说明,在上面的图7中对比了一些具有代表性的模型使用不同的缩放方法,但是所有的模型都是基于相同的基准模型,最后的Top-1准确率展示在上面表7,可以发现复合缩放的效果优越其他。说明了复合缩放的方法很不错。
注:CAM-loss用CAM来约束嵌入的特征图,驱动主干表达目标类别的特征并抑制非目标类别或背景的特征,从而获得更具判别力的特征表示。抑制与类别信息无关的场景。强制让模型注意力聚焦在对应类别的CAM上,在此CAM上的一个分类。
文章出处登录后可见!