论文名称:Run, Don’t Walk: Chasing Higher FLOPS for Faster Neural Networks
论文地址:https://arxiv.org/abs/2303.03667
作者发现由于效率低下的每秒浮点运算,每秒浮点运算的减少并不一定会导致类似水平的延迟减少。提出通过同时减少冗余计算和内存访问有效地提取空间特征。然后基于PConv进一步提出FasterNet,再准的基础上更快。
1. PConv
提出了一种简单的PConv,以同时减少计算冗余和内存访问。图4中的左下角说明了PConv的工作原理。它只需在输入通道的一部分上应用常规Conv进行空间特征提取,并保持其余通道不变。对于连续或规则的内存访问,将第一个或最后一个连续的通道视为整个特征图的代表进行计算。在不丧失一般性的情况下认为输入和输出特征图具有相同数量的通道。因此,PConv的FLOPs仅对于典型的r=1/4 ,PConv的FLOPs只有常规Conv的1/16。此外,PConv的内存访问量较小,即:对于r=1/4,其仅为常规Conv的1/4。
为了充分有效地利用来自所有通道的信息,进一步将逐点卷积(PWConv)附加到PConv。它们在输入特征图上的有效感受野看起来像一个T形Conv,与均匀处理补丁的常规Conv相比,它更专注于中心位置。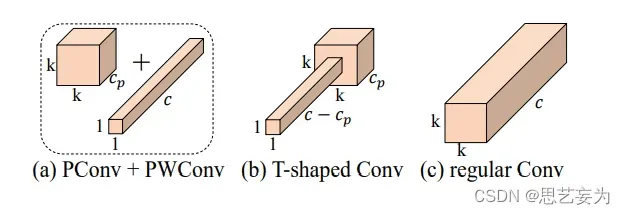
为了证明这个T形感受野的合理性,首先通过计算位置的Frobenius范数来评估每个位置的重要性。假设,如果一个职位比其他职位具有更大的Frobenius范数,则该职位往往更重要。对于正则Conv滤波器,位置处的Frobenius范数由计算,其中,作者认为一个显著位置是具有最大Frobenius范数的位置。然后,在预训练的ResNet18中集体检查每个过滤器,找出它们的显著位置,并绘制显著位置的直方图。图6中的结果表明,中心位置是过滤器中最常见的突出位置。换句话说,中心位置的权重比周围的更重。这与集中于中心位置的T形计算一致。虽然T形卷积可以直接用于高效计算,但作者表明,将T形卷积分解为PConv和PWConv更好,因为该分解利用了滤波器间冗余并进一步节省了FLOPs。
2. FasterNet
鉴于新型PConv和现成的PWConv作为主要的算子,进一步提出FasterNet,这是一个新的神经网络家族,运行速度非常快,对许多视觉任务非常有效。作者的目标是使体系结构尽可能简单,使其总体上对硬件友好。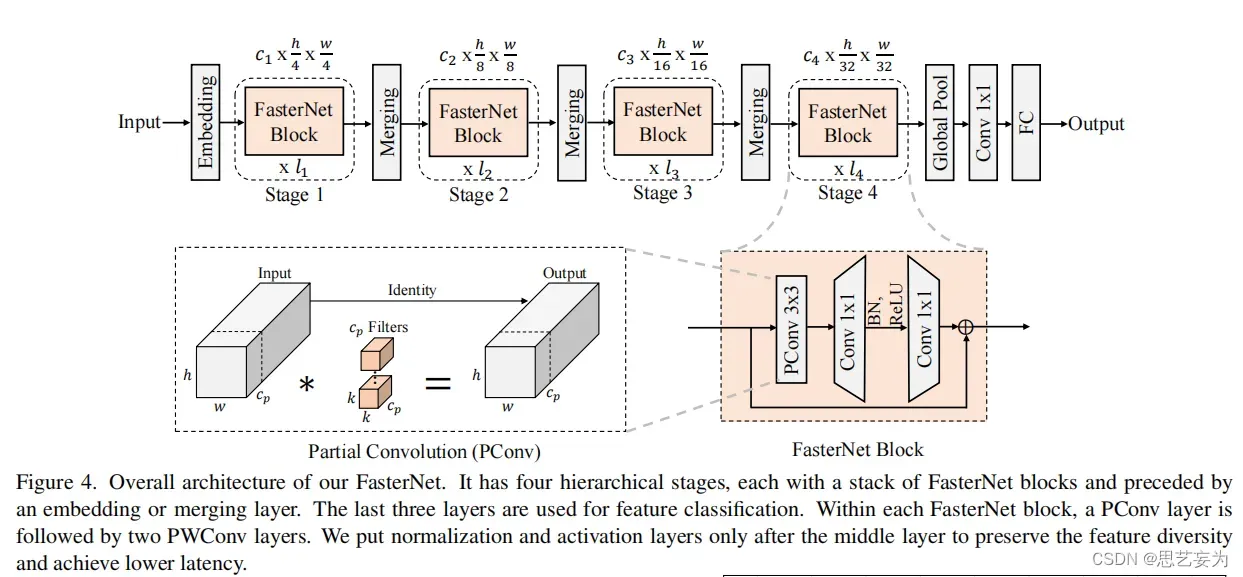
在图4中展示了整体架构。它有4个层次级,每个层次级前面都有一个嵌入层(步长为4的常规4×4卷积)或一个合并层(步长为2的常规2×2卷积),用于空间下采样和通道数量扩展。每个阶段都有一堆FasterNet块。作者观察到,最后两个阶段中的块消耗更少的内存访问,并且倾向于具有更高的FLOPS,因此,放置了更多FasterNet块,并相应地将更多计算分配给最后两个阶段。每个FasterNet块有一个PConv层,后跟2个PWConv(或Conv 1×1)层。它们一起显示为倒置残差块,其中中间层具有扩展的通道数量,并且放置了Shorcut以重用输入特征。
标准化和激活层对于高性能神经网络也是不可或缺的。然而,许多先前的工作在整个网络中过度使用这些层,这可能会限制特征多样性,从而损害性能。它还可以降低整体计算速度。相比之下,只将它们放在每个中间PWConv之后,以保持特征多样性并实现较低的延迟。
使用批次归一化(BN)代替其他替代方法。BN的优点是,它可以合并到其相邻的Conv层中,以便更快地进行推断,同时与其他层一样有效。对于激活层,根据经验选择了GELU用于较小的FasterNet变体,而ReLU用于较大的FasterNet变体,同时考虑了运行时间和有效性。最后三个层,即全局平均池化、卷积1×1和全连接层,一起用于特征转换和分类。
文章出处登录后可见!