共享单车数据处理与分析
- 1. 案例概述
- 1.1项目背景
- 1.2 任务要求
- 1.3 项目分析思维导图
- 2. 分析实现
- 1.2 包的依赖版本
- 1.3 导入模块
- 1.4 加载数据与数据探索
- 1.5 数据分析
- 1.1.1 数据预处理——每日使用量分析
- 1.1.2 连续7天的单日使用分析结论:
- 1.2.1 数据预处理——每日不同时间段的使用量分析
- 1.2.2每日不同时间段使用量分析结论:
- 2.1.1 数据预处理——骑行距离的分析
- 2.1.2 骑行距离的分析结论:
- 2.2.1 数据预处理——高峰期单车迁移情况分析
- 2.2.2 高峰期单车迁移情况分析
- 3.1.1 数据预处理——用户使用频次分析
- 3.1.2 用户使用频次分析结论:
- 1.6 项目总结
本案例来源不清楚,如果有作者,可以联系我,给加上对应链接
1. 案例概述
1.1项目背景
公共交通工具的“最后一公里”是城市居民出行采用公共交通出行的主要障碍,也是建设绿色城市、低碳城市过程中面临的主要挑战。
共享单车(自行车)企业通过在校园、地铁站点、公交站点、居民区、商业区、公共服务区等提供服务,完成交通行业最后一块“拼图”,带动居民使用其他公共交通工具的热情,也与其他公共交通方式产生协同效应。
共享单车是一种分时租赁模式,也是一种新型绿色环保共享经济。自2014年ofo首次提出共享单车概念,至今已陆续产生了25个共享单车品牌,与传统的有桩借还自行车相比,无桩的共享单车自由度更高,广受用户好评。
1.2 任务要求
本次分析拟取2017年5月中旬某共享单车在北京地区的车辆订单数据,从时间、空间、频次三个维度进行分析,对该品牌共享单车的发展方向提出改善性意见。
明确自己的需求是什么,想要用这个数据集来做什么?
数据集如下:
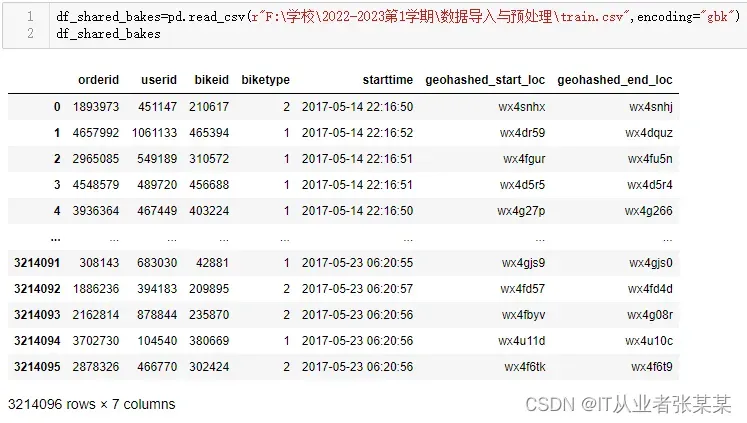
df_shared_bakes=pd.read_csv(r"F:\学校\2022-2023第1学期\数据导入与预处理\train.csv",encoding="gbk")
df_shared_bakes
输出为:
提出问题
1.用户喜欢在那个季节使用共享单车
2.用户喜欢在什么风速使用共享单车
3.用户喜欢在一天中的那个时间段使用共享单车
4.用户喜欢在什么气温下使用共享单车
5.非注册用户和注册用户对于使用共享单车次数的差别
6.用户在工作日使用共享单车还是在工作日使用共享单车的次数多
7.用户喜欢在什么湿度使用共享单车
1.3 项目分析思维导图
2. 分析实现
1.2 包的依赖版本
geopy==2.2.0
python-geohash==0.8.5
pandas==1.1.5
numpy==1.18.0
matplotlib==3.3.4
pyecharts==1.9.0
1.3 导入模块
from geopy.geocoders import BaiduV3
from geopy import distance
import geohash as gh
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from pyecharts.charts import *
from pyecharts import options as opts
import datetime
%matplotlib inline
1.4 加载数据与数据探索
加载数据
df_shared_bakes=pd.read_csv(r"F:\学校\2022-2023第1学期\数据导入与预处理\train.csv",encoding="gbk")
df_shared_bakes
输出为:
一共有321W+条数据。
查看信息
# 查看信息
df_shared_bakes.info()
输出为:

查看空缺值和重复值
# 查看空缺值和重复值
print(df_shared_bakes.duplicated().any())
print(df_shared_bakes.isnull().any())
输出为:
False
orderid False
userid False
bikeid False
biketype False
starttime False
geohashed_start_loc False
geohashed_end_loc False
dtype: bool
1.5 数据分析
1.1.1 数据预处理——每日使用量分析
df_shared_bakes_time_sorted=df_shared_bakes.sort_values(by="starttime")
df_shared_bakes_time_sorted
输出为:
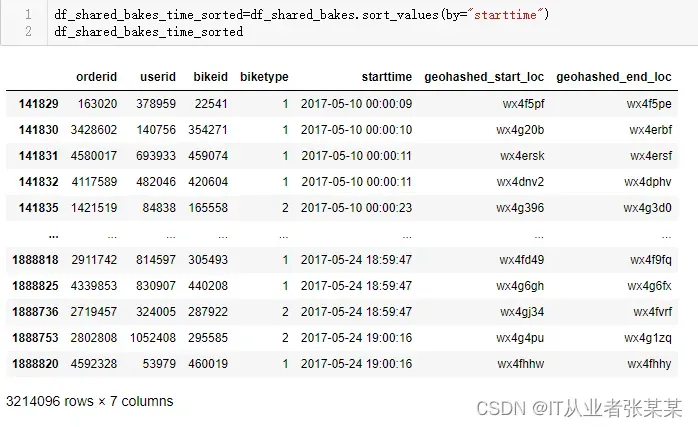
完整数据的时间跨度
#完整数据的时间跨度为2017-5-10至2017-5-24,历时15天
early=df_shared_bakes_time_sorted.iloc[0,:]
last=df_shared_bakes_time_sorted.iloc[-1,:]
print(early.starttime)
print(last.starttime)
输出为:
2017-05-10 00:00:09
2017-05-24 19:00:16
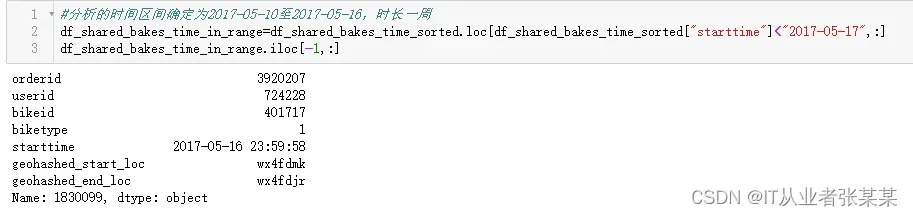
分析的时间区间确定
#分析的时间区间确定为2017-05-10至2017-05-16,时长一周
df_shared_bakes_time_in_range=df_shared_bakes_time_sorted.loc[df_shared_bakes_time_sorted["starttime"]<"2017-05-17",:]
df_shared_bakes_time_in_range.iloc[-1,:]
输出为:
df_shared_bakes_time_in_range.info()
输出为:

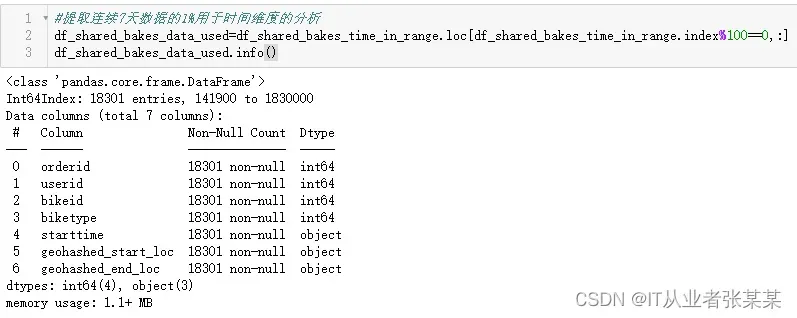
提取连续7天数据的1%用于时间维度的分析
#提取连续7天数据的1%用于时间维度的分析
df_shared_bakes_data_used=df_shared_bakes_time_in_range.loc[df_shared_bakes_time_in_range.index%100==0,:]
df_shared_bakes_data_used.info()
输出为:
对比7天内每天的用户总量,分析工作日与周末的使用量是否存在差异
#2017-05-10是星期三
#对比7天内每天的用户总量,分析工作日与周末的使用量是否存在差异
df_used_by_date=df_shared_bakes_data_used
a=df_used_by_date["starttime"].str.split(" ",expand=True)
#a
df_used_by_date.loc[:,"startdate"]=a.loc[:,0]
df_used_by_date.loc[:,"startetime"]=a.loc[:,1]
#df_used_by_date.head()
s_used_by_date=df_used_by_date.groupby("startdate").count()["userid"]
s_used_by_date
输出为:
startdate
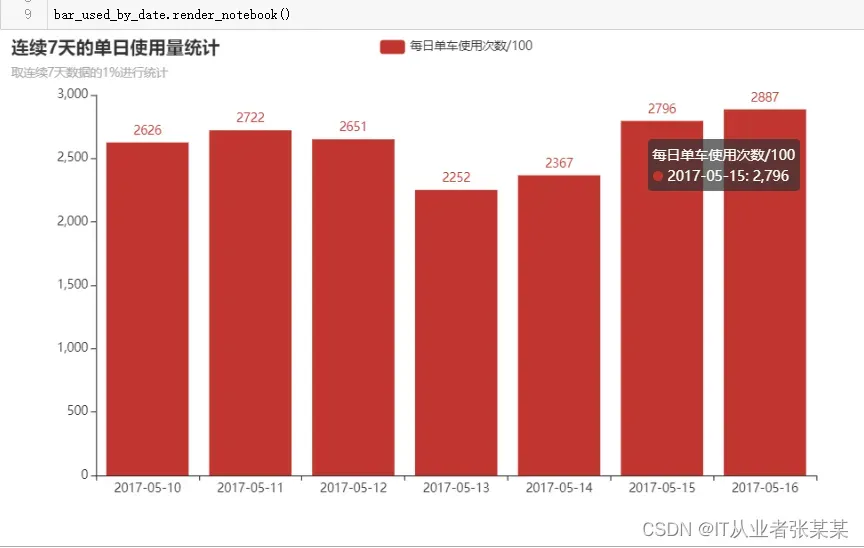
2017-05-10 2626
2017-05-11 2722
2017-05-12 2651
2017-05-13 2252
2017-05-14 2367
2017-05-15 2796
2017-05-16 2887
Name: userid, dtype: int64
1.1.2 连续7天的单日使用分析结论:
工作日相较于周末使用量更多
分别比较工作日与周末的使用量,整体趋势为稳步增长趋势
工作日比周末(13,14日)的使用量更多
#工作日比周末(13,14日)的使用量更多
bar_used_by_date=(Bar()
.add_xaxis(list(s_used_by_date.index))
.add_yaxis("每日单车使用次数/100",list(s_used_by_date))
.set_global_opts(
title_opts={"text":"连续7天的单日使用量统计","subtext":"取连续7天数据的1%进行统计"})
)
bar_used_by_date.render_notebook()
输出为:
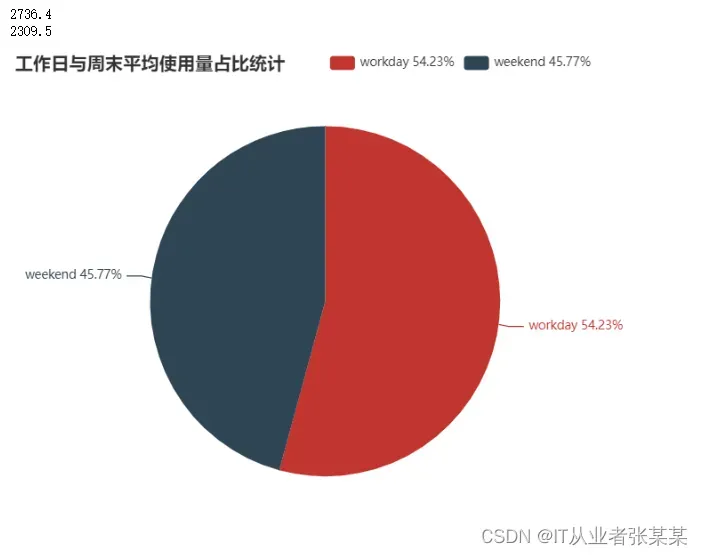
#工作日平均每天的使用量占比约为54.23%,周末平均每天使用量占比45.77%
workday_used_mean=s_used_by_date[s_used_by_date.index.isin(["2017-05-10","2017-05-11","2017-05-12","2017-05-15","2017-05-16"])].sum()/5
weekend_used_mean=s_used_by_date[s_used_by_date.index.isin(["2017-05-13","2017-05-14"])].sum()/2
print(workday_used_mean)
print(weekend_used_mean)
weekend_pct=round(weekend_used_mean*100/(weekend_used_mean+workday_used_mean),2)
workday_pct=round(workday_used_mean*100/(weekend_used_mean+workday_used_mean),2)
pie_used_data=[["workday "+str(workday_pct)+"%",workday_used_mean],["weekend "+str(weekend_pct)+"%",weekend_used_mean]]
pie_used=(Pie()
.add("",pie_used_data,center=["35%","50%"],radius=[0,175])
.set_global_opts(title_opts=opts.TitleOpts(title="工作日与周末平均使用量占比统计")))
pie_used.render_notebook()
输出为:
1.2.1 数据预处理——每日不同时间段的使用量分析
#提取小时信息,用于每日不同时间段的使用量分析
df_used_by_date.loc[:,"hour"]=df_used_by_date["startetime"].str.slice(0,2)
#df_used_by_date.loc[:,"startetime"]
df_used_by_date
输出为:
将数据分为7个单日,分布分析每日不同时间段的使用量
#将数据分为7个单日,分布分析每日不同时间段的使用量
Wednesday=df_used_by_date.loc[df_used_by_date.startdate=="2017-05-10",:]
Thursday=df_used_by_date.loc[df_used_by_date.startdate=="2017-05-11",:]
Friday=df_used_by_date.loc[df_used_by_date.startdate=="2017-05-12",:]
Saturday=df_used_by_date.loc[df_used_by_date.startdate=="2017-05-13",:]
Sunday=df_used_by_date.loc[df_used_by_date.startdate=="2017-05-14",:]
Monday=df_used_by_date.loc[df_used_by_date.startdate=="2017-05-15",:]
Tuesday=df_used_by_date.loc[df_used_by_date.startdate=="2017-05-16",:]
Wednesday_used=Wednesday.groupby("hour").count()["userid"]
Thursday_used=Thursday.groupby("hour").count()["userid"]
Friday_used=Friday.groupby("hour").count()["userid"]
Saturday_used=Saturday.groupby("hour").count()["userid"]
Sunday_used=Sunday.groupby("hour").count()["userid"]
Monday_used=Monday.groupby("hour").count()["userid"]
Tuesday_used=Tuesday.groupby("hour").count()["userid"]
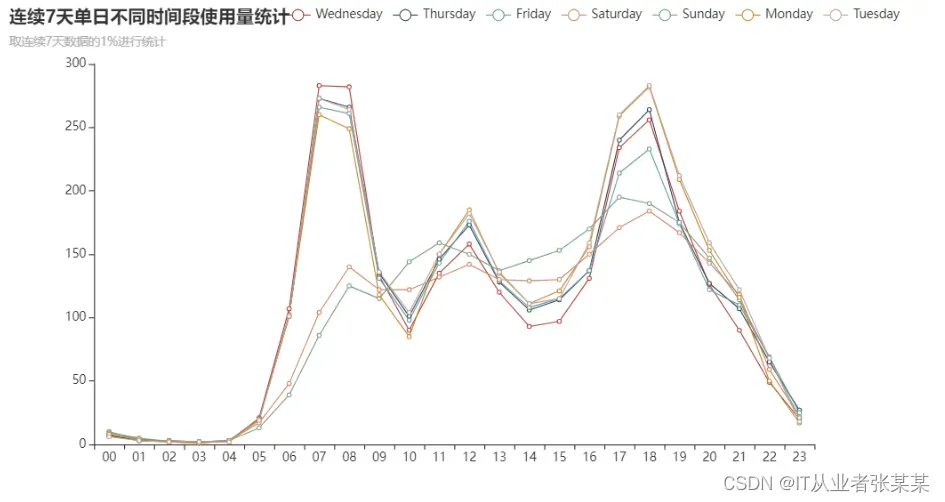
对比每一天不同时间的使用量,分析是否存在有规律的使用峰值等特征
#对比每一天不同时间的使用量,分析是否存在有规律的使用峰值等特征
#工作日与周末分布有不同的分布规律,分别分析
Line_used_by_time=(Line()
.add_xaxis(list(Wednesday_used.index))
.add_yaxis("Wednesday",Wednesday_used)
.add_yaxis("Thursday",Thursday_used)
.add_yaxis("Friday",Friday_used)
.add_yaxis("Saturday",Saturday_used)
.add_yaxis("Sunday",Sunday_used)
.add_yaxis("Monday",Monday_used)
.add_yaxis("Tuesday",Tuesday_used)
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="连续7天单日不同时间段使用量统计",subtitle="取连续7天数据的1%进行统计"),
legend_opts=opts.LegendOpts(pos_left="right"))
)
Line_used_by_time.render_notebook()
输出为:
#将数据分为两类,工作日和周末,分别分析24小时的不同时间段内的使用量
weekend=["2017-05-13","2017-05-14"]
workday=["2017-05-10","2017-05-11","2017-05-12","2017-05-15","2017-05-16"]
Weekend=df_used_by_date.loc[df_used_by_date.startdate.isin(weekend),:]
Workday=df_used_by_date.loc[df_used_by_date.startdate.isin(workday),:]
Weekend_used=Weekend.groupby("hour").count()["userid"]/2
Workday_used=Workday.groupby("hour").count()["userid"]/5
Workday_used
输出为:
hour
00 7.6
01 3.2
02 2.2
03 1.6
04 2.6
05 19.8
06 102.6
07 271.0
08 264.4
09 130.6
10 95.6
11 144.8
12 174.8
13 129.6
14 105.8
15 112.4
16 144.0
17 241.4
18 263.6
19 190.8
20 137.4
21 109.0
22 60.2
23 21.4
Name: userid, dtype: float64
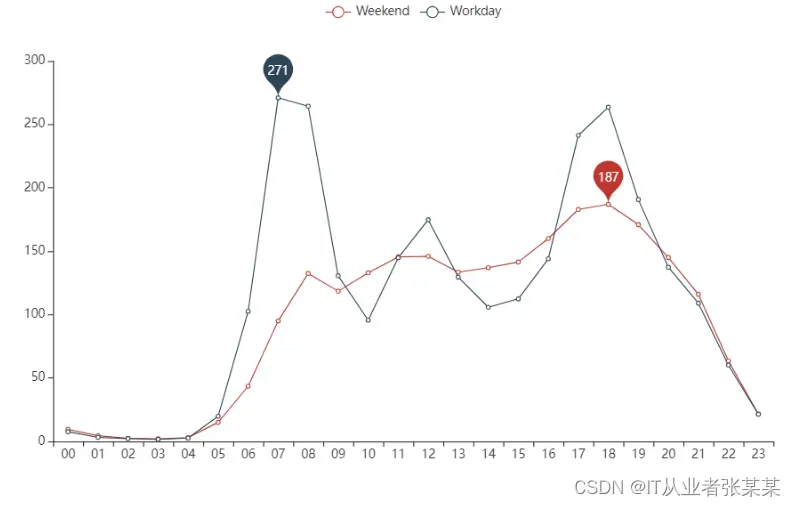
1.2.2每日不同时间段使用量分析结论:
工作日早晚各有一个峰值,中午12点有一个小峰值,说明工作日的单车使用时间符合通勤高峰时间规律,工作日的使用场景以通勤为主,还伴有部分午餐时间的使用
周末在8点至21点区间内使用量平缓分布,中午11至12点、晚5点至7点各有一个小高峰,说明周末的单车使用时间与午餐、晚餐时间相关,即周末的使用场景以休闲、聚餐为主
结合前述单日总使用量的对比,通勤需求产生的使用量更大,可能产生潮汐现象(后续具体分析)
可以选择工作日非高峰时段或周末进行单车维修、保养等工作。
#对比工作日与周末不同时间的使用量,分析分布规律
Line_used_by_time_new=(Line()
.add_xaxis(list(Weekend_used.index))
.add_yaxis("Weekend",Weekend_used,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
.add_yaxis("Workday",Workday_used,
markpoint_opts=opts.MarkPointOpts(data=[opts.MarkPointItem(type_="max")]))
.set_series_opts(
label_opts=opts.LabelOpts(is_show=False))
)
Line_used_by_time_new.render_notebook()
输出为:
2.1.1 数据预处理——骑行距离的分析
df_used_by_date=df_used_by_date.reset_index(drop=True)
df_used_by_date
输出为:
#当前位置数据采用geohash编码方式,geohash编码长度为7位
#解码后发现经纬度在小数点后两位时,geohash编码的第7位无法有效区分
#因此距离小于850m时,无法明确计算出距离,统一用0值填充
s_series=df_used_by_date.loc[:,"geohashed_start_loc"]
e_series=df_used_by_date.loc[:,"geohashed_end_loc"]
for i in df_used_by_date.index:
s=gh.decode(s_series[i])
e=gh.decode(e_series[i])
s_loc=str(float(s[0]))+","+str(float(s[1]))
e_loc=str(float(e[0]))+","+str(float(e[1]))
df_used_by_date.loc[i,"起始纬度"]=float(s[0])
df_used_by_date.loc[i,"起始经度"]=float(s[1])
df_used_by_date.loc[i,"结束纬度"]=float(e[0])
df_used_by_date.loc[i,"结束经度"]=float(e[1])
df_used_by_date.loc[i,"起始点距离"]=distance.distance(s,e).km
if i%1000==0:
print(f'{round(i*100/(df_used_by_date.index.stop-1),5)}%')
elif i==df_used_by_date.index.stop-1:
print("100%")
df_used_by_date
输出为:
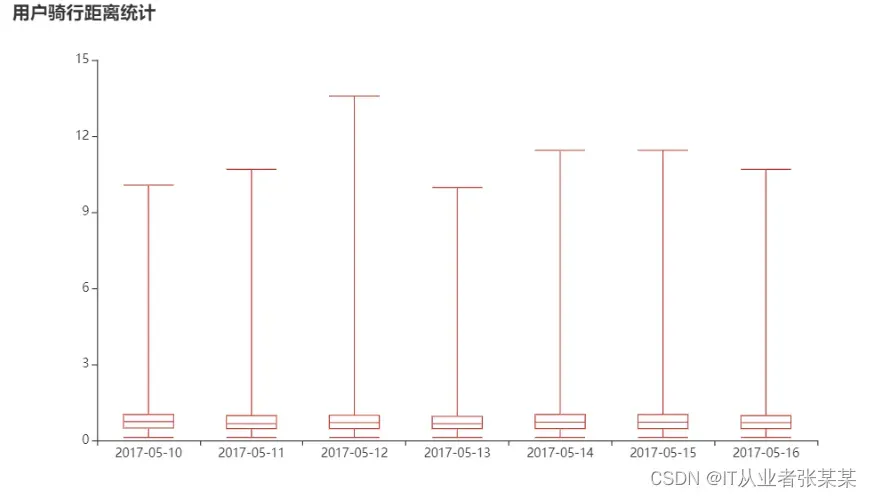
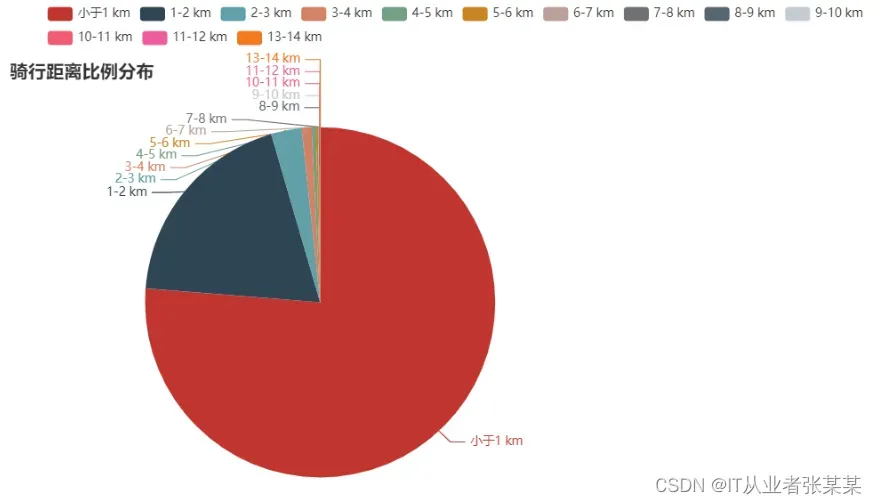
2.1.2 骑行距离的分析结论:
工作日与周末的分布情况相似,大部分用户的骑行距离都小于1.4km
骑行距离不超过1km的用户占比过半,符合共享单车的使用场景——解决“最后一公里”问题
#工作日与周末的分布情况相似,大部分用户的骑行距离都小于1.4km
dis_10=round(df_used_by_date.loc[df_used_by_date.startdate=="2017-05-10","起始点距离"],2)
dis_11=round(df_used_by_date.loc[df_used_by_date.startdate=="2017-05-11","起始点距离"],2)
dis_12=round(df_used_by_date.loc[df_used_by_date.startdate=="2017-05-12","起始点距离"],2)
dis_13=round(df_used_by_date.loc[df_used_by_date.startdate=="2017-05-13","起始点距离"],2)
dis_14=round(df_used_by_date.loc[df_used_by_date.startdate=="2017-05-14","起始点距离"],2)
dis_15=round(df_used_by_date.loc[df_used_by_date.startdate=="2017-05-15","起始点距离"],2)
dis_16=round(df_used_by_date.loc[df_used_by_date.startdate=="2017-05-16","起始点距离"],2)
box=(Boxplot()
.add_xaxis(["2017-05-10","2017-05-11","2017-05-12","2017-05-13","2017-05-14","2017-05-15","2017-05-16"])
.add_yaxis("",Boxplot.prepare_data([dis_10,dis_11,dis_12,dis_13,dis_15,dis_15,dis_16]))
.set_global_opts(title_opts=opts.TitleOpts(title="用户骑行距离统计")))
box.render_notebook()
输出为:
#骑行距离不超过1km的用户占比过半
df_used_by_date["起始点int值"]=df_used_by_date.起始点距离.astype(int)
dis_grouped=df_used_by_date.groupby("起始点int值").count()["userid"]
pie_dis_x=list(str(i)+"-"+str(i+1)+" km" for i in dis_grouped.index)
dis_data=list(list(z) for z in zip(pie_dis_x,dis_grouped))
dis_data[0][0]="小于1 km"
pie_dis=(Pie()
.add("",dis_data,center=["35%", "60%"],radius=[0, 175])
.set_global_opts(title_opts=opts.TitleOpts(title="骑行距离比例分布",pos_bottom="83%"))
)
pie_dis.render_notebook()
输出为:
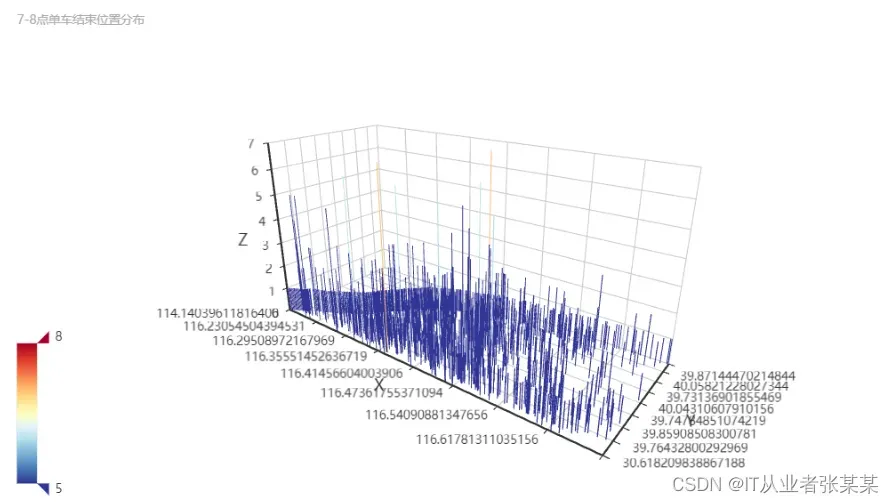
2.2.1 数据预处理——高峰期单车迁移情况分析
提取7-8点时间段内所有被使用的单车的起点位置和终点位置
#df_used_by_date.起始纬度.min()——26.14
#df_used_by_date.起始纬度.max()——40.3
#df_used_by_date.起始经度.min()——114.15
#df_used_by_date.起始经度.max()——121.52
#df_used_by_date.结束纬度.min()——26.13
#df_used_by_date.结束纬度.max()——40.3
#df_used_by_date.结束经度.min()——114.14
#df_used_by_date.结束经度.max()——121.51
#提取7-8点时间段内所有被使用的单车的起点位置和终点位置
df_hour_7=df_used_by_date.loc[df_used_by_date.hour=="07",:]
start_point_7=df_hour_7.groupby(["起始经度","起始纬度"]).count()["orderid"]
start_point_7=start_point_7.reset_index(drop=False)
t=zip(start_point_7["起始经度"],start_point_7["起始纬度"],start_point_7["orderid"])
start_loc_7=[]
for z in t:
#print(z)
start_loc_7.append(list(z))
end_point_7=df_hour_7.groupby(["结束经度","结束纬度"]).count()["orderid"]
end_point_7=end_point_7.reset_index(drop=False)
t=zip(end_point_7["结束经度"],end_point_7["结束纬度"],end_point_7["orderid"])
end_loc_7=[]
for z in t:
#print(z)
end_loc_7.append(list(z))
提取8-9点时间段内所有被使用的单车的起点位置和终点位置
#提取8-9点时间段内所有被使用的单车的起点位置和终点位置
df_hour_8=df_used_by_date.loc[df_used_by_date.hour=="08",:]
start_point_8=df_hour_8.groupby(["起始经度","起始纬度"]).count()["orderid"]
start_point_8=start_point_8.reset_index(drop=False)
t=zip(start_point_8["起始经度"],start_point_8["起始纬度"],start_point_8["orderid"])
start_loc_8=[]
for z in t:
#print(z)
start_loc_8.append(list(z))
end_point_8=df_hour_8.groupby(["结束经度","结束纬度"]).count()["orderid"]
end_point_8=end_point_8.reset_index(drop=False)
t=zip(end_point_8["结束经度"],end_point_8["结束纬度"],end_point_8["orderid"])
end_loc_8=[]
for z in t:
#print(z)
end_loc_8.append(list(z))
将7-8点时间段内的点起始位置分布绘制为两张图
#将7-8点时间段内的点起始位置分布绘制为两张图
bar_3D_start_7=(Bar3D()
.add("",
start_loc_7)
.set_global_opts(
title_opts=opts.TitleOpts(title="7-8点单车迁移情况统计",subtitle="7-8点单车起始位置分布"),
visualmap_opts=opts.VisualMapOpts(
max_=8,
min_=5,
range_color=[
"#313695",
"#4575b4",
"#74add1",
"#abd9e9",
"#e0f3f8",
"#ffffbf",
"#fee090",
"#fdae61",
"#f46d43",
"#d73027",
"#a50026",
],
)
))
bar_3D_start_7.render_notebook()
bar_3D_end_7=(Bar3D()
.add("",
end_loc_7)
.set_global_opts(
title_opts=opts.TitleOpts(title="",subtitle="7-8点单车结束位置分布"),
visualmap_opts=opts.VisualMapOpts(
max_=8,
min_=5,
range_color=[
"#313695",
"#4575b4",
"#74add1",
"#abd9e9",
"#e0f3f8",
"#ffffbf",
"#fee090",
"#fdae61",
"#f46d43",
"#d73027",
"#a50026",
],
)))
bar_3D_end_7.render_notebook()
输出为:
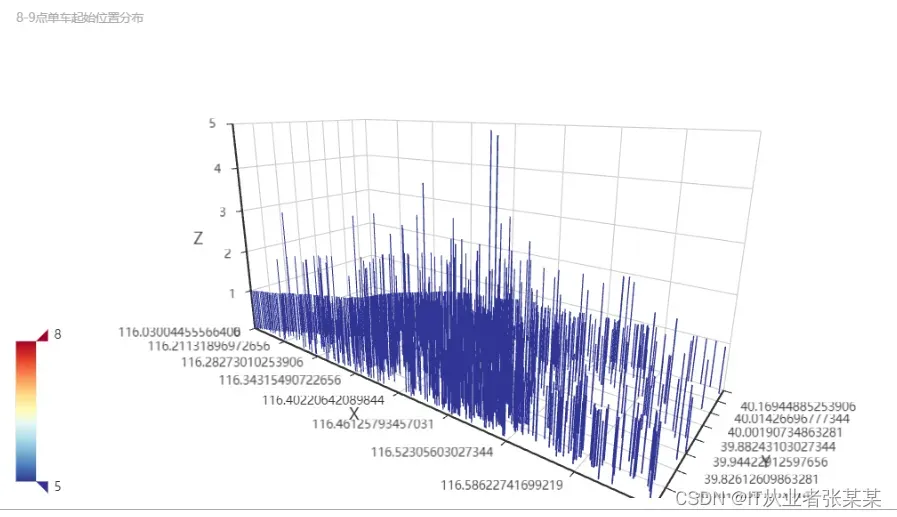
将8-9点时间段内的点起始位置分布绘制为两张图
#将8-9点时间段内的点起始位置分布绘制为两张图
bar_3D_start_8=(Bar3D()
.add("",
start_loc_8)
.set_global_opts(
title_opts=opts.TitleOpts(title="8-9点单车迁移情况统计",subtitle="8-9点单车起始位置分布"),
visualmap_opts=opts.VisualMapOpts(
max_=8,
min_=5,
range_color=[
"#313695",
"#4575b4",
"#74add1",
"#abd9e9",
"#e0f3f8",
"#ffffbf",
"#fee090",
"#fdae61",
"#f46d43",
"#d73027",
"#a50026",
],
)
))
bar_3D_start_8.render_notebook()
bar_3D_end_8=(Bar3D()
.add("",
end_loc_8)
.set_global_opts(
title_opts=opts.TitleOpts(title="",subtitle="8-9点单车起始位置分布"),
visualmap_opts=opts.VisualMapOpts(
max_=8,
min_=5,
range_color=[
"#313695",
"#4575b4",
"#74add1",
"#abd9e9",
"#e0f3f8",
"#ffffbf",
"#fee090",
"#fdae61",
"#f46d43",
"#d73027",
"#a50026",
],
)))
bar_3D_end_8.render_notebook()
输出为:
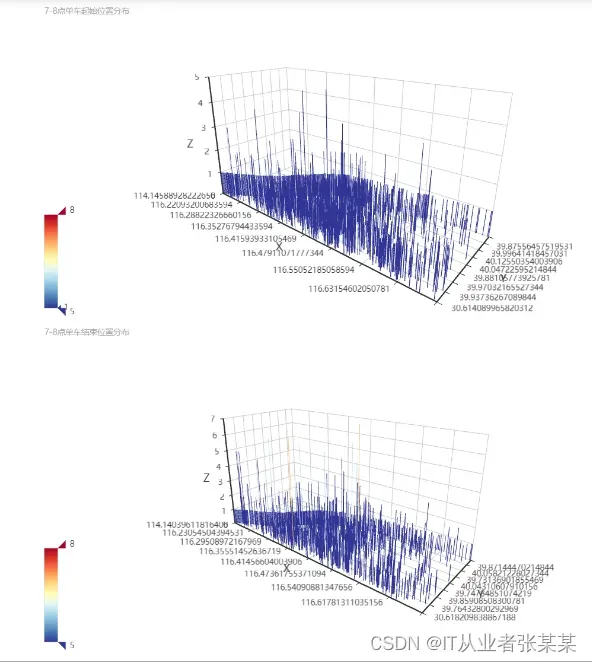
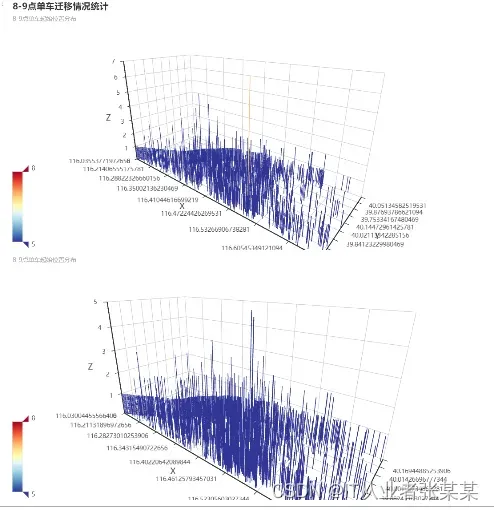
2.2.2 高峰期单车迁移情况分析
高峰期有明显的潮汐现象
可以针对早晚高峰,提前从需求较少的区域投放车辆至高峰期高需求区域
#可以看出,高峰期有明显的潮汐现象
#可以针对早晚高峰,提前从需求较少的区域投放车辆至高峰期高需求区域
page = Page()
page.add(bar_3D_start_7,bar_3D_end_7)
page.render_notebook()
输出为:
#可以看出,高峰期有明显的潮汐现象
#可以针对早晚高峰,提前从需求较少的区域投放车辆至高峰期高需求区域
page = Page()
page.add(bar_3D_start_8,bar_3D_end_8)
page.render_notebook()
输出为:
3.1.1 数据预处理——用户使用频次分析
df_shared_bakes_time_in_range.head()
输出为:
user_frequency=pd.DataFrame(df_shared_bakes_time_in_range.groupby("userid").count()["orderid"])
user_frequency=user_frequency.reset_index()
pie_user_frequency_data=user_frequency.groupby("orderid").count()["userid"]
more_than_10=pie_user_frequency_data[pie_user_frequency_data.index>10].sum()
pie_user_frequency_data=pie_user_frequency_data[:11]
pie_user_frequency_data[11]=more_than_10
pie_user_frequency_data=list(list(z) for z in zip(pie_user_frequency_data.index,pie_user_frequency_data))
pie_user_frequency_data[10][0]="大于10次"
date=df_shared_bakes_time_in_range["starttime"].str.slice(0,10)
df_shared_bakes_time_in_range.loc[:,"startdate"]=date
df_shared_bakes_time_in_range.head()
输出为:
user_frequency_weekend=pd.DataFrame(df_shared_bakes_time_in_range.loc[df_shared_bakes_time_in_range.startdate.isin(weekend),:].groupby("userid").count()["orderid"])
user_frequency_workday=pd.DataFrame(df_shared_bakes_time_in_range.loc[df_shared_bakes_time_in_range.startdate.isin(workday),:].groupby("userid").count()["orderid"])
user_frequency_weekend=user_frequency_weekend.reset_index()
user_frequency_workday=user_frequency_workday.reset_index()
pie_user_frequency_data_weekend=user_frequency_weekend.groupby("orderid").count()["userid"]
pie_user_frequency_data_workday=user_frequency_workday.groupby("orderid").count()["userid"]
more_than_10_weekend=pie_user_frequency_data_weekend[pie_user_frequency_data_weekend.index>10].sum()
more_than_10_workday=pie_user_frequency_data_workday[pie_user_frequency_data_workday.index>10].sum()
pie_user_frequency_data_weekend=pie_user_frequency_data_weekend[:11]
pie_user_frequency_data_workday=pie_user_frequency_data_workday[:11]
pie_user_frequency_data_weekend[11]=more_than_10_weekend
pie_user_frequency_data_workday[11]=more_than_10_workday
pie_user_frequency_data_weekend=list(list(z) for z in zip(pie_user_frequency_data_weekend.index,pie_user_frequency_data_weekend))
pie_user_frequency_data_workday=list(list(z) for z in zip(pie_user_frequency_data_workday.index,pie_user_frequency_data_workday))
pie_user_frequency_data_weekend[10][0]="大于10次"
pie_user_frequency_data_workday[10][0]="大于10次"
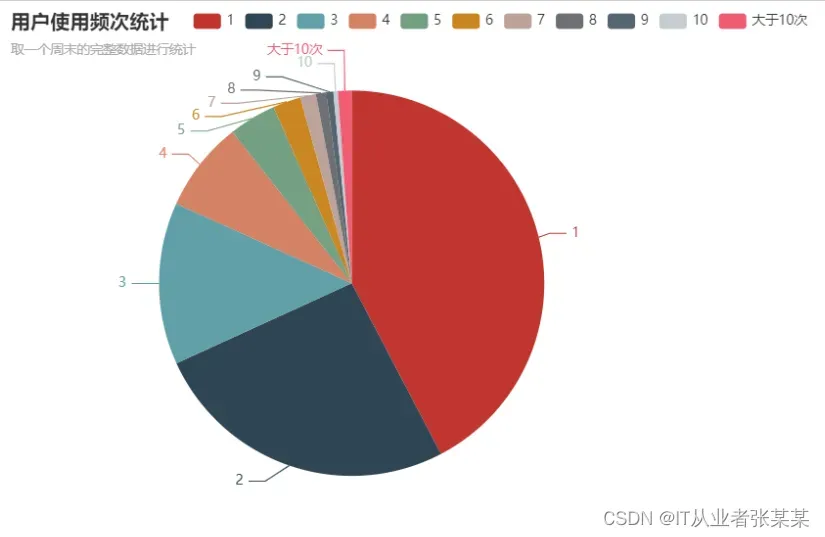
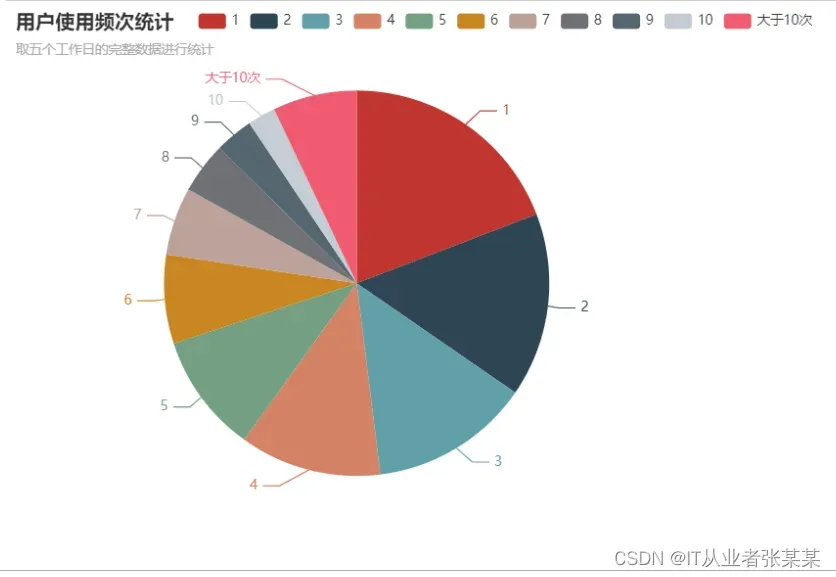
3.1.2 用户使用频次分析结论:
一周内用户的使用次数大量分布在10次以下,50%的用户使用次数为4次及以下
周末期间用户使用单车的次数普遍分布在3次及以下
工作日期间用户使用共享单车的次数普遍分布在5次及以下,使用3次及以下的用户占比近一半
工作日期间的用户使用频次有较大提升空间,通勤时段用户有大量使用需求,但总体来看使用频次仍偏低,考虑改进两个因素
0.因素一 高峰时段的车辆分布情况,是否因为高峰时段车辆数量不足,导致用户无法使用到单车
1.因素二 用户粘性差,是否用户对本品牌的单车选择倾向性低,可以考虑加大月卡等套餐的推广力度,或提升本品牌单车品质
*工作日期间使用单车次数6次及以上的用户为高粘性用户,占比约30%
#一周内用户的使用次数大量分布在10次以下,50%的用户使用次数为4次及以下
pie_user_frequency=(Pie()
.add("",pie_user_frequency_data,center=["35%","50%"],radius=[0,175])
.set_global_opts(title_opts=opts.TitleOpts(title="用户使用频次统计",subtitle="取连续7天的完整数据进行统计")))
pie_user_frequency.render_notebook()
输出为:

#一周内,周末期间用户使用单车的次数普遍分布在3次及以下
pie_user_frequency__weekend=(Pie()
.add("",pie_user_frequency_data_weekend,center=["35%","50%"],radius=[0,175])
.set_global_opts(title_opts=opts.TitleOpts(title="用户使用频次统计",subtitle="取一个周末的完整数据进行统计")))
pie_user_frequency__weekend.render_notebook()
输出为:
#一周内,工作日期间用户使用共享单车的次数普遍分布在5次及以下,使用3次及以下的用户占比近一半
#工作日期间的用户使用频次有较大提升空间
#通勤时段用户有大量使用需求,但总体来看使用频次仍偏低,考虑改进两个因素
#因素一 高峰时段的车辆分布情况,是否因为高峰时段车辆数量不足,导致用户无法使用到单车
#因素二 用户粘性差,是否用户对本品牌的单车选择倾向性低,可以考虑加大月卡等套餐的推广力度,或提升本品牌单车品质
#工作日期间使用单车次数6次及以上的用户为高粘性用户,占比约30%
rich_text = {
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
}
pie_user_frequency_workday=(Pie()
.add("",pie_user_frequency_data_workday,center=["35%","50%"],radius=[0,175])
.set_global_opts(title_opts=opts.TitleOpts(title="用户使用频次统计",subtitle="取五个工作日的完整数据进行统计")))
pie_user_frequency_workday.render_notebook()
输出为:
1.6 项目总结
本次分析明确了共享单车的使用场景:
0.工作日早晚高峰的通勤需求和午餐时间部分用户外出用餐需求
1.周末午餐、晚餐时间外出就餐需求,以及白天无明显峰值的外出需求
2.短距离骑行(1.4公里内)
改善性意见:
0.工作日高峰期时间段有明显的潮汐现象,可以提前增加高用车需求区域的单车投放量
1.用户使用频次有提升空间,考虑到工作日的通勤需求,五个工作日期间有近50%的用户使用频次不超过三次,用户粘性较差,可以推广月卡或优惠套餐等进一步提升用户粘性
文章出处登录后可见!