目录
前言
一、赛题背景
二、数据探索
1.读取数据
2.查看数据统计量
duration分箱展示
3.查看数据分布
4.数据相关图
5.其它变量可视化展示
三、数据建模
四、特征输出
五、最终成绩
前言
本次比赛数据集质量比较好,没有缺失值及重复值,但正负样本不均衡,模型使用了xgboost、lightgbm、catboost三个模型训练,结果lightgbm>xgboost>catboost,所以没有最好的模型,只有适合的模型。由于评分标准采用Accuracy,且正负样本不均衡,就算模型不能识别负样本,线上也能达到0.92,所以简单训练下就可以轻松达到0.95。lightgbm加交叉验证可以达到0.970左右,xgboost在0.965左右,catboost在0.960左右。
一、赛题背景
赛题以银行产品认购预测为背景,想让你来预测下客户是否会购买银行的产品。在和客户沟通的过程中,我们记录了和客户联系的次数,上一次联系的时长,上一次联系的时间间隔,同时在银行系统中我们保存了客户的基本信息,包括:年龄、职业、婚姻、之前是否有违约、是否有房贷等信息,此外我们还统计了当前市场的情况:就业、消费信息、银行同业拆解率等。
用户购买预测是数字化营销领域中的重要应用场景,通过这道赛题,鼓励学习者利用营销活动信息,为企业提供销售策略,也为消费者提供更适合的商品推荐。
官网数据链接:【教学赛】金融数据分析赛题1:银行客户认购产品预测-天池大赛-阿里云天池
二、数据探索
1.读取数据
import pandas as pd
import numpy as np
df=pd.read_csv("/train.csv")
test=pd.read_csv("/test.csv")
df['subscribe'].value_counts()
#####
no 19548
yes 2952
Name: subscribe, dtype: int64目标变量比例失衡
2.查看数据统计量
df.describe().T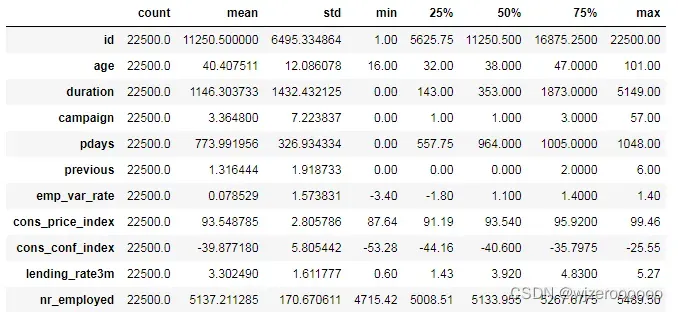
duration分箱展示
import matplotlib.pyplot as plt
import seaborn as sns
bins=[0,143,353,1873,5149]
df1=df[df['subscribe']=='yes']
binning=pd.cut(df1['duration'],bins,right=False)
time=pd.value_counts(binning)
# 可视化
time=time.sort_index()
fig=plt.figure(figsize=(6,2),dpi=120)
sns.barplot(time.index,time,color='royalblue')
x=np.arange(len(time))
y=time.values
for x_loc,jobs in zip(x,y):
plt.text(x_loc, jobs+2, '{:.1f}%'.format(jobs/sum(time)*100), ha='center', va= 'bottom',fontsize=8)
plt.xticks(fontsize=8)
plt.yticks([])
plt.ylabel('')
plt.title('duration_yes',size=8)
sns.despine(left=True)
plt.show()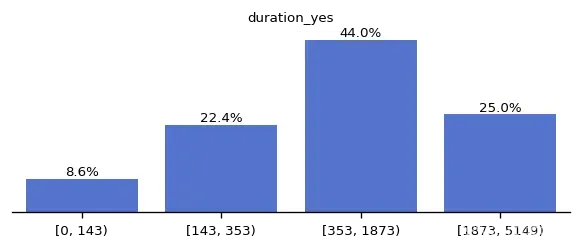
可以看出时长对目标变量有一定的区分
3.查看数据分布
# 分离数值变量与分类变量
Nu_feature = list(df.select_dtypes(exclude=['object']).columns)
Ca_feature = list(df.select_dtypes(include=['object']).columns)
#查看训练集与测试集数值变量分布
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.figure(figsize=(20,15))
i=1
for col in Nu_feature:
ax=plt.subplot(4,4,i)
ax=sns.kdeplot(df[col],color='red')
ax=sns.kdeplot(test[col],color='cyan')
ax.set_xlabel(col)
ax.set_ylabel('Frequency')
ax=ax.legend(['train','test'])
i+=1
plt.show()
# 查看分类变量分布
Ca_feature.remove('subscribe')
col1=Ca_feature
plt.figure(figsize=(20,10))
j=1
for col in col1:
ax=plt.subplot(4,5,j)
ax=plt.scatter(x=range(len(df)),y=df[col],color='red')
plt.title(col)
j+=1
k=11
for col in col1:
ax=plt.subplot(4,5,k)
ax=plt.scatter(x=range(len(test)),y=test[col],color='cyan')
plt.title(col)
k+=1
plt.subplots_adjust(wspace=0.4,hspace=0.3)
plt.show()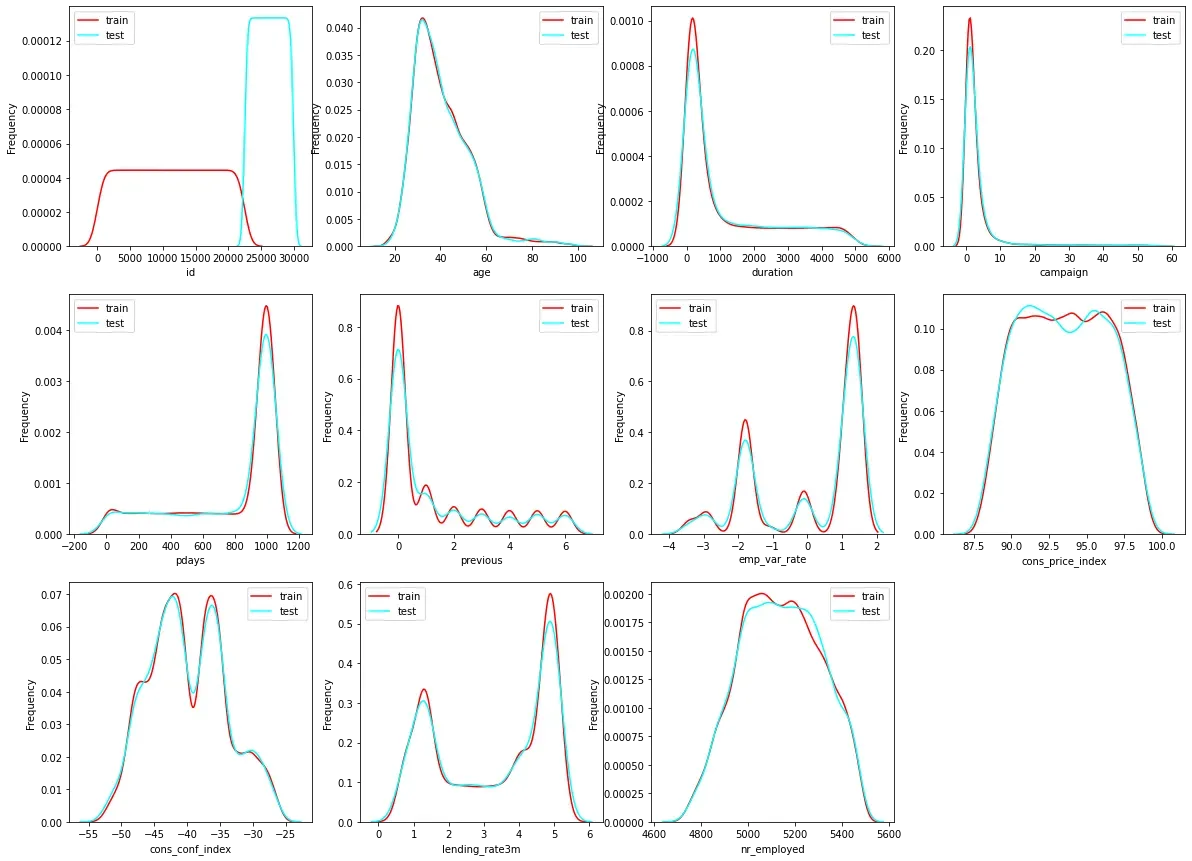
4.数据相关图
from sklearn.preprocessing import LabelEncoder
lb = LabelEncoder()
cols = Ca_feature
for m in cols:
df[m] = lb.fit_transform(df[m])
test[m] = lb.fit_transform(test[m])
df['subscribe']=df['subscribe'].replace(['no','yes'],[0,1])
correlation_matrix=df.corr()
plt.figure(figsize=(12,10))
sns.heatmap(correlation_matrix,vmax=0.9,linewidths=0.05,cmap="RdGy")
# 几个相关性比较高的特征在模型的特征输出部分也占据比较重要的位置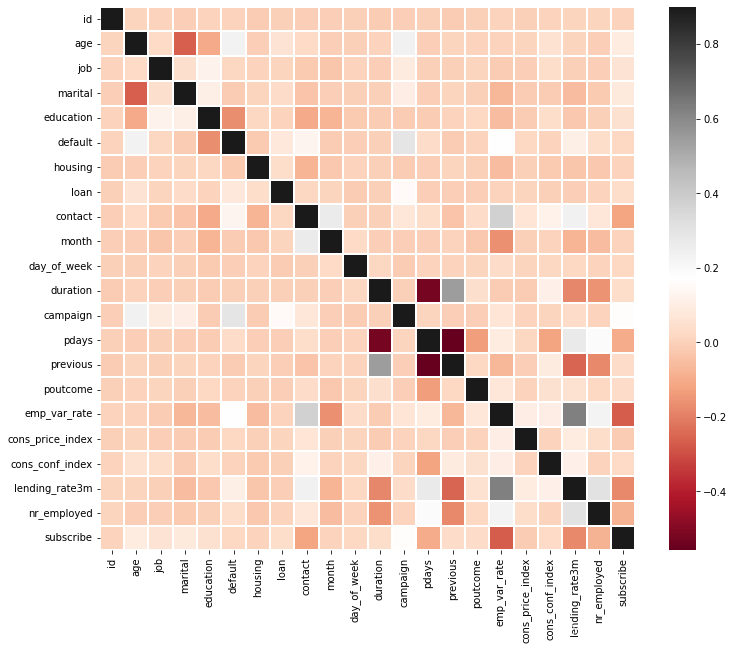
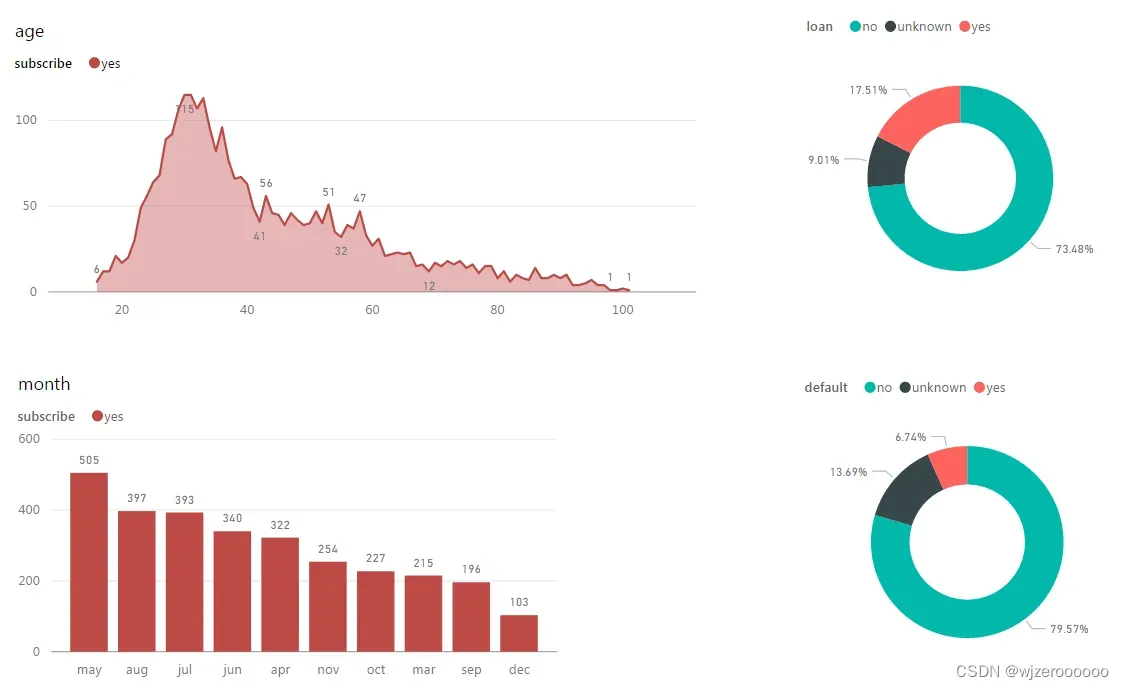
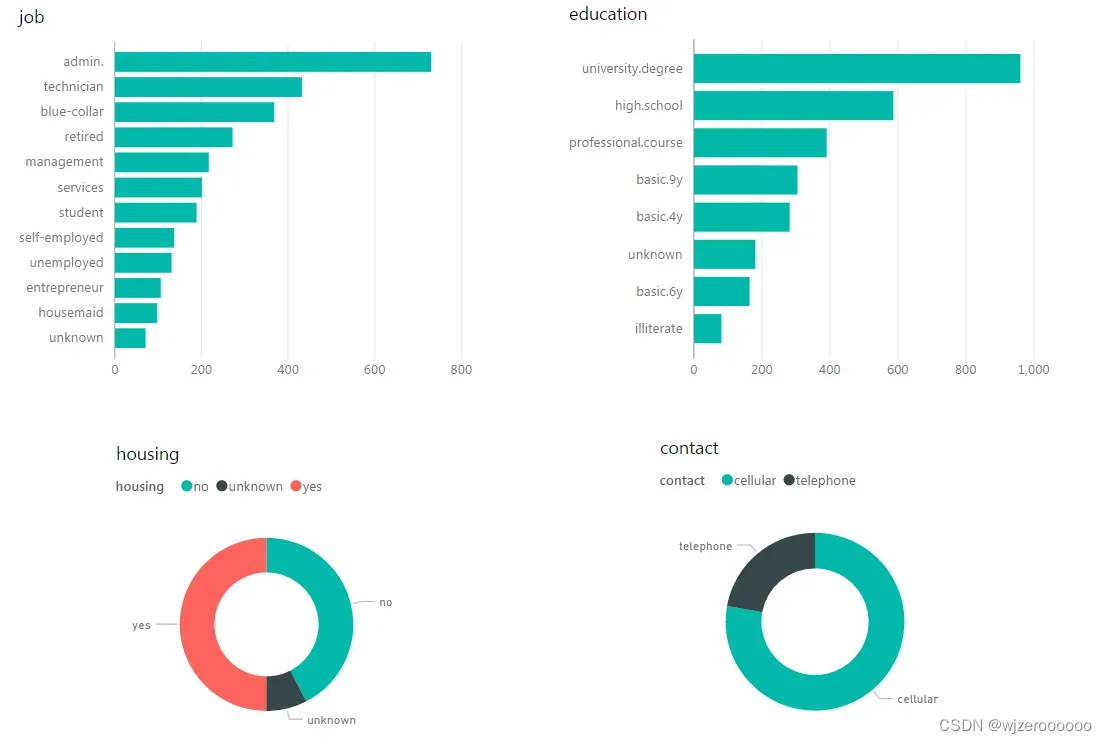
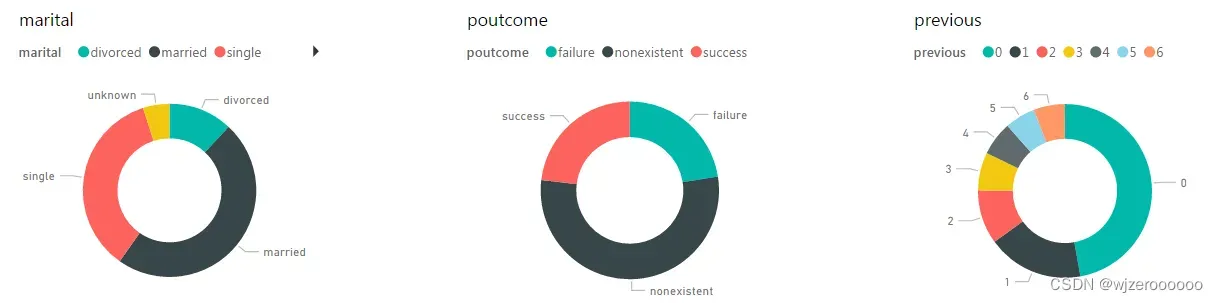
5.其它变量可视化展示
这里可视化的都是样本为yes的数据
三、数据建模
本次数据没有做任何特征工程,虽然也尝试过平均数编码,但效果不太好,所以就直接上原始数据建模
from lightgbm.sklearn import LGBMClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import KFold
from sklearn.metrics import accuracy_score, auc, roc_auc_score
X=df.drop(columns=['id','subscribe'])
Y=df['subscribe']
test=test.drop(columns='id')
# 划分训练及测试集
x_train,x_test,y_train,y_test = train_test_split( X, Y,test_size=0.3,random_state=1)
# 建立模型
gbm = LGBMClassifier(n_estimators=600,learning_rate=0.01,boosting_type= 'gbdt',
objective = 'binary',
max_depth = -1,
random_state=2022,
metric='auc')
# 交叉验证
result1 = []
mean_score1 = 0
n_folds=5
kf = KFold(n_splits=n_folds ,shuffle=True,random_state=2022)
for train_index, test_index in kf.split(X):
x_train = X.iloc[train_index]
y_train = Y.iloc[train_index]
x_test = X.iloc[test_index]
y_test = Y.iloc[test_index]
gbm.fit(x_train,y_train)
y_pred1=gbm.predict_proba((x_test),num_iteration=gbm.best_iteration_)[:,1]
print('验证集AUC:{}'.format(roc_auc_score(y_test,y_pred1)))
mean_score1 += roc_auc_score(y_test,y_pred1)/ n_folds
y_pred_final1 = gbm.predict_proba((test),num_iteration=gbm.best_iteration_)[:,1]
y_pred_test1=y_pred_final1
result1.append(y_pred_test1)
# 模型评估
print('mean 验证集auc:{}'.format(mean_score1))
cat_pre1=sum(result1)/n_folds
ret1=pd.DataFrame(cat_pre1,columns=['subscribe'])
ret1['subscribe']=np.where(ret1['subscribe']>0.5,'yes','no').astype('str')
ret1.to_csv('/GBM预测.csv',index=False)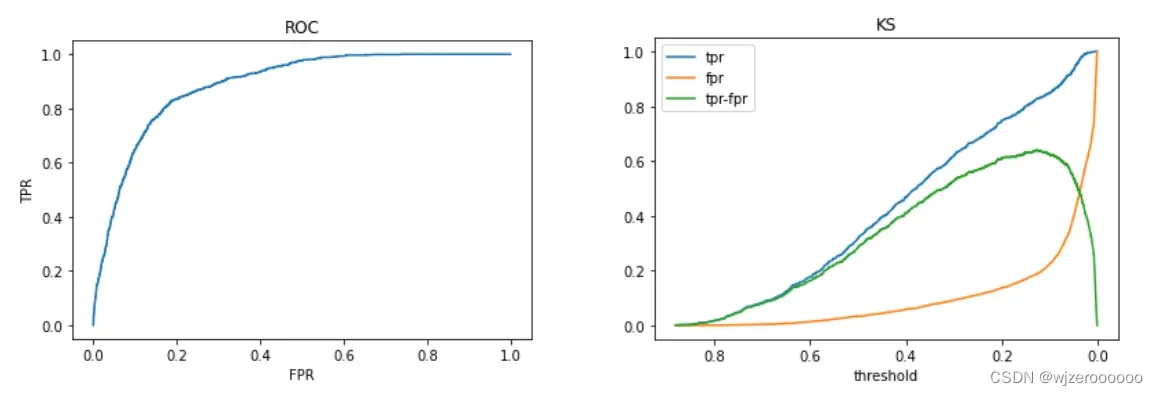
四、特征输出
import shap
explainer = shap.TreeExplainer(gbm)
shap_values = explainer.shap_values(X)
shap.summary_plot(shap_values, X, plot_type="bar",max_display =20)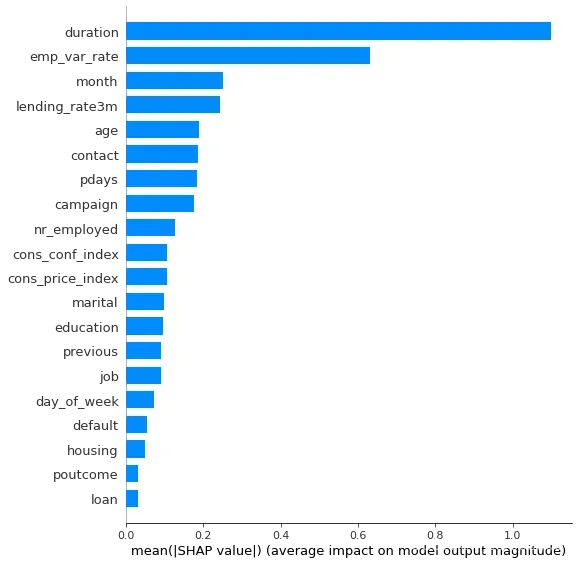
五、最终成绩
总结
1. 类似违约、欺诈的这种案例样本,负样本的比例都是相对较少的,模型在正样本的表现都是不错的,但识别负样本的效果往往一般, 所以实际项目中如何提升模型识别负样本的精度及召回率才是重点,毕竟大部分项目负样本才是我们关心的。
2. 就本赛事的结果Accuracy,由于样本不平衡,即使所有样本都为正,Accuracy也能有0.92,但这种模型本身不具备识别负样本的能力,所以还得结合precision、recall等指标参考。
3. 实际项目中不要依赖于一个算法,可以综合多个算法的结果进行比较来对负样本进行预测筛查,然后结合原始数据的特征及业务经验对负样本进行再次筛选。
文章出处登录后可见!