
1 题目
B题 人工智能对大学生学习影响的评价
人工智能简称AI,最初由麦卡锡、明斯基等科学家于1956年在美国达特茅斯学院开会研讨时提出。
2016年,人工智能AlphaGo 4:1战胜韩国围棋高手李世石,期后波士顿动力公司的人形机器人Atlas也展示了高超的感知和控制能力。2022年,人工智能绘画作品《太空歌剧院》获得了美国科罗拉多州博览会艺术比赛一等奖。2023年3月16日,百度公司推出人工智能新产品“文心一言”。
为抢抓人工智能发展的重大战略机遇,国务院2017年发布《新一代人工智能发展规划》,指出科技强国要发挥人工智能技术的力量,部署构筑我国人工智能发展的先发优势,加快建设创新型国家和世界科技强国。教育部2018年发布《教育信息化2.0行动计划》,提出实现“智能化领跑教育信息化”行动指南,强调发展智能教育。
人工智能的发展对社会各个层面均有不同程度的影响,也影响着大学生的学习。为了解人工智能在不同侧面对大学生学习的影响情况,设计了调查问卷,详见附件1,调查反馈结果详见附件2:调查数据.xlsx。
请根据你们感兴趣的某个侧面,结合附件1和附件2:调查数据.xlsx所给出的数据,建立相应的数学模型,分析人工智能对大学生学习的影响,解决以下问题:
1.对附件2:调查数据.xlsx中所给数据进行分析和数值化处理,并给出处理方法;
2.根据你们对数据的分析结果选取评价指标,从优先级、科学性、可操作性等方面论述其合理性,并构建评价指标体系;
3.建立数学模型,评价人工智能对大学生学习的影响,给出明确、有说服力的结论;
4.根据调查问卷的数据,结合你们对人工智能的了解、认知和判断,以及对未来人工智能发展的展望,写一份人工智能对大学生学习影响的分析报告,可以包括但不限于积极或消极的影响。
附件1.调查问卷
附件2:调查数据.xlsx.调查数据
2 建模思路
这是一个数据分析、数据挖掘的题目了,这一类题目的赛题,做好可视化,从多个角度去分析。
2.1 问题一
对附件2:调查数据.xlsx中的数据,可以按照以下步骤进行分析和数值化处理:
(1)对每个单选题进行计数,统计每个选项的人数和所占比例,以直方图或饼图展示。
(2)对每个多选题进行计数,统计每种组合的人数和所占比例,以多重条形图或热力图展示。
(3)对于第6列,将其进行数值化处理,可以将每个选项的时间转化为小时数,再计算平均上网时长和标准差,以及各个时间段的人数和所占比例。
(4)对于第22列和第30列,可以将每个选项进行编码,转化为数字,方便后续分析。
(5)对于第9列、第10列、第11列、第12列和第21列,可以按照二元变量的方式进行编码,转化为0或1,表示是否选中。
(6)对于第16列、第17列、第18列、第19列、第20列和第21列,可以将选项进行分类,然后采用类别变量的方式进行编码。
(7)对于第23列到第29列,可以将每个选项进行编码,然后采用类别变量的方式进行分析。
(8)最后可以进行相关性分析和因素分析,探索各个变量之间的关系和影响。可以采用回归分析、聚类分析、主成分分析等方法进行模型建立和预测。
2.2 问题二
评价指标体系应可以包含以下方面:
(1)用户特征
包括性别、专业、年级、性格、上网方式和上网时长等选项,这些信息可以用来对不同的用户群体进行分析。
(2)使用学习软件的情况
包括是否使用过学习软件工具、使用时间、传输资料的偏好、是否想获取全国各高校的学习资源、老师是否推荐过使用等选项,这些信息有助于了解大学生使用学习软件的情况。
(3)人工智能学习工具选择
包括对人工智能学习工具的看法、选择使用人工智能学习工具的原因、使用人工智能学习工具的想法和使用人工智能学习工具的限制等选项,这些信息有助于分析学生对人工智能学习工具的态度。
(4)使用人工智能学习工具的效果和问题
包括个人使用人工智能学习工具的意愿、最想得到的效果、是否赞同大学生使用人工智能学习工具等选项以及对使用人工智能学习工具的安全和重要方面的关注等,这些信息有助于了解学生使用人工智能学习工具带来的影响。
(5)在网络中的活动和学习困扰
包括网络中的活动、学习软件与传统教学相比的优势、在学习中困扰的问题以及使用学习软件进行学习的形式等选项,这些信息有助于确定学习软件在大学生学习中的作用和存在的问题。
(6)对人工智能学习工具的期望
包括心目中的人工智能学习工具应该具备的功能、人工智能学习工具应该融合到哪个学习环节等选项,这些信息有助于了解学生对未来人工智能学习工具的期望和需求。
注意可能需要考虑到不同选项之间的关系,进行综合分析和评估。
2.3 问题三
就是数据清洗和建模
(1)数据清洗和处理
首先需要对附件2:调查数据.xlsx.csv进行数据清洗和处理,包括去除脏数据、缺失值填充等操作。
(2)数据分析
对于单选题,可以使用频数分析、比例分析等方法对每个选项出现的次数进行统计,了解大学生对学习软件以及人工智能学习工具的使用情况、态度等。对于多选题,可以使用多元频数分析等方法探究各个选项之间的相关性。
(3)统计分析
可以使用因子分析、聚类分析等方法对不同的影响因素进行分析。例如,可以通过因子分析将不同的选项归纳为几个维度,如使用频率、功能需求、安全性等维度;也可以通过聚类分析将同一特征下的数据分为不同类别,如使用频率较高、偏好某一类型功能等。
(4)建立数学模型
综合前面的数据分析和统计分析结果,建立多元回归模型、决策树模型等进行预测和评估,进一步探究人工智能对大学生学习的影响情况。
(5)结论
根据所建立的数学模型,得出明确、有说服力的结论,判断人工智能学习工具对于大学生学习的影响程度、以及对于现有学习方式的优势和不足等方面进行评价,并提出相应的建议和改进。
3 代码实现
3.1 问题一
(1)进行特征编码
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MultiLabelBinarizer
# 加载数据文件
data = pd.read_excel("data/附件2:调查数据.xlsx")
# 前22列采用类别变量进行编码
# 第23列之后的列采用类别变量进行one-hot编码
df = data.iloc[:,23:]
# 对每一列进行多标签二值化编码
mlb = MultiLabelBinarizer()
cols = df.columns
for col in df.columns:
# 将每一列的数据按照分隔符进行分割
df[col] = df[col].apply(lambda x: x.split('┋') if isinstance(x, str) else x)
mlb.fit_transform(df[col])
# # 将编码结果按照列名展开为新的列
for i, label in enumerate(mlb.classes_):
data[f'{col}_{label}'] = df[col].apply(lambda x: 1 if label in x else 0)
data.drop(columns=df.columns,inplace=True)
(2)分析数据
# 设置中文字体
。。。略,请下载完整代码
# 单选题1~22统计每个选项的人数和所占比例
for i in range(1, 23):
print("题目{}选项人数:\n{}\n".format(i, counts))
print("题目{}选项比例:\n{}\n".format(i, percentages))
# 绘制各题目的直方图和饼图
plt.subplot(2, 1, 1)
plt.bar(counts.index, counts.values)
plt.title(cols[i])
plt.ylabel("Counts")
plt.subplot(2, 1, 2)
plt.pie(percentages.values, labels=percentages.index, autopct="%1.1f%%")
plt.title(cols[i])
plt.tight_layout()
plt.show()
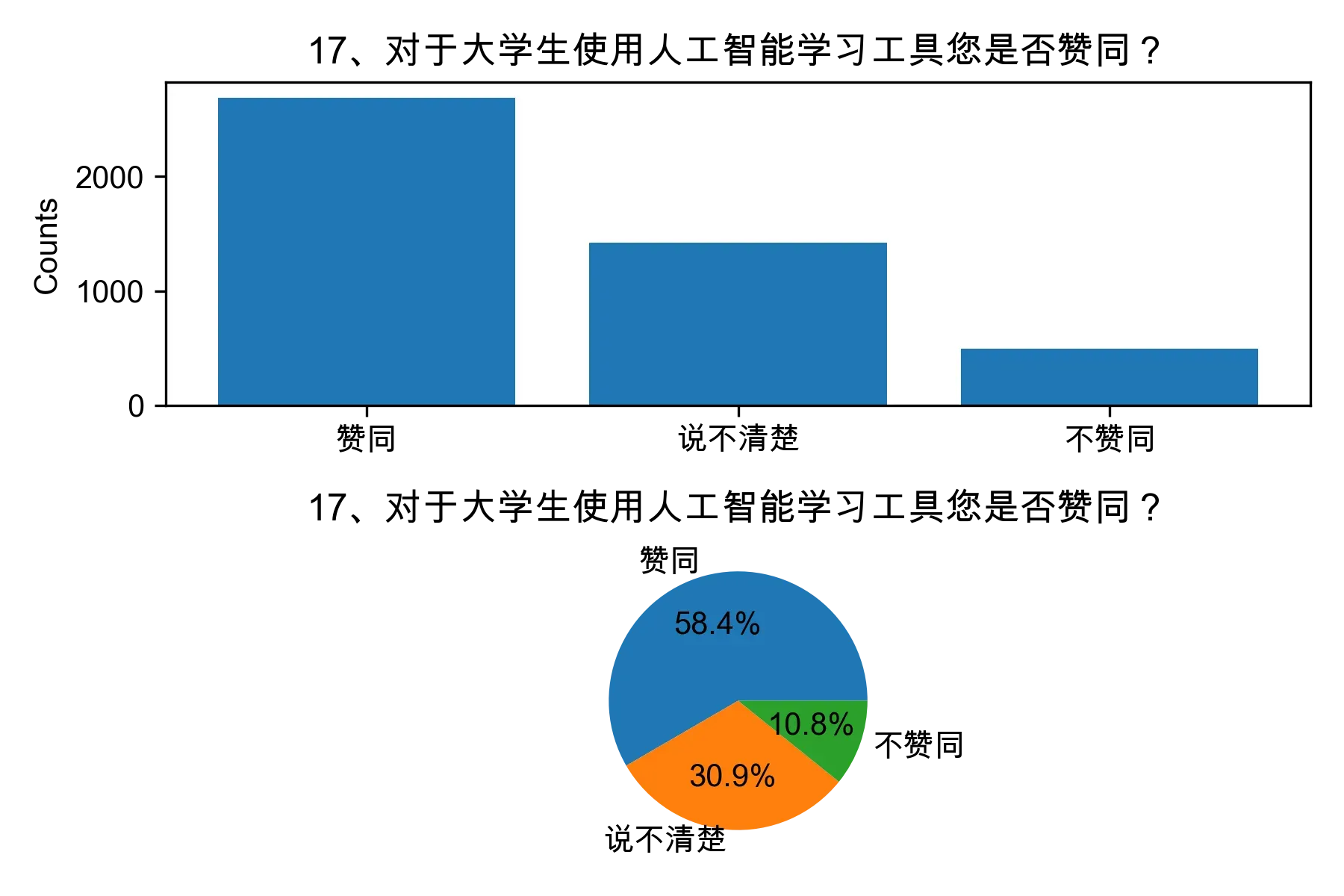
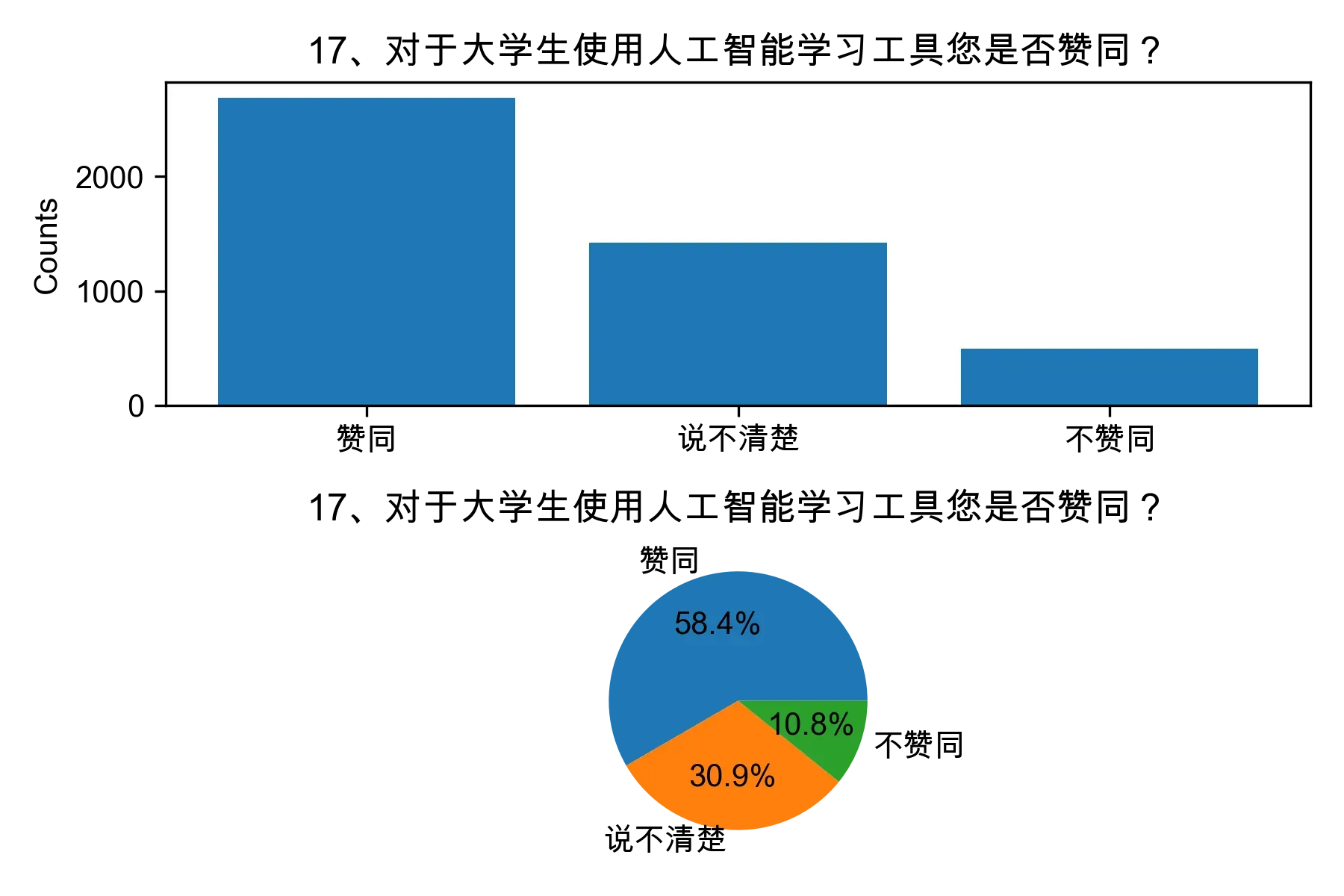
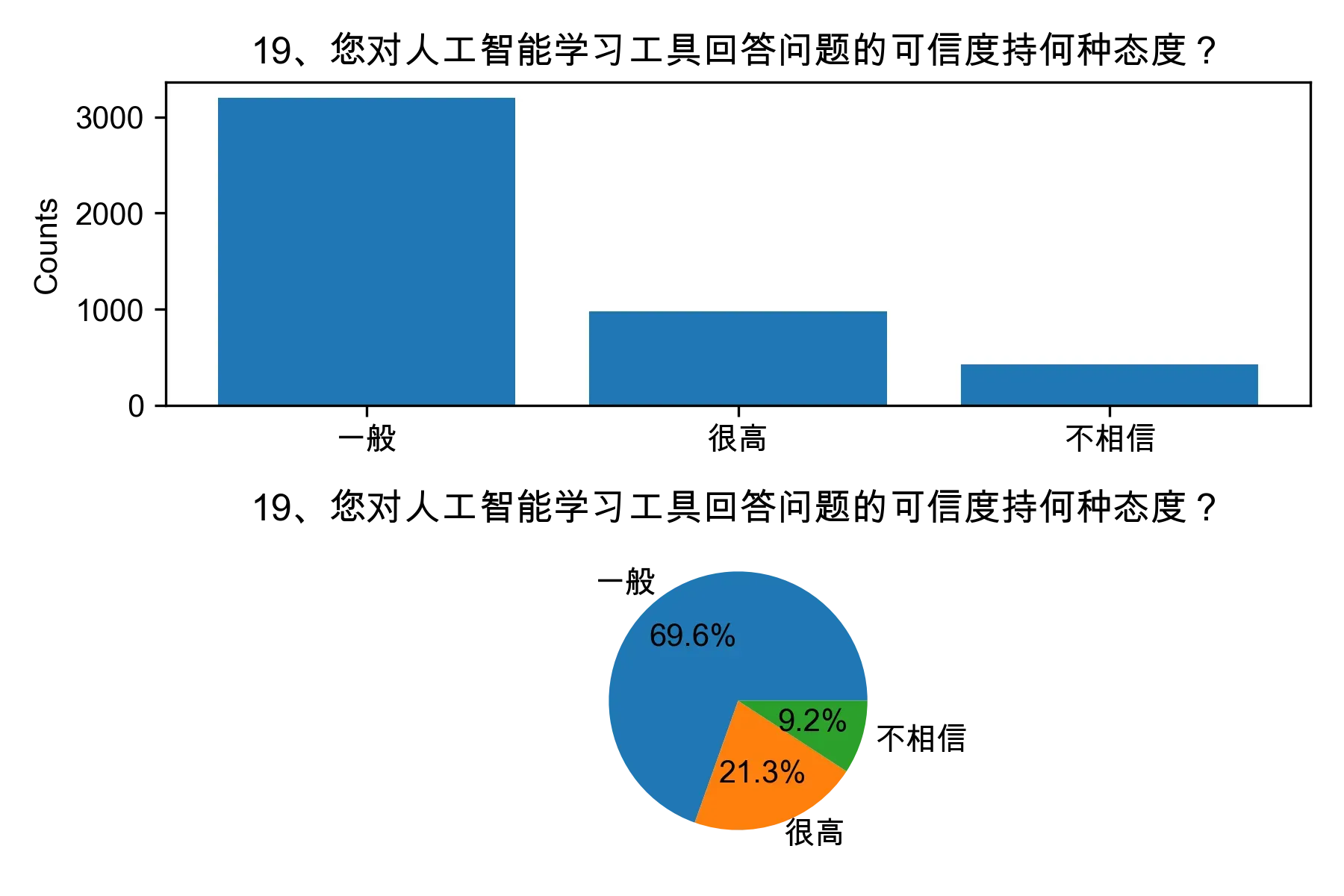
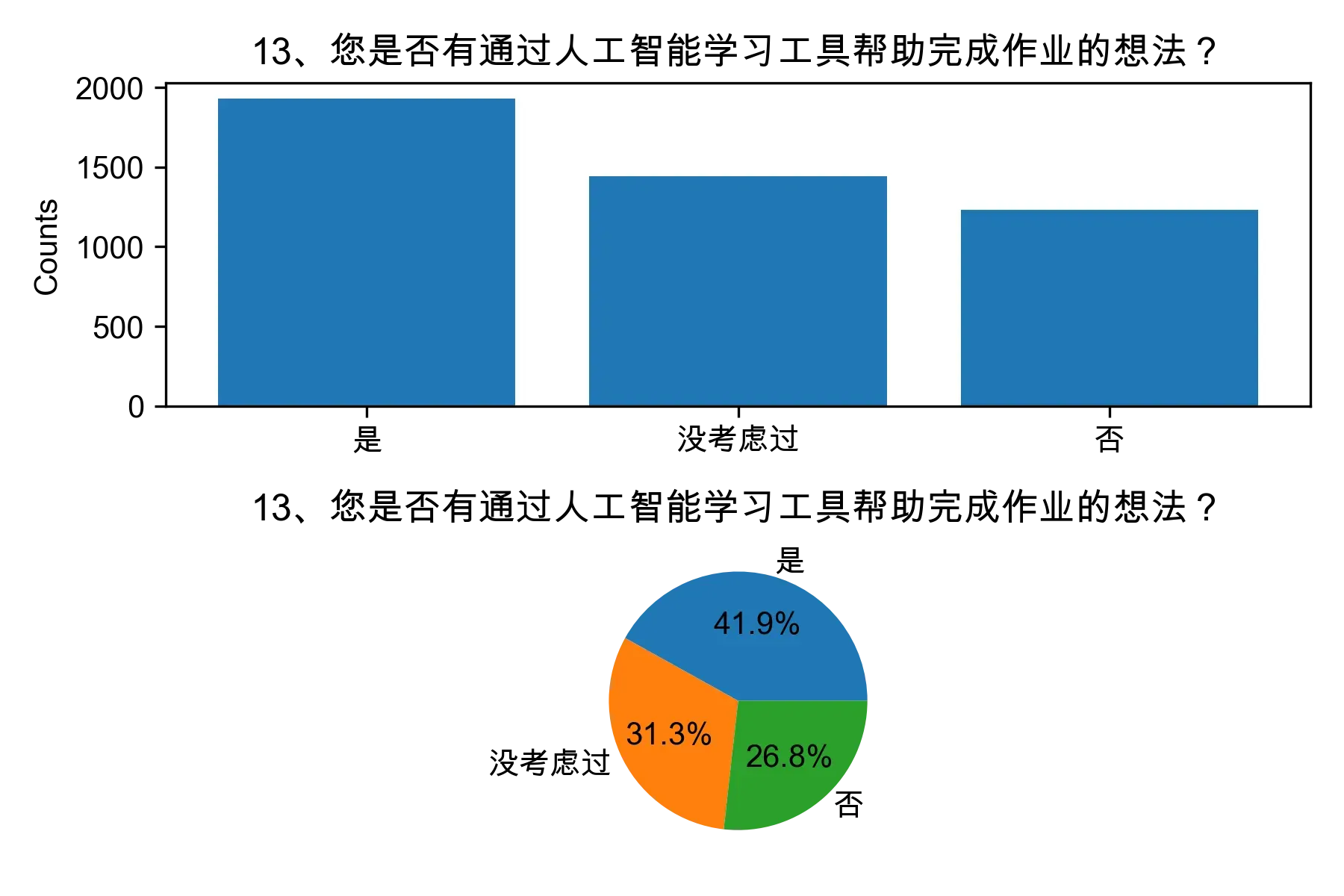
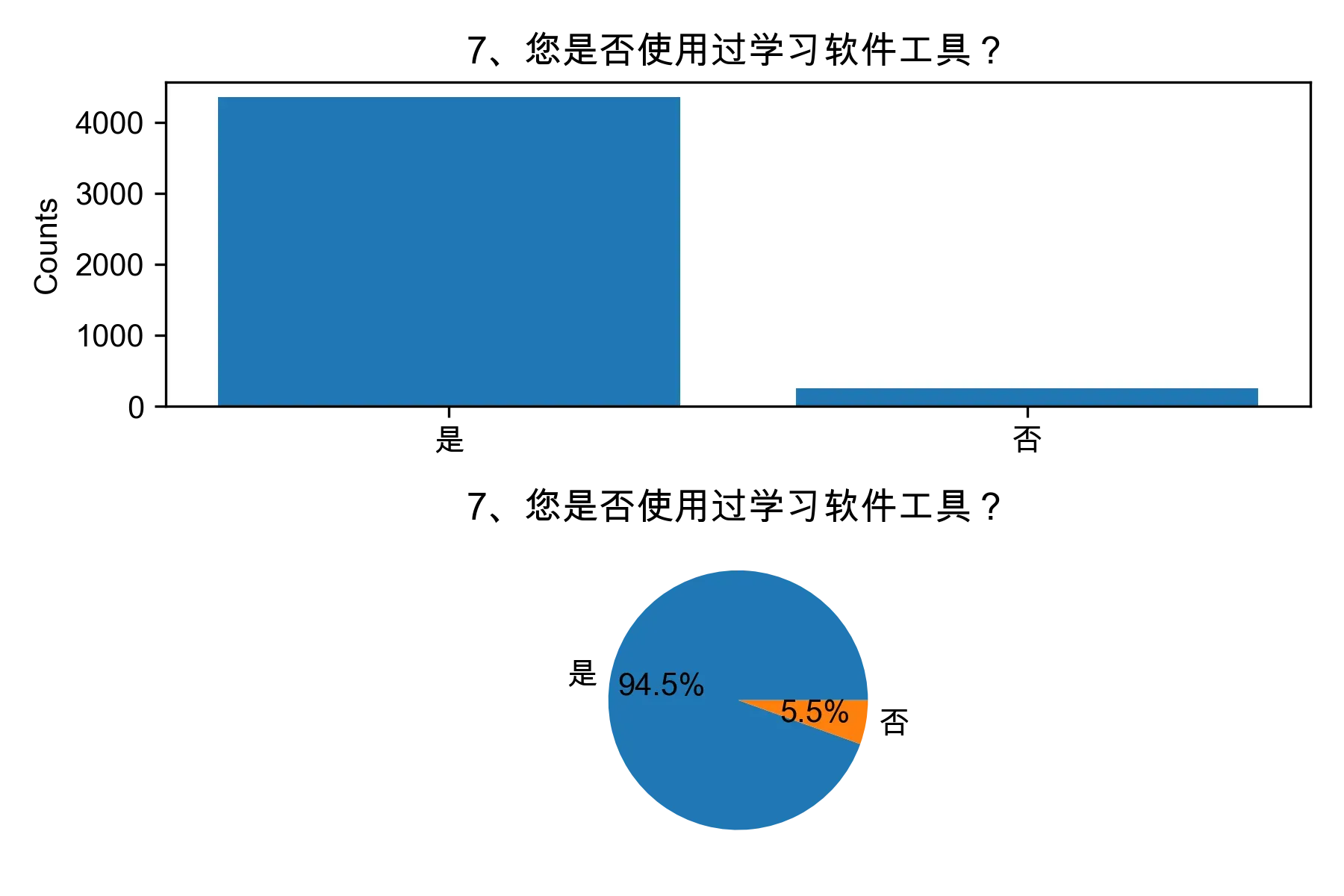
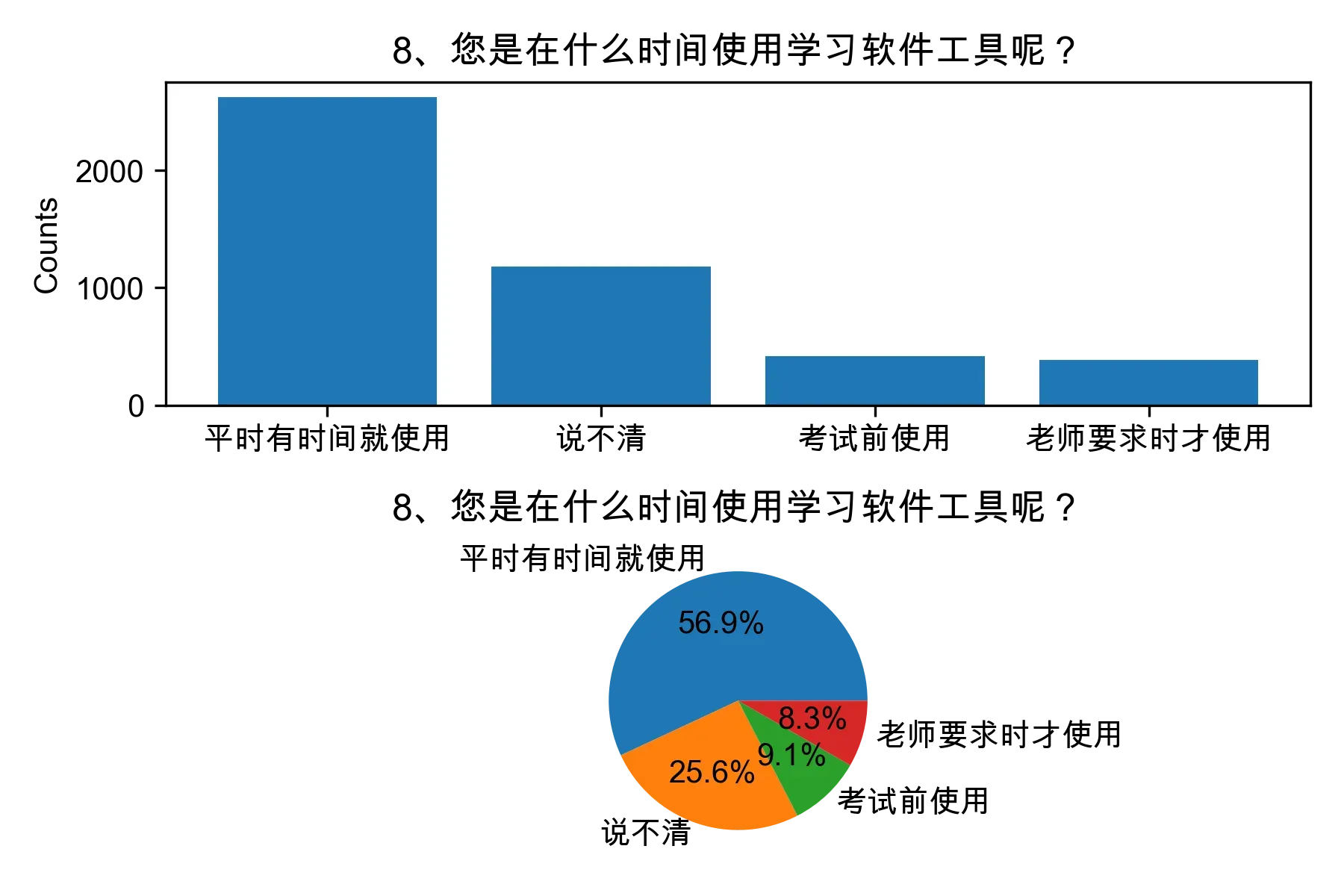
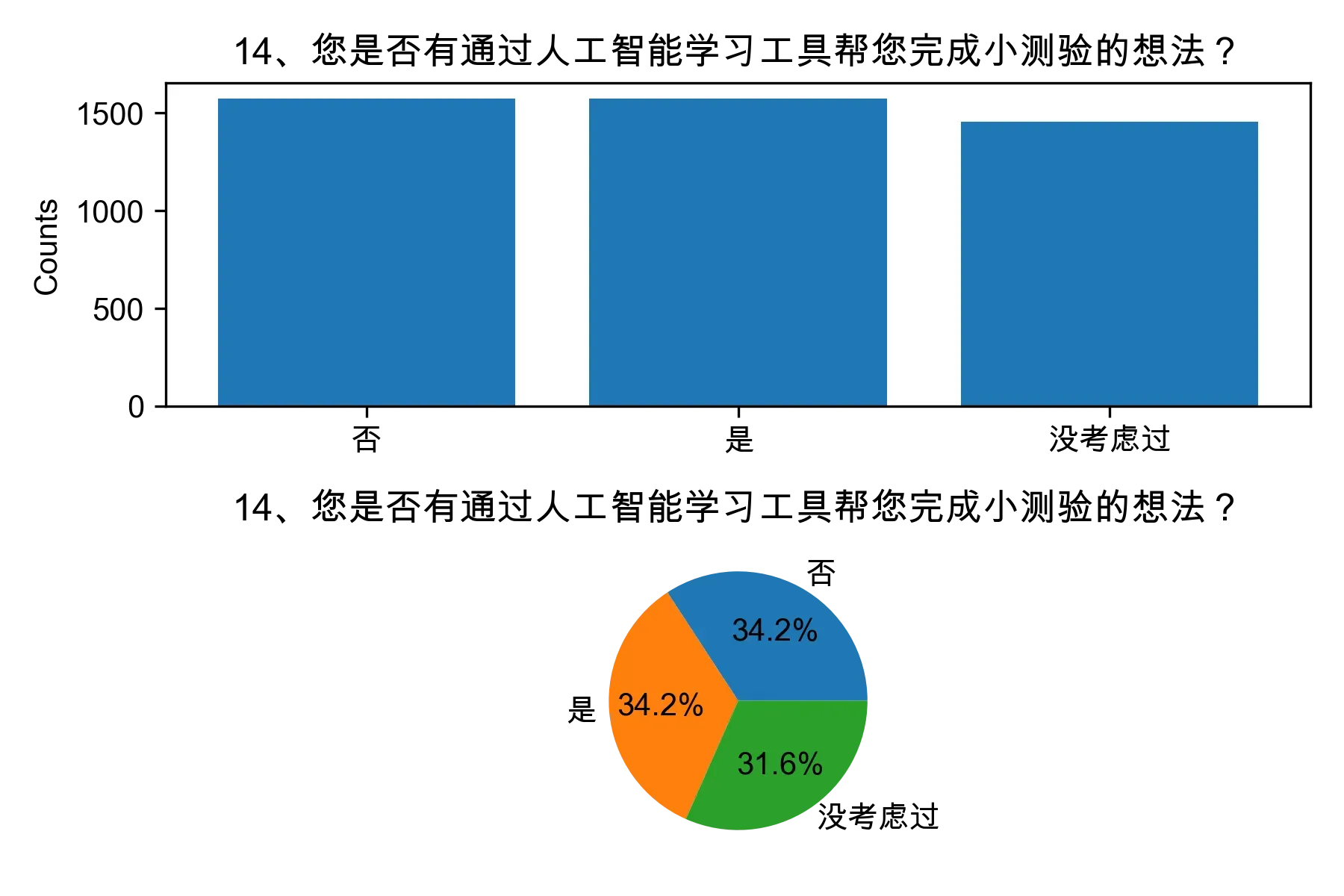
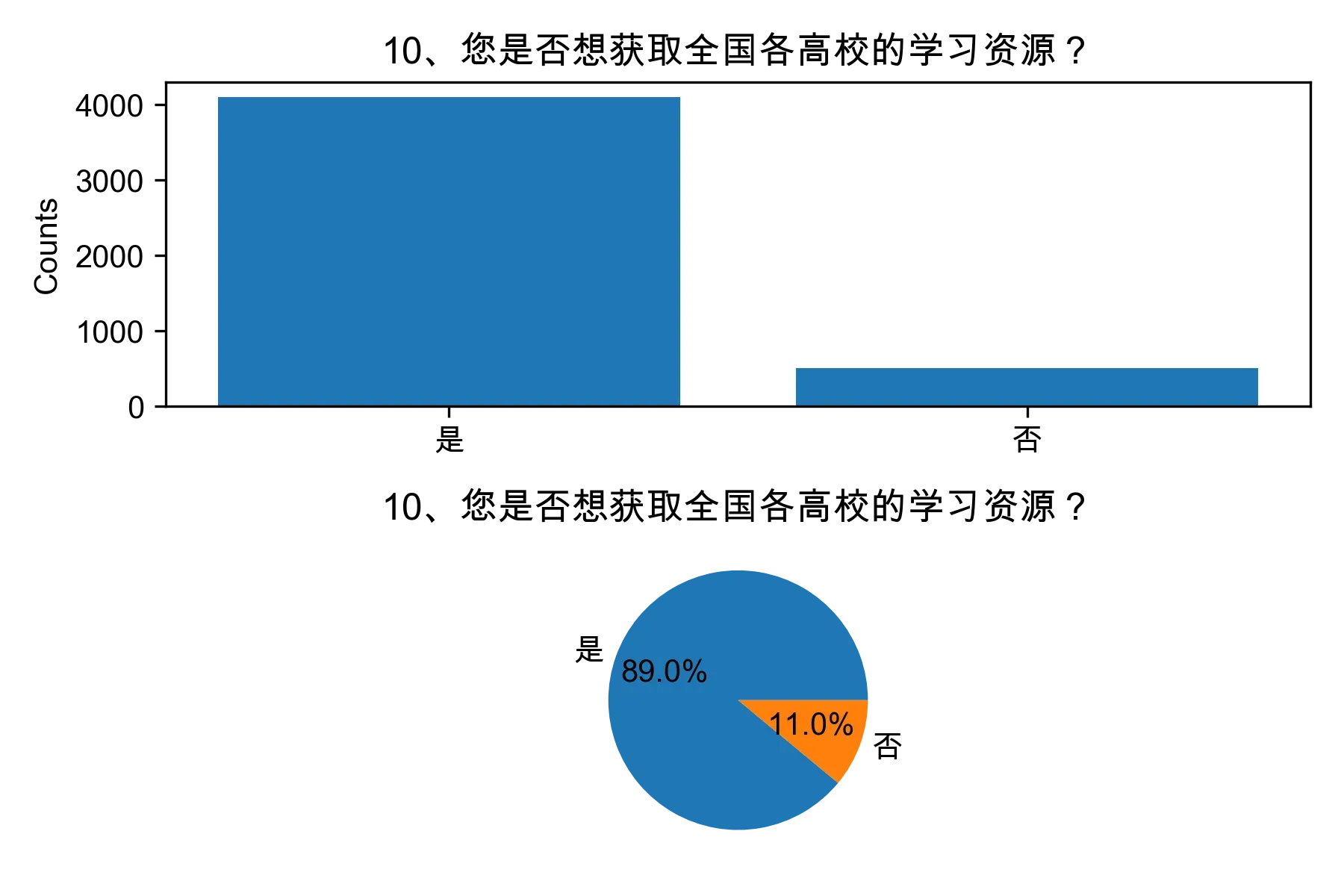
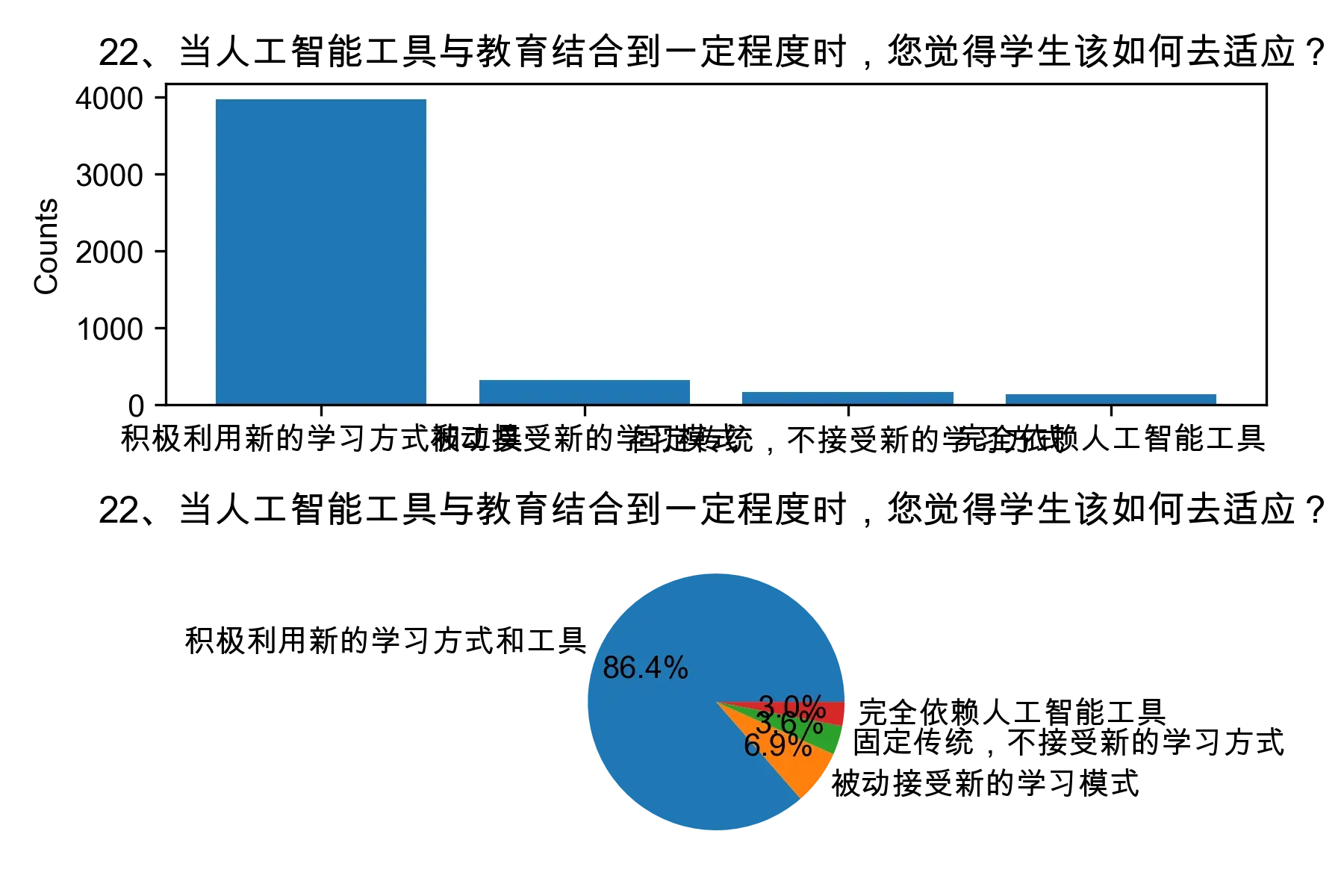
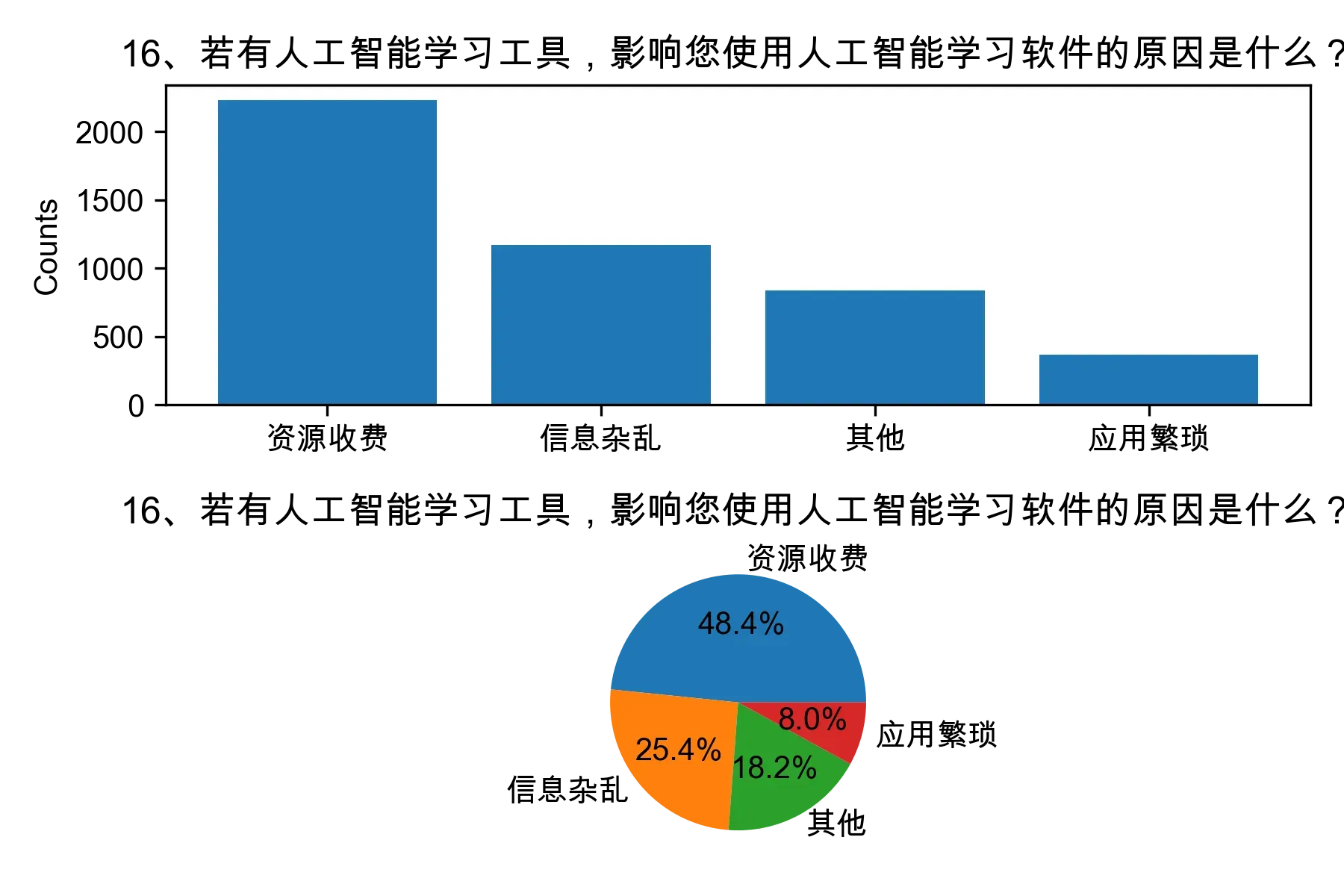
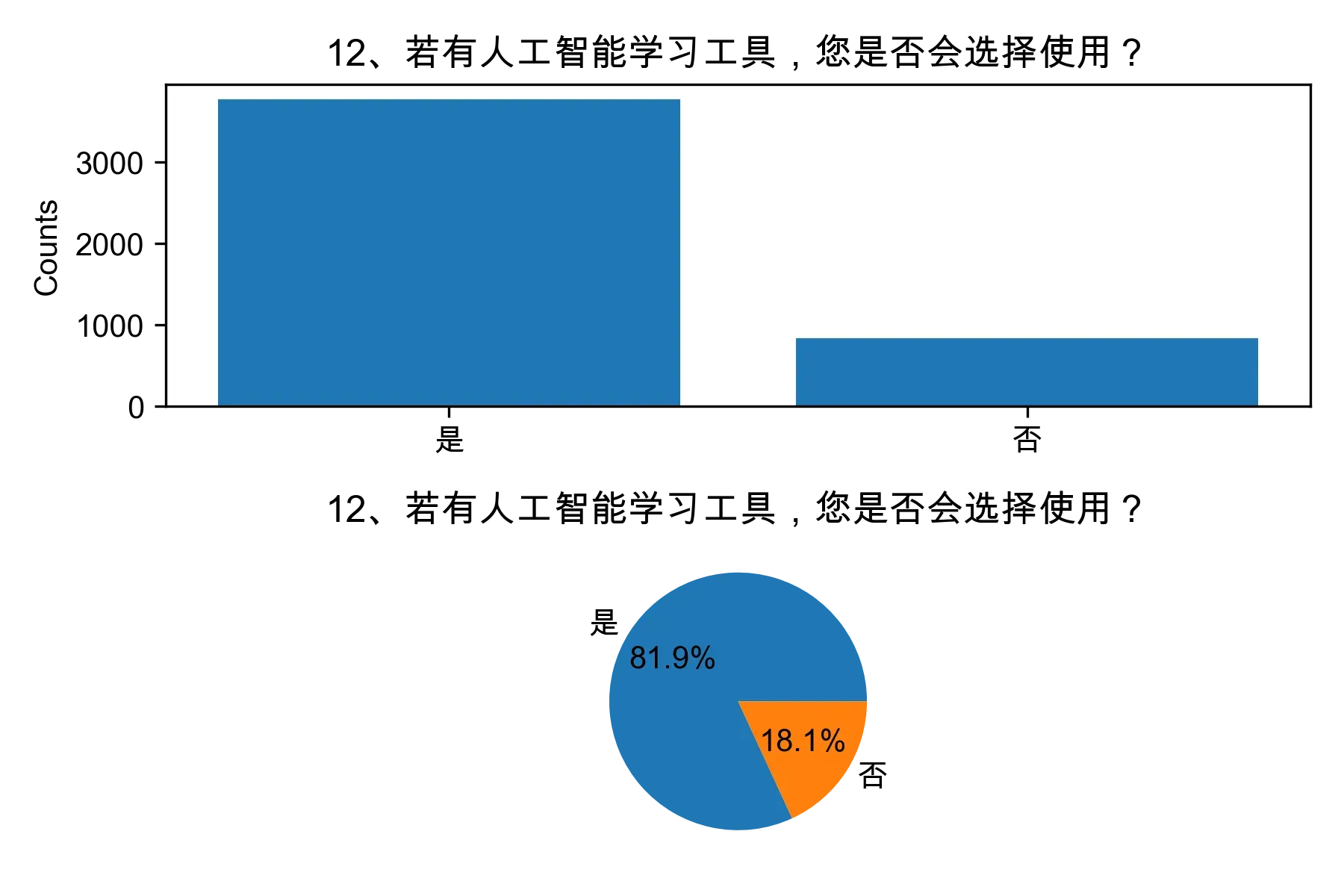
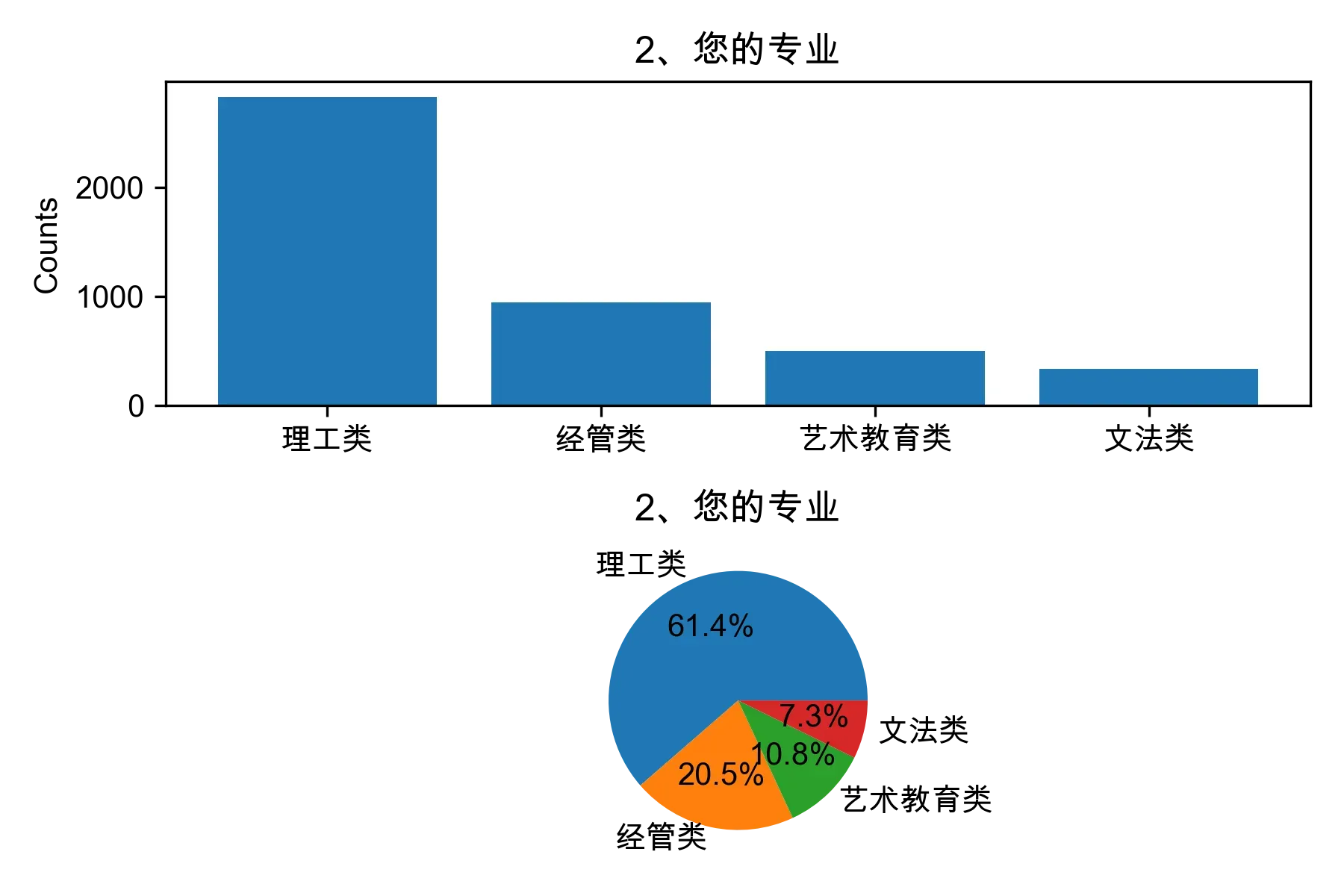
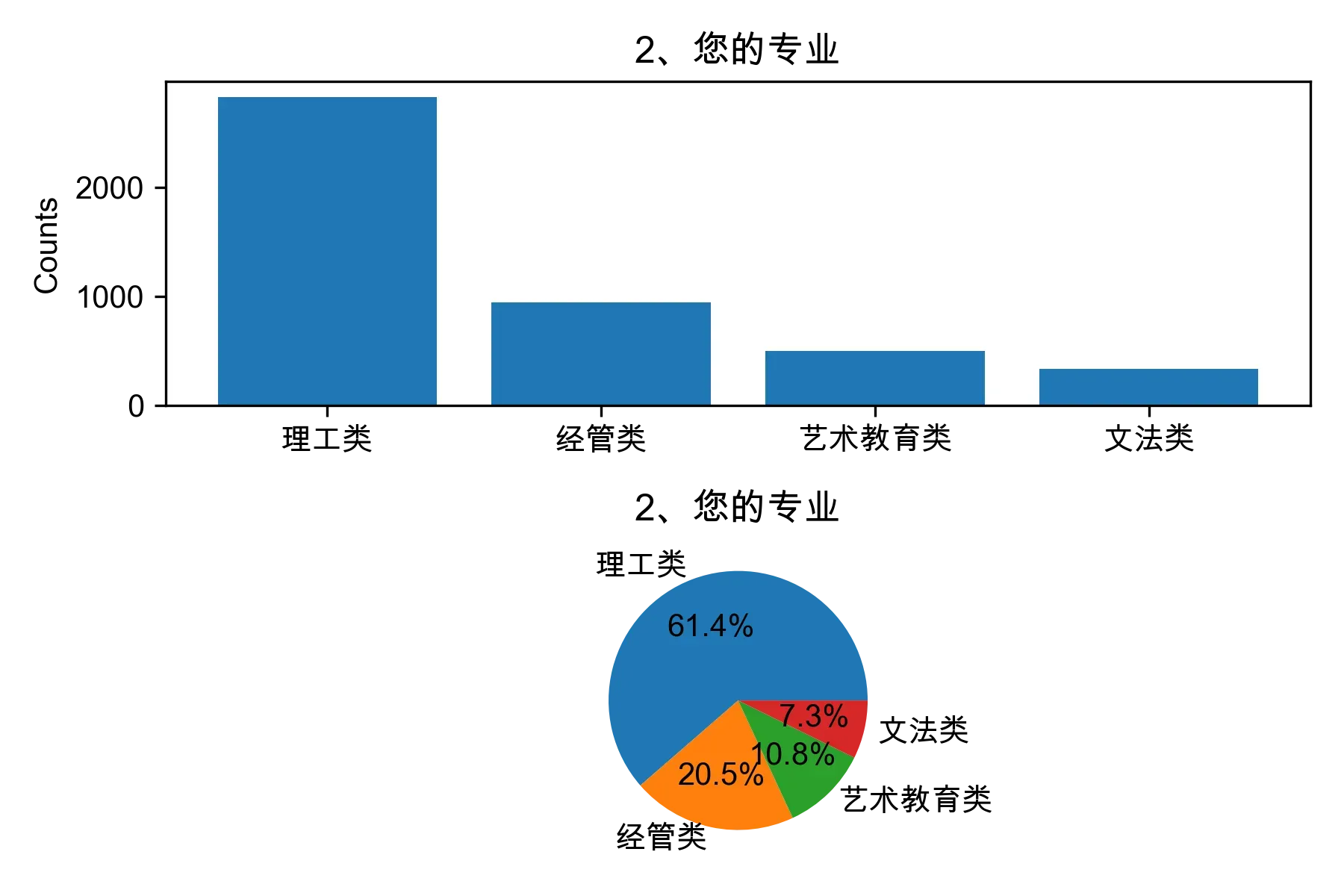
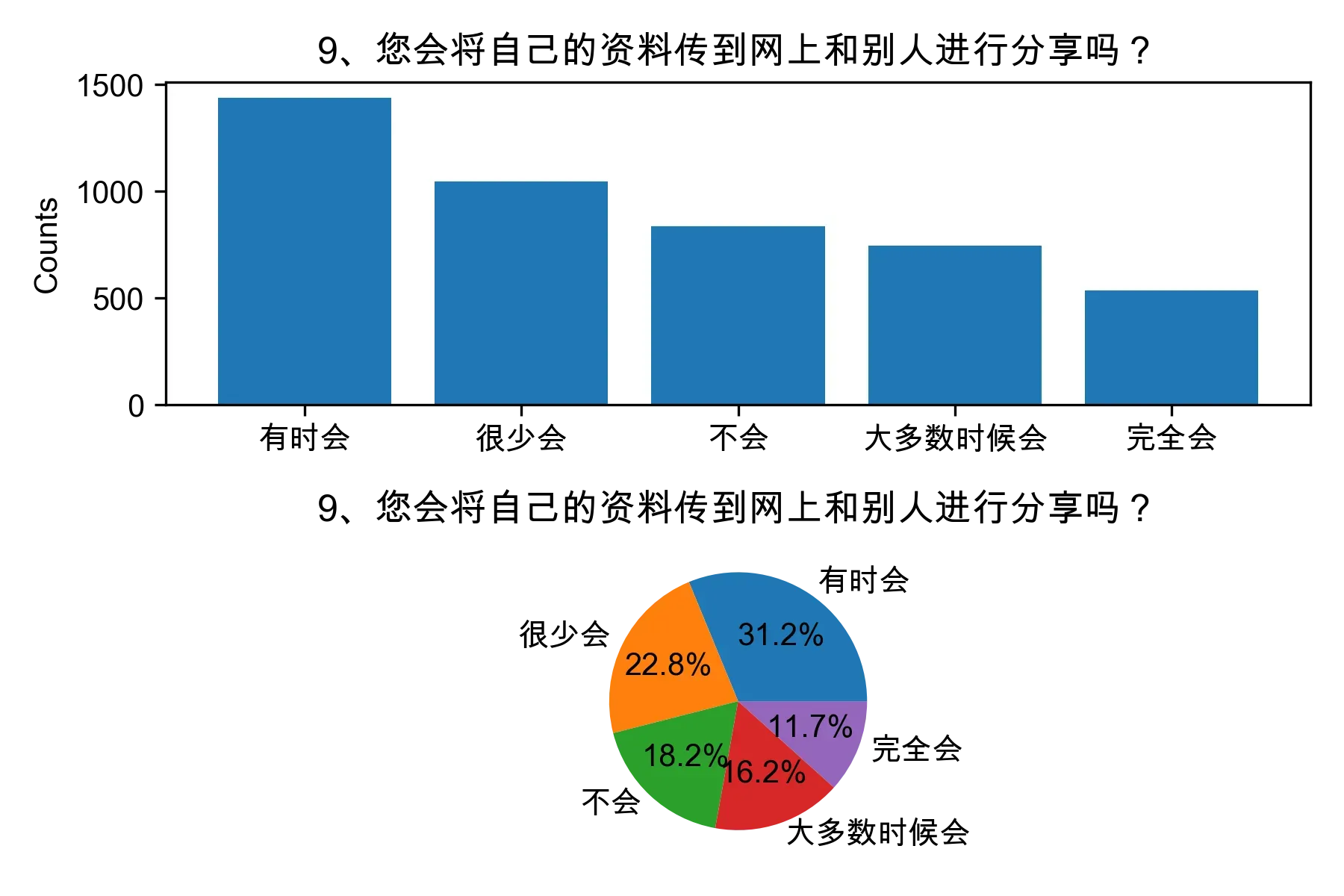
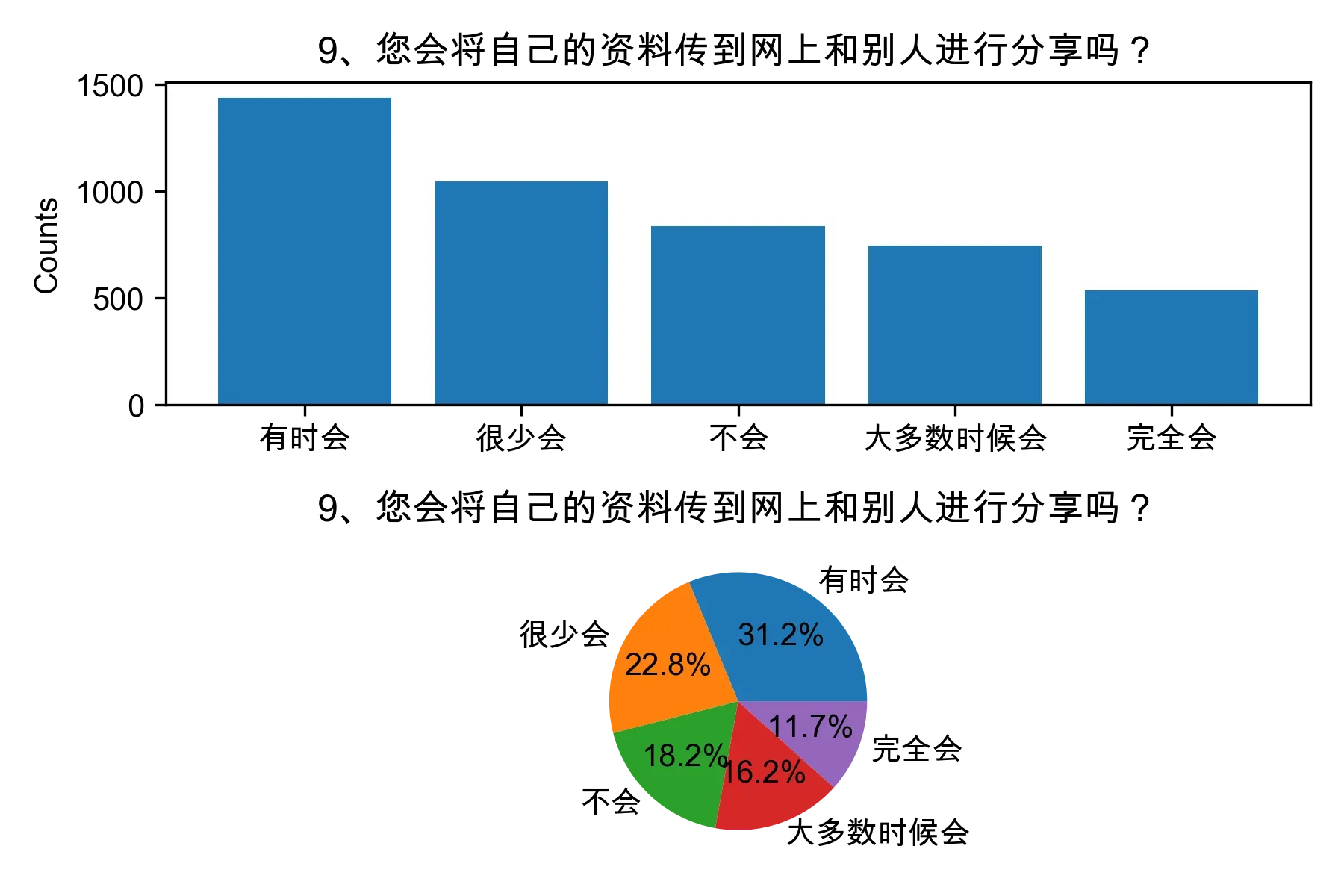
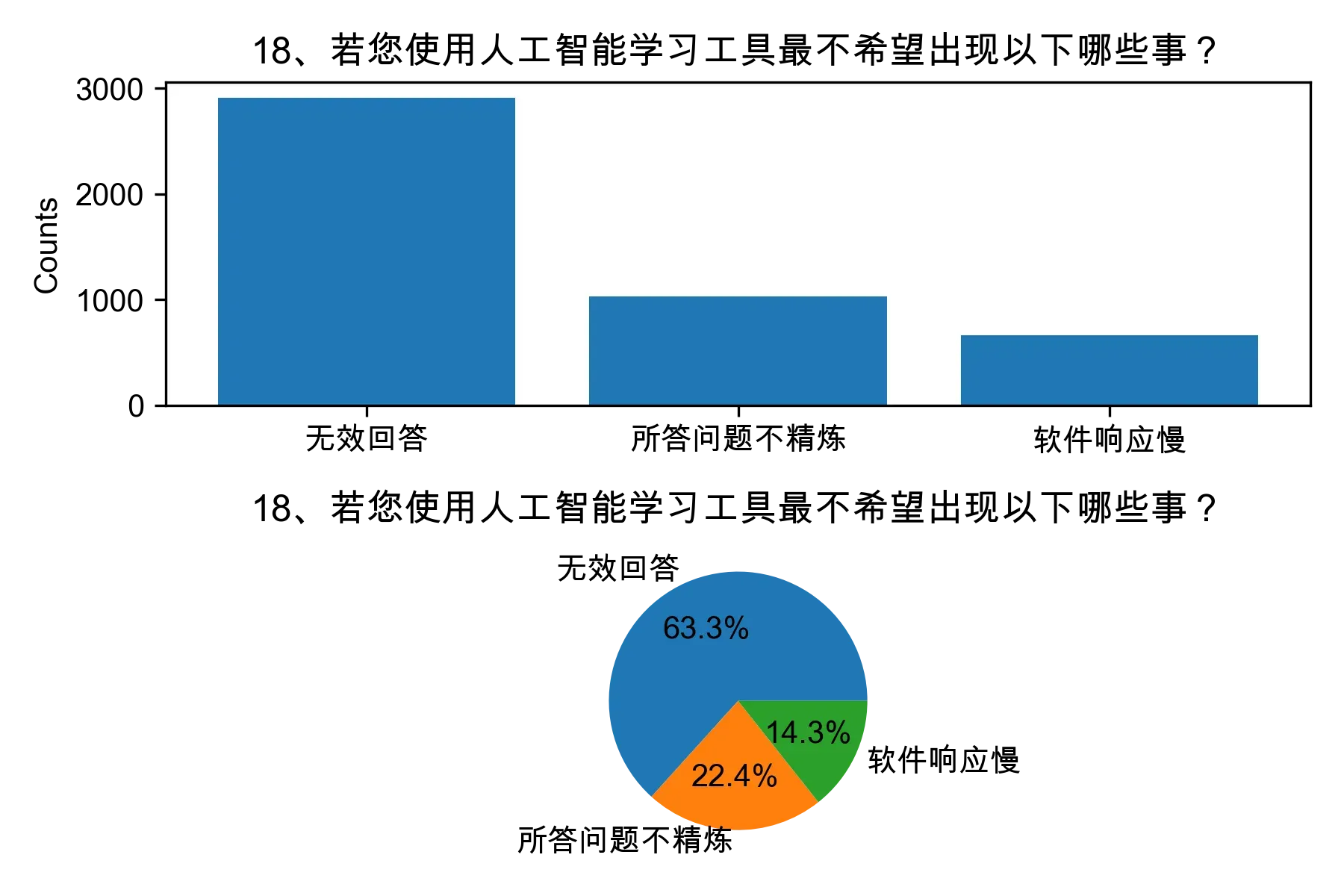
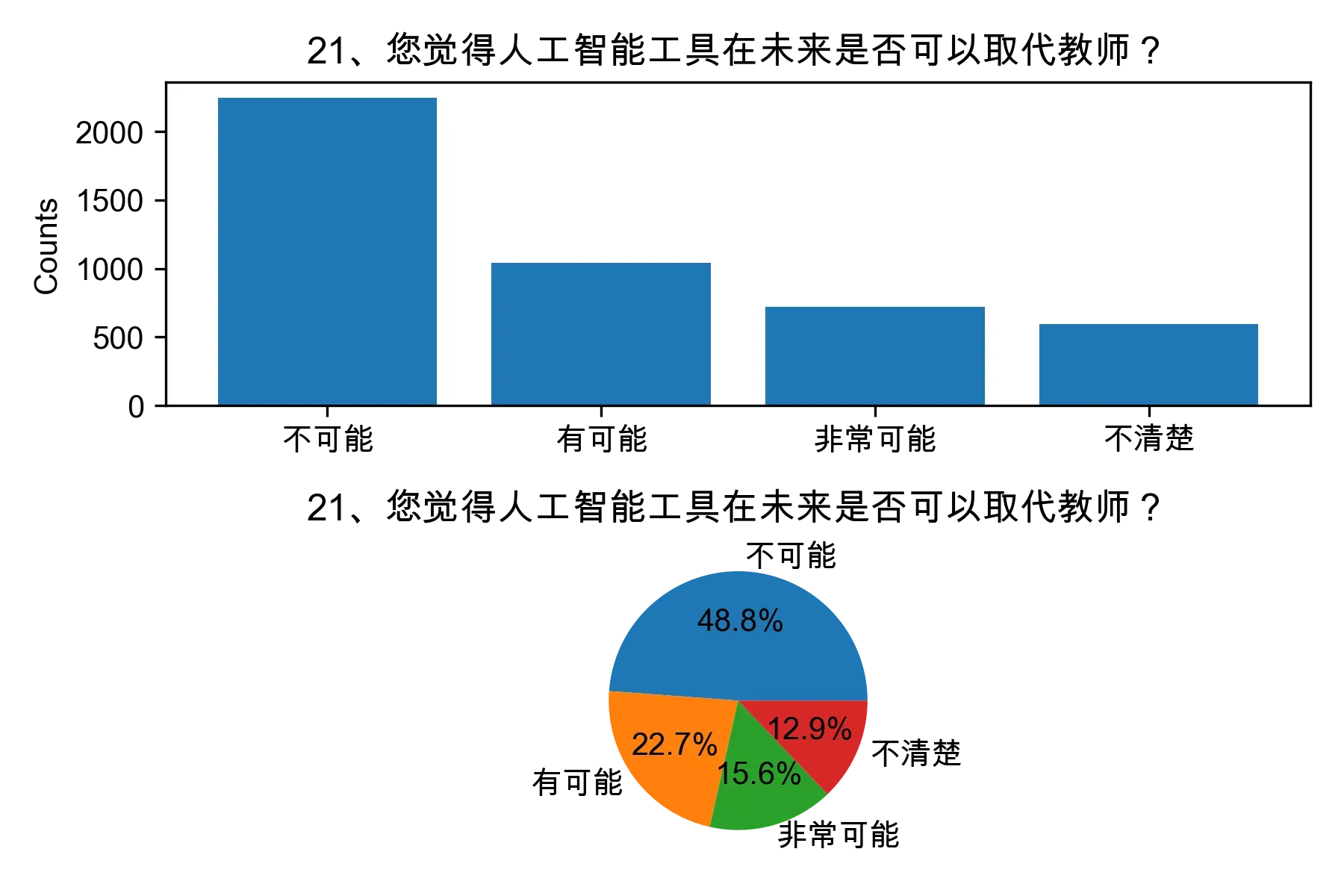
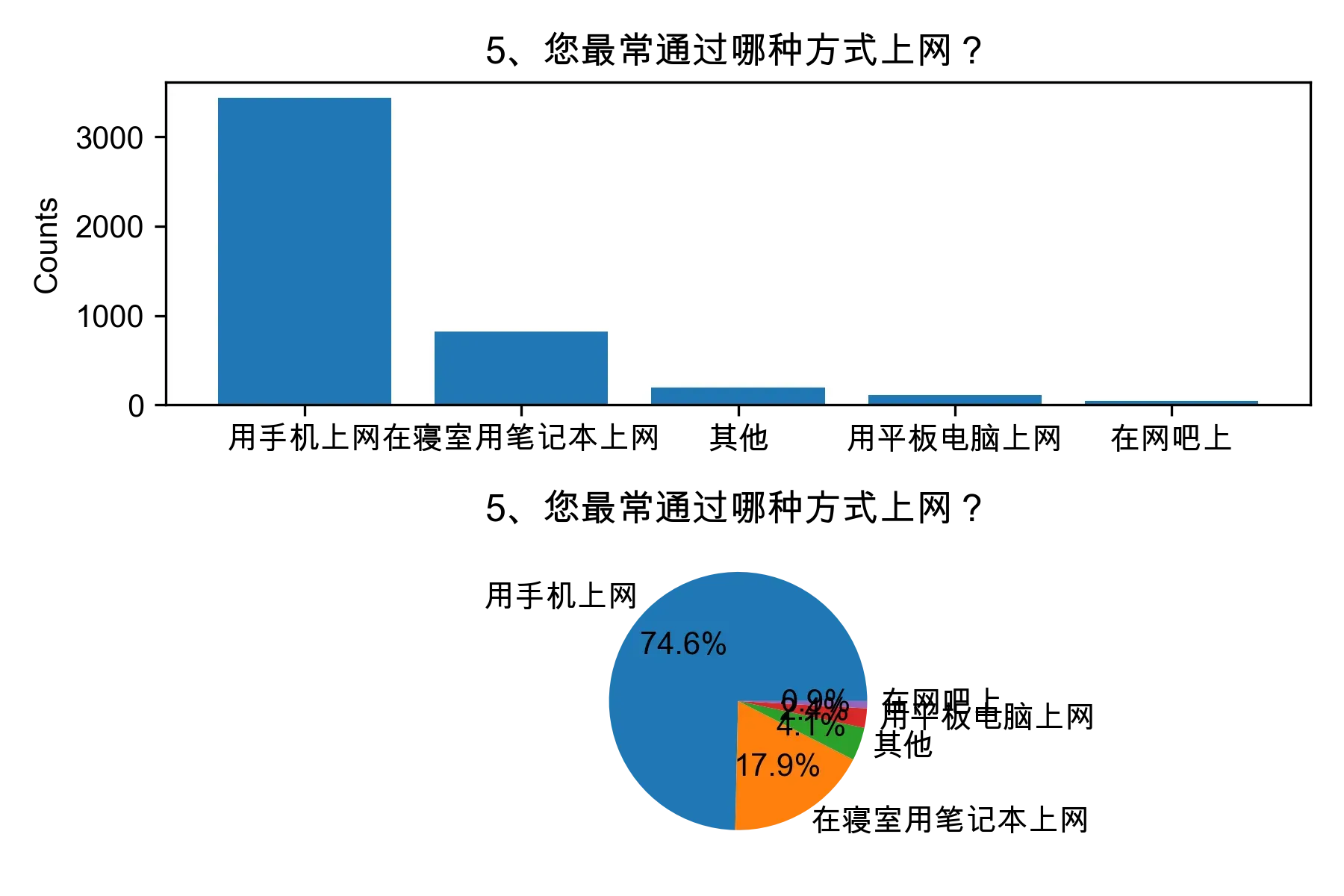
from collections import Counter, defaultdict
from itertools import chain
import numpy as np
cols = df.columns
i = 1
for col in df.columns:
# 将每一列的数据按照分隔符进行分割
df[col] = df[col].apply(lambda x: x.split('┋') if isinstance(x, str) else x)
element_count_dict = defaultdict(int)
for row in df[col]:
element_count = Counter(row)
for element, count in element_count.items():
element_count_dict[element] += count
# 将 defaultdict 转换为普通字典
。。。略,请下载完整代码
percentages = [i/ np.sum(counts) * 100 for i in counts]
# 绘制各题目的直方图和饼图
plt.subplot(2, 1, 1)
plt.bar(element_count_dict.keys(), element_count_dict.values())
plt.title(col)
plt.ylabel("Counts")
plt.subplot(2, 1, 2)
plt.pie(percentages, labels=element_count_dict.keys(), autopct="%1.1f%%")
plt.tight_layout()
plt.savefig(f'img/{i+23}.png',dpi=300)
i+=1
plt.show()
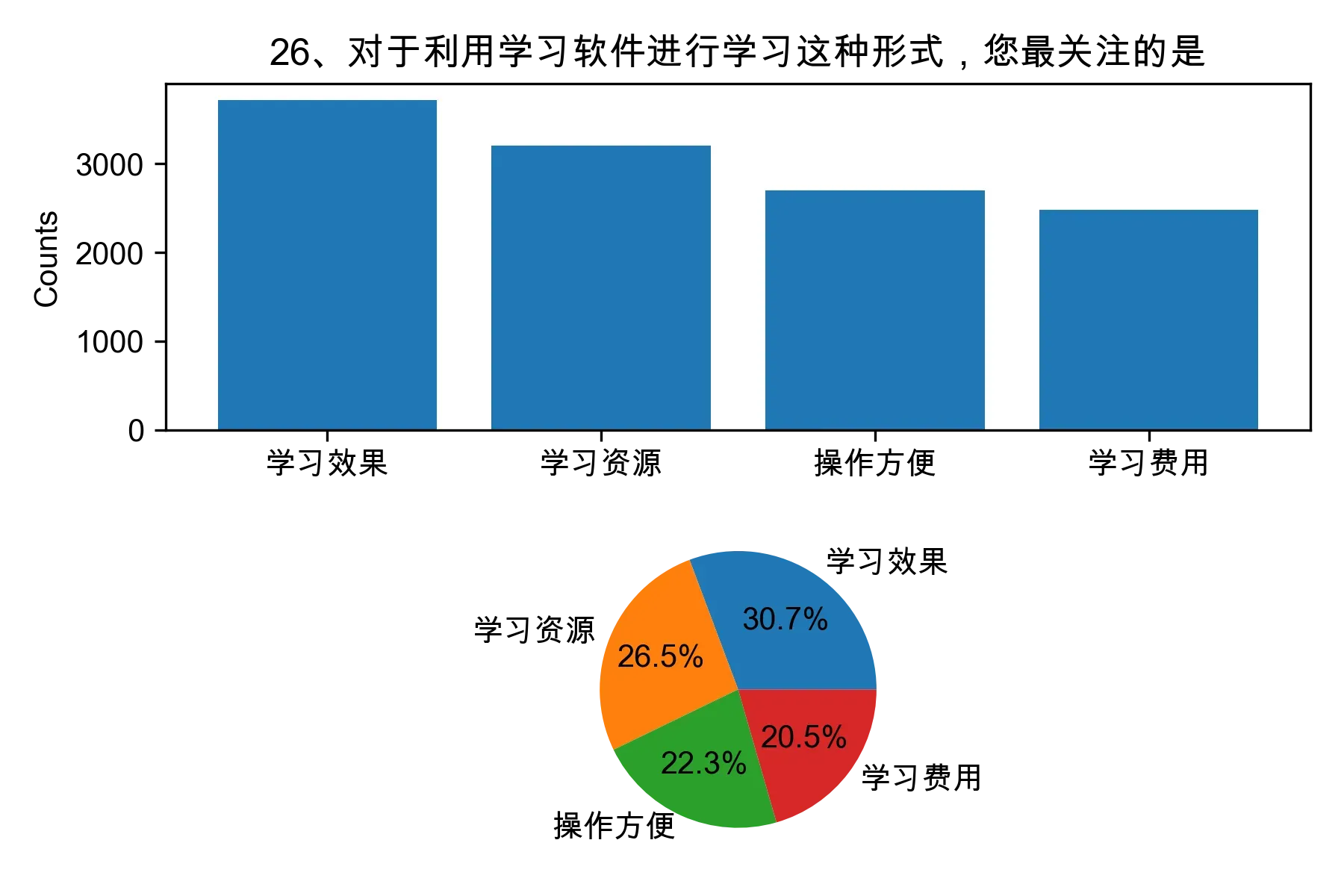
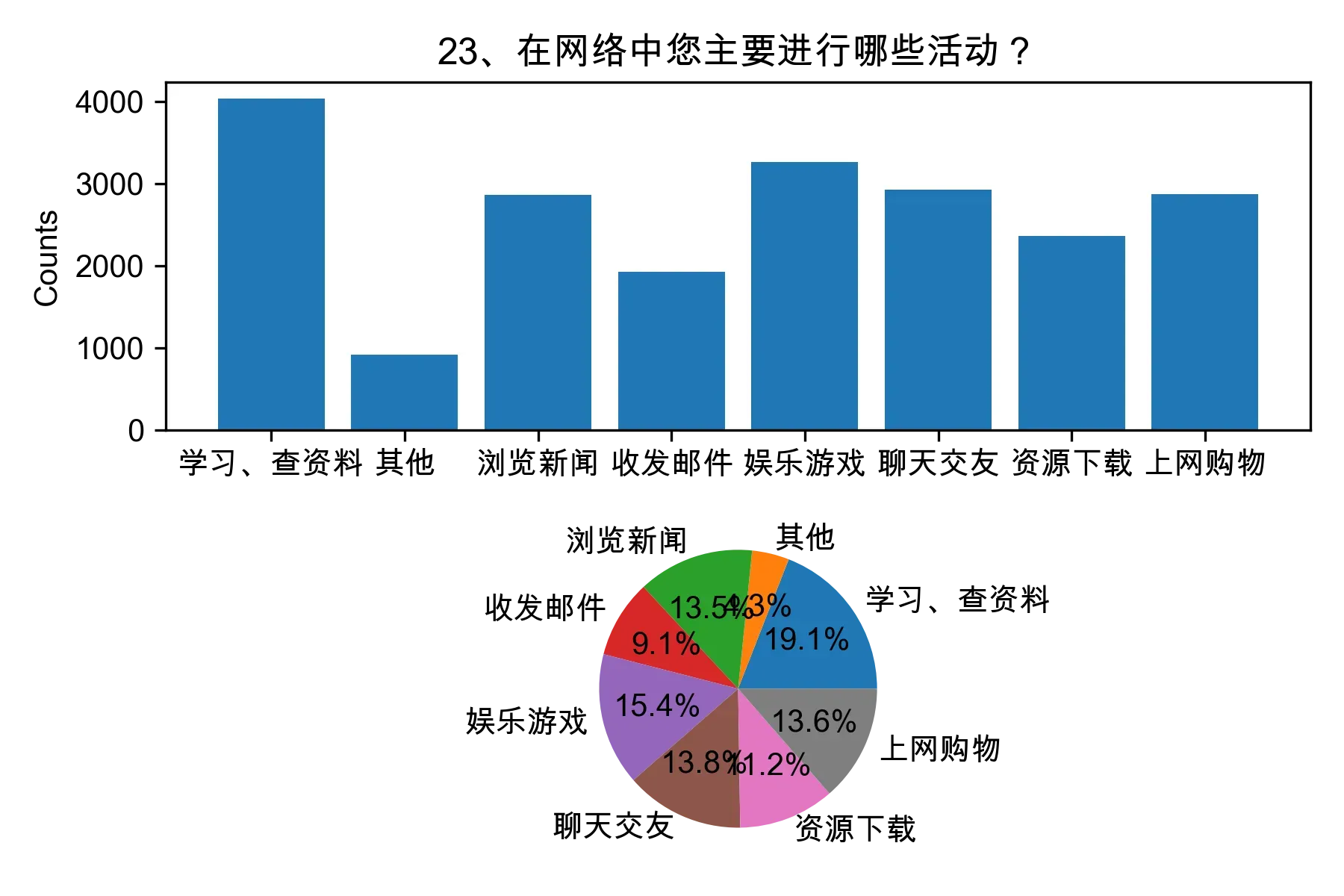
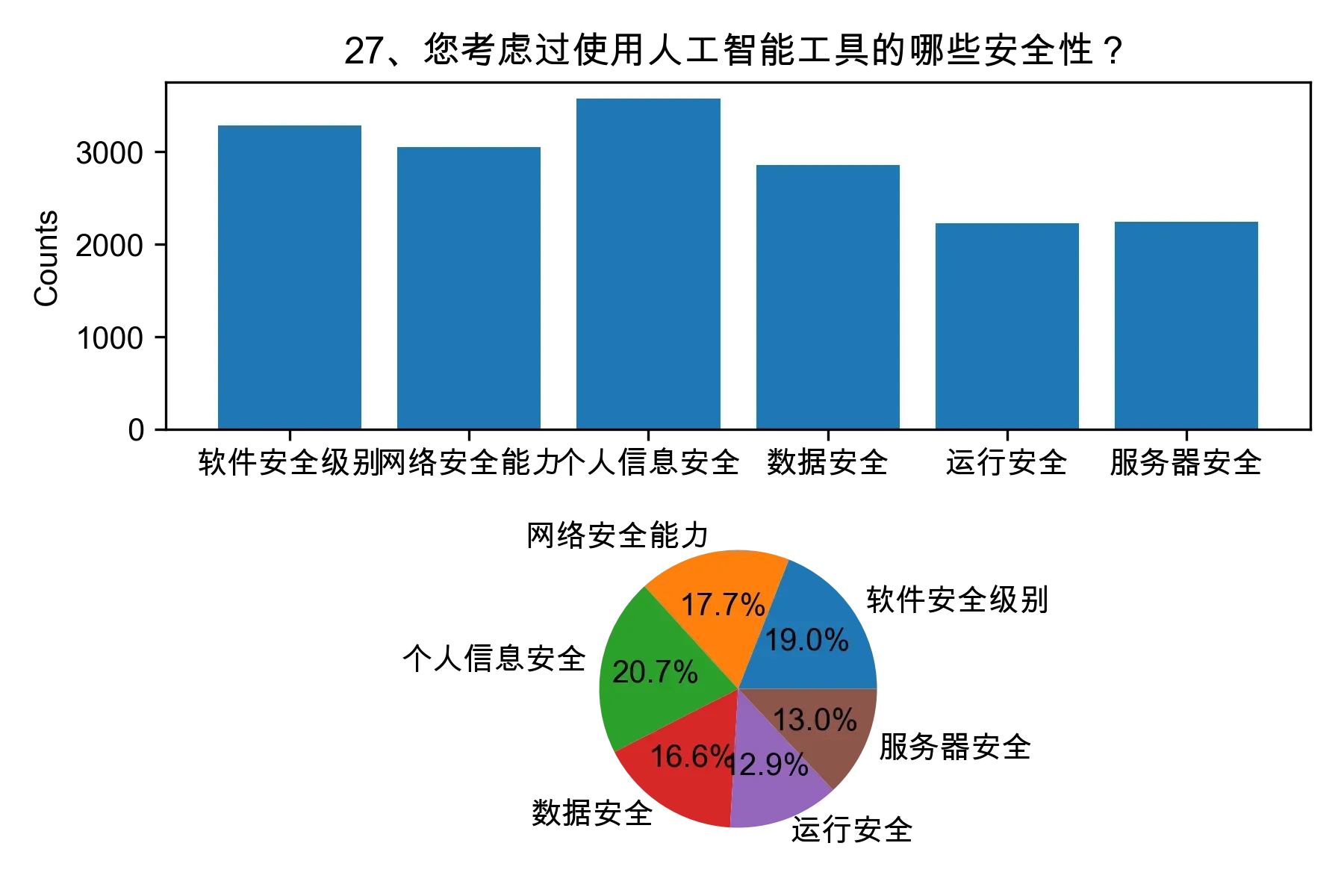
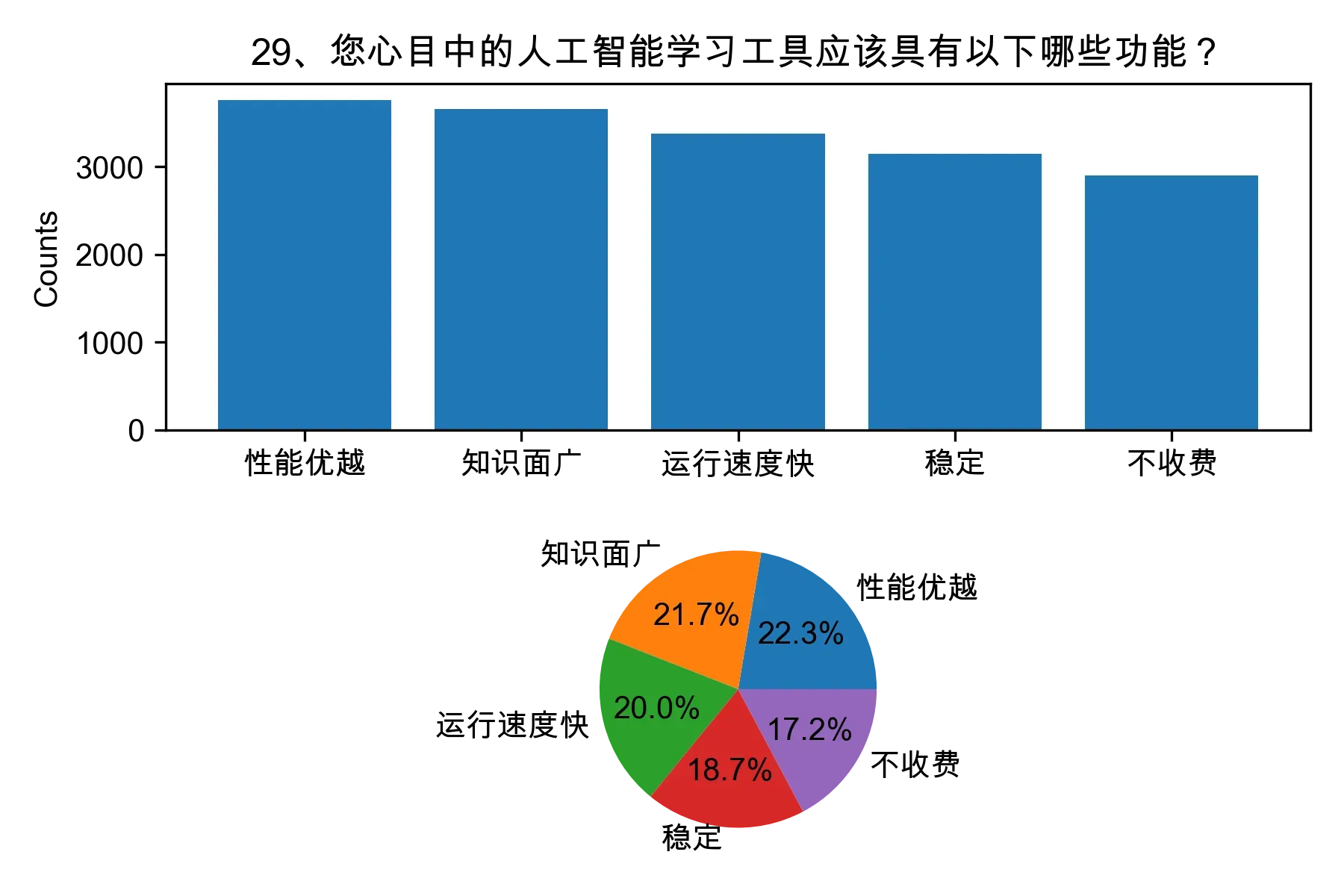
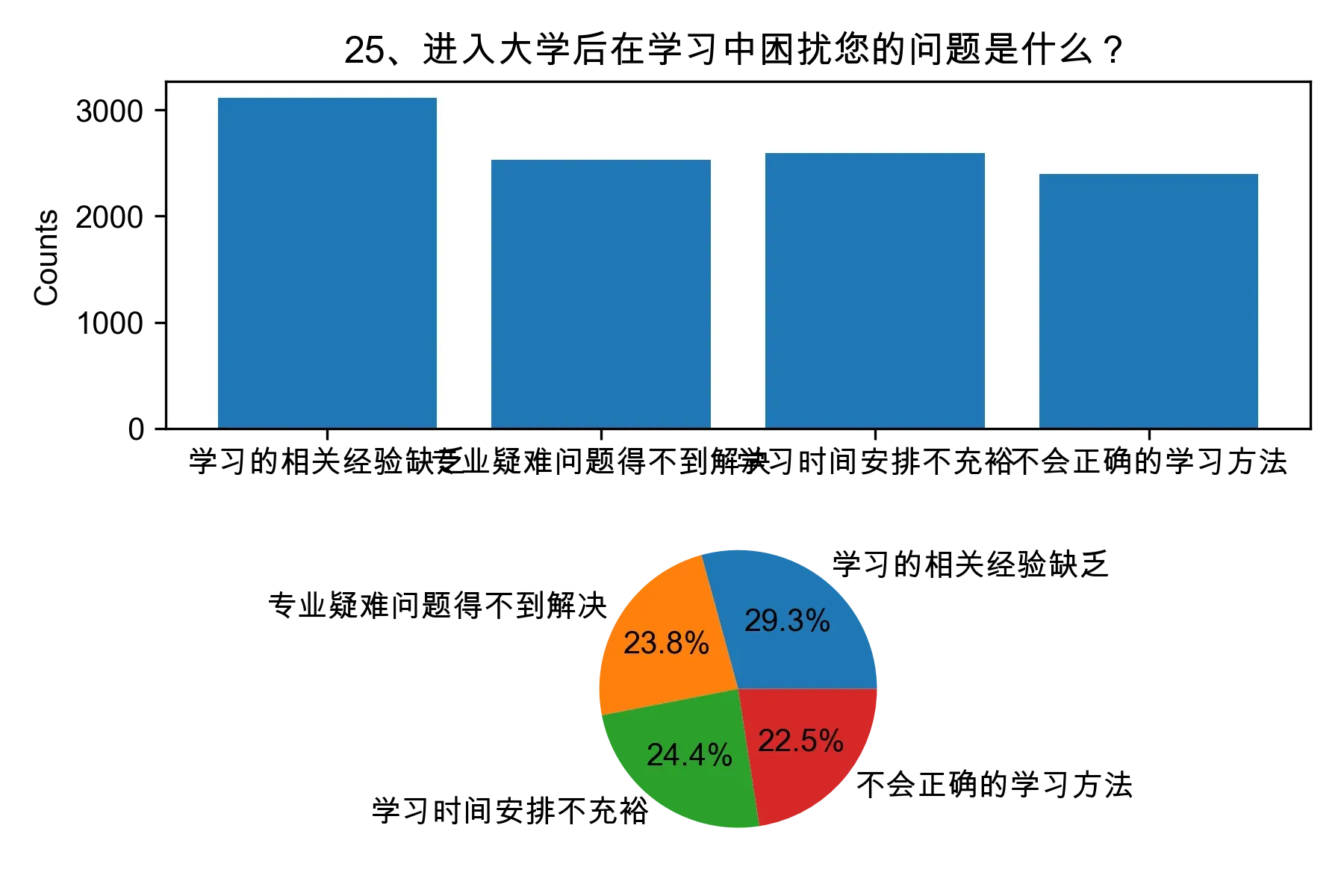
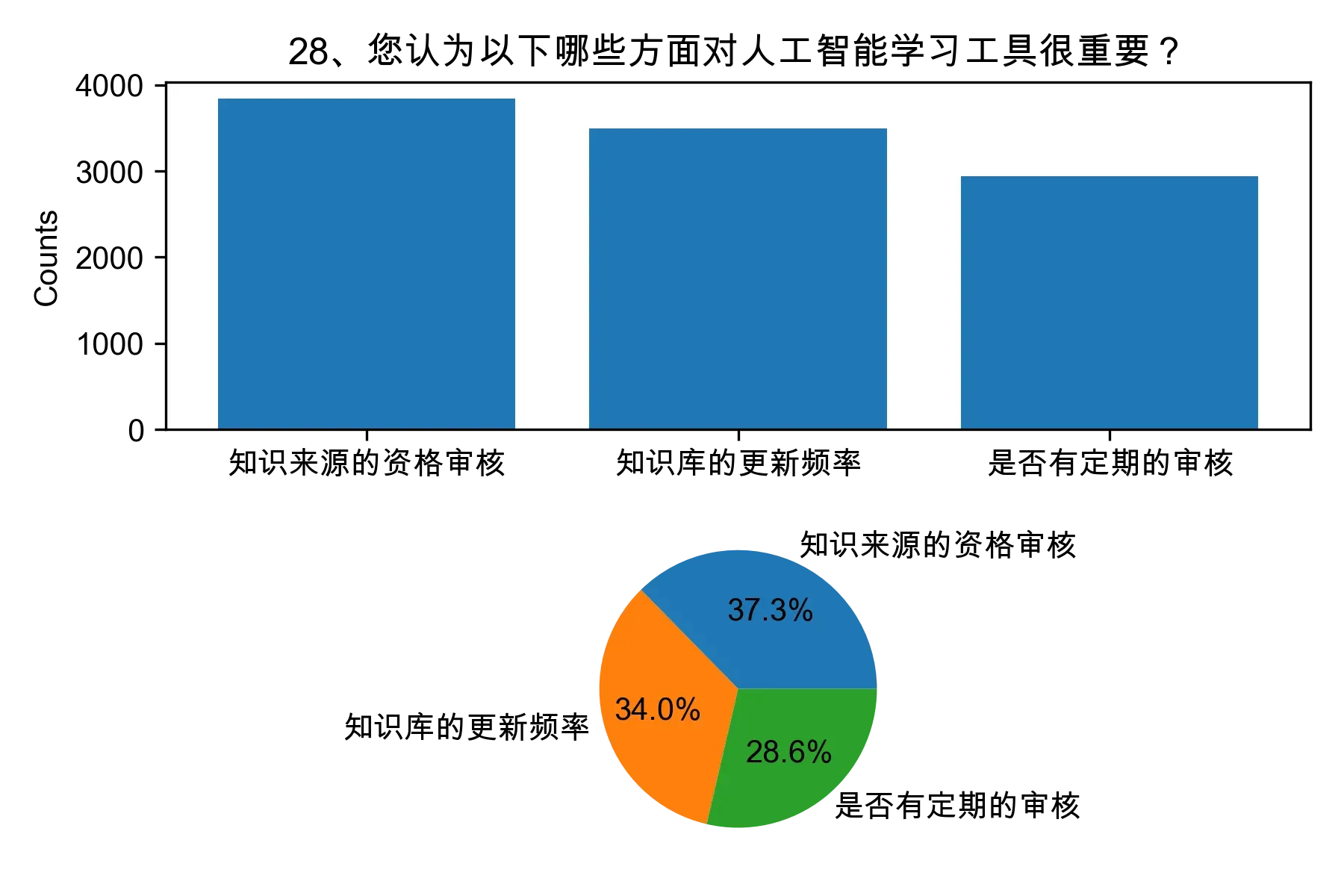
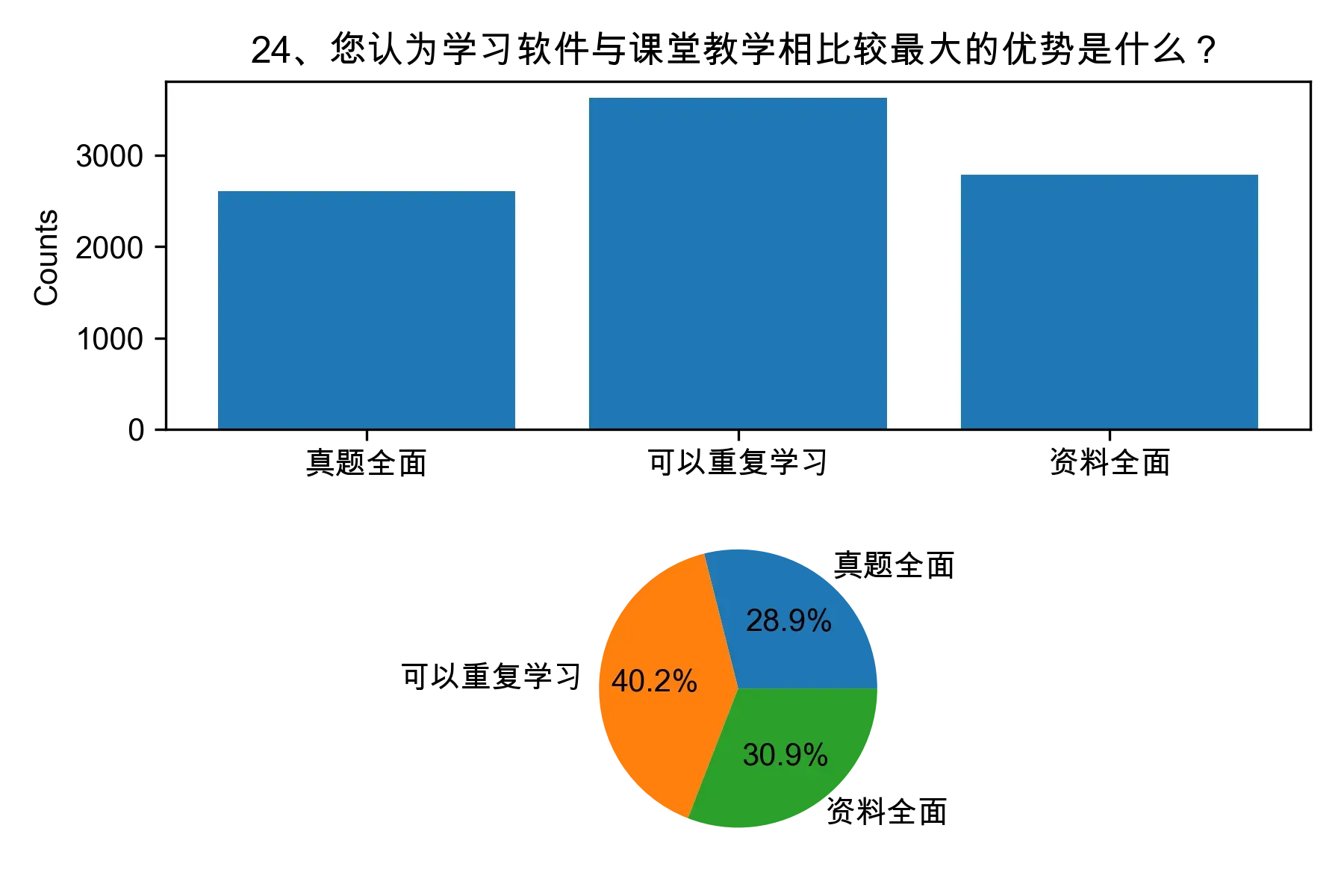
3.2 问题二
持续更新中
3.3 问题三
持续更新中
4 完整下载
查看知乎文章底部,或者私信我
文章出处登录后可见!