最近几乎所有的热点都被chatgpt占据,相信大家都对chatgpt已经不陌生了,最近我也看了一些,总结了一些关于大模型的资料,有些不足或者建议,欢迎大家指正。
什么是AI大模型?
AI大模型就是Foundation Model(基础模型),指通过在大规模宽泛的数据上进行训练后能适应一系列下游任务的模型。(Foundation Model名词来源李飞飞等众学者的这篇论文On the Opportunities and Risks of Foundation Models)。
AI大模型是人工智能迈向通用智能的里程碑技术。深度学习作为新一代人工智能的标志性技术,完全依赖模型自动从数据中学习知识,在显著提升性能的同时,也面临着通用数据激增与专用数据匮乏的矛盾。AI大模型兼具“大规模”和“预训练”两种属性,面向实际任务建模前需在海量通用数据上进行预先训练,能大幅提升AI的泛化性、通用性、实用性。
大模型发展
AI大模型发展起源于自然语言处理领域。在2017年Transformer网络提出后,伴随着参数量的不断提升,它在自然语言处理领域慢慢成为基础性架构,并在2018年其参数量达到3亿规模,也就是我们所熟知的BERT。基于如此之大的参数量,研究者发现它能够同时出色地完成多种自然语言处理任务,这也就吸引了越来越多的人加入其中。
在大模型研究的早期阶段,仍然主要集中在自然语言处理领域,诞生了诸如上述BERT、GPT-3等一系列代表性模型,它们的参数量从起初的几亿,快速增长为数十亿乃至千亿规模。而随之带来的就是相应能力的提升,具备了从简单的文本问答、文本创作到符号式语言的推理能力;近两年,部分研究者提出了以其他模态(如视觉等)为基础的大模型研究,希望模型也可以看懂世间万物。在这个阶段,诞生了如ViT等包含数亿参数规模的视觉模型。 上述模型分别具备了读的能力和看的能力,研究者期望将这两类能力统一起来,具备如大脑体现的多模态感知能力,这一部分的代表性模型就是CLIP、DALL·E等模型。
更多的多模态模型介绍详见 https://zhuanlan.zhihu.com/p/460512128
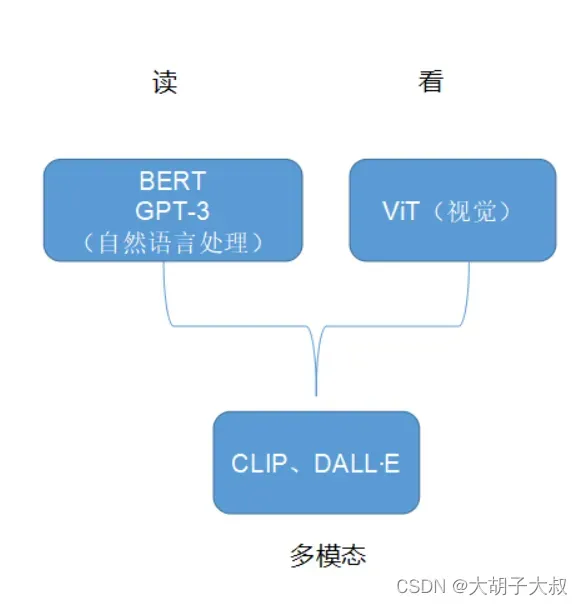
主流大模型
(1)BERT:谷歌于2018年10月发布的BERT模型是最为典型的基础模型,它利用BooksCorpus和英文维基百科里纯文字的部分,无须标注数据,用设计的两个自监督任务来做训练,训练好的模型通过微调在11个下游任务上实现最佳性能。
(2)谷歌2021年发布的视觉迁移模型Big Transfer,BiT
(3)OpenAI在2020年5月发布的GPT-3则是一个自回归语言模型,具有1750亿参数,在互联网文本数据上训练得到的这一基础模型,可以使用提示的例子完成各式各样的任务,使用描述任务(如“把英文翻译成法语:”)加一个示例(如“sea otter => loutre de mer”),再给一个prompt提示(如“cheese =>”),GPT-3模型即可生成cheese对应的法文。这类模型正在成为主流的AI范式。
以GPT系列为例:
1)GPT-1是上亿规模的参数量,数据集使用了1万本书的BookCorpus,25亿单词量;
2)GPT-2参数量达到了15亿规模,其中数据来自于互联网,使用了800万在Reddit被链接过的网页数据,清洗后越40GB(WebText);
3)GPT-3参数规模首次突破百亿,数据集上将语料规模扩大到570GB的CC数据集(4千亿词)+WebText2(190亿词)+BookCorpus(670亿词)+维基百科(30亿词)。
(4)Google 去年提出了 FLAN,一个基于 finetune 的 GPT 模型。它的模型结构和 GPT 相似。但是不同于 GPT-3 的是,它基于 62 个数据集,每个数据集构造了 10 个 Prompt 模板,也就是总共拿到 620 个模板的数据之后再进行 finetune。
更多介绍在此链接 https://zhuanlan.zhihu.com/p/545709881
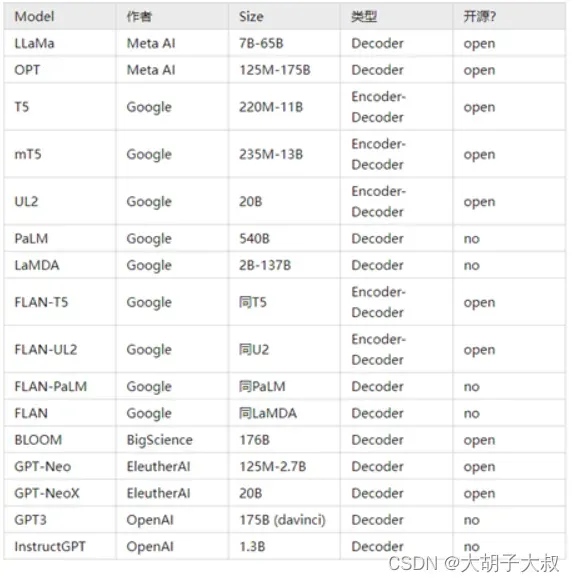
国外大模型一览表
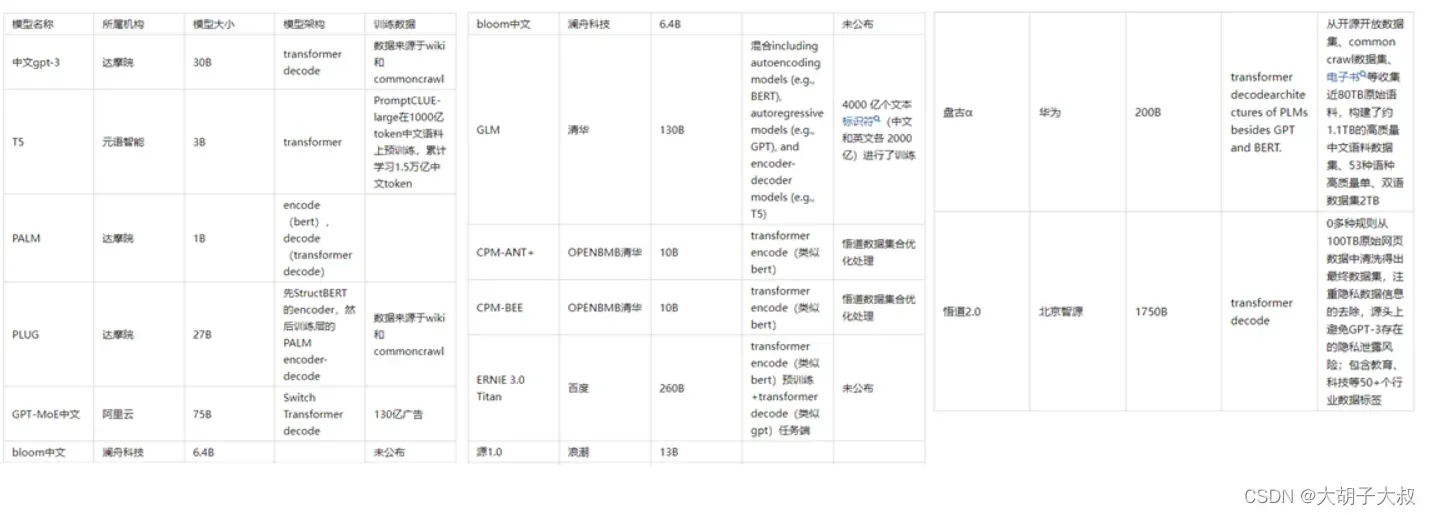
国内大模型发展情况
2021年4月,华为云联合循环智能发布盘古NLP超大规模预训练语言模型,参数规模达1000亿;联合北京大学发布盘古α超大规模预训练模型,参数规模达2000亿。 阿里达摩院发布270亿参数的中文预训练语言模型PLUG,联合清华大学发布参数规模达到1000亿的中文多模态预训练模型M6。
2021年6 月,北京智源人工智能研究院发布了超大规模智能模型“悟道 2.0”,参数达到 1.75 万亿,成为当时全球最大的预训练模型。
2021年7月,百度推出ERNIE 3.0 知识增强大模型,参数规模达到百亿。
2021年10月,浪潮发布约2500亿的超大规模预训练模型“源1.0”。 2021年12月,百度推出ERNIE 3.0 Titan模型,参数规模达2600亿。而达摩院的M6模型参数达到10万亿,将大模型参数直接提升了一个量级。
到2022年,大模型继续火热。最开始,大模型是集中在计算语言领域,但如今也已逐渐拓展到视觉、决策,应用甚至覆盖蛋白质预测、航天等等重大科学问题,谷歌、Meta、百度等等大厂都有相应的成果。
国内大模型一览表
大模型与传统模型比对
| AI大模型 | 传统的AI模型 | |
| 1 | AI大模型得益于其“大规模预训练﹢微调”的范式,可以很好地适应不同下游任务,展现出它强大的通用性 | 由于数据规模或是模型表达能力的约束,这些模型往往只能有针对性地支持一个或者一类任务,而无法支持其他任务 |
| 2 | AI大模型预先在海量通用数据上训练并具备多种基础能力,可结合多种垂直行业和业务场景需求进行模型微调和应用适配 | 传统AI能力碎片化、作坊式开发 |
| 3 | AI大模型已成为上层应用的技术底座,能够有效支撑智能终端、系统、平台等产品应用落地 | 传统AI应用过程中存在的壁垒多、部署难 |
| 4 | 在共享参数的情况下,只需在不同下游实验中做出相应微调就能得到优越的表现 | 传统AI模型存在难以泛化到其他任务上的局限性 |
| 5 | 自监督学习方法,可以减少数据标注,并且模型参数规模越大,优势越明显,避免开发人员再进行大规模的训练,使用小样本就可以训练自己所需模型,极大降低开发使用成本。 | 人工标注成本高、周期长、准确度不高 |
| 6 | 有望进一步突破现有模型结构的精度局限 |
模型精度–传统模型
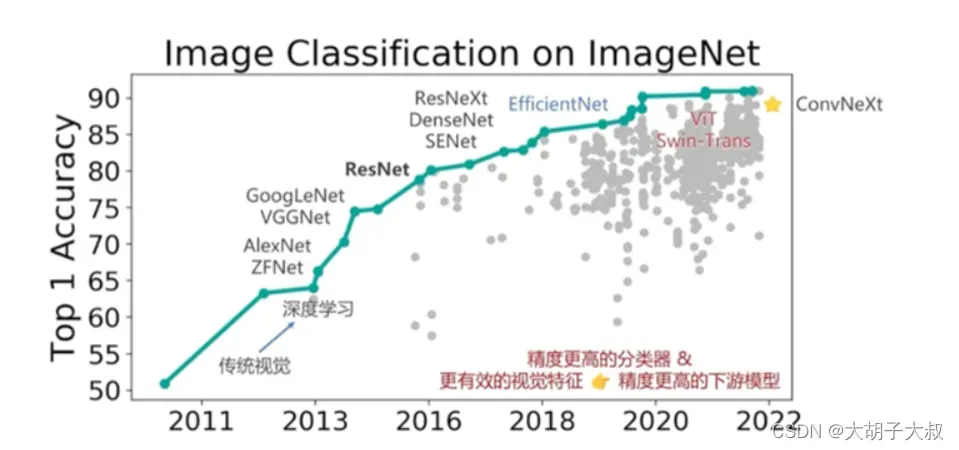
从深度学习发展前10年的历程来看,模型精度提升,主要依赖网络在结构上的变革。 例如,从AlexNet到ResNet50,再到NAS搜索出来的EfficientNet,ImageNet Top-1 精度从58提升到了84。但是,随着神经网络结构设计技术,逐渐成熟并趋于收敛,想要通过优化神经网络结构从而打破精度局限非常困难。
模型精度–Bit模型精度
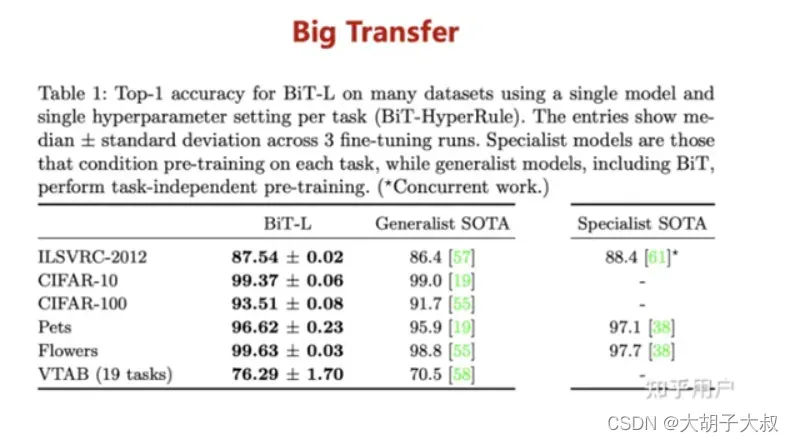
以谷歌2021年发布的视觉迁移模型Big Transfer,BiT为例。扩大数据规模也能带来精度提升,例如使用ILSVRC-2012(128 万张图片,1000 个类别)和JFT-300M(3亿张图片,18291个类别)两个数据集来训练ResNet50,精度分别是77%和79%。另外使用 JFT-300M训练ResNet152x4,精度可以上升到87.5%,相比ILSVRC-2012+ResNet50结构提升了10.5%。
(下图)通过模型参数来看大模型在参数规模变大时对精度的影响,彩色文字是对数据集的注释。

算力需求
使用单块英伟达V100GPU训练的理论时间来感受大模型对算力的需求,典型的大模型例如GPT BERT GPT-2等的训练时间如下。
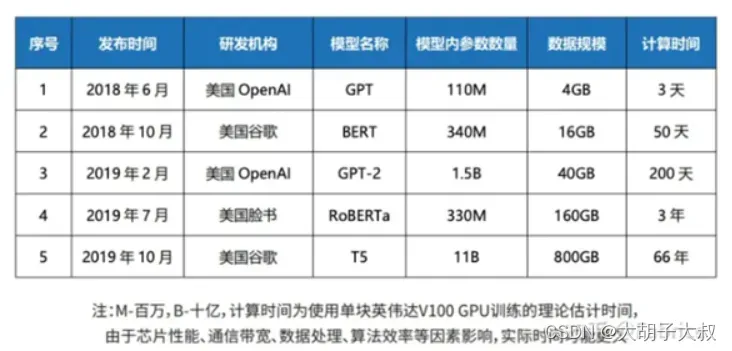
例如,GPT-3的训练使用了上万块英伟达v100 GPU,总成本高达2760万美元,个人如果要训练出一个PaLM也要花费900至1700万美元。 虽然训练会使用更大规模的算力消耗,推理会少非常多,比如清华大学与智谱AI联合开源的双语大模型GLM-130B,通过快速推理方法,已经将模型压缩到可以在一台A100(40G*8)或V100(32G*8)服务器上进行单机推理。但是一台A100的8卡机也是要大几十万(A100 40G单卡7w左右,8张卡则56w,那么整机也需要60w左右了),这个成本,对很多AI应用来说,还是很高。
好消息则是算力在迭代,算力成本也在下降,NVIDIA的H系列显卡,比如H100,单从算力(fp32)相比以往T4(深度学习1.0时代主流显卡),达到7倍++,坏消息则是H100这样的强大算力显卡被限制出口国内。
在大模型时代,针对Transformer结构优化的加速卡、工具链也在被不断推出,算力厂商在抢占大模型计算高地的同时,提高算力和降低成本,让大模型落地通路可行。
国内应用场景
智源研究院针对2021年北京冬奥会,提出了“悟道”大模型用于冬奥手语播报数字人,提供智能化的数字人手语生成服务,方便听障人士也能收看赛事专题报道,提升他们的社会参与度和幸福感。这个项目还得到了北京市残疾人联合会和市残联聋人协会的大力支持。

华为盘古CV大模型。主要是针对无人机电力智能巡检这个场景,以国网重庆永川供电公司为例,无人机智能巡检开发主要面临两个挑战:一是如何对海量数据进行高效标注;二是缺陷种类多达上百种,需要数十个AI识别模型。
盘古CV大模型在数据标注方面,利用海量无标注电力数据进行预训练,结合少量标注样本进行微调,使得样本筛选效率提升约30倍,以永川供电每天采集5万张高清图片为例,可节省人工标注时间170人天。在模型通用性方面,可以做到一个模型适配上百种缺陷,替代原有20多个小模型,减少了模型维护成本,平均精度提升18.4%,开发成本降低90%。

当然也缺少不了最近双十一,双十一是淘宝系统服务最繁忙的一天,如何有效地应对成千上亿的用户咨询。
基于达摩院开发的M6大模型智能生成内容文案,方便智能客服进行上下文理解和问题回答生成。
另外大模型的多模态特征提取能力,也能进行商品属性标签补充、认知召回等下游任务。
大模型训练框架
目前部分深度学习框架,例如Pytorch和Tensorflow,没有办法满足超大规模模型训练的需求,于是微软基于Pytroch开发了DeepSpeed,腾讯基于Pytroch开发了派大星PatricStar,达摩院同基于Tensoflow开发的分布式框架Whale。像是华为昇腾的MindSpore、百度的PaddlePaddle,还有国内的追一科技OneFlow等厂商,对超大模型训练进行了深度的跟进与探索,基于原生的AI框架支持超大模型训练。

大模型主要头部厂商
最主要的竞争对手有基于英伟达的GPU+微软的DeepSpeed,Google的TPU+Tensorflow,当然还有华为昇腾Atlas800+MindSpore三大厂商能够实现全面的优化。至于其他厂商,大部分都是基于英伟达的GPU基础上进行一些创新和优化。
斯坦福大学大模型中心对全球 30 个主流大模型进行了全方位的评测
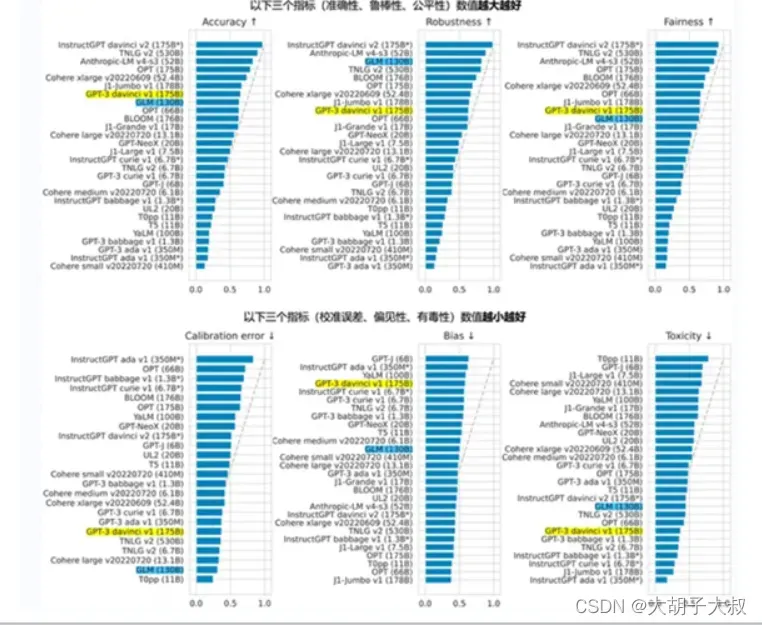
GLM-130B 是亚洲唯一入选的大模型。在与 OpenAI、Google Brain、微软、英伟达、Meta AI 的各大模型对比中,评测报告显示 GLM-130B 在准确性和公平性指标上与 GPT-3 175B (davinci) 接近或持平,鲁棒性、校准误差和无偏性优于 GPT-3 175B。
由清华技术成果转化的公司智谱 AI 开源了 GLM 系列模型的新成员——中英双语对话模型 ChatGLM-6B,支持在单张消费级显卡上进行推理使用。这是继此前开源 GLM-130B 千亿基座模型之后,智谱 AI 再次推出大模型方向的研究成果。
开源的地址:https://github.com/THUDM/ChatGLM-6B
期望
对于AI大模型而言,我们不仅期望它的参数量巨大,大模型也应同时具备多种模态信息的高效理解能力、跨模态的感知能力以及跨差异化任务的迁移与执行能力等。
关于文章的内容放到了ppt里面,想要下载的朋友可以到我的资源里面下载,ppt做的比较粗糙,还请见谅。
文章出处登录后可见!