电影推荐系统
目录
电影推荐系统 1
- 数据描述 1
- 变量说明 1
- 程序介绍 2
本次课程作业在 small-movielens 数据集的基础上,对用户、电影、评分数据进行了处理,然后根据 Pearson 相关系数计算出用户与其他用户之间的相似度,根据相似度进行推荐和预测评分,最后再根据数据集中的测试数据,计算该推荐系统的MAE等。
-
数据描述
数据集来源于 MovieLens|GroupLens 网站。完整的数据集是由 943 个用户对 1682 个项目的 100000 个评分组成。每位用户至少对 20 部电影进行了评分。用户和项从 1 开始连续编号。数据是随机排列的。这是一个以选项卡分隔的:用户id|项id|分级|时间戳 列表。从 1970年1月1日 UTC 开始,时间戳是unix时间戳。在这些数据集的基础上,small-movielens 还包括 u1-u5,ua,ub 等七组测试集 (.base)/训练集 (.test) 数据。其中,u1-u5 是以 8:2 的比例随机生成互斥的训练集和测试集;ua、ub 是按照 9:1 的比例随机生成的互斥的训练集和测试集,不同的是,这两组数据的测试集中每个用户是对正好 10 部不同电影进行了评分。数据集如下图所示。
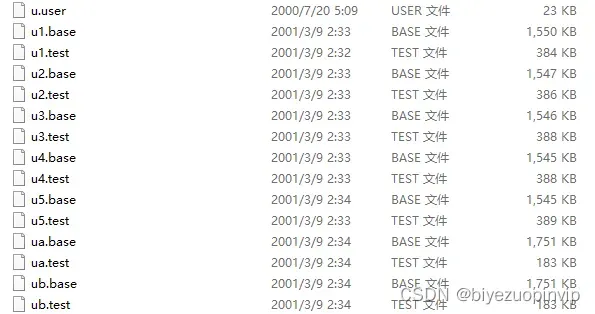
-
变量说明
users :保存所有用户,不重复 list 类型 存储结构:[user1, user2,…]
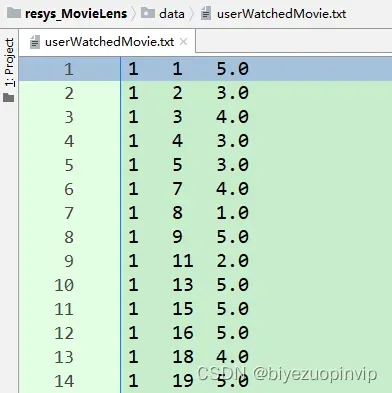
userWatchedMovie :保存所有用户看过的所有电影,字典嵌套字典类型 存储结构:{user1:{movie1:rating1, movie2:rating2, …}, user2:{…},…}
movieUser :保存用户与用户之间共同看过的电影,字典嵌套字典嵌套 list 存储结构:{user1:{user2:[movie1,…],user3:[…],…},user2:{user3:[…],…},…}
userSimilarity :保存用户与用户之间的相似度(皮尔逊相似度) 存储结构:{user1:{user2:sim, user3:sim,…}, user2:{user3:sim, …}, …}
allUserTopNSim :保存每个用户都取前 n=10 个最相似的用户,以及相似度 存储结构:{user1:{user01:sim,user02:sim,…},user2:{user01:sim,…},…}
recommendedMovies :从最相似的用户中推荐,每个相似用户推荐两部,同时计算出预测值并保存在这个变量里 存储结构:{user1:{user01:{movie01:predictionRating,…},user02:[…],…},user2:{user01:[…],…},…}
usersTest :测试集文件中的所有用户 存储结构:同 users
userWatchedMovieTest :测试集文件中所有用户看过的所有电影 存储结构:同 userWatchedMovie
movieAlsoInTest :保存推荐的电影正好也在用户测试数据中看过的那一些电影,以便后面进行 MAE 计算 存储结构:{user1:[movie1,movie2,…],…}
averageRating :保存每个用户对被推荐的电影的预测平均分 存储结构:{user1:{movie01:[count,sumPreRating,averageRating],…},…}
eachUserMAE :保存对每个用户而言计算出的 MAE 存储结构:{user1:MAE,user2:MAE,…}
# -*- coding:utf-8 -*-
from math import sqrt
import os
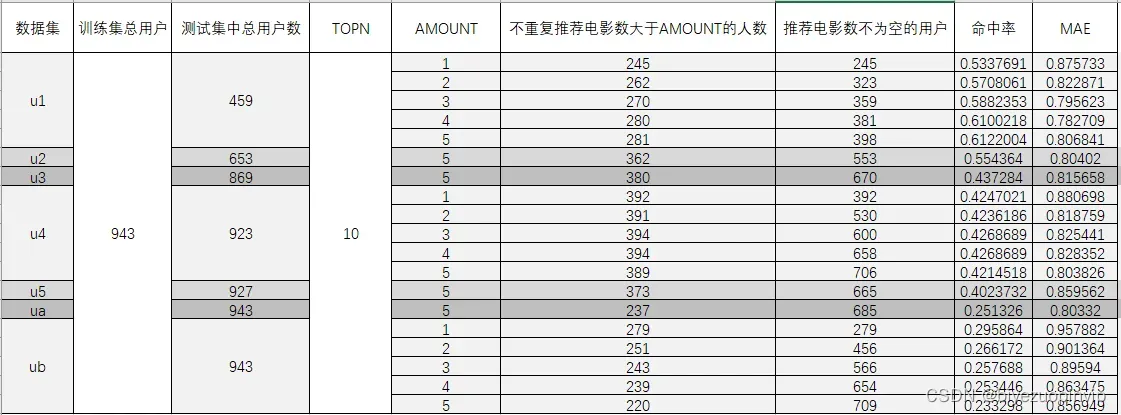
TOPN = 10 # 设置每个用户相似度最高的前TOPN个用户
AMOUNT = 5 # 设置前TOPN个相似用户中每个用户给当前用户推荐的电影数量
# 读取训练集数据文件
filePath = './data/u1.base'
users = [] # 保存所有用户,不重复list类型
userWatchedMovie = {} # 保存所有用户看过的所有电影,字典嵌套字典类型
movieUser = {} # 保存用户与用户之间共同看过的电影,字典嵌套字典嵌套list
with open(filePath, 'r') as trainFile:
# 计算所有的用户以及用户看过的电影和评分,保存到相关字典变量中
for line in trainFile:
# type(line)是string类型,其中分离出来的userId等也都是string类型
# strip()方法是去除指定首尾字符
(userId, movieId, rating, timestamp) = line.strip('\n').split('\t')
if userId not in users:
users.append(userId)
userWatchedMovie.setdefault(userId, {})
userWatchedMovie[userId][movieId] = float(rating)
# 计算用户与用户共同看过的电影
for x in range(len(users)-1):
movieUser.setdefault(users[x], {})
for y in range(x+1, len(users)):
movieUser[users[x]].setdefault(users[y], [])
for m in userWatchedMovie[users[x]].keys():
if m in userWatchedMovie[users[y]].keys():
movieUser[users[x]][users[y]].append(m)
# 计算用户与用户之间的相似度,皮尔逊相似度
userSimilarity = {}
for a in movieUser.keys():
userSimilarity.setdefault(a, {})
for b in movieUser[a].keys():
userSimilarity[a].setdefault(b, 0)
if len(movieUser[a][b]) == 0:
userSimilarity[a][b] = 0 # 如果两个人没有看过同一部电影,则相似度为0
continue
else:
# 下面开始进行相似度的计算,皮尔森相关系数
avgUserA = 0 # A用户打分的平均值
avgUserB = 0 # B用户打分的平均值
numerator = 0 # Pearson的分子部分
denominatorA = 0 # Pearson的分母A部分
denominatorB = 0 # Pearson的分母B部分
count = len(movieUser[a][b]) # 保存两个用户共同看过的电影的数量
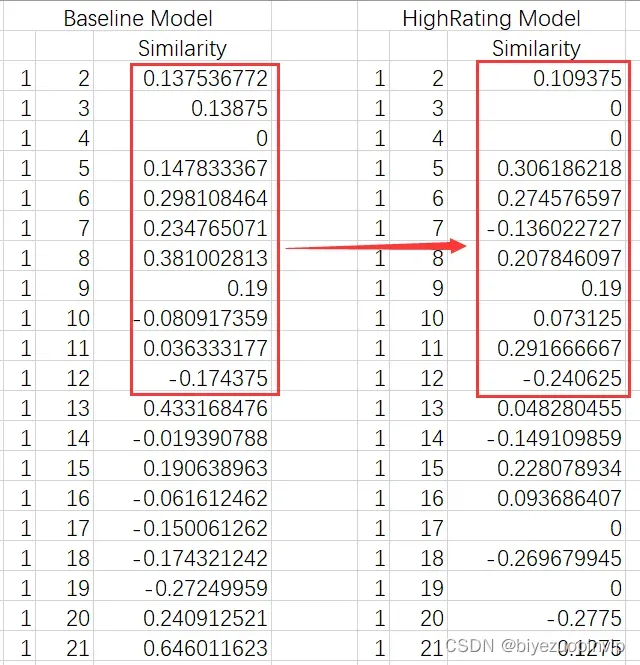
# 这里用到了一个召回率的因素,因为在前述的实验过程中,发现最相似的用户
# 相似度达到了 1.0 ,感觉有点不正常,比如说用户1和用户9,共同只看过两部电影,但是相似度却等于 1.0
# 这个是不太正确的,所以加入了召回率的考量
# 加入之后,发现用户1和用户9的相似度从1.0下降到0.19,感觉是比较合理的
factor = 0
if count > 20: # 20是自己指定的
factor = 1.0
else:
if count < 0:
factor = 0
else:
factor = (-0.0025 * count * count) + (0.1 * count)
for movie in movieUser[a][b]: # 对于两个用户都看过的每一部电影,进行计算
avgUserA += float(userWatchedMovie[a][movie])
avgUserB += float(userWatchedMovie[b][movie])
avgUserA = float(avgUserA / count)
avgUserB = float(avgUserB / count)
# print(avgUserA)
# print(avgUserB)
for m in movieUser[a][b]:
# print(userWatchedMovie[a][m])
tempA = float(userWatchedMovie[a][m]) - avgUserA
tempB = float(userWatchedMovie[b][m]) - avgUserB
# print(tempA)
numerator += tempA * tempB
denominatorA += pow(tempA, 2) * 1.0
denominatorB += pow(tempB, 2) * 1.0
# print(numerate)
if denominatorA != 0 and denominatorB != 0:
userSimilarity[a][b] = factor * (numerator / (sqrt(denominatorA * denominatorB)))
else:
userSimilarity[a][b] = 0
# 每个用户都取前n个最相似的用户,以便后续进行推荐
# singleUserTopNSim = {}
allUserTopNSim = {}
for currentUserId in users: # 计算当前用户的最相似的前n个用户
singleUserSim = {} # 存放单个用户对所有用户的相似度
allUserTopNSim.setdefault(currentUserId, {}) # 存放所有用户的TopN相似的用户
for compareUserId in users:
if currentUserId == compareUserId:
break
else:
singleUserSim[compareUserId] = userSimilarity[compareUserId][currentUserId]
if int(currentUserId) != len(users):
singleUserSim.update(userSimilarity[currentUserId])
# print(currentUserId, end=' ')
# print(singleUserSim)
# python中的字典是无序的,但是有时候会根据value值来取得字典中前n个值,
# 此处思想是将字典转化成list,经过排序,取得前n个值,再将list转化回字典
# 进行排序,取前N个相似的用户,此时singleSortedSim是一个list类型:[(key,value),(key,value),(key,value),...]
singleSortedSim = sorted(singleUserSim.items(), key=lambda item: item[1], reverse=True)
singleTopN = singleSortedSim[:TOPN] # 取出前N个最相似的值
for single in singleTopN:
allUserTopNSim[currentUserId][single[0]] = single[1] # 保存当前用户计算出的TopN个相似用户以及相似度
# 从最相似的用户中推荐,每个相似用户推荐number部,那么每个用户就能得到推荐的number*10部电影
recommendedMovies = {}
for oneUser in allUserTopNSim.keys():
recommendedMovies.setdefault(oneUser, {})
for simUser in allUserTopNSim[oneUser].keys():
oneMovieList = []
simUserMovieList = []
number = 0
recommendedMovies[oneUser].setdefault(simUser, {})
for movie in userWatchedMovie[simUser].keys():
if number >= AMOUNT: # 每个人推荐数量为number部的电影数
break
if movie not in userWatchedMovie[oneUser].keys(): # and (movie not in recommendedMovies[oneUser]):
# 计算预测权值
if int(oneUser) < int(simUser):
# oneMovieList.append(list(movieUser[oneUser][simUser]))
# simUserMovieList.append(list(movieUser[oneUser][simUser]))
length = len(movieUser[oneUser][simUser])
#simUserMovieList.append(movie)
#tupleOne = tuple(oneMovieList)
#tupleSim = tuple(simUserMovieList)
sumOne = 0.0
sumSim = 0.0
for i in movieUser[oneUser][simUser]:
sumOne += userWatchedMovie[oneUser].get(i)
sumSim += userWatchedMovie[simUser].get(i)
sumSim += userWatchedMovie[simUser].get(movie)
avgOneUser = sumOne / length
avgSimUser = sumSim / (length + 1)
predictionRating = avgOneUser + (userWatchedMovie[simUser][movie] - avgSimUser)
recommendedMovies[oneUser][simUser][movie] = predictionRating #这是一个需要计算的值
number += 1
else:
# oneMovieList.append(movieUser[simUser][oneUser])
# simUserMovieList.append(movieUser[simUser][oneUser])
length = len(movieUser[simUser][oneUser])
# simUserMovieList.append(movie)
sumOne = 0
sumSim = 0
for i in movieUser[simUser][oneUser]:
sumOne += userWatchedMovie[oneUser].get(i)
sumSim += userWatchedMovie[simUser].get(i)
sumSim += userWatchedMovie[simUser].get(movie)
avgOneUser = sumOne / length
avgSimUser = sumSim / (length + 1)
predictionRating = avgOneUser + (userWatchedMovie[simUser][movie] - avgSimUser)
recommendedMovies[oneUser][simUser][movie] = predictionRating #这是一个需要计算的值
number += 1
else:
continue
'''
# 读取测试集数据文件
filePathTest = './data/u1.test'
usersTest = [] # 保存所有用户,不重复list类型
userWatchedMovieTest = {} # 保存所有用户看过的所有电影,字典嵌套字典类型
with open(filePathTest, 'r') as testFile:
# 计算所有的用户以及用户看过的电影和评分,保存到相关字典变量中
for lineTest in testFile:
(userIdTest, movieIdTest, ratingTest, timestampTest) = lineTest.strip('\n').split('\t')
if userIdTest not in usersTest:
usersTest.append(userIdTest)
userWatchedMovieTest.setdefault(userIdTest, {})
userWatchedMovieTest[userIdTest][movieIdTest] = ratingTest
'''
'''
# 要找到在测训练集中用户没有看过,但是在测试集中用户看过并且被推荐过的电影,这样后面好计算MAE(平均绝对误差)
movieRecommendedAlsoInTest = {}
for user in usersTest:
movieRecommendedAlsoInTest.setdefault(user, [])
for m in recommendedMovies[user]:
if m in userWatchedMovieTest[user].keys():
movieRecommendedAlsoInTest[user].append(m)
'''
'''
writeFilePath = './data/movieuser.txt'
if os.path.exists(writeFilePath):
os.remove(writeFilePath)
writeFile = open(writeFilePath, 'w')
for m in movieUser.keys():
for n in movieUser[m].keys():
writeFile.writelines([m, '\t', n, '\t', str(movieUser[m][n])])
writeFile.write('\n')
writeFile.close()
'''
writeFilePath = './data/userWatchedMovie.txt'
if os.path.exists(writeFilePath):
os.remove(writeFilePath)
writeFile = open(writeFilePath, 'w')
for m in userWatchedMovie.keys():
for n in userWatchedMovie[m].keys():
writeFile.writelines([m, '\t', n, '\t', str(userWatchedMovie[m][n])])
writeFile.write('\n')
writeFile.close()
writeFilePath = './data/allUserTop10Sim.txt'
if os.path.exists(writeFilePath):
os.remove(writeFilePath)
writeFile = open(writeFilePath, 'w')
for m in allUserTopNSim.keys():
for n in allUserTopNSim[m].keys():
writeFile.writelines([m, '\t', n, '\t', str(allUserTopNSim[m][n])])
writeFile.write('\n')
writeFile.close()
writeFilePath = './data/recoMovieWithRating.txt'
if os.path.exists(writeFilePath):
os.remove(writeFilePath)
writeFile = open(writeFilePath, 'w')
for m in recommendedMovies.keys():
for n in recommendedMovies[m].keys():
writeFile.writelines([m, '\t', n, '\t', str(recommendedMovies[m][n])])
writeFile.write('\n')
writeFile.close()
writeFilePath = './data/userSimilarity.txt'
if os.path.exists(writeFilePath):
os.remove(writeFilePath)
writeFile = open(writeFilePath, 'w')
for m in userSimilarity.keys():
for n in userSimilarity[m].keys():
writeFile.writelines([m, '\t', n, '\t', str(userSimilarity[m][n])])
writeFile.write('\n')
writeFile.close()
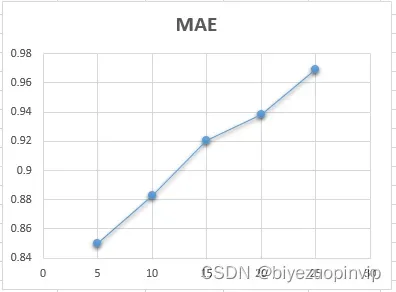
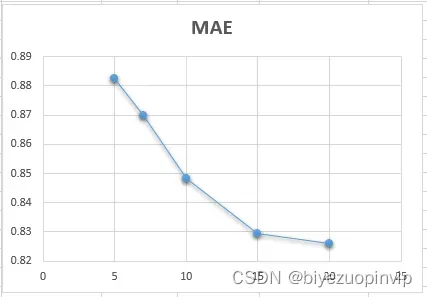
文章出处登录后可见!