大家好!我是岛上程序猿,感谢您阅读本文,欢迎一键三连哦。
目录
- 一、项目简介
- 二、系统设计
- 2.1软件功能模块设计
- 2.2数据库设计
- 三、系统项目部分截图
- 3.1管理员功能模块
- 3.2热搜数据
- 3.3热搜
- 四、论文目录
- 五、部分核心代码
- 4.1 热词部分
- 获取源码或论文
一、项目简介
整个开发过程首先对软件系统进行需求分析,得出系统的主要功能。接着对系统进行总体设计和详细设计。总体设计主要包括系统功能设计、系统总体结构设计、系统数据结构设计和系统安全设计等;详细设计主要包括系统数据库访问的实现,主要功能模块的具体实现,模块实现关键代码等。最后对系统进行功能测试,并对测试结果进行分析总结,得出系统中存在的不足及需要改进的地方,为以后的系统维护提供了方便,同时也为今后开发类似系统提供了借鉴和帮助。
本系统开发利用现有的成熟技术参考,以源代码为模板,分析功能调整与微博舆情分析系统的实际需求相结合,确定了Python开发微博舆情分析系统的使用。
二、系统设计
2.1软件功能模块设计
系统整体功能如下:

2.2数据库设计
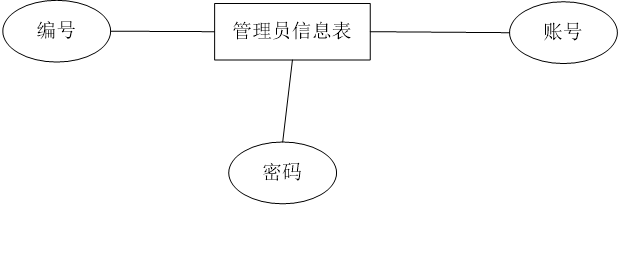
(1)系统的E-R图
概念模型是数据库设计的强大工具。数据库概念模型设计可以通过E-R图描述现实世界的概念模型。系统的E-R图显示了系统中实体之间的链接。
(2)实体属性图
管理员实体图如图4-1。
三、系统项目部分截图
3.1管理员功能模块
管理员登录进入微博舆情分析系统可以查看热搜数据、类搜索引擎、热点词统计展示等内容,如图5-2所示。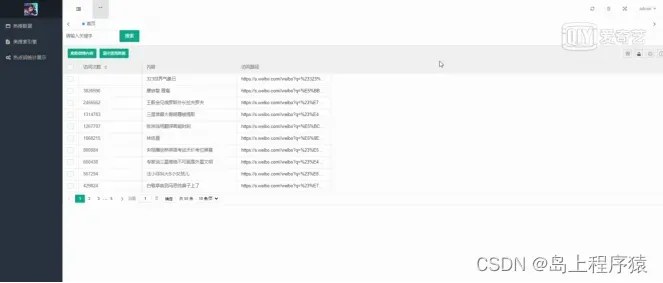
3.2热搜数据
在热搜数据页面可以通过输入关键字可以搜索相关热搜,并根据需要清空重置数据,如图5-3所示。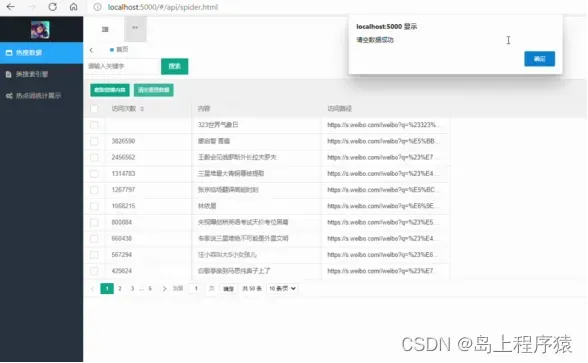
3.3热搜
通过点击爬取微博内容,系统自动爬取微博内容,点击访问路径后会出现热搜微博,如图5-4所示。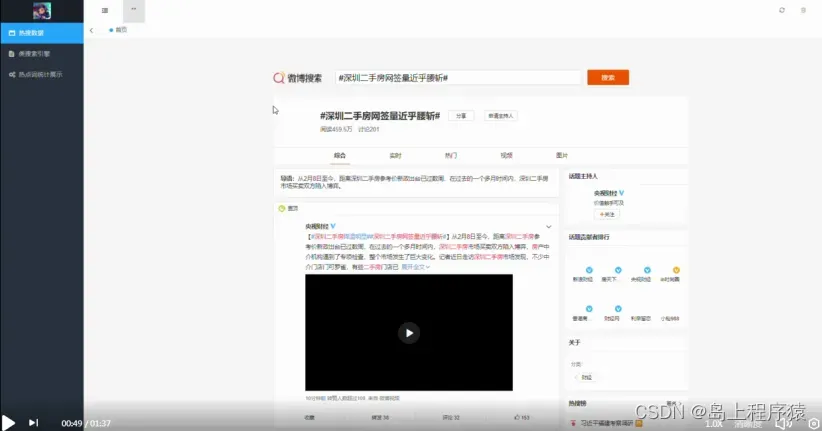
热点词统计,在热点词统计页面可以查看热点词语的柱状图,如图5-5所示。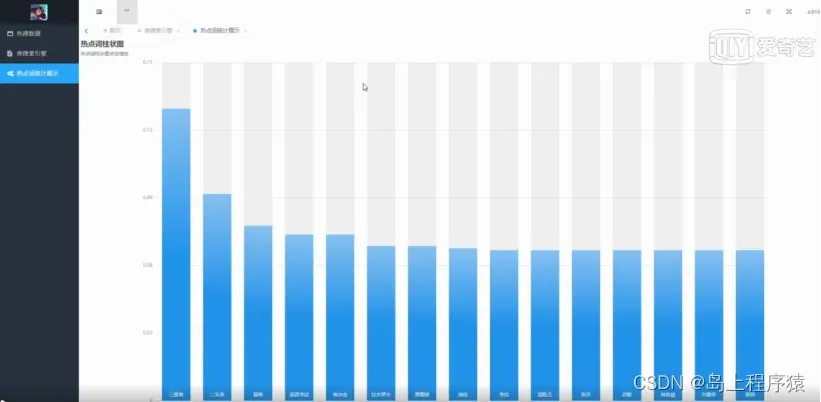
类搜索引擎,在类搜索引擎页面通过输入关键字进行搜索,会出现和关键字有关的微博内容、访问次数、访问路径等内容,如图5-6所示。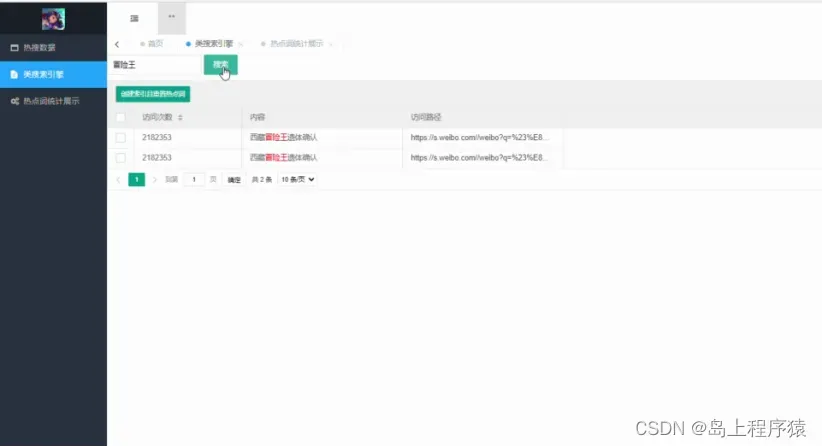
热点微博,通过类搜索引擎后,点击访问路径,会出现相关热点微博,如图5-7所示。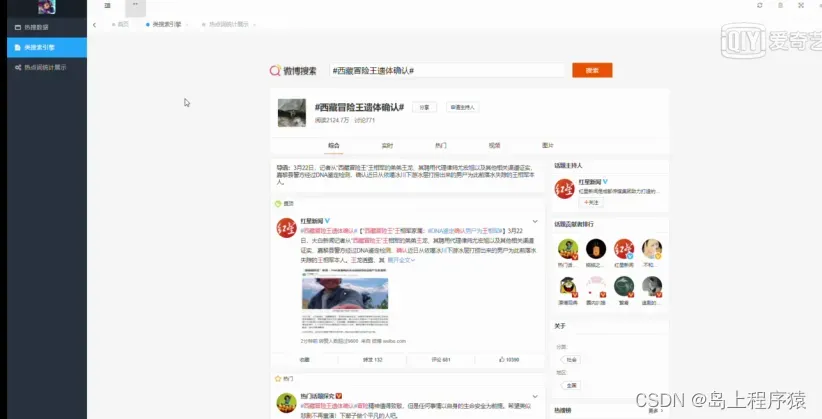
四、论文目录
摘 要 I
Abstracts II
目 录 III
第1章 绪论 1
1.1课题背景 1
1.2目的和意义 1
1.3研究现状 2
1.4研究内容 3
第2章 关键技术研究 4
2.1 Python简介 4
2.2 B/S框架 4
2.3 MySQL数据库 4
第3章 需求分析 5
3.1可行性分析 6
3.1.1 技术可行性 6
3.1.2 经济可行性 6
3.1.3 操作可行性 7
3.1.4 法律可行性 7
3.2需求分析 7
3.3系统设计原则 8
3.4业务流程分析 9
3.4.1操作流程 9
3.4.2添加信息流程 11
3.4.3删除信息流程 11
第4章 系统总体设计 13
4.1系统功能模块 13
第5章 系统实现 18
5.1管理员功能模块 20
第6章 系统测试 29
6.1系统测试的目的 30
6.2测试策略 30
6.3测试特性及分析 30
6.4功能测试 31
6.5测试结果 32
结 论 33
参考文献 34
致 谢 35
五、部分核心代码
4.1 热词部分
import jieba
import jieba.analyse
import os
from flask import request,Blueprint,jsonify
from pojo.Content import Content
hotwords = Blueprint('hotwords', __name__)
targetTxt="hotwords.txt"
#分词热词
def hotwordCreate(data):
if not os.path.isfile(targetTxt):
fd = open(targetTxt, mode="w", encoding="utf-8")
fd.close()
targetFile=open(targetTxt, 'w')
for el in data:
if el.content is not "":
seg = jieba.cut(el.content, cut_all = False)
output = ' '.join(seg)
targetFile.write(output)
targetFile.write('n')
targetFile.close()
print("分词结束且保存进入文件中")
@hotwords.route("/getHotWords")
def hotwordRead():
file=open(targetTxt, 'r')
text = file.readlines()
keywords = jieba.analyse.extract_tags(str(text), topK=10, withWeight=True, allowPOS=())
list=[]
for hotWord in keywords:
list.append({
"hotWord":hotWord[0]
})
return jsonify(list)
@hotwords.route("/echartsHotWordDisplay")
def echartsHotWordDisplay():
file = open(targetTxt, 'r')
text = file.readlines()
keywords = jieba.analyse.extract_tags(str(text), topK=15, withWeight=True, allowPOS=())
list = []
dataAxis=[]
data=[]
for hotWord in keywords:
list.append({
"hotWord": hotWord[0]
})
dataAxis.append(hotWord[0])
data.append(hotWord[1])
return jsonify({
"dataAxis":dataAxis,
"data":data
})
# list=[]
# c1=Content()
# c1.content="我是最棒的啊"
# c2=Content()
# c2.content="张三李四王五"
# c3=Content()
# c3.content="王五赵六天齐"
# c4=Content()
# c4.content="测试得方案"
# list.append(c1)
# list.append(c2)
# list.append(c3)
# list.append(c4)
# hotwordCreate(list)
# hotwordRead()
获取源码或论文
如需对应的源码,可以评论或者私信都可以。
文章出处登录后可见!