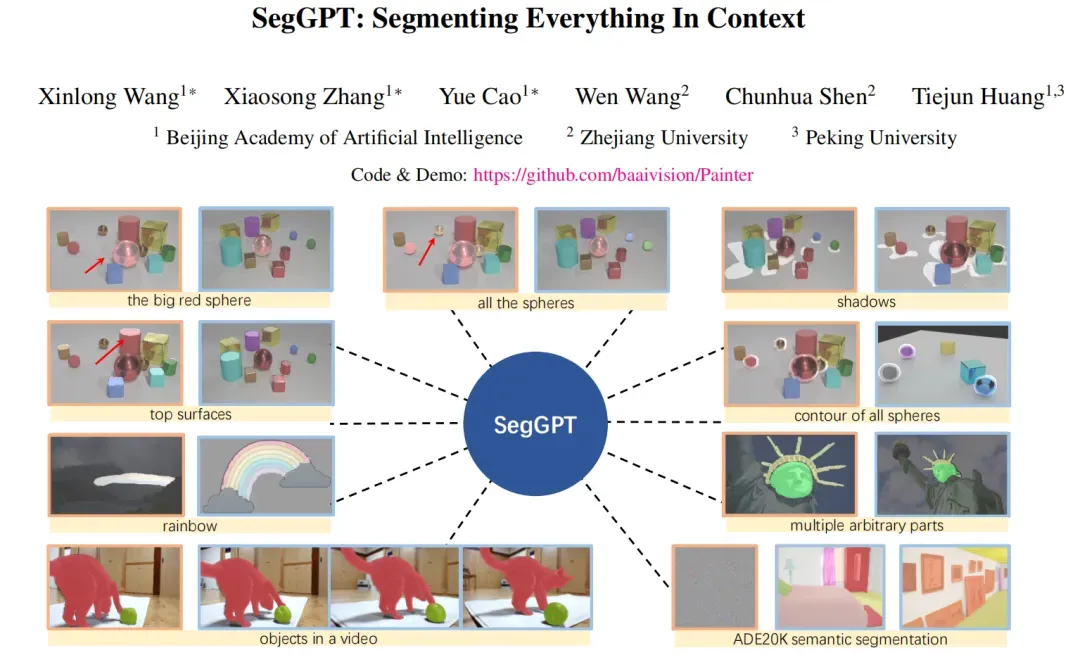
前言 本文介绍了 SegGPT,它是 Painter 框架的特殊版本,将各种分割任务统一到一个通用的上下文学习框架中,该框架通过将它们转换为相同格式的图像来适应不同类型的分割数据,并将不同的任务统一为同一个图像修复问题,即随机屏蔽任务输出图像并重建缺失像素。经过训练,SegGPT可以对图像进行任意分割任务或通过上下文推理的视频。通过在广泛的任务上进行评估,结果显示了定性或定量分割域内和域外目标的强大能力。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
论文:https://arxiv.org/pdf/2304.03284.pdf
Code & Demo:https://github.com/baaivision/Painter
论文出发点
受NLP领域中大规模语言模型chatGPT的启发,作者想训练一个能够解决CV领域中多样化和无限分割任务的单一模型。但主要挑战是双重的:(1)在训练中整合那些非常不同的数据类型,例如部分、语义、实例、全景、人物、医学图像、航拍图像等;(2) 设计一种不同于传统多任务学习的可泛化训练方案,该方案在任务定义上灵活,能够处理域外任务。此外,在 Painter 的传统框架中,每个任务的颜色空间都是预先定义的,导致解决方案崩溃为多任务学习。如语义分割是预先定义了一组颜色,并为每个语义类别分配了固定的颜色。类似地,在实例分割中,实例对象的颜色是根据其位置类别分配的,即颜色的数量等于空间位置的数量,从而得到模型仅依靠颜色本身来确定任务,而不是使用段之间的关系。
创新思路
本文将分割视为视觉感知的通用格式,并将不同的分割任务统一到一个通用的上下文学习框架中。该框架通过将不同类型的分割数据转换为相同格式的图像来适应它们。SegGPT 的训练被表述为上下文着色问题,每个数据样本具有随机颜色映射。目的是仅根据上下文为相应区域(例如类、对象实例、部件等)着色。通过使用随机着色方案,模型被迫参考上下文信息来完成分配的任务,而不是依赖于特定的颜色。
方法
In-Context Coloring
首先随机采样另一张与输入图像共享相似上下文的图像,如相同的语义类别或对象实例。随后,从目标图像中随机采样一组颜色,并将每种颜色映射到一个随机颜色。这导致相应像素的重新着色。最终,得到两对图像,将其定义为上下文对。此外,还使用了混合示例训练模型的混合上下文训练方法,将具有相同颜色映射的多个图像拼接在一起。然后随机裁剪生成的图像并调整大小以形成混合上下文训练样本。这种统一以一致的方式利用所有分割数据集,仅根据特定任务改变数据采样策略,并根据不同的数据类型定义不同的上下文。语义分割中,进行随机类别抽样。实例分割中,对象实例以随机数采样。通过一组增强变换得到的同一图像的不同视图,视为上下文中的图像。所有的采样都是关于颜色的,即相同的颜色表示相同的类别或相同的实例。
Segment Anything Model
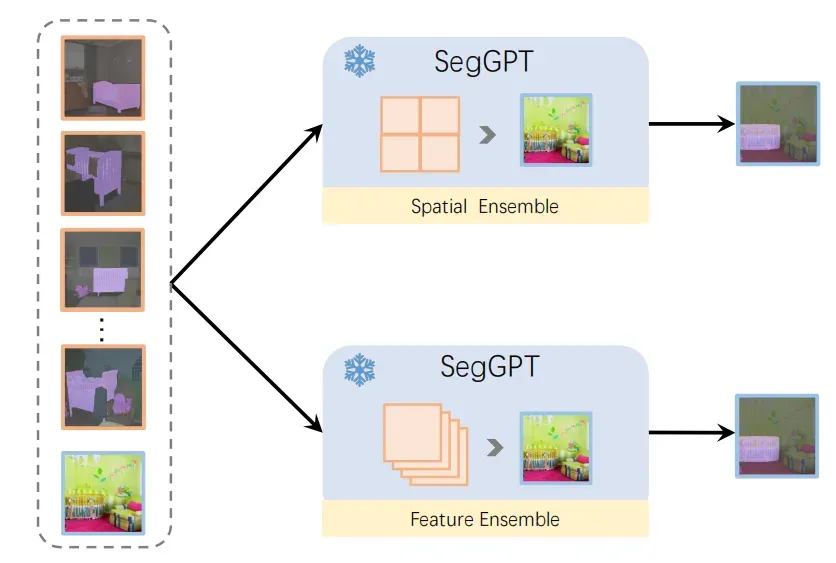
本文提出了两种上下文集成方法。一种称为空间集成(spatial ensemble),多个示例拼接在 n × n 网格中,然后二次采样到与单个示例输入分辨率相同的大小。。另一种方法是特征集成(feature ensemble),多个示例在批次维度中组合并独立计算,除了查询图像的特征在每个注意层之后被平均。通过这种方式,查询图像在推理过程中收集了有关多个示例的信息。
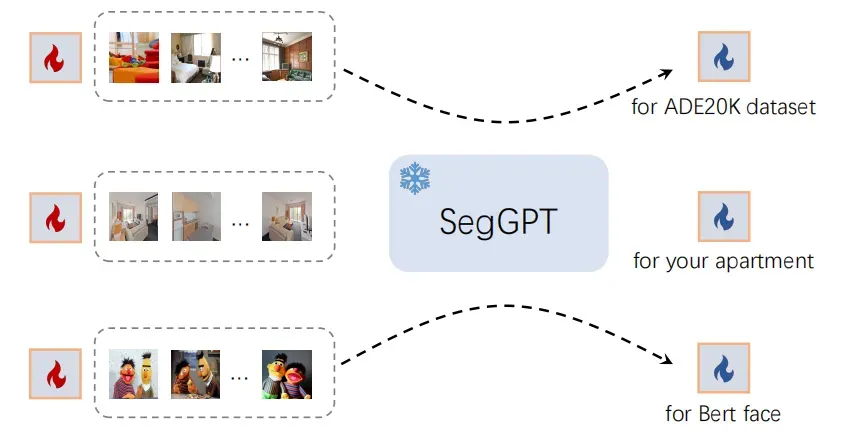
In-Context Tuning
冻结整个模型并初始化一个可学习的图像张量作为输入上下文。只有这个可学习的图像张量在训练期间被更新。其余的训练保持不变。调整后,将学习到的图像张量取出,将其用作特定应用程序的即插即用密钥。
结果
作者使用不同类型的分割数据集,包括部分、语义、实例、全景、人、视网膜和航拍图像分割,提供一个统一的视角,无需对数据集进行额外的工作或调整,并且在添加额外数据集时不需要对架构或pipeline进行修改,这与以前需要手工标签合并来组合不同类型的分割数据集的方法不同。
YouTube-VOS 2018 上视频对象分割结果可视化:

更多的可视化:

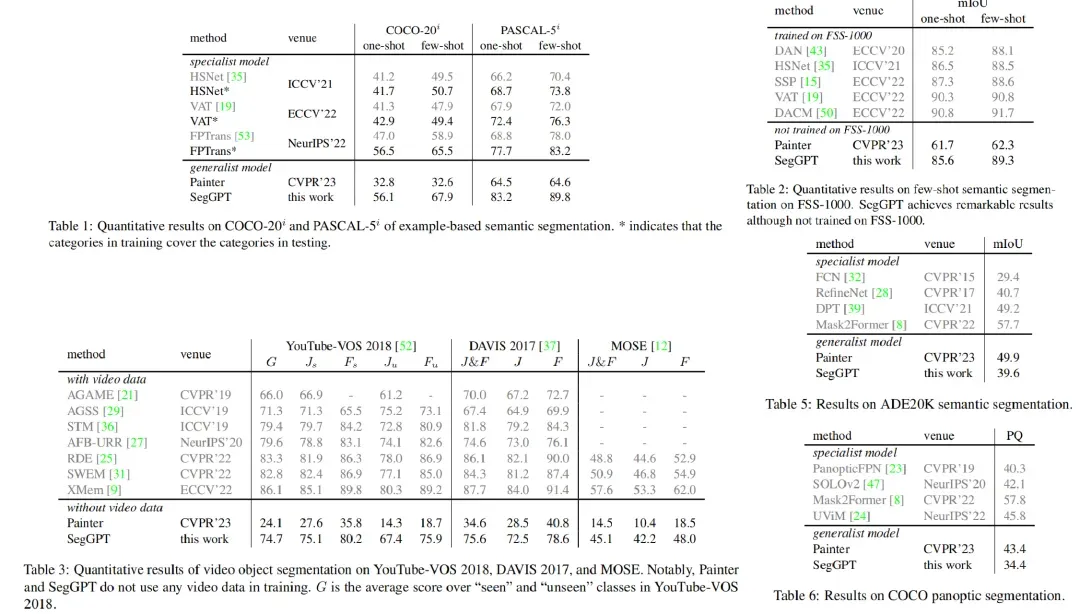
各种分割方法的对比情况:
消融实验:
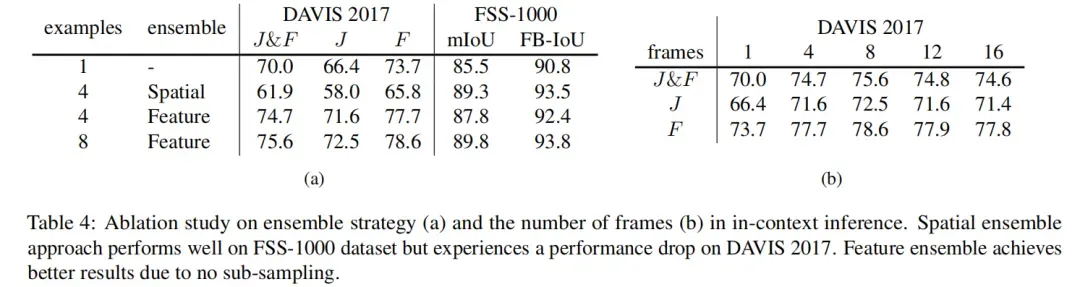
总结
本文提出了一个通用分割模型,展示了如何设计适当的训练策略以充分利用上下文视觉学习的灵活性。虽然引入了一种新的随机着色机制以提高上下文训练的泛化能力,但它使训练任务本质上更加困难,这可能是具有大量训练数据的域内任务性能较差的原因,例如语义ADE20K 上的分割和 COCO 上的全景分割。
通过利用任务定义的灵活性和上下文推理,在图像/视频分割中实现更多样化的应用。扩大模型尺寸是作者计划进一步提高性能的一种途径。使用更大的模型,可以捕获数据中更复杂的模式,这可能会导致更好的分割结果。然而,这伴随着寻找更多数据的挑战。一种潜在的解决方案是探索自我监督学习技术。希望本文的工作将激励社区继续探索计算机视觉中上下文学习的潜力。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。
【技术文档】《从零搭建pytorch模型教程》122页PDF下载
QQ交流群:470899183。群内有大佬负责解答大家的日常学习、科研、代码问题。
模型部署交流群:732145323。用于计算机视觉方面的模型部署、高性能计算、优化加速、技术学习等方面的交流。
其它文章
上线一天,4k star | Facebook:Segment Anything
3090单卡5小时,每个人都能训练专属ChatGPT,港科大开源LMFlow
Efficient-HRNet | EfficientNet思想+HRNet技术会不会更强更快呢?
ICLR 2023 | SoftMatch: 实现半监督学习中伪标签的质量和数量的trade-off
目标检测创新:一种基于区域的半监督方法,部分标签即可(附原论文下载)
文章出处登录后可见!