python读写excel的方式有很多,不同的模块在读写的讲法上稍有区别,这里我主要介绍几个常用的方式。
- 用xlrd和xlwt进行excel读写;
- 用openpyxl进行excel读写;
- 用pandas进行excel读写;
一、数据准备
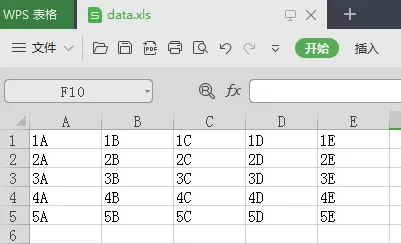
为了方便演示,我这里新建了一个data.xls和data.xlsx文件,第一个工作表sheet1区域“A1:E5”的内容如下,用于测试读写excel的代码:
二、0xlrd和xlwt
xlrd是一个库,用于从Excel文件中以.xls格式读取数据和格式化信息
xlwt是一个库,用于将数据和格式化信息写入较旧的Excel文件(例如:.xls)。
1示例
| pip install xlrd |
| pip install xlwt |
我们开始来读取文件的内容
| import xlrd |
| import os |
| file_path = os.path.dirname(os.path.abspath(__file__)) |
| base_path = os.path.join(file_path, ‘data.xlsx’) |
| book = xlrd.open_workbook(base_path) |
| sheet1 = book.sheets()[0] |
| nrows = sheet1.nrows |
| print(‘表格总行数’, nrows) |
| ncols = sheet1.ncols |
| print(‘表格总列数’, ncols) |
| row3_values = sheet1.row_values(2) |
| print(‘第3行值’, row3_values) |
| col3_values = sheet1.col_values(2) |
| print(‘第3列值’, col3_values) |
| cell_3_3 = sheet1.cell(2, 2).value |
| print(‘第3行第3列的单元格的值:’, cell_3_3) |

接下来我们来进行写入,写入可以进行的操作太多了,我这里只列举了常用的的操作。
| import xlwt |
| import datetime |
| # 创建一个workbook 设置编码 |
| workbook = xlwt.Workbook(encoding=’utf-8′) |
| # 创建一个worksheet |
| worksheet = workbook.add_sheet(‘Worksheet’) |
| # 写入excel参数对应 行, 列, 值 |
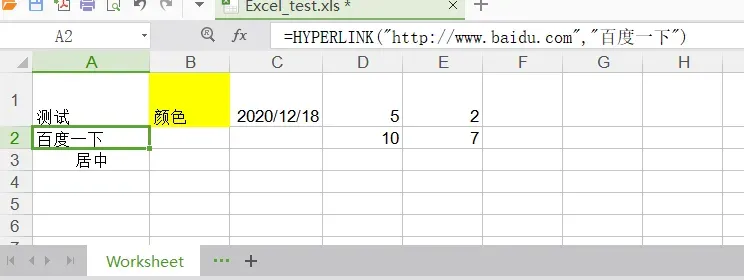
| worksheet.write(0, 0, label=’测试’) |
| # 设置单元格宽度 |
| worksheet.col(0).width = 3333 |
| # 设置单元格高度 |
| tall_style = xlwt.easyxf(‘font:height 520;’) |
| worksheet.row(0).set_style(tall_style) |
| # 设置对齐方式 |
| alignment = xlwt.Alignment() # Create Alignment |
| # May be: HORZ_GENERAL, HORZ_LEFT, HORZ_CENTER, HORZ_RIGHT, HORZ_FILLED, HORZ_JUSTIFIED, HORZ_CENTER_ACROSS_SEL, HORZ_DISTRIBUTED |
| alignment.horz = xlwt.Alignment.HORZ_CENTER |
| # May be: VERT_TOP, VERT_CENTER, VERT_BOTTOM, VERT_JUSTIFIED, VERT_DISTRIBUTED |
| alignment.vert = xlwt.Alignment.VERT_CENTER |
| style = xlwt.XFStyle() # Create Style |
| style.alignment = alignment # Add Alignment to Style |
| worksheet.write(2, 0, ‘居中’, style) |
| # 写入带颜色背景的数据 |
| pattern = xlwt.Pattern() # Create the Pattern |
| # May be: NO_PATTERN, SOLID_PATTERN, or 0x00 through 0x12 |
| pattern.pattern = xlwt.Pattern.SOLID_PATTERN |
| pattern.pattern_fore_colour = 5 # May be: 8 through 63. 0 = Black, 1 = White, 2 = Red, 3 = Green, 4 = Blue, 5 = Yellow, 6 = Magenta, 7 = Cyan, 16 = Maroon, 17 = Dark Green, 18 = Dark Blue, 19 = Dark Yellow , almost brown), 20 = Dark Magenta, 21 = Teal, 22 = Light Gray, 23 = Dark Gray, the list goes on… |
| style = xlwt.XFStyle() # Create the Pattern |
| style.pattern = pattern # Add Pattern to Style |
| worksheet.write(0, 1, ‘颜色’, style) |
| # 写入日期 |
| style = xlwt.XFStyle() |
| # Other options: D-MMM-YY, D-MMM, MMM-YY, h:mm, h:mm:ss, h:mm, h:mm:ss, M/D/YY h:mm, mm:ss, [h]:mm:ss, mm:ss.0 |
| style.num_format_str = ‘M/D/YY’ |
| worksheet.write(0, 2, datetime.datetime.now(), style) |
| # 写入公式 |
| worksheet.write(0, 3, 5) # Outputs 5 |
| worksheet.write(0, 4, 2) # Outputs 2 |
| # Should output “10” (A1[5] * A2[2]) |
| worksheet.write(1, 3, xlwt.Formula(‘D1*E1’)) |
| # Should output “7” (A1[5] + A2[2]) |
| worksheet.write(1, 4, xlwt.Formula(‘SUM(D1,E1)’)) |
| # 写入超链接 |
| worksheet.write(1, 0, xlwt.Formula(‘HYPERLINK(“http://www.baidu.com”;”百度一下”)’)) |
| # 保存 |
| workbook.save(‘Excel_test.xls’) |
需要注意的是最好在当前路径下通过命令行执行,否则无法生成文件。
三、0openpyxl
openpyxl是一个Python库,用于读取/写入Excel 2010 xlsx/xlsm/xltx/xltm文件。
安装包
| pip install openpyx |
安装完成可以开始进行读取数据
| import openpyxl |
| import os |
| file_path = os.path.dirname(os.path.abspath(__file__)) |
| base_path = os.path.join(file_path, ‘data.xlsx’) |
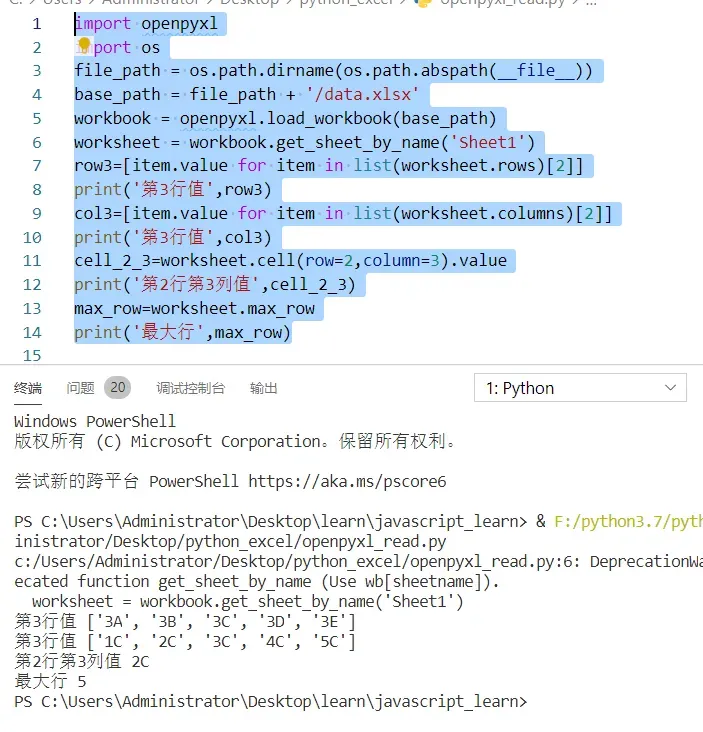
| workbook = openpyxl.load_workbook(base_path) |
| worksheet = workbook.get_sheet_by_name(‘Sheet1’) |
| row3=[item.value for item in list(worksheet.rows)[2]] |
| print(‘第3行值’,row3) |
| col3=[item.value for item in list(worksheet.columns)[2]] |
| print(‘第3行值’,col3) |
| cell_2_3=worksheet.cell(row=2,column=3).value |
| print(‘第2行第3列值’,cell_2_3) |
| max_row=worksheet.max_row |
| print(‘最大行’,max_row) |
现在我们来开始写入数据
| import openpyxl |
| import datetime |
| from openpyxl.styles import Font, colors, Alignment |
| #实例化 |
| workbook = openpyxl.Workbook() |
| # 激活 worksheet |
| sheet=workbook.active |
| #写入数据 |
| sheet[‘A1′]=’python’ |
| sheet[‘B1′]=’javascript’ |
| #写入时间 |
| sheet[‘A2’] = datetime.datetime.now().strftime(“%Y-%m-%d”) |
| # 第2行行高 |
| sheet.row_dimensions[2].height = 40 |
| # B列列宽 |
| sheet.column_dimensions[‘B’].width = 30 |
| # 设置A1中的数据垂直居中和水平居中 |
| sheet[‘A1′].alignment = Alignment(horizontal=’center’, vertical=’center’) |
| # 下面的代码指定了等线24号,加粗斜体,字体颜色黄色。直接使用cell的font属性,将Font对象赋值给它。 |
| bold_itatic_24_font = Font(name=’等线’, size=24, italic=True, color=’00FFBB00′, bold=True) |
| sheet[‘B1’].font = bold_itatic_24_font |
| # 合并单元格, 往左上角写入数据即可 |
| sheet.merge_cells(‘A2:B2’) # 合并一行中的几个单元格 |
| # 拆分单元格 |
| # sheet.unmerge_cells(‘A2:B2’) |
| #保存 |
| workbook.save(‘new.xlsx’) |
四、0pandas
pandas支持xls, xlsx, xlsm, xlsb, odf, ods和odt文件扩展名从本地文件系统或URL读取。支持读取单个工作表或工作表列表的选项。
首先依然是安装包
| pip install pandas |
语法:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False,dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, **kwds)
- io,Excel的存储路径
- sheet_name,要读取的工作表名称
- header, 用哪一行作列名
- names, 自定义最终的列名
- index_col, 用作索引的列
- usecols,需要读取哪些列
- squeeze,当数据仅包含一列
- converters ,强制规定列数据类型
- skiprows,跳过特定行
- nrows ,需要读取的行数
- skipfooter , 跳过末尾n行
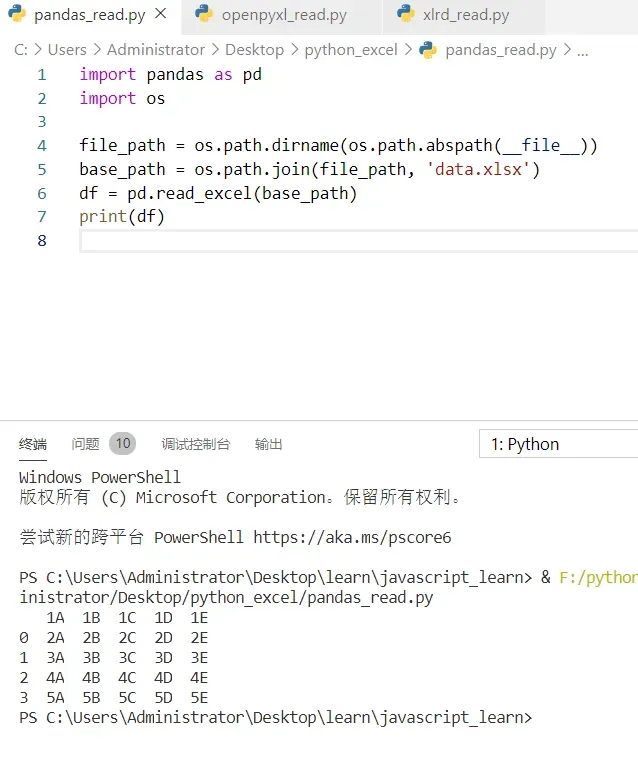
| import pandas as pd |
| import os |
| file_path = os.path.dirname(os.path.abspath(__file__)) |
| base_path = os.path.join(file_path, ‘data.xlsx’) |
| df = pd.read_excel(base_path) |
| print(df) |
写入数据
语法:
DataFrame.to_excel(excel_writer, sheet_name=’Sheet1′, na_rep=”, float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep=’inf’, verbose=True, freeze_panes=None)
参数说明:
- excel_writer:文件路径或现有的ExcelWriter
- sheet_name:将包含数据文件的工作表的名称
- na_rep:缺失的数据表示
- float_format:格式化浮点数的字符串。例如float_format = ” %。2f”格式为0.1234到0.12。
- columns:列
- header:写出列名。如果给定一个字符串列表,则假定它是列名的别名。
- index:写入行名称(索引)
- index_label:如果需要,索引列的列标签。如果未指定,并且标头和索引为真,则使用索引名。如果DataFrame使用多索引,应该给出一个序列。
- startrow:左上角的单元格行转储数据帧。
- startcol:左上角单元格列转储数据帧。
- engine:编写要使用的引擎“ openpyxl”或“ xlsxwriter”。 您还可以通过选项io.excel.xlsx.writer,io.excel.xls.writer和io.excel.xlsm.writer进行设置。
- merge_cells:将多索引和层次结构行写入合并单元格。
- encoding:对生成的excel文件进行编码。仅对xlwt有必要,其他编写器本身支持unicode。
- inf_rep:表示无穷大。
- verbose:在错误日志中显示更多信息。
- freeze_panes:指定要冻结的最底部的行和最右边的列
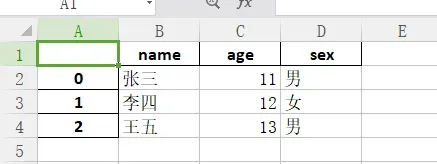
| from pandas import DataFrame |
| data = {‘name’: [‘张三’, ‘李四’, ‘王五’],’age’: [11, 12, 13],’sex’: [‘男’, ‘女’, ‘男’]} |
| df = DataFrame(data) |
| df.to_excel(‘file.xlsx’) |
2023最新Web自动化测试,Python+Selenium自动化环境搭建全套项目实战教程
文章出处登录后可见!