BLIP-2: 图像到文本的生成器

- BLIP-2: Scalable Pre-training of Multimodal Foundation Models for the World’s First Open-source Multimodal Chatbot
1论文摘要
由于大规模模型的端到端的训练,视觉与语言的预训练模型的成本越来越高。本文提出了BLIP-2,这是一种通用的有效的预训练策略,它从现成的冷冻预训练图像编码器与大型的语言模型中引导视觉语言预训练。BLIP-2通过一个轻量级的查询transformer弥补了模态差距,该transformer分为两个阶段进行预训练:第一个阶段从冷冻的图像编码器中引导视觉语言representation learning。第二阶段从一个固定的语言模型中引导视觉到语言的生成学习。
优点:BLIP-2 achieves state-of-the-art performance on various vision-language tasks, despite having significantly fewer trainable parameters than existing methods. For example, our model outperforms Flamingo80B by 8.7% on zero-shot VQAv2 with 54x fewer trainable parameters. We also demonstrate the model’s emerging capabilities of zero-shot image-to-text generation that can follow natural language instructions
- paper:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- huggingface :huggingface
- github:salesforce/LAVIS
- blip-2
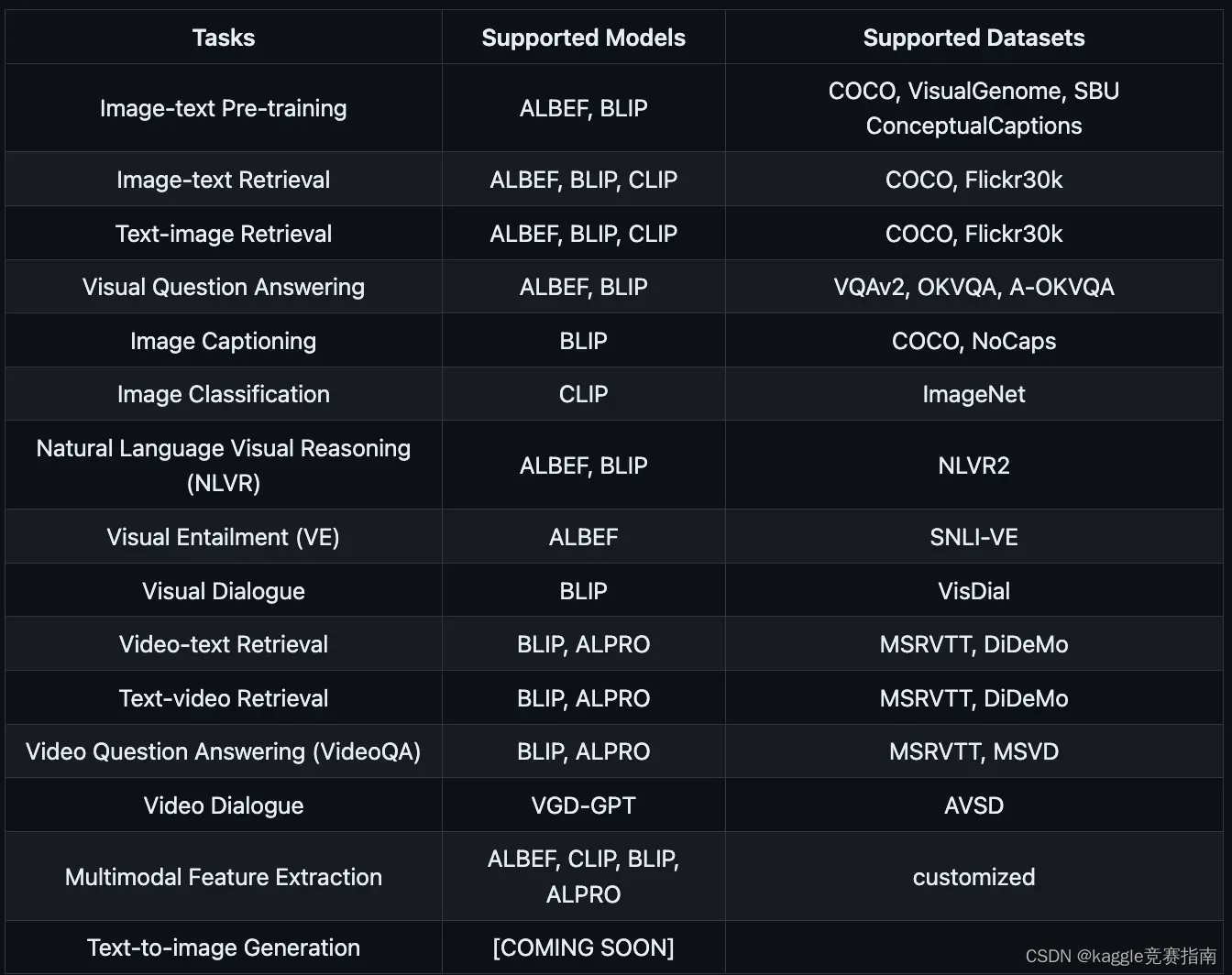
2一些任务的总结对应支持的模型
3BLIP- example

4How BLIP-2 works
llm要理解视觉内容,关键是要弥合视觉语言的情态鸿沟。由于llm在自然语言预训练期间没有见过任何图像,因此弥合模态差距具有挑战性,特别是当llm仍然处于冻结状态时。为此,我们提出了一个用新的两阶段预训练策略预训练的查询转换器(Q-Former)。如下图所示,Q-Former经过预训练后,可以有效地充当冻结的图像编码器和冻结的LLM之间的桥梁,从而缩小了模态差距。
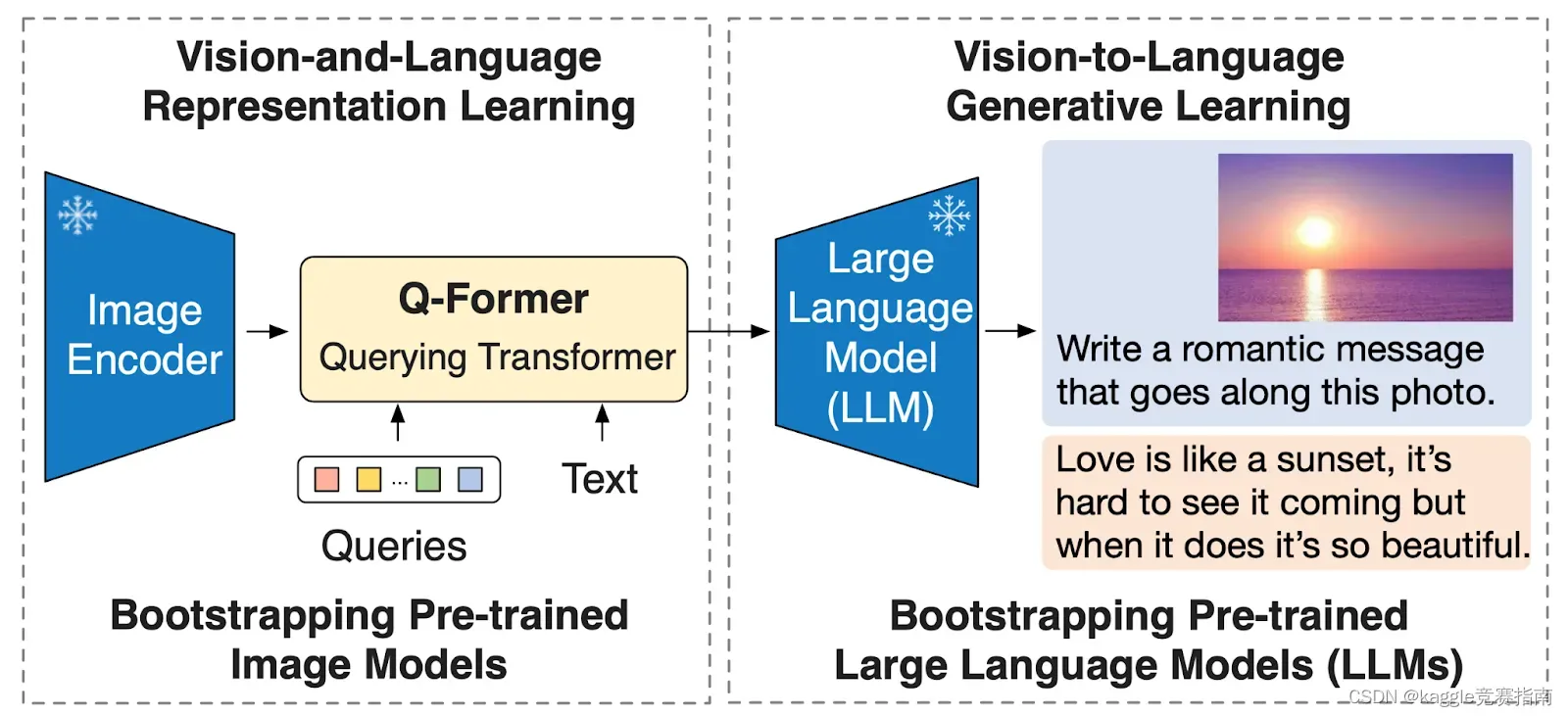
Overview of BLIP-2 two-stage pre-training strategy
- 第一个阶段是视觉和语言表征学习。在这个阶段,我们将Q-Former连接到一个冻结的图像编码器,并用图像-文本对进行预训练。Q-Former学习提取与相应文本最相关的图像特征。我们从BLIP (https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/)中重新设计了用于视觉和语言表示学习的预训练目标。
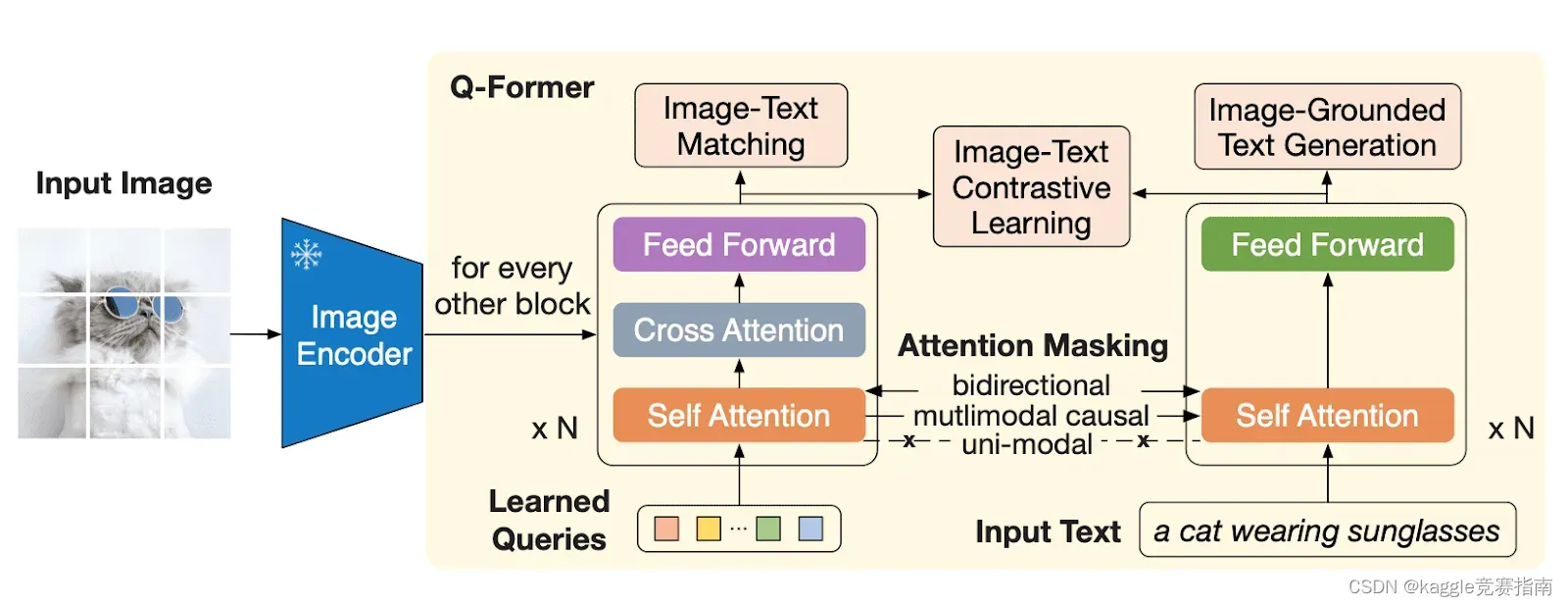
Overview of Q-Former and the first stage of vision-language representation learning in BLIP-2
- 第二阶段是视觉-语言生成学习。在这一阶段,我们将Q-Former的输出连接到冻结的LLM。我们预先训练Q-Former,这样它的输出特征就可以被LLM解释,从而生成相应的文本。我们实验了基于解码器的LLMs(例如OPT)和基于编码器-解码器的LLMs(例如FlanT5)
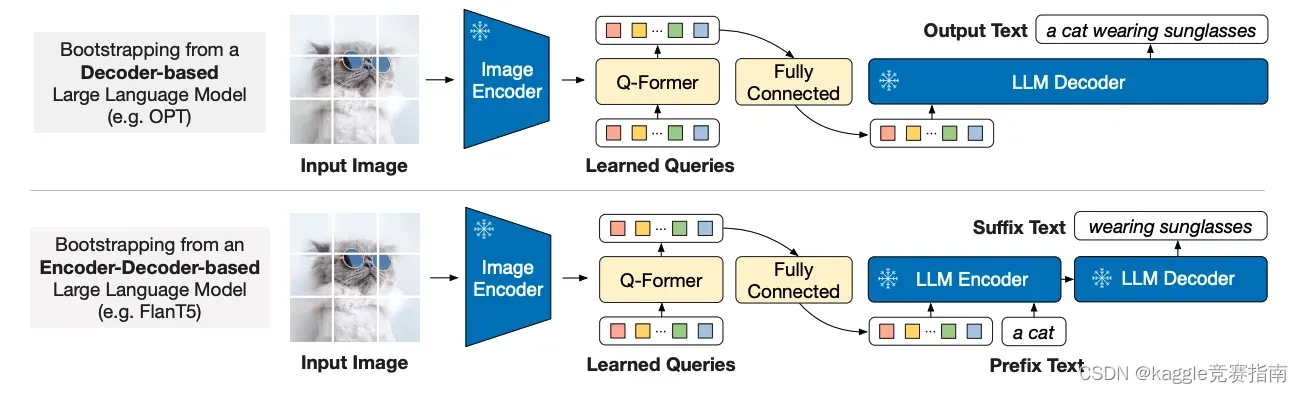
overview of the second stage of vision-to-language generative learning in BLIP-2
在推理过程中,我们只需将文本指令附加在Q-Former的输出之后,作为LLM的输入。我们已经对各种图像编码器和LLM进行了实验,并得出了一个有希望的观察结果:更强的图像编码器和更强的LLM都会导致BLIP-2的更好性能。这一观察结果表明,BLIP-2是一种通用的视觉语言预训练方法,可以有效地收集视觉和自然语言社区的快速进展。BLIP-2是构建多模态对话AI代理的重要突破性技术。
5 BLIP demo
install
pip install salesforce-lavis
library
import torch
from PIL import Image
import requests
from lavis.models import load_model_and_preprocess
示例图像展示
img_url = 'https://storage.googleapis.com/sfr-vision-language-research/LAVIS/assets/merlion.png'
raw_image = Image.open(requests.get(img_url, stream=True).raw).convert('RGB')
display(raw_image.resize((596, 437)))

device
# setup device to use
device = torch.device("cuda") if torch.cuda.is_available() else "cpu"
Load pretrained/finetuned BLIP2 captioning model
# we associate a model with its preprocessors to make it easier for inference.
model, vis_processors, _ = load_model_and_preprocess(
name="blip2_t5", model_type="pretrain_flant5xxl", is_eval=True, device=device
)
vis_processors.keys()
# dict_keys(['train', 'eval'])
将图像处理为模型输入的格式
image = vis_processors["eval"](raw_image).unsqueeze(0).to(device)
生成标题 (using beam search)
model.generate({"image": image})
输出 :# ‘singapore’
generate multiple captions using nucleus sampling
## 由于核采样的不确定性,你可能会得到不同的标题。
model.generate({"image": image}, use_nucleus_sampling=True, num_captions=3)
instructed zero-shot vision-to-language generation
Ask the model to explain its answer.
model.generate({"image": image, "prompt": "Question: which city is this? Answer:"})
[‘singapore’]
model.generate({
"image": image,
"prompt": "Question: which city is this? Answer: singapore. Question: why?"})
[‘it has a statue of a merlion’]
model.generate({
"image": image,
"prompt": "Question: which city is this? Answer: singapore. Question: why?"})
# 'it has a statue of a merlion'
context = [
("which city is this?", "singapore"),
("why?", "it has a statue of a merlion"),
]
question = "where is the name merlion coming from?"
template = "Question: {} Answer: {}."
prompt = " ".join([template.format(context[i][0], context[i][1]) for i in range(len(context))]) + " Question: " + question + " Answer:"
print(prompt)
# generate model's response
model.generate({"image": image,"prompt": prompt})
# 'merlion is a portmanteau of mermaid and lion'
用于比赛中的实战
比赛介绍kaggle竞赛-Stable Diffusion数据分析与baseline
BLIP2 models are very large to load, so I use some techniques such as init_empty_weights.
And in order to submit within 9 hours, a beam width of beam search in decoder is reduced to 3.
代码参照👆github链接
环境安装
# locally downloaded salesforce-lavis
!pip install salesforce-lavis --no-index --find-links=file:///kaggle/input/lavis-pip/
# in order to load local weights files, modified version of salesforce-lavis is required. so firstly uninstall.
!pip uninstall -y salesforce-lavis
# and install modified salesforce-lavis
!pip install salesforce-lavis --no-index --find-links=file:///kaggle/input/lavis-mod-wheel/salesforce_lavis-1.0.0.dev1-py3-none-any.whl
数据
- 数据链接data
在kaggle环境下很难使用BLIP一类的大模型,主要原因是我们在加载权重的时候使用了两倍的显存,于是我改进为使用一倍显存。
库
import os
import gc
import cv2
import sys
import torch
import numpy as np
import torch.nn as nn
import pandas as pd
import polars as pl
import matplotlib.pyplot as plt
from PIL import Image
from lavis.models import load_model, load_preprocess, load_model_and_preprocess
from lavis.processors import load_processor
from lavis.models.blip2_models.blip2_opt import Blip2OPT
from typing import Dict
from sklearn.metrics.pairwise import cosine_similarity
from pathlib import Path
from accelerate import init_empty_weights
sys.path.append('/kaggle/input/sentence-transformers-222/sentence-transformers')
from sentence_transformers import SentenceTransformer, models
节省显存使用
显存不够用?一种大模型加载时节约一半显存的方法
# these helper functions are based on the following repository.
# https://github.com/FrancescoSaverioZuppichini/Loading-huge-PyTorch-models-with-linear-memory-consumption/blob/main/README.md
def get_keys_to_submodule(model: nn.Module) -> Dict[str, nn.Module]:
keys_to_submodule = {}
for submodule_name, submodule in model.named_modules():
for param_name, param in submodule.named_parameters():
splitted_param_name = param_name.split('.')
is_leaf_param = len(splitted_param_name) == 1
if is_leaf_param:
if submodule_name != '':
key = f"{submodule_name}.{param_name}"
else:
key = param_name
keys_to_submodule[key] = submodule
return keys_to_submodule
def load_state_dict_with_low_memory(model: nn.Module, state_dict: Dict[str, torch.Tensor]):
model.to(torch.device("meta"))
keys_to_submodule = get_keys_to_submodule(model)
for key, submodule in keys_to_submodule.items():
val = state_dict.get(key)
if val is not None:
param_name = key.split('.')[-1]
param_dtype = getattr(submodule, param_name).dtype
val = val.to(param_dtype)
new_val = torch.nn.Parameter(val, requires_grad=False)
setattr(submodule, param_name, new_val)
推断部分
comp_path = Path('/kaggle/input/stable-diffusion-image-to-prompts/')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
with init_empty_weights():
my_model = Blip2OPT(opt_model="facebook/opt-2.7b")
class DictWrapper:
def __init__(self, d):
self.dict = d
def __getattr__(self, name):
return self.dict[name]
def get(self, name, default_val=None):
return self.dict.get(name, default_val)
dict_tr = {
"name": "blip_image_train",
"image_size": 224
}
dict_ev = {
"name": "blip_image_eval",
"image_size": 224
}
dict_t = {
"name": "blip_caption"
}
config = {
"vis_processor":{
"train":DictWrapper(dict_tr),
"eval":DictWrapper(dict_ev),
},
"text_processor":{
"train":DictWrapper(dict_t),
"eval":DictWrapper(dict_t)
}
}
vis_processors = load_preprocess(config)[0]
加载模型
#低显存加载模型权重
load_state_dict_with_low_memory(my_model, torch.load("/kaggle/input/blip2-pretrained-opt27b-sdpth/blip2_pretrained_opt2.7b_sd.pth"))
my_model.eval()
gc.collect()
代码核心在此
images = os.listdir(comp_path / 'images')
pred_prompt_list = []
for image_name in images:
image = Image.open(comp_path / 'images' / image_name).convert('RGB')
#图像处理为模型输入格式
image = vis_processors["eval"](image).unsqueeze(0).to(device)
#产生标题(num_beans = 3)将可能的标题都给产出
pred_prompt = my_model.generate({"image": image}, num_beams=3)
#将生成的结果添加到pred_prompt_list中
pred_prompt_list.append(pred_prompt[0])
后续将pred_prompt_list使用官方的all-MiniLM-L6-v2映射到384维度上进行提交
del my_model
gc.collect()
st_model = SentenceTransformer('/kaggle/input/sentence-transformers-222/all-MiniLM-L6-v2')
prompt_embeddings = st_model.encode(pred_prompt_list, batch_size=256).flatten()
imgIds = [i.split('.')[0] for i in images]
EMBEDDING_LENGTH = 384
eIds = list(range(EMBEDDING_LENGTH))
imgId_eId = [
'_'.join(map(str, i)) for i in zip(
np.repeat(imgIds, EMBEDDING_LENGTH),
np.tile(range(EMBEDDING_LENGTH), len(imgIds)))]
submission = pd.DataFrame(
index=imgId_eId,
data=prompt_embeddings,
columns=['val']
).rename_axis('imgId_eId')
submission.to_csv('submission.csv')
文章参考
SDIP BLIP2 baseline public
相关文章
图像分类竞赛进阶技能:OpenAI-CLIP使用范例
文章出处登录后可见!