决策树算法Python实现
- Python决策树实现
- 一、sklearn实现决策树分类
- 1.1 导入sklean中的tree模块
- 1.2 使用sklean的基本流程
- 1.3 DecisionTreeClassifier()的参数解释
- 1.4 剪枝操作
- 1.5绘制决策树
Python决策树实现
一、sklearn实现决策树分类
1.1 导入sklean中的tree模块
from sklean import tree
| 模块 | 解释 |
|---|---|
| tree.DecisionTreeClassifier | 分类树 |
| tree.DecisionTreeRegressor | 回归树 |
| tree.export_graphviz | 将生成的决策树导出为DOT模式,画图专用 |
| tree.ExtraTreeClassifier | 高随机版本的分类树 |
| tree.ExtraTreeRegressor | 高随机版本的回归树 |
1.2 使用sklean的基本流程
- 实例化模型对象
clf = tree.DecisionTreeClassifier()
- 通过模型接口训练模型
clf = clf.fit(X_train,y_train)
- 通过测试集对模型评分(0-1)
Test_score = clf,score(X_test,y_test)
1.3 DecisionTreeClassifier()的参数解释
clf = tree.DecisionTreeClassifier(criterion='entropy/gini',random_state = None,splitter='best/random')
- criterion
criterion这个参数正是用来决定不纯度的计算方法的。skleran提供了两种选择。
输入”entropy”,使用信息熵。
输入“gini”,使用基尼系数。
对于高维数据或者噪音很多的数据,信息熵很容易过拟合,基尼系数在这种情况下效果往往会更好。
- random_state
random_state用来设置分支中的随机模式的参数,默认为None,在高维度时随机性会表示的更加明显。
- splitter
splitter也是用来控制决策树中的随机选项的,有两种输入值。
输入“best”,决策树在分支时虽然随机,但是还是会优先选择更加重要的特征进行分支;
输入”random”,决策树会在分支时更加随机,树会因为含有更多的不必信息而更深更大,可能会导致过拟合问题。
当你预测到你的模型可能会过拟合,用这两个参数可以帮助你降低树建成之后过拟合的可能性。当然,树一旦建成,我们依然是使用剪枝参数来防止过拟合。
1.4 剪枝操作
- max_depth(预剪枝)
限制树的最大深度,超过设定深度的树枝全部剪掉
- min_samples_leaf
一个节点在分支后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分支就不会发生,或者,分支会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生。
- min_samples_split
一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分支,否则分支就不会发生。一般搭配max_depth使用,这个参数的数量设置的大小会引起过拟合,设置的太大会阻止模型学习数据。对于类别不多的分类问题,=1通常就是最佳选择。一般来说,建立从=5开始使用。如果叶节点中含有的样本量变化很大,建立输入浮点数作为样本量的百分比来使用。同时,这个参数可以保证每个叶子的最小尺寸,可以在回归问题中避免低方差,过拟合的叶子节点出现。
- max_features
限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃,和max_depth相似
- min_impurity_decreases
限制信息增益的大小,信息增益小于设定数值的分枝不会发生。
- 确认最优的剪枝参数
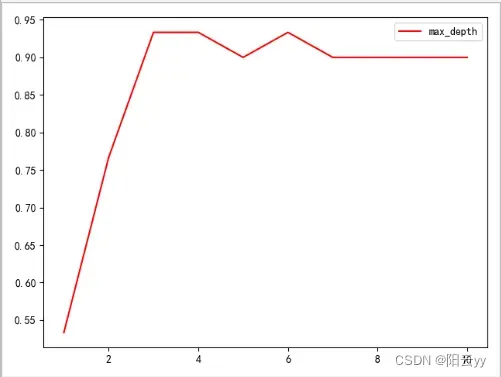
我们已经训练好的决策树模型,确定超参数的曲线来进行判断,超参数的学习曲线,是一条以超参数的取值为横坐标,模型的度量指标作为纵坐标的曲线,它是用来衡量不同超参数取值下模型的表现的线,我们的模型度量指标就是score。
from sklearn.tree import DecisionTreeClassifier
import matplotlib.pyplot as plt
# 训练样本
clf = clf.fit(X_trainer, Y_trainer)
result = clf.score(X_test,Y_test)
print("模型在测试集上进行评分:\n",result)
predict_y = clf.predict(X_test)
print("对测试集样本的预测结果:\n", predict_y)
predict_y1 = clf.predict_proba(X_test)
print("预测样本为某个标签的概率:\n", predict_y1)
# %%
test = []
for i in range(10):
clf = DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(X_trainer, Y_trainer)
score = clf.score(X_test, Y_test)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
score曲线可视化结果:
1.5绘制决策树
- 环境配置
官网下载graphviz安装包进行本地安装;
链接: Graphviz官网
记住安装位置,比如C:\Program Files\Graphviz
配置环境变量:需要分别配置用户环境变量与系统环境变量
用户环境变量配置:找到PATH环境变量;新建输入C:\Program Files\Graphviz\bin(要与安装目录一致);点击确定。
系统环境变量:找到PATH环境变量;新建C:\Program Files\Graphviz\bin\dot.exe(要与安装目录一致);点击确定。
python环境配置:Win+R+cmd进入终端输入pip install graphviz即可安装
注意:环境配置结束后,可能需要重启编译软件生效
- 导入模块
from sklearn.datasets import load_iris
from sklearn import model_selection
import graphviz
from sklearn import tree
- 加载数据
# 加载鸢尾花数据集,X为数据集,y为标签
dataSet = load_iris()
X = dataSet.data
y = dataSet.target
# 特征名称
feature_names = dataSet.feature_names
# 类名
target_names = dataSet.target_names
- 创建决策树模型
# 划分数据集
X_trainer, X_test, Y_trainer, Y_test = model_selection.train_test_split(X, y, test_size=0.3)
# 创建决策树对象
clf = tree.DecisionTreeClassifier(criterion = 'entropy')
# 训练样本
clf_tree = clf.fit(X_trainer, Y_trainer)
score = clf_tree.score(X_test,Y_test)
print("模型在测试集上进行评分:\n",score)
- 模型预测
predict_y = clf.predict(X_test)
print("对测试集样本的预测结果:\n", predict_y)
predict_y1 = clf.predict_proba(X_test)
print("预测样本为某个标签的概率:\n", predict_y1)
- 使用grapviz绘制决策树
clf_dot = tree.export_graphviz(clf_tree,
out_file= None,
feature_names= feature_names,
class_names= target_names,
filled= True,
rounded= True)
graph = graphviz.Source(clf_dot,
filename="iris_decisionTree",
format="png")
graph.view()
print("\n特征重要程度为:")
info = [*zip(feature_names, clf.feature_importances_)]
for cell in info:
print(cell)
- Iris数据集决策树分类结果
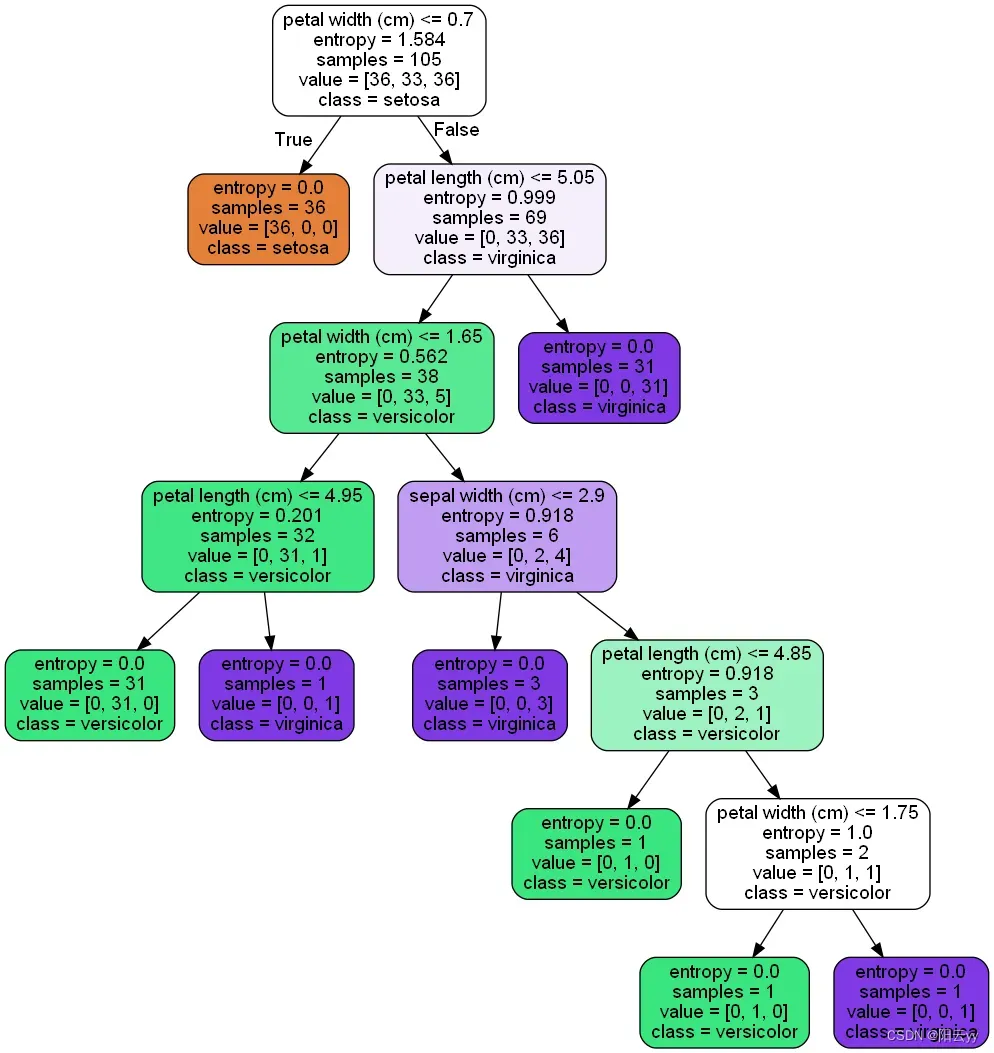
模型在测试集上进行评分:
0.8888888888888888
特征重要程度为:
('sepal length (cm)', 0.0)
('sepal width (cm)', 0.012044591855253375)
('petal length (cm)', 0.0)
('petal width (cm)', 0.9879554081447467)
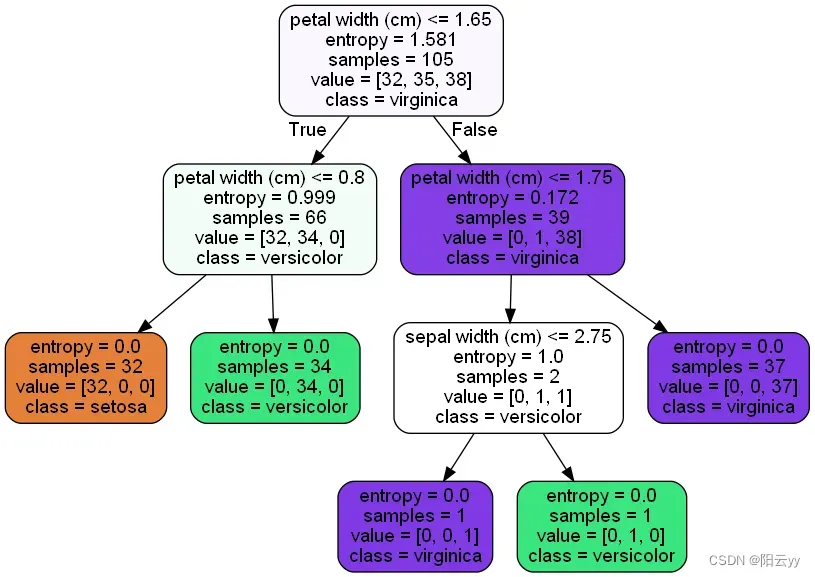
- 根据测试评分进行max_depth调整
clf = tree.DecisionTreeClassifier(criterion = 'entropy',max_depth=3)
调整结果为:
当前学习记录到此结束,后续根据学习继续扩展更新。
文章出处登录后可见!