作者前言
欢迎小可爱们前来借鉴我的gtieehttps://gitee.com/qin-laoda
目录
Beautiful Soup的简介 解析⼯具对⽐ BeautifulSoup的基本使⽤ 解析器 搜索⽂档树 CSS常⽤选择器介绍 select和css选择器提取元素 _______________________________________________前面我已经介绍了正则表达式,下面我们来介绍bs4
Beautiful Soup的简介
Beautiful Soup是python的⼀个库,最主要的功能是从⽹⻚抓取数据,
BeautifulSoup安装 pip install bs4
如图:
我们来看看三种数据提取的方法
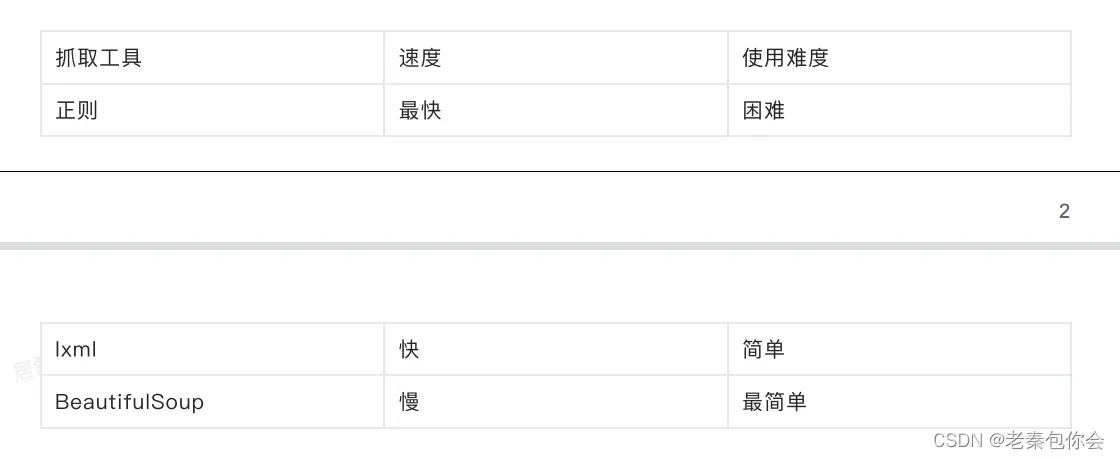
本人建议还是使用xpath获取数据是比较好的,使用简单,本次介绍只是让各位知道方法有很多种,找到适合自己的就行
下面我提供一个网址里面有Beautiful Soup库的多种使用方向,而我们使用bs4就是要使用其中的搜索⽂档树
解析器
GitHub地址: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/ 使用bs4和其他的获取数据的方法不同最主要的是要有 解析器如图:
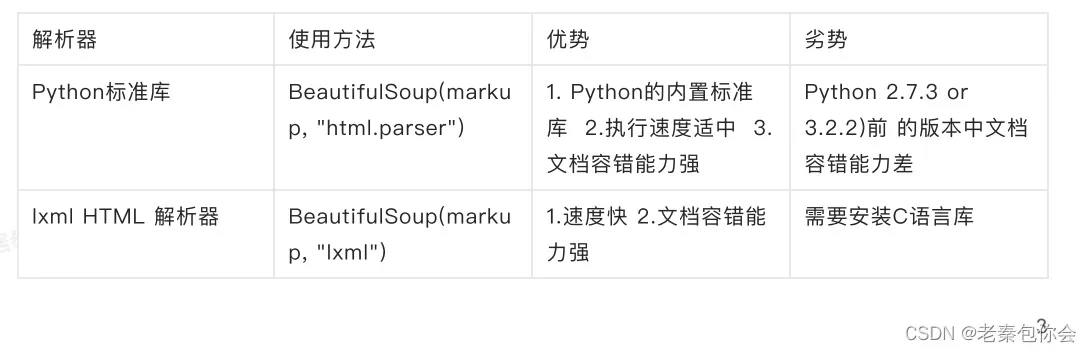
上面只是两个比较常用的,还有一些我没有列举出来,有兴趣的小可爱可以进入到我给的链接进行查看
如图:

def parse_data(self,html):
# 创建一个bs4对象
soup = BeautifulSoup(html,"lxml")
# 查看soup 对象的内容(格式化输出,会自动补全标签)
# print(soup.prettify())
# 获取title标签
print(soup.title)
print(type(soup.title))
print(soup.title.string)
print(soup.title.name)结果:

这里我们简单的介绍一下
soup = BeautifulSoup(html,”lxml”)
soup.title:获取title标签,返回一个bs4类
soup.title.string 获取title标签里面的文本
soup.title.name 获取title标签的名字(标签名字)
注意:这种方法只能获取第一个找到的标签,不能获取到所有的相同的标签
Beautiful Soup定义了很多搜索⽅法,这⾥着重介绍2个: find() 和 find_all() .其
它⽅法的参数和⽤法类似
find()
代码:
def parse_data(self, html):
# 创建一个bs4对象
soup = BeautifulSoup(html,"lxml")
print(soup.find("p"))
print(type(soup.find("p")))
print(soup.find("span",{"class":"con_txt"}))结果:
find(): 获取第一个找到的标签,返回一个bs4对象 ,比较局限
soup.find(“span”,{“class”:”con_txt”})获取到class=”con_txt”的span标签
find_all()
代码:
def parse_data(self, html):
# 创建一个bs4对象
soup = BeautifulSoup(html,"lxml")
print(soup.find_all("p"))
# 获取所有p标签
print(type(soup.find_all("p")))
# 获取所有p标签的前几个
print(soup.find_all("p",limit=2))
# 每个p标签的文本
for p in soup.find_all("p"):
print(p.string)
# .获取所有class等于con_txt的span标签
print(soup.find_all("span",{"class":"con_txt"}))
print(soup.find_all("span",class_="con_txt"))
# 将所有div的id="OrderConfirmDialog_close"和class="ui_widget_close"提取出来
print(soup.find_all("div",{"id":"OrderConfirmDialog_close","class":"ui_widget_close"}))结果(一部分)

获取属性值的方法
代码:
def parse_data(self, html):
# 创建一个bs4对象
soup = BeautifulSoup(html, "lxml")
print(soup.find_all("div", {"id": "OrderConfirmDialog_close"})[0].get("class"))
print(soup.find_all("div", {"id": "OrderConfirmDialog_close"})[0].attrs.get("class"))
print(soup.find_all("div", {"id": "OrderConfirmDialog_close"})[0]["class"])
.get() 和.attrs.get()的区别就是attrs.get()能防止报错
上面第三种方法和字典类似,
获取文本的方法
代码:
def parse_data(self, html):
# 创建一个bs4对象
soup = BeautifulSoup(html, "lxml")
# print(soup.find_all("div",{'class':"content"}))
for i in soup.find_all("div",{'class':"content"}):
print(i.string)
print(i.strings)
print(i.get_text())
print(i.stripped_strings)结果

CSS常⽤选择器介绍
代码(html):
<style type="text/css">
# 选择p标签
p{
background-color:red;
}
# 根据class选择p标签
.line1{
background-color:pink;
}
#line3{
background-color:blue;
}
# div下⾯的p标签
.box p{
background-color:pink;
}
# 选择div class下⾯直接的p标签
.box > p {
background-color:pink;
}
# 选择name=username的input标签
input[name="username"]{
background-color:pink;
}
</style>上面是html代码的类型定义 .代表class # 代码id
select和css选择器提取元素
代码
def parse_data(self, html):
# 创建一个bs4对象
soup = BeautifulSoup(html, "lxml")
soup.select("p")
# 通过标签名获取
print(soup.select("p"))
# 通过类名的来获取标签
print(soup.select(".con_txt"))
# 通过id名来获取标签
print(soup.select("#OrderConfirmDialog_close"))
# 组合查找
print(soup.select("div#OrderConfirmDialog_close"))
print(soup.select("p .con_txt"))
print(soup.select("p span.con_txt"))
利用select来查找数据要懂属于它的语法
我来讲讲组合查找,
“div#OrderConfirmDialog_close”:找到id=OrderConfirmDialog_close的div的标签
“p .con_txt” :找到 class=con_txt的 p标签及p标签里面的其他标签
“p span.con_txt” 找到p标签下class=con_txt的span标签
select()返回的都是列表
全部代码:
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver import ChromeOptions
class Zongheng(object):
def __init__ (self):
pass
def parse_url(self,url):
option = ChromeOptions()
option.add_experimental_option('excludeSwitches', ['enable-automation'])
# 创建一个浏览器
self.driver = webdriver.Chrome(executable_path='E:/python1/chromedriver', options=option)
# 如何实现让selenium规避被检测的⻛险
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""
})
# js 过检
self.driver.execute_script("Object.defineProperty(navigator, 'webdriver', {get: () => undefined})")
# 打开网址
self.driver.get(url)
# def parse_data(self,html):
# # 创建一个bs4对象
# soup = BeautifulSoup(html,"lxml")
# # 查看soup 对象的内容(格式化输出,会自动补全标签)
# # print(soup.prettify())
# soup.find()
# # 获取title标签
# print(soup.title)
# print(type(soup.title))
# print(soup.title.string)
# print(soup.title.name)
# def parse_data(self, html):
#
# # 创建一个bs4对象
# soup = BeautifulSoup(html,"lxml")
# print(soup.find("span",{"class":"con_txt"}))
# print(type(soup.find("span",{"class":"con_txt"})))
# def parse_data (self, html):
#
# # 创建一个bs4对象
# soup = BeautifulSoup(html, "lxml")
#
# print(soup.find_all("p"))
# # 获取所有p标签
# print(type(soup.find_all("p")))
# # 获取所有p标签的前几个
# print(soup.find_all("p", limit=2))
#
# # 每个p标签的文本
# for p in soup.find_all("p"):
# print(p.string)
#
# # .获取所有class等于con_txt的span标签
# print(soup.find_all("span", {"class": "con_txt"}))
# print(soup.find_all("span", class_="con_txt"))
#
# # 将所有div的id="OrderConfirmDialog_close"和class="ui_widget_close"提取出来
# print(soup.find_all("div", {"id": "OrderConfirmDialog_close", "class": "ui_widget_close"}))
# def parse_data(self, html):
# # 创建一个bs4对象
# soup = BeautifulSoup(html, "lxml")
#
# print(soup.find_all("div", {"id": "OrderConfirmDialog_close"})[0].get("class"))
# print(soup.find_all("div", {"id": "OrderConfirmDialog_close"})[0].attrs.get("class"))
# print(soup.find_all("div", {"id": "OrderConfirmDialog_close"})[0]["class"])
# def parse_data(self, html):
# # 创建一个bs4对象
# soup = BeautifulSoup(html, "lxml")
#
# # print(soup.find_all("div",{'class':"content"}))
# for i in soup.find_all("div",{'class':"content"}):
# print(i.string)
# print(list(i.strings))
# print(i.get_text())
# print(i.stripped_strings)
def parse_data(self, html):
# 创建一个bs4对象
soup = BeautifulSoup(html, "lxml")
soup.select("p")
# 通过标签名获取
print(soup.select("p"))
# 通过类名的来获取标签
print(soup.select(".con_txt"))
# 通过id名来获取标签
print(soup.select("#OrderConfirmDialog_close"))
# 组合查找
print(soup.select("div#OrderConfirmDialog_close"))
print(soup.select("p .con_txt"))
print(soup.select("p span.con_txt"))
def main (self):
"""主要的业务逻辑"""
# url
url = "https://book.zongheng.com/chapter/1216709/68382502.html"
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
# 发送请求获取响应
self.parse_url(url)
# print(self.driver.page_source)
html=self.driver.page_source
# 数据的提取
self.parse_data(html)
# 保存
if __name__ == '__main__':
zongheng = Zongheng()
zongheng.main()
这里我就不讲保存了,后面xpath会讲
总结
以上就是我所讲的内容,如果想要bs4爬取网址的代码可以进入我的giteehttps://gitee.com/qin-laoda
文章出处登录后可见!