一、什么是AI视频智能分析?
视频智能分析已渗透到生活生产中的方方面面。从生活中的刷脸支付、停车场的车牌识别、工厂园区的烟火识别、工地的工装安全帽识别到车间零部件智能检测,视频智能分析无处不在。简单来说,AI视频智能分析是通过人工智能技术处理和分析视频数据的方法。
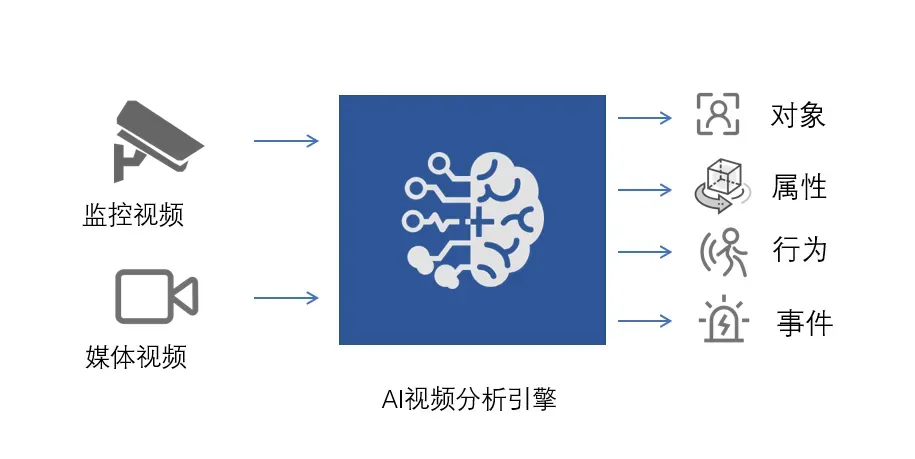
图1. AI视频智能分析示意图
如图1所示,监控视频与媒体视频经AI视频分析引擎分析处理,输出对象、属性、行为以及事件。
对象分析:视频分析的重要任务是结构化目标的识别,包括人、车、物的位置与类别信息,结合业务系统产生价值应用。如人员电子围栏、车流量统计等应用。
属性分析:属性是被测目标颜色、大小、长宽、位置等描述性信息。可靠稳定的属性信息可产生极具价值的业务应用。如钢厂板材的长款测量、板材的位置追踪等应用。
行为分析:行为是被测目标在特定时间段内产生的动作以及表现出的行为等描述性信息。与属性分析相比时序特性更明显,因此,在技术实现上也更加复杂。可应用至异常行为动作或动作流程检测中。如打架检测、摔倒检测、操作规范检测中。
事件分析:事件是对象、属性、行为等要素的综合。事件分析为强业务导向分析,通过AI视频分析引擎建立端到端的事件智能分析。如跨模态视频检索,通过输入对象、属性、行为等文字性描述,检索目标视频。
二、AI视频智能分析有那些技术?
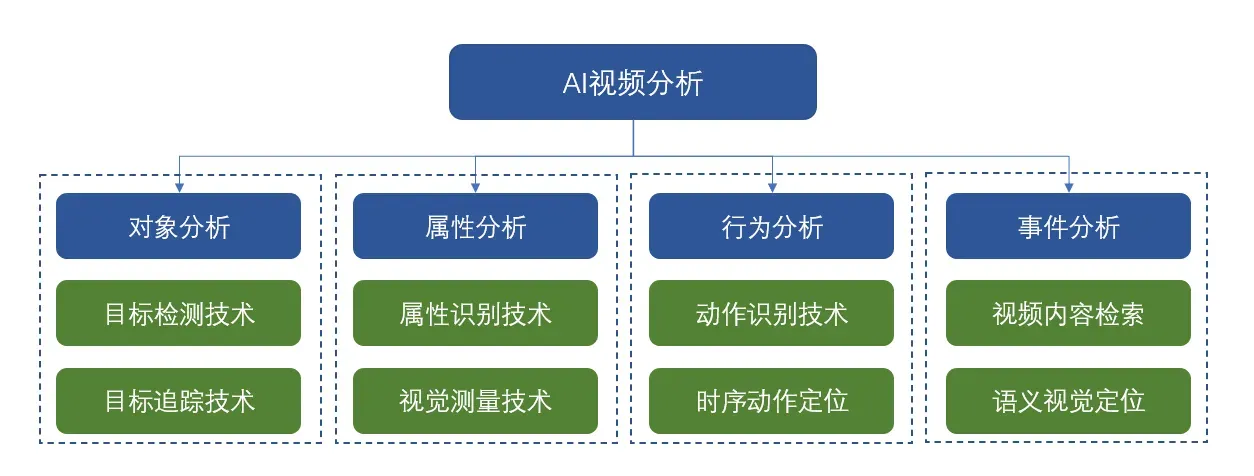
图2. 视频内容分析技术
1、目标检测技术
目标检测任务是识别目标类别并定位目标在图像中位置。因此,其解决的问题为是什么?在哪?
基于深度学习的目标检测发展近十年,成果颇丰,其中代表性方法包括基于anchor的one stage与two stage方法。下面介绍two stage经典模型Faster-RCNN以及one stage经典模型Yolov5。
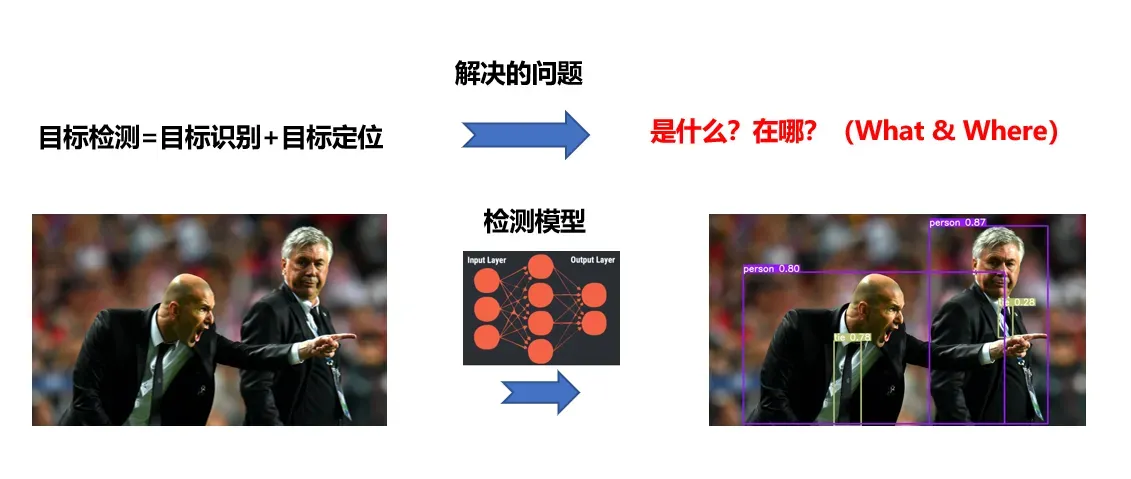
图3 目标检测示意图
一阶段与两阶段的区别在于是否需要生成Proposal box。两阶段模型首先通过RPN网络生成无类别的Proposal box,再经模型分类Proposal box类别并精确回归Proposal box坐标;一阶段模型通过anchor机制直接预测目标类别与目标坐标。两者区别如图4所示。
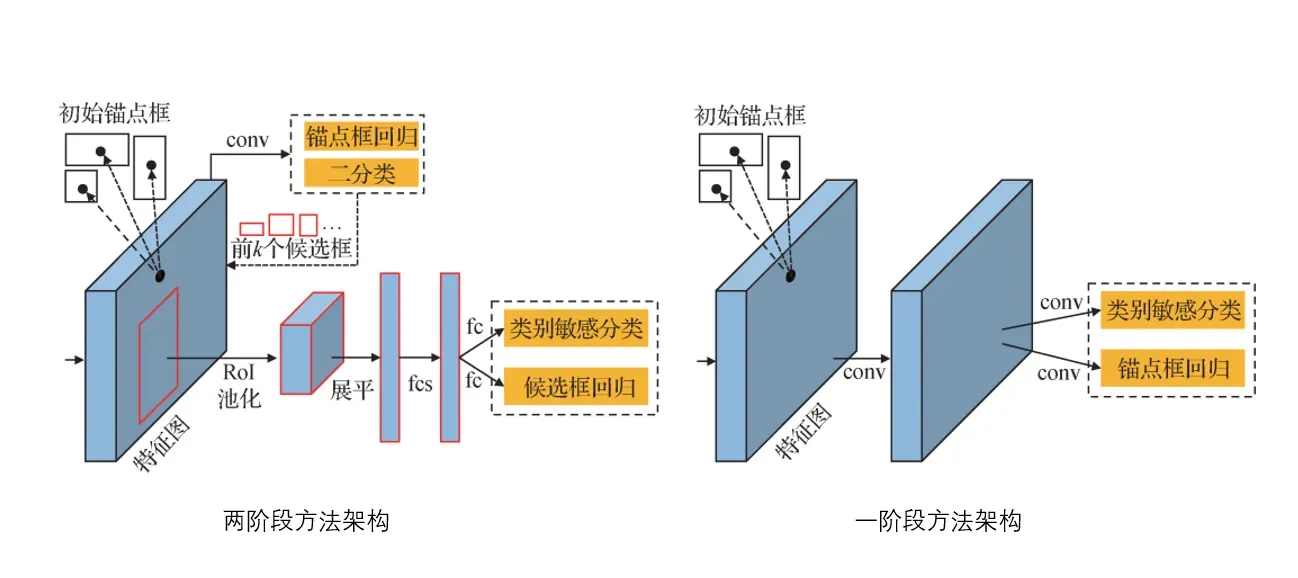
图4. 两阶段与一阶段方法架构
(1)Faster-RCNN
Faster-RCNN网络结构如图5所示,分为stage1与stage2。stage1主要任务是依靠rpn网络生成proposal boxes; stage2主要是任务是对proposal box进行分类与精确定位。下面介绍其细节。
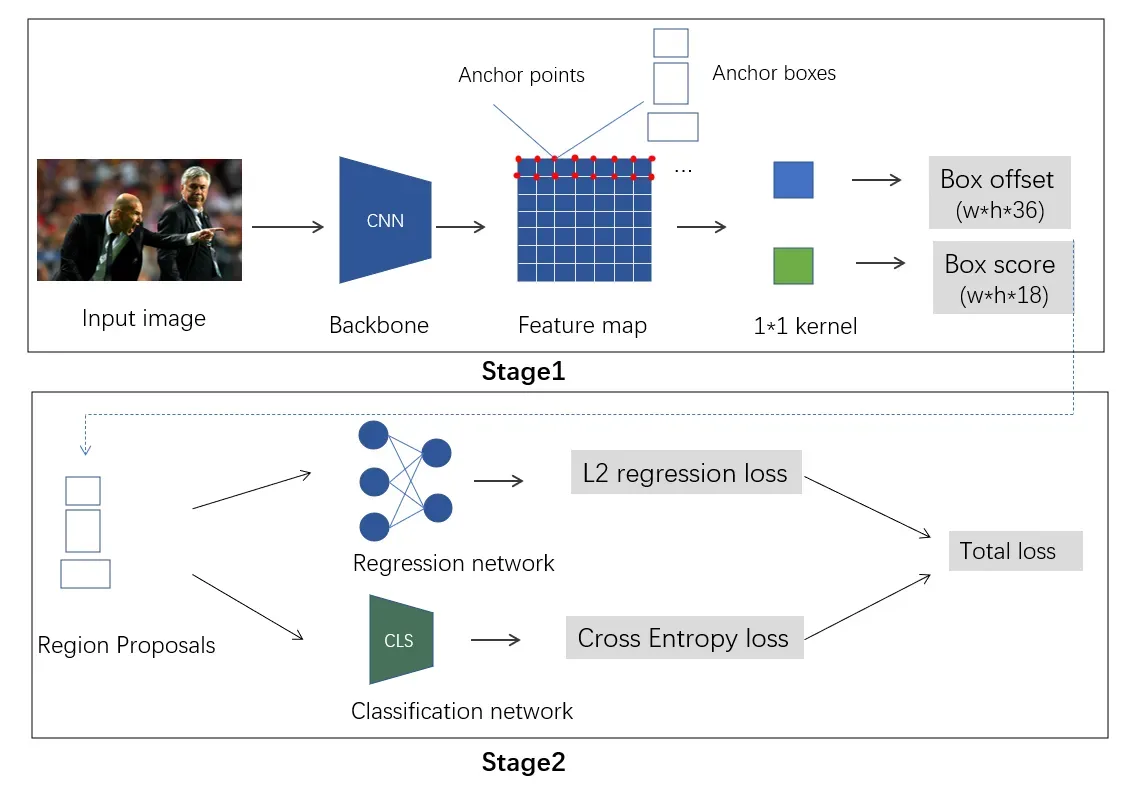
图5. Faster RCNN网络示意图
第一阶段:原始图像经backbone提取特征并输出feature map。backbone为vgg16,经16倍下采样并后接512个3*3*512的filters输出feature map。feature map的每个点作为anchor point并以此产生3种比例与3种大小的anchor box,因此,每个feature map上的每个点处负责预测9种anchor的类别与偏移量。为此,在feature map后接18个1*1*512的filters,提取18种特征,预测9个anchor为前景或背景的概率;在feature map后接36个1*1*512的filters,提取36种特征,预测9个anchor的4个坐标。我们在feature map的每个点上分配了9个anchor boxes。为训练RPN网络中的分类(二分类)与回归,需要对每个anchor进行标注,即标注每个anchor box为1(前景)或0(背景)以及每个anchor box的ground truth的坐标。对于一个60*40的feature map来说产生的anchor box为60*40*9=21.6k个,去除边界处越界的框,并经过nms处理剩余6k左右。最后通过每个anchor box的score得分排序筛选出128个前景与128个背景anchor box,利用这256个anchor box进行RPN训练。正样本的选取条件为:a) 与groundtruth具有最大IOU的anchor box;b)与任意的groudtruth的IOU大于0.7的anchor box。满足a)或b)任意一个条件则可被选为正样本。负样本的选取条件为:与所有的groundtruth的IOU均小于0.3。 IOU在0.3-0.7之间的anchor box忽略不参与训练。经过RPN网络训练,原始图像经RPN网络会输出256个proposal。
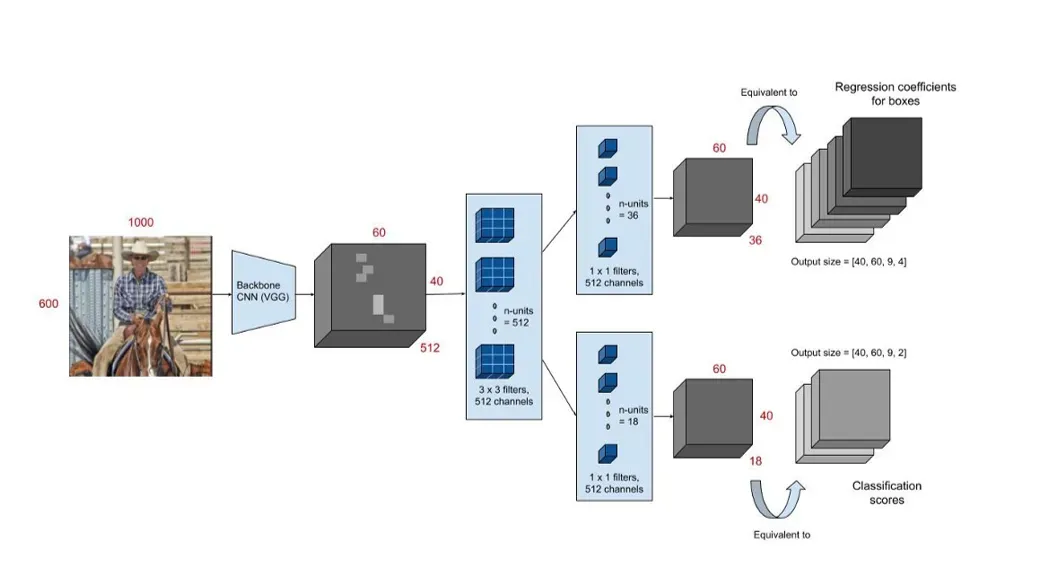
图6. RPN网络结构图
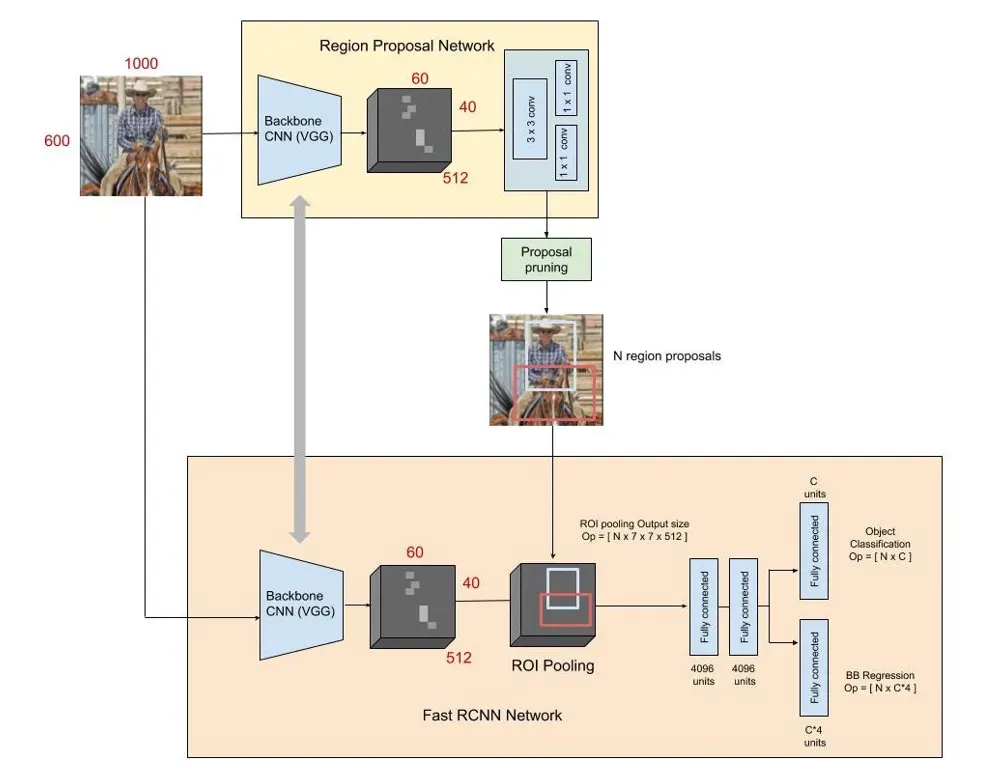
图7. Faster RCNN网络结构图
第二阶段:原始图像经RPN网络产生一系列proposal boxes。这些proposal boxes会在backbone所产生的feature map上提取相应特征,由于每个proposal box的大小不同,后续网络连接了全连接层因此要求每个proposal box的输出大小恒定,为此对于每个proposal box后接ROI Pooling模块将每个proposal box的输出转换为7*7*512后接全连接层用于proposal box的分类与坐标回归。
其训练过程分为四步:
第一步:单独训练RPN网络,使用ImageNet分类任务的权重对Backbone CNN网络进行初始化。并且端到端微调用于生成region proposal(整个RPN网络权重均更新)。
第二步:单独训练Fast RCNN网络,使用ImageNet分类任务的权重对Backbone CNN网络进行初始化,使用RPN生成的proposal作为输入训练Fast RCNN网络(整个Fast RCNN网络权重均更新)。
第三步:微调RPN网络,利用Fast RCNN网络对RPN网络与Fast RCNN网络的共享卷积层进行初始化,同时固定共享卷积层,只微调RPN网络独有的部分,完成训练得到最终的RPN网络(只更新RPN网络独有的部分)。
第四步:微调Fast RCNN网络,利用第三步模型对Fast RCNN的共享卷积层进行初始化,同时固定共享卷积层,只微调Fast RCNN网络独有的部分,完成Fast RCNN网络训练(至更新Fast RCNN网络独有部分)。
经过以上四步,RPN与Fast RCNN共享卷积层保持一致,并独自享有各自的网络部分,完成region proposal生成与Fast RCNN目标检测。
总的来说Faster RCNN的核心为RPN网络,解决了传统selective search在候选框生成上的速度问题。并成为两阶段目标检测模型的典范。
(2)Yolov5
图8. yolov5结构示意图
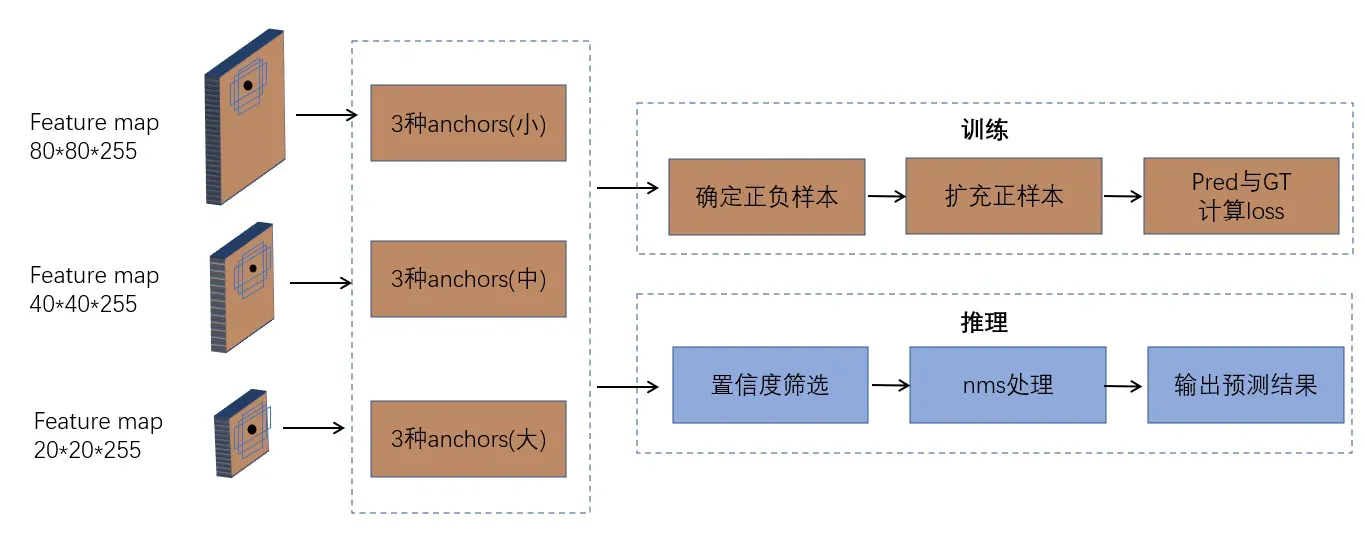
图9. yolov5训练与推理
yolov5的网络结构示意图如图8所示,分为输入层、特征提取层、特征融合层、检测层以及输出层。
特征提取层:采用CSP-Darknet53作为Backbone。提取1/8,1/16以及1/32图像特征。其核心主要由CBS算子、C3算子以及SPPF算子构成。
特征融合层:采用FPN以及PAN作为特征融合层。YOLO系列将Faster-RCNN网络结构中的RPN层进行了改造使其能够直接预测目标类别而不是预测是否为前景。Faster-RCNN是在下采样16倍之后的特征图上做Region Proposal的预测。假如统一采用下采样16倍的特征图直接预测目标会导致小目标类别难以预测,原因是16倍下采样率网络层数较浅,用于分类的语义特征不够丰富。而如果为提高小目标语义特征继续下采样特征图,会导致小目标类别与位置预测精度下降,原因是小目标在原图中占的像素少,下采样倍数过大导致在最终的特征图中占的像素非常少,甚至小于1*1(比如20*20下采样32倍为0.625*0.625),因此特征图中用于预测的像素点可能包含其他物体或背景的特征导致类别与坐标预测精度下降。同时对于大目标的预测,深层特征能够提取丰富的语义特征用于其类别判定,但随着网络层数的加深,网络提取的特征感受野大、整体性强,但是局部细节信息不准确,而这些局部的细节特定包含着物体的位置信息,因此,网络层数的加深对于大目标的检测位置信息不够准确。为此,YOLO系列引入了多尺度检测层FPN,下采样率大的检测层感受野大,用于检测大目标;下采样率小的检测层感受野小,用于检测小目标。下采样率小的浅层特征细节与位置信息丰富;下采样率大的深层特征整体与语义信息丰富。在检测小目标时,将深层特征进行上采样并与浅层特征在通道方向上进行叠加;在检测大目标时,将融合后的浅层特征直接下采样并与深层特征在通道方向上进行叠加。特征融合层充分利用深层网络语义特征用于识别;充分利用浅层网络位置特征用于定位。
检测层:YOLO在检测层上采用了三种尺度,用于检测大、中、小三种不同尺寸的目标。在三个检测层中,每个检测层特征图上的每个点分配三个不同形状尺寸的anchor,并由检测层在每个点处预测物体类别、物体相对于每个anchor的偏移量,物体相对于anchor的宽与高。对于每个点预测3*(80+4+1)=255种元素。因此,对于20*20,40*40以及80*80的三种检测头,预测输出为8400*3*(80+4+1)=25200*85。其中,80表示80类目标,4为目标相对于anchor中心点的偏移量x,y、目标宽与anchor宽的比例因子w,目标高相对于anchor高的比例因子h,1表示目标置信度。
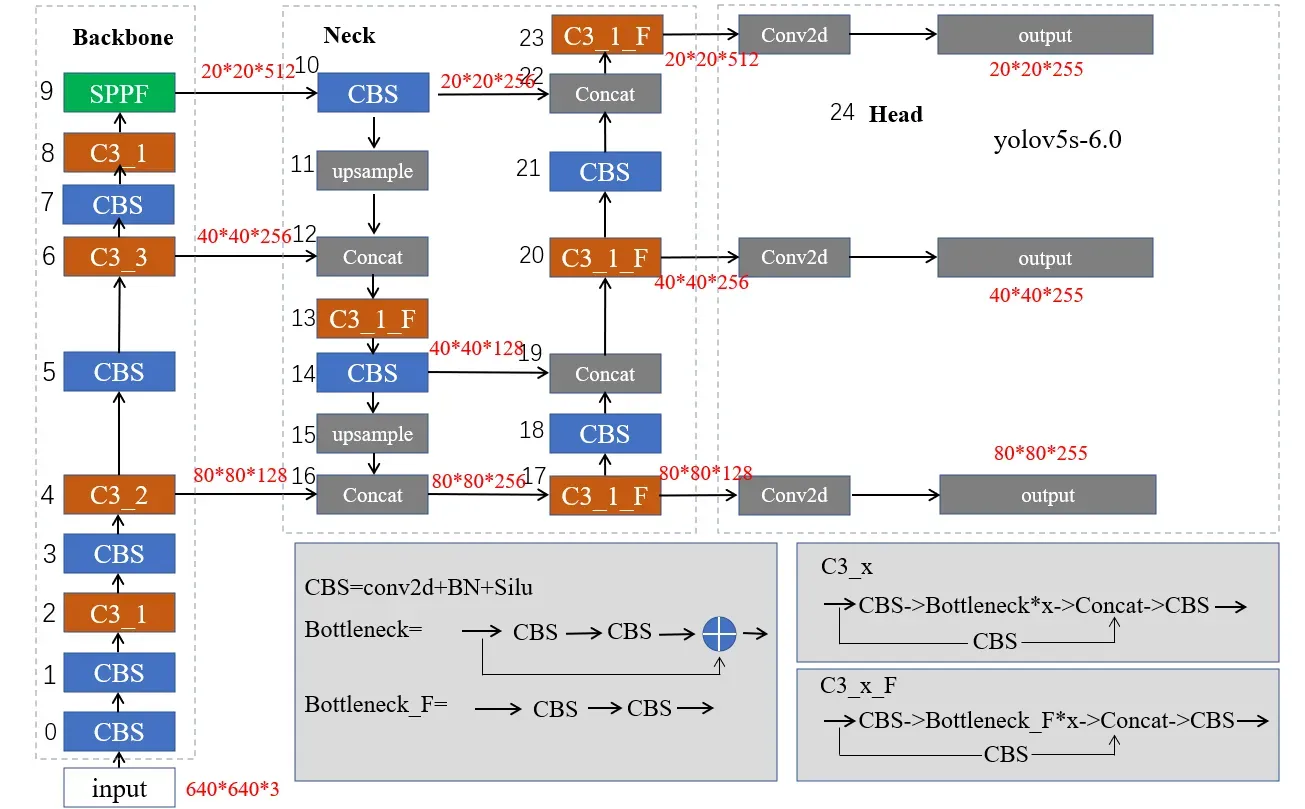
图10. yolov5s-6.0网络结构图
yolov5的训练与推理过程如下:
训练:
a. 定义网络结构yolov5s,m,l,x并获取每张图片的groundtruth;
b. 根据anchor与groundtruth确定正负样本并扩充正样本;
c. 根据正负样本、网络预测值pred以及groundtruth计算loss;
d. 反向传播更新网络参数,设定训练轮数与超参数,完成网络训练,保存网络参数。
推理:
a. 加载网络模型与权重,输入预测图片;
b. 网络前向传播,获取预测结果25200*85;
c. 根据置信度阈值0.45过滤部分结果,根据nms对预测结果再次过滤;
d. 输出目标检测结果x,y,w,h,c,p。
有关正负样本的确定方法如下:
yolov5的正负样本确定方法不同于Faster-RCNN中的RPN网络以及yolov3中的基于IOU划分方法。其依据的规则为groundtruth与anchor的宽高比,同时一个groundtruth可由多个anchor预测,一方面增加了目标召回的几率,另一方面增加了正样本数量缓解了正负样本不均衡问题。
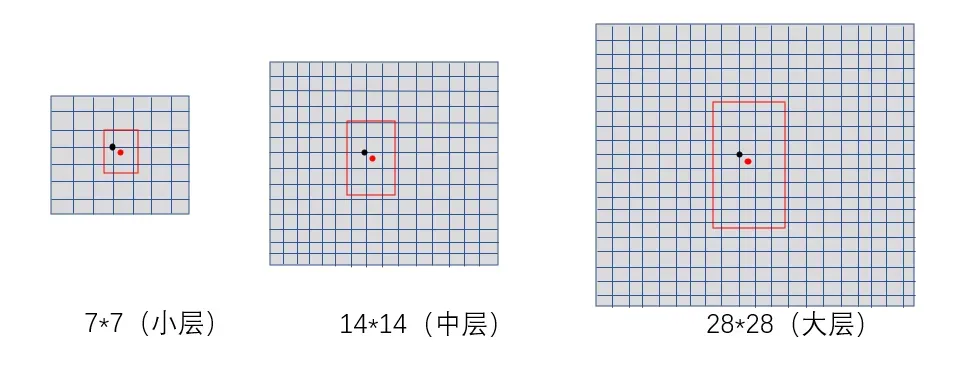
图11. yolov5跨分支预测
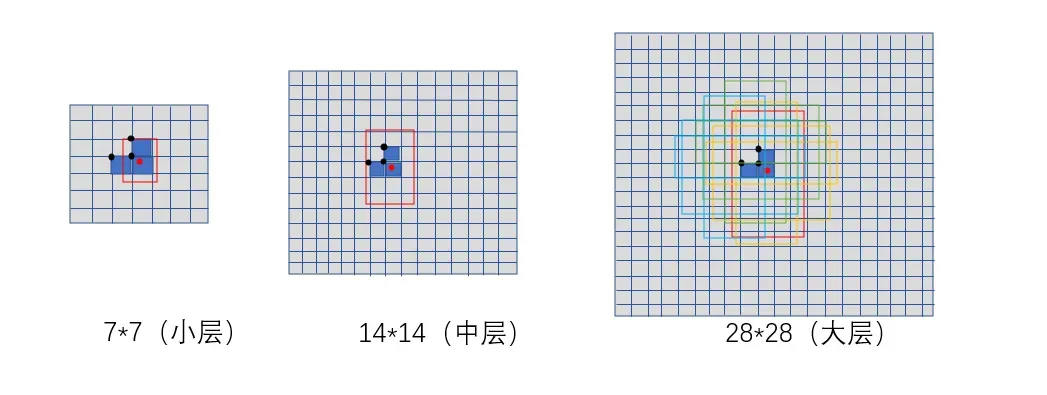
图12. yolov5跨grid以及跨anchor预测
跨分支预测:
不同于yolov3,一个groundtruth只能由一个anchor预测,即也只能通过一个分支预测。yolov5可以通过三个分支同时对目标预测,优势如上述。如图11所示,一个groundtruth最多可由三个分支的anchor同时预测,只要其满足正样本的条件。
跨grid预测:
yolov5为扩增正样本,以负责预测目标的grid为中心,从其上、下、左、右四个方向选择两个距离groundtruth中最近的两个grid也负责预测该目标。这样预测groundtruth的grid由1个变为3个。
跨anchor预测:
yolov5采用基于宽高比的匹配策略。记groundtruth宽高与anchor的宽高比为r1, anchor的宽高与groundtruth宽高记为r2。在r1与r2中选择大值记为r。若r<4,则该anchor为正样本。因此,对于1个groundtruth, 与之匹配的anchor最多为3*3*3=27个。
例如:图12中与红色的groundtruth匹配的anchor有branch1_grid1_anchor1,branch2_grid1_anchor等。
2、目标跟踪技术
目标跟踪的任务是关联时序目标身份,简单的说是当前目标是上一时刻的哪个目标?因此,其解决的主要问题为目标数据关联与匹配。目标跟踪技术应用领域广泛,小到目标计数统计、大到军事精确制导。
如图13所示,时刻1检测出两个目标,并记为目标a,目标b;时刻2检测出两个目标,并记为目标a’,目标b’。跟踪即判断a’是上一时刻的a还是b,同理判断b’是上一时刻的a还是b。这样对于每个目标分配一个唯一id, 相同的目标共享同一id,随着时间推移,相同的目标在时间上与空间上被关联到了一起,每个目标形成一条轨迹。据此可进行业务功能的应用与分析。
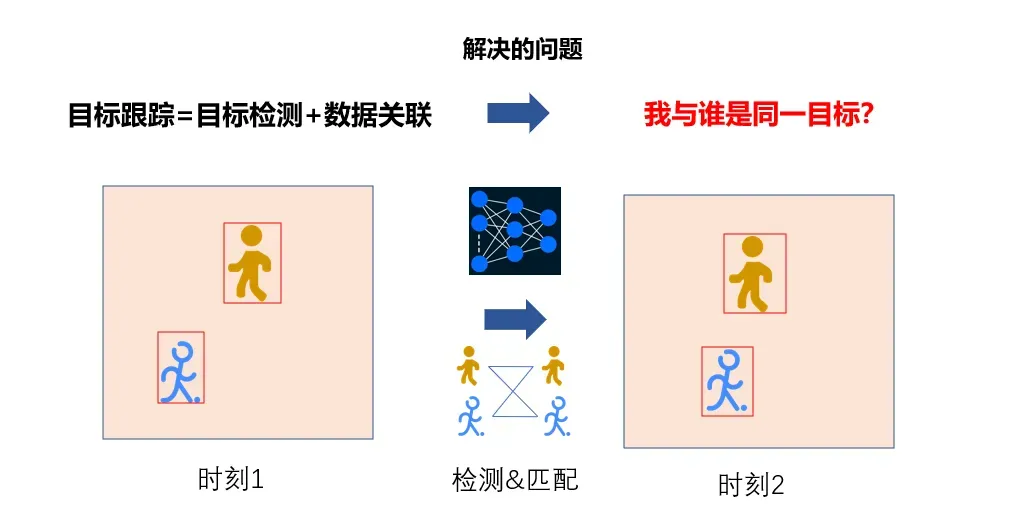
图13. 目标追踪示意图
对于目标追踪其核心问题为数据的关联匹配。因此,需要设计一个判断准则来评价两个目标是否相似。总的来说这些方法主要包括:
a. 距离相似性度量
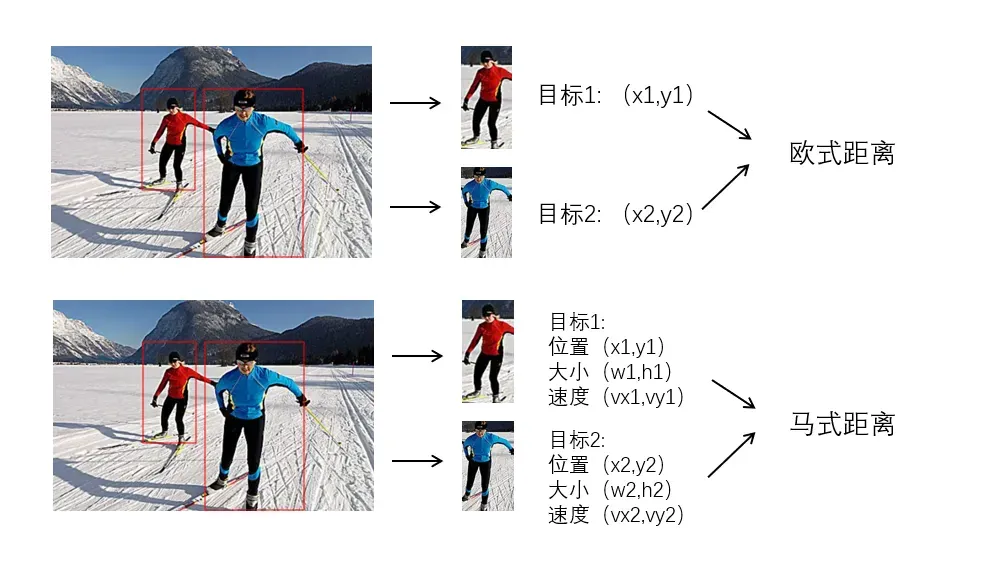
图14. 距离相似性度量示意图
距离相似性度量主要以位置、大小、形状、速度等指标,采用欧式距离或马氏距离评价两目标的相似性。对于量纲一致且变量之间独立无相关性的可采用欧式距离。反之,采用马氏距离。
b. 外观相似性度量
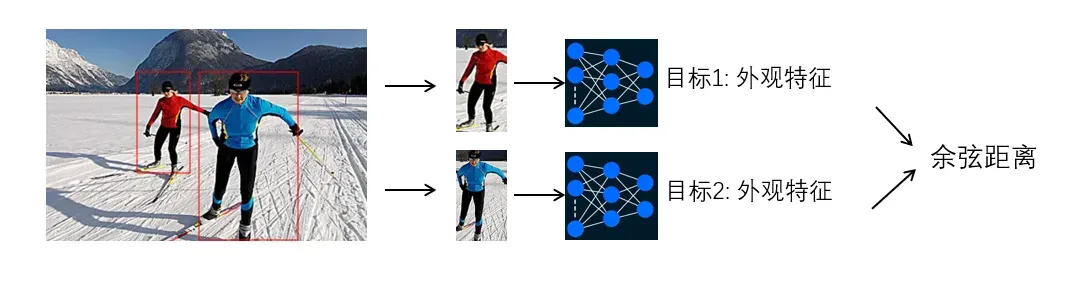
图15. 特征相似性度量示意图
外观相似性度量采用目标外观特征评价相似性,这些特征主要通过神经网络提取,例如,deepsort提取每个目标的128维特征并采用余弦距离度量其相似性。
c. 位置相似性度量
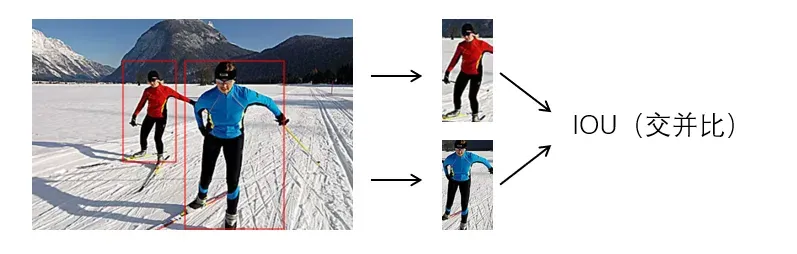
图16. 位置相似性度量示意图
位置相似性度量的另一常用指标为IOU(交并比),两个目标重叠的区域与两个目标集合的区域的比值,可评价两个目标的重叠区域,且为无量纲的指标范围0-1,完全重叠为1,无重叠为0。
为熟悉目标追跟实现原理,下面介绍目标跟踪的经典算法deepsort。在介绍之前需了解其前身sort算法。
(1)sort
sort全称simple online and realtime tracking,是多目标跟踪算法(mot)。核心思想:基于目标检测结果,采用卡尔曼滤波算法与匈牙利算法关联前后目标,实现跟踪。具体算法流程如下:
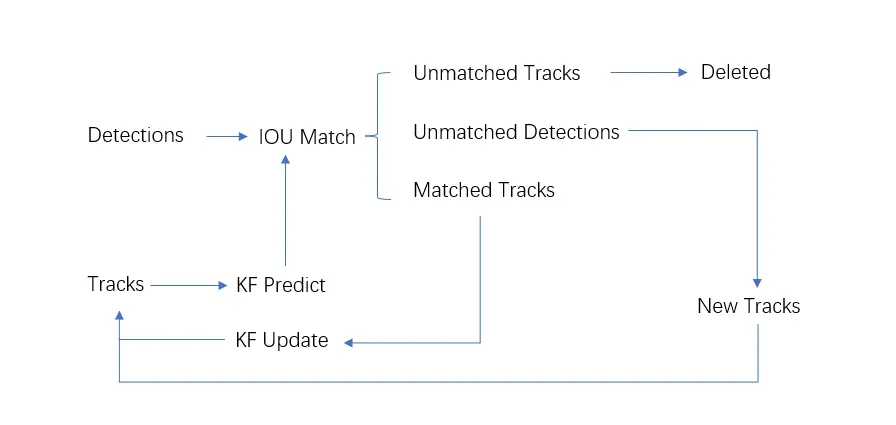
图17. sort算法流程图
概要流程:检测当前帧目标->当前帧目标与上一帧轨迹匹配->预测下一帧轨迹。
详细算法整体流程如下:
第一步:利用第一帧检测到的Detections创建对应的Tracks,初始化卡尔曼滤波,并基于该帧的Tracks预测下一帧Tracks。
第二步:检测当前帧的Detections并与上一帧预测的Tracks进行IOU Match。得到匹配代价矩阵Cost Matrix。
第三步:匈牙利算法根据cost matrix对当前帧所有目标的检测框与上一帧预测得到的轨迹框的匹配。匹配结果有三种。第一种,检测框与轨迹框匹配得到Matched Tracks;第二种检测框未匹配到轨迹框得到Unmatched detections;第三种,轨迹框未匹配到检测框得到Unmatched Tracks。
第四步: 对Matched Tracks更新卡尔曼滤波并预测下一帧Tracks;对Unmatched Detections分配新的Tracks并初始化卡尔曼滤波,预测下一帧Tracks;对Unmatched Tracks直接删除。
第五步: 重复第二步至第四步,至视频结束。
sort算法有什么问题?
sort算法只利用了位置、大小、速度等信息的相似性度量,速度快是其优势。但是,其存在同一目标id,切换频繁的问题,即同一目标在跟踪过程中会跟丢。这主要由以下原因造成:
第一,目标长时间遮挡,重新出现,造成跟踪丢失。原因,一方面目标经遮挡后重新出现的运动信息与遮挡前预测的运动信息存在差异,无法匹配;另一方面,Unmathed Tracks无保留机制已经被删除,重新出现只能重新分配New Tracks.
第二,目标漏检,重新检出,ID重新分配。由于检测器的性能,当前帧目标未检出,上一帧Tracks被判为Unmatched Tracks被删除,重新检测的目标只能重新分配新的ID,造成目标跟丢。
(2)deepsort
为解决长时间遮挡跟丢的问题,提出了deepsort算法。deepsort全称simple online realtime tracking with a deep association metric。相比于sort主要引入了外观相似性度量解决长时间遮挡跟丢问题。
在sort基础上增加的部分:Matching Cascade, Tracks Confirmed机制。整体流程图如下:
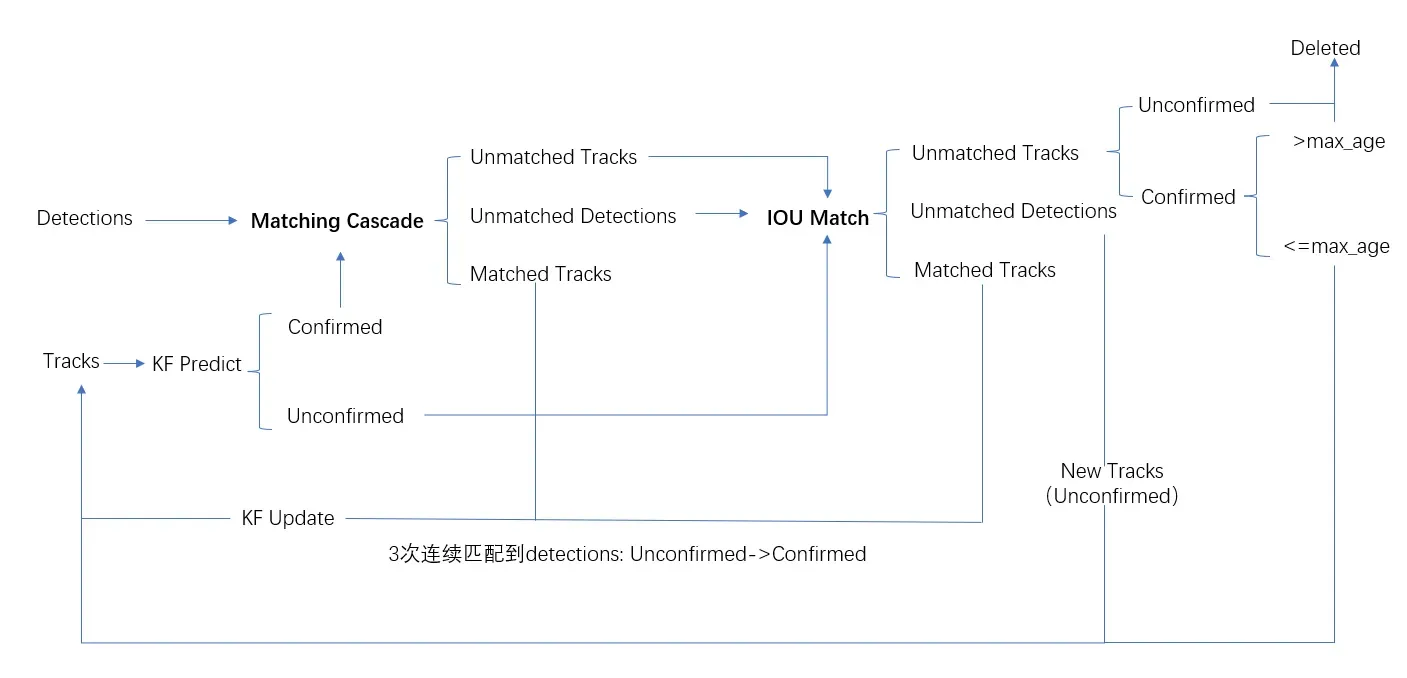
图18. deepsort算法流程图
概要流程:检测当前帧目标->当前帧目标与上一帧轨迹匹配(Matching Cascade& IOU Match)->预测下一帧轨迹。
详细算法整体流程如下:
第一步:利用第一帧检测到的Detections创建对应的Tracks,并初始化卡尔曼滤波,预测下一帧的Tracks。第一帧预测的Tracks状态为Unconfirmed状态,Tracks连续3帧匹配到Detections才转化为Confirmed状态。
第二步:检测当前帧的Detections,并与上一帧的Tracks进行IOU Matching,计算两者代价矩阵Cost Matrix。
第三步:对于Unconfirmed Tracks, 根据Cost Matrix以及匈牙利算法,对Detections与Tracks进行匹配。匹配结果有三种,第一种,Detections与Tracks完成匹配得到Matched Tracks;第二种,Detections未匹配到Tracks,这时为Detections分配一个新的Tracks;第三种Tracks未匹配到Detections,此时由于Tracks一次都没有匹配到Detections,因此,为Unconfirmed状态,直接删除该Tracks。对于Matched Tracks更新卡尔曼滤波,并预测下一帧Tracks;对于New Tracks初始化卡尔曼滤波并预测下一帧Tracks。
第四步:反复进行第二步与第三步,至出现Confirmed Tracks或视频结束。
第五步:通过卡尔曼滤波预测下一帧的Confirmed Tracks与Unconfirmed Tracks。对于Confirmed Tracks,执行Matching Cascade级联匹配Detections与上一帧Tracks。级联匹配策略:外观信息欧式距离与运动信息马氏距离的加权来评价两目标的相似性。对于外观信息,每次Tracks与Detections匹配上,都会保存匹配的Detections的外观特征,每个Tracks最多包含100个最新的历史外观特征,当前帧Detections与每个Tracks的100个历史外观特征进行欧式距离计算,并取最小的距离作为当前Detection与该Track的外观相似度。对于运动信息,当前帧Detections与上一帧Tracks计算马氏距离。对Detections与Tracks所计算的外观相似度与运动信息马氏距离的加权和作为Cost Matrix。在实际的操作中,代价矩阵的计算只利用了外观相似度。根据匈牙利算法对Detections与Tracks进行匹配。对匹配结果,通过Detections与Tracks的外观相似度与马氏距离的乘积门限阈值进行过滤。注意:Confirmed Tracks按照失联匹配的次数从少到多与Detections进行匹配,这样做是因为,失联少的Tracks为最新的Tracks与Detections匹配成功的可能性更大。
第六步:执行完成Matching Cascade输出三种状态,第一种,Detections与Tracks完成匹配得到Matched Tracks;第二种,Detections未匹配到Tracks得到Unmatched Detections;第三种,Tracks未匹配到Detections得到Unmatched Tracks。对于Unmatched Detections与Unmatched Tracks以及Unconfirmed Tracks输入IOU Match再次进行匹配,输出三种匹配结果。第一种,Matched Tracks,进入下一个循环;第二种,Unmatched Detections,重新分配New Tracks;第三种,Unmatched Tracks,对于Unconfirmed Tracks直接删除,对于Confirmed Tracks判断其失联匹配的次数max_age,如果失联匹配次数大于30次(可定义其他值),认为目标已经从视野消失,将目标轨迹进行删除;如果失联匹配次数小于等于30次(可定义其他值),对失联匹配次数+1,进入下一轮匹配。
第七步:反复进行第五步至第六步至视频结束。
什么是Matching Cascade?
所谓Matching Cascade即级联匹配。通过外观相似性度量与运动信息的马氏距离度量,评价检测目标框与轨迹框的相似性。比如跟踪的行人被障碍物长时间遮挡,当行人走出遮挡物重新出现时,所处的位置与进入遮挡物前的位置可能差异较大,即IOU很低或者为0,IOU Match是匹配不上的。但是,进入遮挡物前后的行人一般在外表特征上不会发生明显变化,即两者的外表特征相似度高,利用Matching Cascade可以对该种情况的行人进行召回。
文章出处登录后可见!