生信技能树学徒学习第二周
一、GEO数据库简介
GEO全称Gene Expression Omnibus data base,由美国国立生物技术信息中心NCBI创建并维护的基因表达数据库(通过NCBI首页,All Databases下拉框中选择GEO DataSets)。收录了世界各国研究机构提交的高通量基因表达数据。2000年开始建立的时候,主要是表达芯片数据,但是之后随着数据库的流行,逐渐扩展业务到许多其它的高通量数据,比如:甲基化(genome methylation),染色质结构(chromatinstructure),基因组-蛋白交互作用(genome-protein interaction)等。
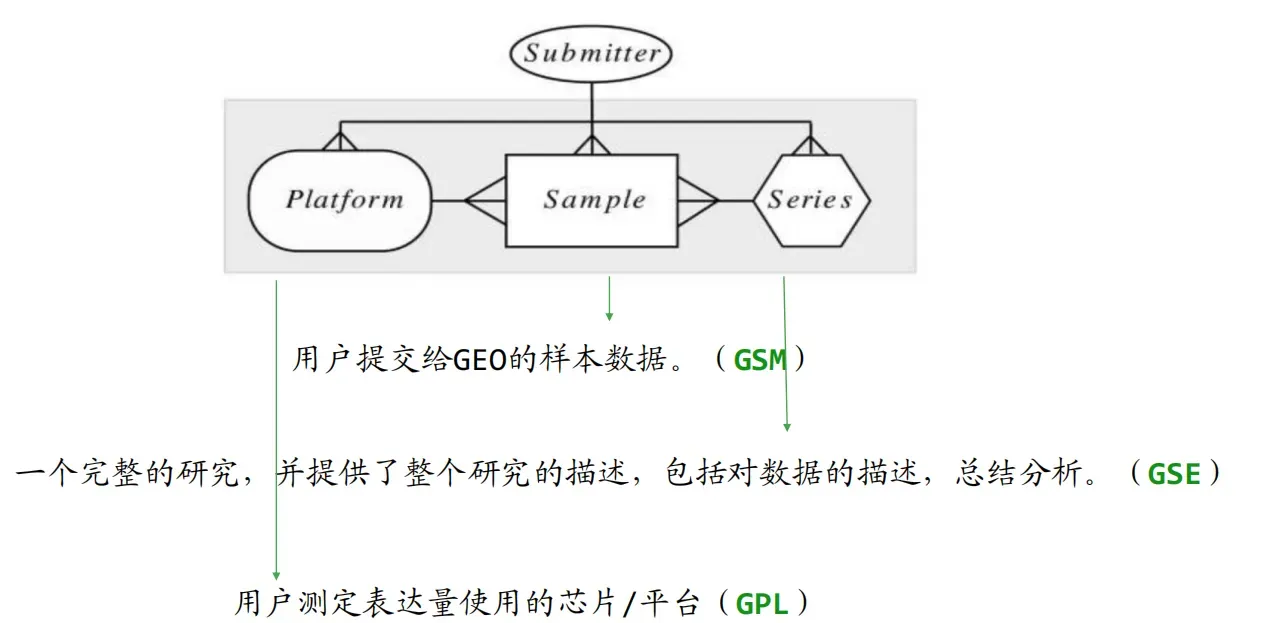
我们寻找数据集时注意以下三个信息:
GEO Series (GSE):研究项目的ID,我们可以通过搜索研究的id号来找到相关的基因数据集
GEO Sample (GSM) :样本ID号,同一个数据集中每个样品ID是不同的,在后续分析中我们也可以获取到不同样品的处理方式和基本信息
GEOPlatform (GPL) 芯片平台:不同芯片平台的基因注释是有差异的,正确的基因平台注释我有助于下游分析的成功
基因芯片是通过基因探针与序列的结合来,来确定基因的表达
二、GEO数据挖掘的分析思路
1.实验数据设计
实验目的:通过基因表达量数据的差异分析和富集分析来解释生物学的现象
通过实验组与对照组的比较→找出差异基因→找差异基因的功能/找差异基因之间的关联→解释差异
2.数据分析思路
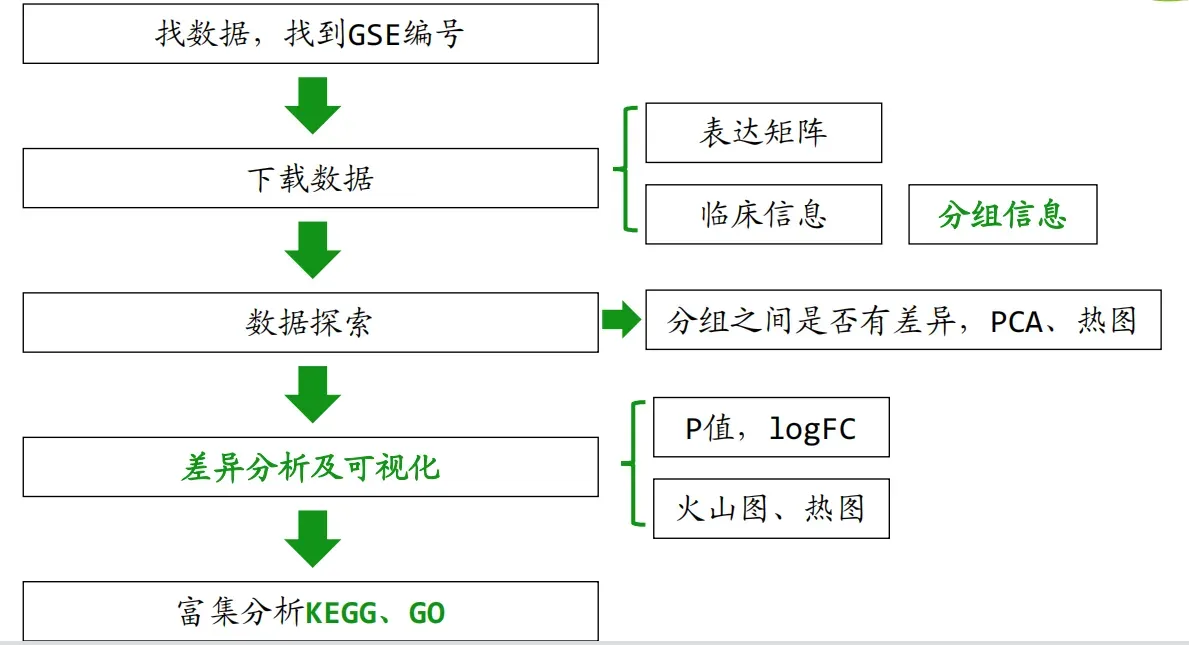
三、图表介绍
1.热图
热图通过将数据矩阵中的各个值按一定规律映射为颜色展示,利用颜色变化来可视化比较数据。当应用于数值矩阵时,热图中每个单元格的颜色展示的是行变量和列变量交叉处的数据值的大小;若行为基因,列为样品,则是对应基因在对应样品的表达值;若行和列都为样品,展示的可能是对应的两个样品之间的相关性;同样的,若行名和列名都为基因,也可以展示两个对应基因之间的相关性。当然,行列之间也不必须是这二类。
不同样品组代表性基因的表达差异、不同样品组代表性化合物的含量差异、不同样品之间的两两相似性。实际上,任何一个表格数据都可以转换为热图展示。
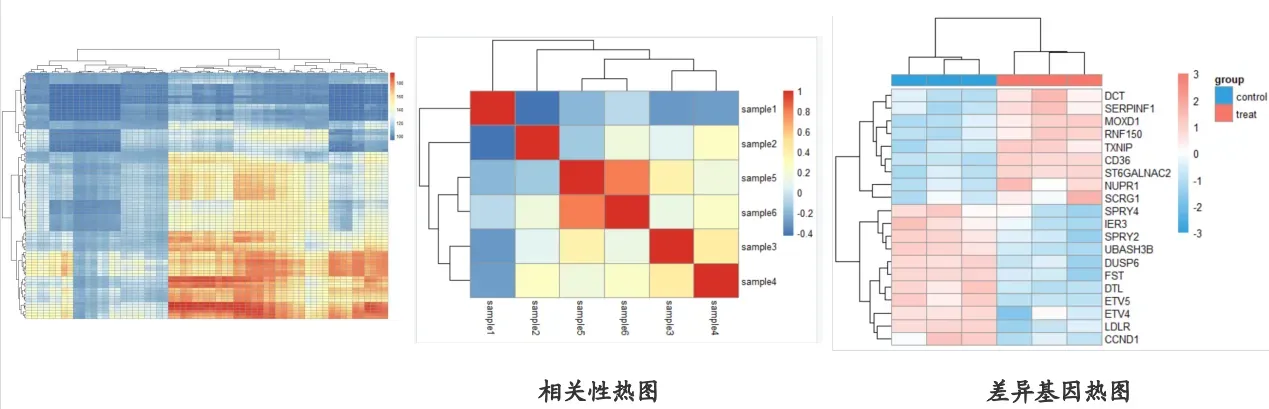
热图输入的数据,需要是数据库或者数值型矩阵
颜色变化表示数值大小
2.散点图和箱式图
箱式图是将散点图更居像的一种表现,用于表现单基因在不同样品之间的表达量差异
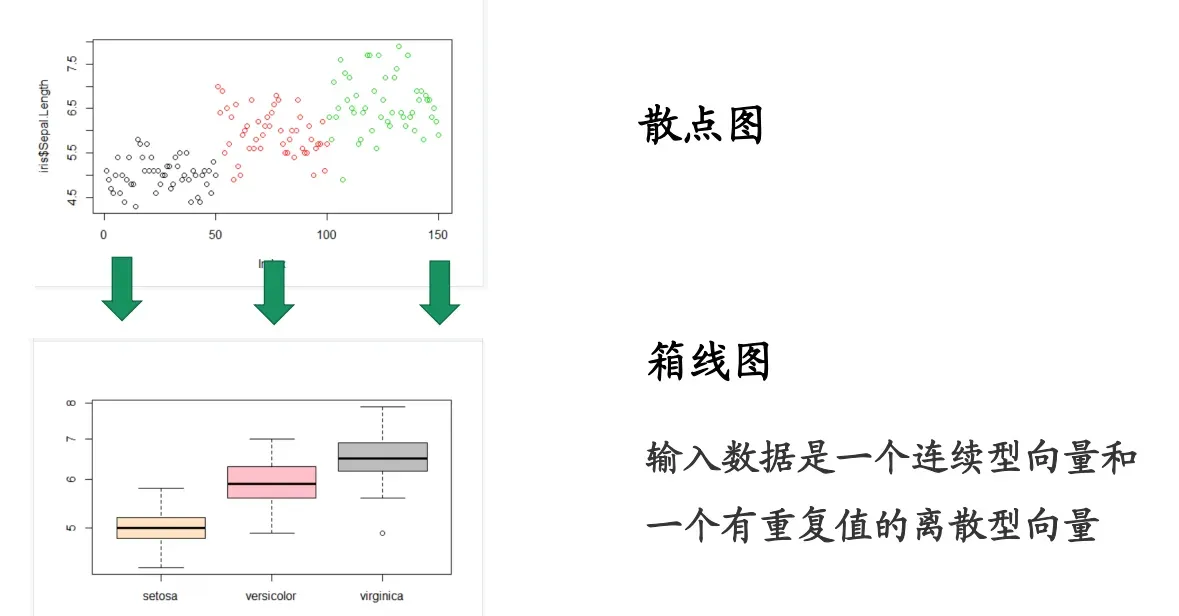
要理解箱式图的几个要素,以及离群点的出现
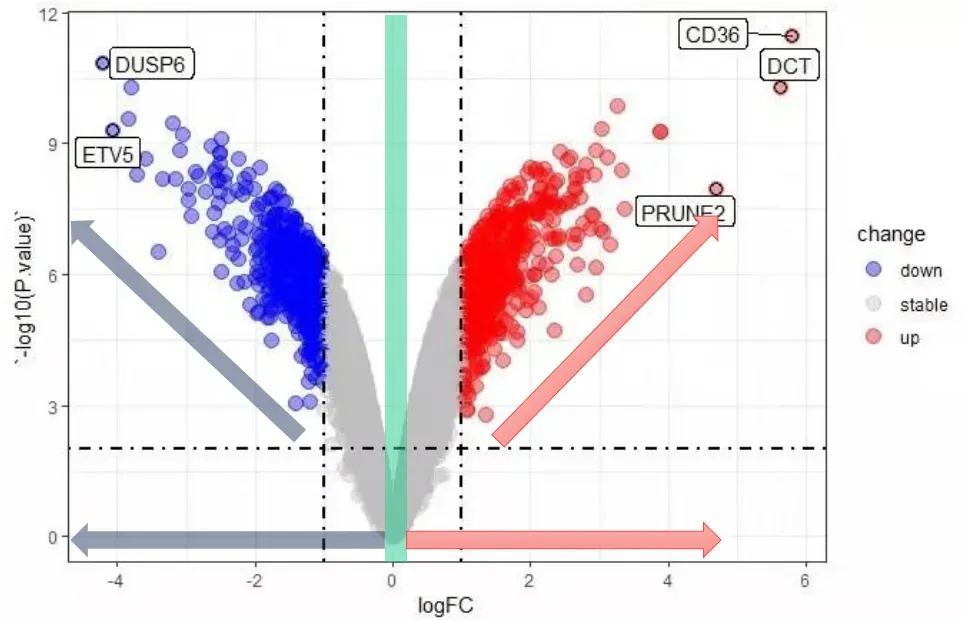
3.火山图
用于多基因表达量的组间差异分析
通过规定Foldchange值和P value值来规定火山图的阈值,来帮助我们找到差异基因
其中 Foldchange(FC):处理组平均值/对照组平均值 logFoldchange(logFC):Foldchange取log2
Foldchange>0,treat>control,差异基因表达量上调
Foldchange<0,treat<control,差异基因表达量下调
4.主成分分析
运用降维思想,将多指标转换为少数几个综合指标(即主成分)
PCA的工作就是从原始的空间中顺序地找一组相互正交的坐标轴,新的坐标轴的选择与数据本身是密切相关的。其中,第一个新坐标轴选择是原始数据中方差最大的方向,第二个新坐标轴选取是与第一个坐标轴正交的平面中使得方差最大的,第三个轴是与第1,2个轴正交的平面中方差最大的。依次类推,可以得到n个这样的坐标轴。通过这种方式获得的新的坐标轴,我们发现,大部分方差都包含在前面k个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面k个含有绝大部分方差的坐标轴。事实上,这相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,实现对数据特征的降维处理。
根据这些对主成分进行聚类,代表样本的点在坐标轴上越远,说明样本差异越大。
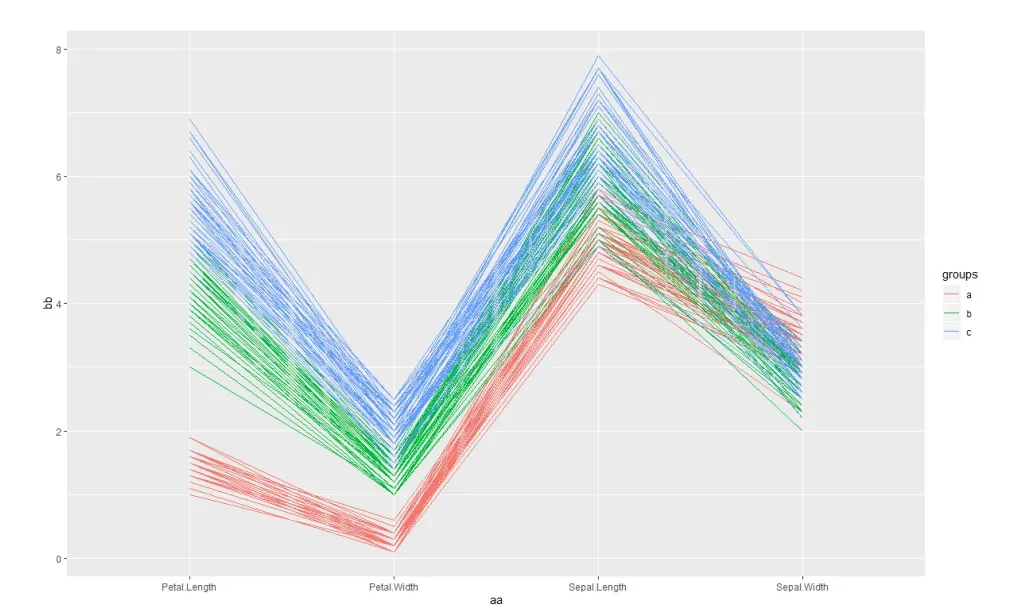
如本图,一个样本有四个特征,也就是数据往往是多维的,我们采用降维的思想,将样本最大的特征保留下来,以便观察他们的差异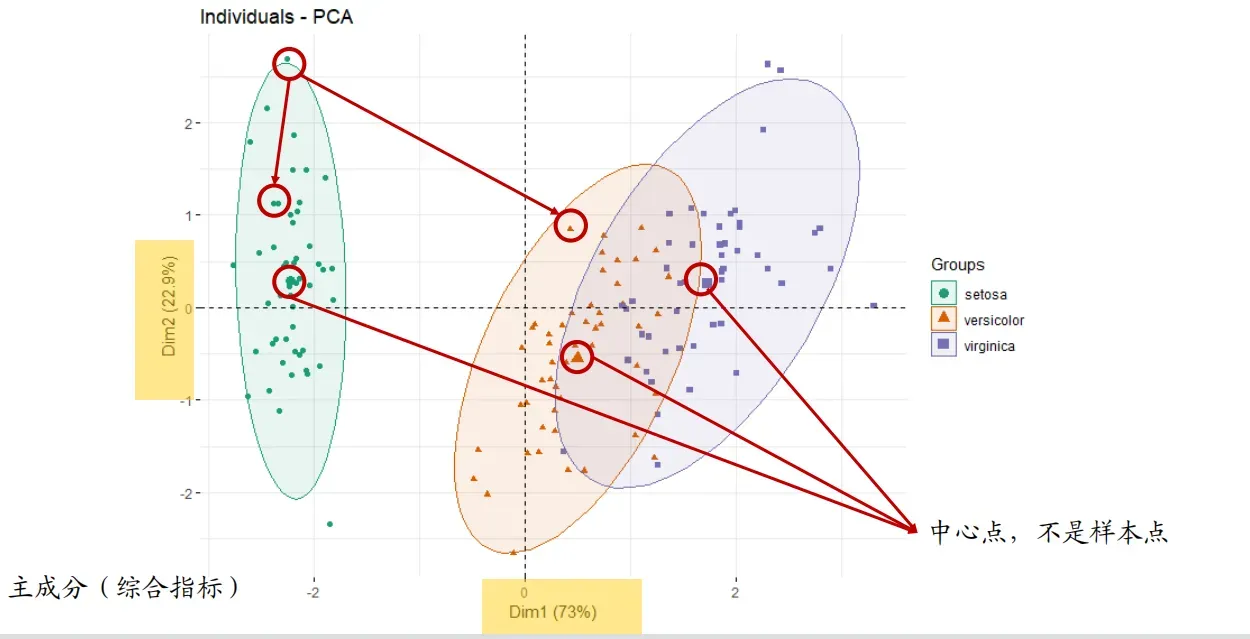 图上点代表样本,点与点之间的距离代表样本与样本之间的差异
图上点代表样本,点与点之间的距离代表样本与样本之间的差异
PCA主要用于“预实验”简单查看组间是否有差别
同一分组形成一簇(反映组内差异)
中心点之间距离(反映组间差别)
文章出处登录后可见!