深度学习简介
| 深度学习是人工智能领域中的一个分支,目标是通过模拟人脑的神经网络实现智能化。在过去的几年中,深度学习已经被广泛应用于图像识别、语音识别、自然语言处理等领域。本文将对深度学习进行简要介绍。 |
| 深度学习 | 神经网络 | 图像分类 |
文章目录
- 什么是深度学习?
- 深度学习的基本原理
- 深度学习的应用
- 深度学习经典案例——图像分类
- 图像分类的关键
- 总结
什么是深度学习?

深度学习是一种基于神经网络的机器学习技术。与传统的机器学习算法相比,深度学习的模型具有更深的结构,可以更好地处理大规模的数据,并且可以自动地学习特征。深度学习的基本思想是模仿人脑中神经元之间的连接方式,通过训练神经网络来实现从输入数据到输出结果的映射。在深度学习中,通常使用反向传播算法来训练神经网络。
深度学习的基本原理
深度学习的基本原理是神经网络。神经网络由多个神经元组成,每个神经元接收一些输入,然后根据一定的权重进行处理,并将结果传递给下一个神经元。最后,神经网络的输出结果被用来预测或分类数据。
深度学习的神经网络通常是深度的,意味着有多个隐藏层。每个隐藏层包含多个神经元,用于处理输入数据的不同特征。深度学习通过反向传播算法来训练神经网络。反向传播算法将损失函数的梯度反向传播到神经网络中,从而更新神经元之间的权重,以使得神经网络的输出结果更加接近于真实值。
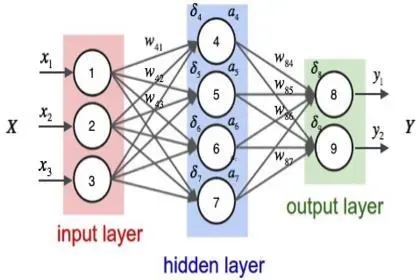
深度学习的应用
深度学习已经被广泛应用于图像识别、语音识别、自然语言处理等领域。在图像识别方面,深度学习可以通过卷积神经网络来识别图像中的物体。在语音识别方面,深度学习可以通过循环神经网络来识别说话人的语音内容。在自然语言处理方面,深度学习可以通过递归神经网络来生成自然语言描述。
深度学习经典案例——图像分类
一个经典的深度学习案例是图像分类任务,这里将展示如何使用Keras实现一个简单的卷积神经网络(Convolutional Neural Network, CNN)对CIFAR-10数据集进行图像分类。
CIFAR-10是一个经典的图像分类数据集,它包含60000张32×32的彩色图像,其中50000张用于训练,10000张用于测试,共分为10个类别。每个类别包含6000张图像。
import keras
from keras.datasets import cifar10
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from keras.optimizers import RMSprop
from keras.callbacks import ReduceLROnPlateau
# 加载CIFAR-10数据集
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
# 将图像像素值缩放到0到1之间
x_train = x_train.astype('float32') / 255
x_test = x_test.astype('float32') / 255
# 将类别标签转化为独热编码形式
y_train = keras.utils.to_categorical(y_train, 10)
y_test = keras.utils.to_categorical(y_test, 10)
# 构建卷积神经网络模型
model = Sequential()
model.add(Conv2D(32, (3, 3), padding='same', activation='relu', input_shape=(32, 32, 3)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(64, (3, 3), padding='same', activation='relu'))
model.add(Conv2D(64, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(512, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(10, activation='softmax'))
# 定义RMSprop优化器和学习率衰减方法
optimizer = RMSprop(lr=0.001, rho=0.9, epsilon=1e-08, decay=0.0)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.2, patience=5, min_lr=0.0001)
# 编译模型
model.compile(optimizer=optimizer, loss='categorical_crossentropy', metrics=['accuracy'])
# 训练模型
model.fit(x_train, y_train, batch_size=64, epochs=50, validation_data=(x_test, y_test), callbacks=[reduce_lr])
图像分类的关键
1.数据预处理:在训练之前,需要对图像数据进行预处理。常见的预处理包括对图像进行缩放、裁剪、旋转和翻转等操作,以及对图像进行标准化或归一化,以便更好地进行训练。
2.模型架构:深度学习中最常用的图像分类模型是卷积神经网络(Convolutional Neural Network,CNN)。CNN通常由卷积层、池化层、全连接层和激活函数组成。卷积层用于提取图像的特征,池化层用于减小特征图的大小,全连接层用于分类任务。
3.模型训练:深度学习模型的训练通常采用随机梯度下降(Stochastic Gradient Descent,SGD)算法,通过最小化损失函数来更新模型的权重。常见的损失函数包括交叉熵损失函数和均方误差损失函数。
4.超参数调整:模型的超参数对模型的性能有很大的影响,包括学习率、批量大小、卷积核大小等。通常采用网格搜索或随机搜索等方法来调整超参数。
5.迁移学习:迁移学习是指将一个预训练的模型在新的任务上进行微调。这种方法可以大大减少训练时间和数据需求,同时还可以提高模型的泛化能力。
6.数据增强:数据增强是一种有效的方法,可以通过旋转、翻转、缩放等方式来增加数据量,从而提高模型的泛化能力。
7.模型评估:模型的评估通常使用准确率、召回率、精确率等指标来衡量模型的性能。同时,还可以使用混淆矩阵和ROC曲线等工具来分析模型的表现。
总结
深度学习是一种人工智能领域中的机器学习技术,它的基础是人工神经网络。它利用大量的数据和计算资源来训练神经网络,从而实现各种任务,例如图像识别、自然语言处理、语音识别和推荐系统等。
深度学习的主要优势在于它可以自动学习特征和模式,而无需人为干预。这使得深度学习在许多领域中比传统方法更有效。深度学习的另一个重要优势是它的可扩展性。随着计算能力和数据量的增加,深度学习模型的性能也可以不断提高。
深度学习的应用非常广泛,包括图像识别、目标检测、图像分割、语音识别、自然语言处理、机器翻译、推荐系统、预测分析等等。除此之外,深度学习还被广泛应用于医学诊断、自动驾驶、工业生产和金融领域等。
深度学习的核心是神经网络,其中包括卷积神经网络(CNN)、循环神经网络(RNN)和变换器(Transformer)等。这些神经网络可以用于不同的任务和领域,并且可以通过微调和层叠等方法来进一步提高性能。
深度学习的实践需要大量的数据和计算资源,因此需要高性能的硬件和软件支持。例如,GPU和TPU等专用处理器可以提高深度学习模型的训练和推理速度。同时,深度学习框架如TensorFlow、PyTorch和Keras等可以帮助开发者快速构建和训练深度学习模型。
总的来说,深度学习是一种强大的机器学习技术,可以应用于各种领域和任务。虽然它需要大量的数据和计算资源,但随着硬件和软件技术的不断发展,深度学习将成为未来人工智能领域的主流技术之一。
文章出处登录后可见!