1 VITS模型介绍
VITS(Variational Inference with adversarial learning for end-to-end Text-to-Speech)是一种结合变分推理(variational inference)、标准化流(normalizing flows)和对抗训练的高表现力语音合成模型。
VITS模型是韩国科学院在2021年6月提出的,VITS通过隐变量而非频谱串联起来语音合成中的声学模型和声码器,在隐变量上进行随机建模并利用随机时长预测器,提高了合成语音的多样性,输入同样的文本,能够合成不同声调和韵律的语音。
论文地址:VITS论文
2 VITS模型结构
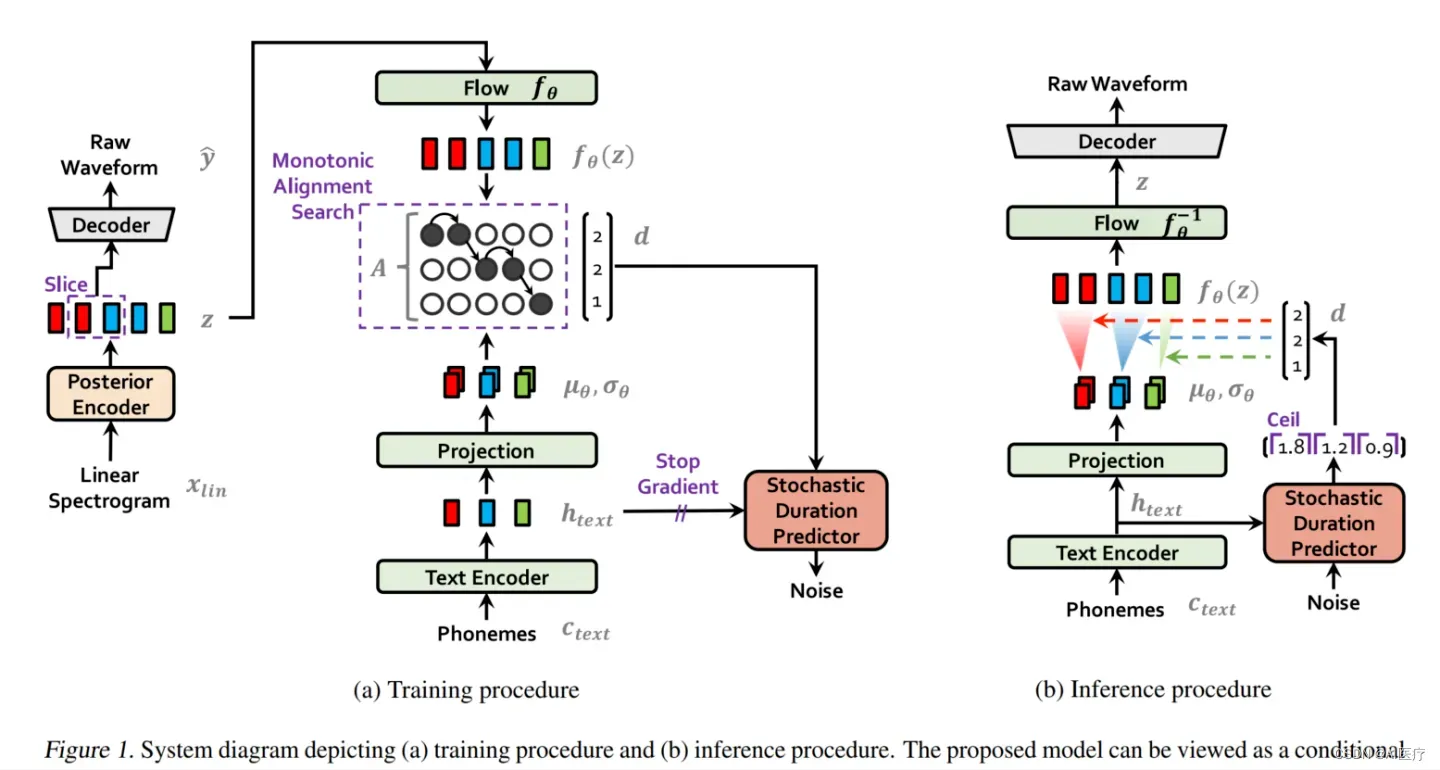
VITS主要包括3块:
- 条件变分自编码器(Variational AutoEncoder,VAE)
- 从变分推断中产生的对齐估计
- 生成对抗训练
VITS 语音合成完全端到端TTS的里程碑,主要突破点如下:
(1)首个自然度超过2-stage架构SOTA的完全E2E模型。MOS4.43, 仅低于GT录音0.03。声称目前公开系统最好效果。
(2)得益于图像领域中把Flow引入VAE提升生成效果的研究,成功把Flow-VAE应用到了完全E2E的TTS任务中。
(3)训练非常简便,完全E2E。不需要像Fastspeech系列模型需要额外提pitch, energy等特征,也不像多数2-stage架构需要根据声学模型的输出来finetune声码器以达到最佳效果。
(4)摆脱了预设的声学谱作为链接声学模型和声码器的特征,成功的应用来VAE去E2E的学习隐性表示来链接两个模块
(5)多说话人模型自然度不下降,不像其他模型趋于持平GT录音MOS分
3 使用vits模型进行中文语音合成训练
3.1 github项目下载:
git clone https://github.com/PlayVoice/vits_chinese3.2 运行环境搭建:
annoconda环境搭建详见:annoconda安装与使用
conda create -n vits pyton==3.9
conda activate vits
cd vits_chinese
pip install -r requirements.txt
cd monotonic_align
python setup.py build_ext --inplace
3.3 数据集下载:
下载标贝男声数据集,采样频率为22050,下载地址如下:
标贝男声数据集(第一个包)
标贝男声数据集(第二个包)
标贝男声数据集标注数据
下载完成后,将数据集解压缩后放到“vits_chinese/data/waves”目录下,标注数据放到
“vits_chinese/data”目录下
3.4 预训练模型下载:
韵律模型下载:韵律模型
下载完成后,移动到“vits_chinese/bert/”目录下
3.5 数据预处理:
修改配置文件:vi config/bert_vits.json
"max_wav_value": 32768.0,
"sampling_rate": 22050,
"filter_length": 1024,python vits_prepare.py -c ./configs/bert_vits.json3.6 启动训练
python train.py -c configs/bert_vits.json -m bert_vits3.7 训练后推理
python vits_infer.py --config ./configs/bert_vits.json --model logs/bert_vits/G_700000.pth
其中G_700000.pth为训练后的模型,根据训练实际情况指定训练模型进行推理
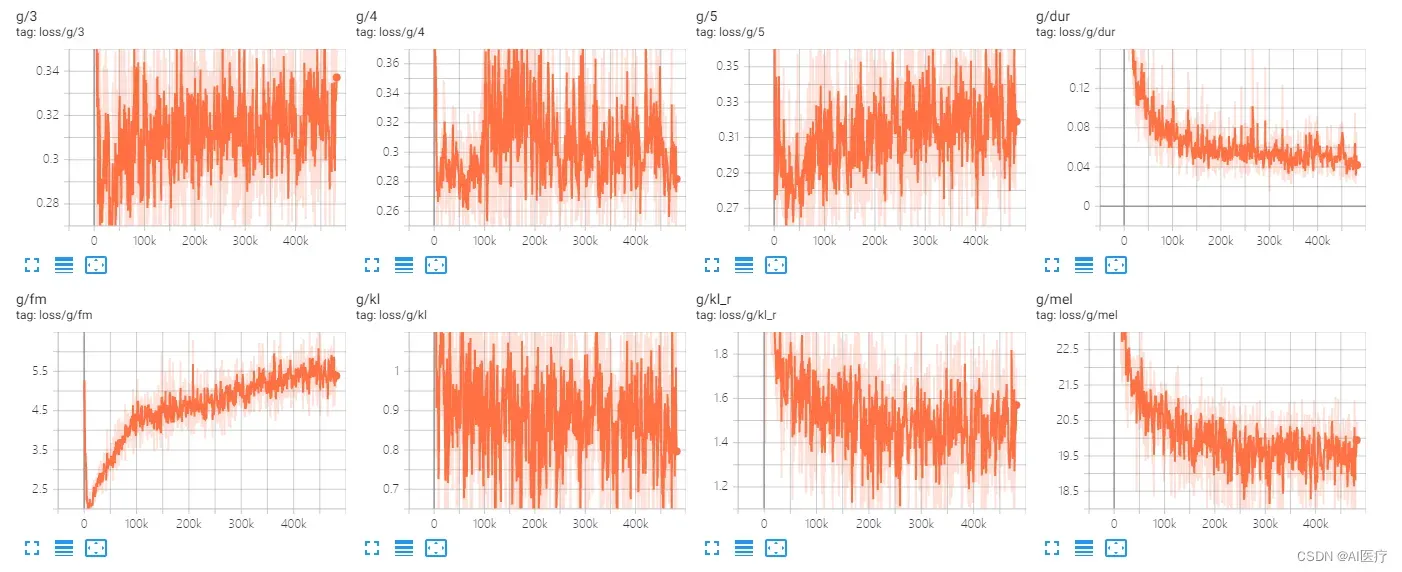
4 训练结果展示
经过1000个epoch训练后的语音生成效果如下:
https://download.csdn.net/download/lsb2002/87832170d
5 预训练模型
使用标贝男声数据,使用Tasla-v100GPU,经过70万epochs训练后模型,新speaker可以在此模型上二次训练,达到快速收敛的效果。预训练模型下载地址
下载后,将模型存储到/vits_chinese/logs/bert_vits/目录下,启动二次训练
文章出处登录后可见!