1、生成模型
首先回顾一下生成模型要解决的问题:
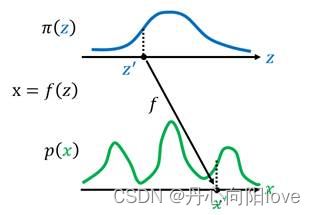
如上图所示,给定两组数据z和x,其中z服从已知的简单先验分布π(z)(通常是高斯分布),x服从复杂的分布p(x)(即训练数据代表的分布),现在我们想要找到一个变换函数f,它能建立一种z到x的映射f:z–>x,使得每对于π(z)中的一个采样点z,都能在p(x)中有一个(新)样本点x与之对应。如果这个变换函数能找到的话,那么我们就实现了一个生成模型的构造。
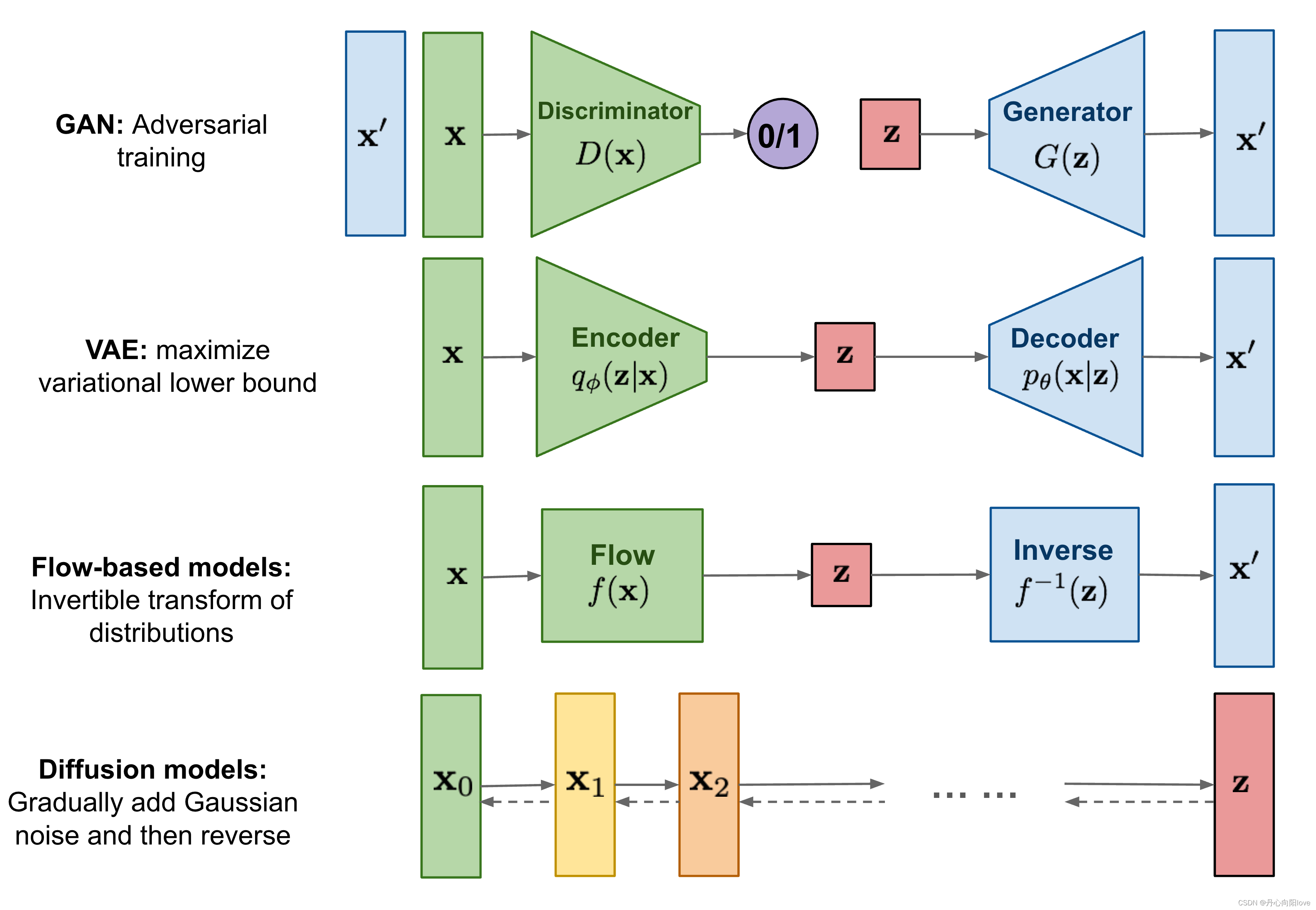
GAN、VAE和基于流的模型。他们在生成高质量样本方面取得了巨大成功,但每个都有其自身的局限性。GAN 模型因其对抗性训练性质而以潜在的不稳定训练和较少的生成多样性而闻名,GANs的良好结果可能局限于变异性相对有限的数据,因此对抗学习不容易扩展到建模复杂的多模态分布。VAE 依赖于替代损失。流模型必须使用专门的架构来构建可逆变换,基于无限微分的假设,把分布映射问题转换为将积分式Jaccobi行列式硬算出来。
2、扩散模型
扩散模型的灵感来自非平衡热力学。他们定义了扩散步骤的马尔可夫链,以缓慢地将随机噪声添加到数据中,然后学习逆向扩散过程以从噪声中构造所需的数据样本。与 VAE 或流模型不同,扩散模型是通过固定过程学习的,并且潜在变量具有高维度(与原始数据相同)
前向扩散过程
给定从真实数据分布中采样的数据点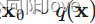
让我们定义一个前向扩散过程,在这个过程中,我们向样本中添加少量高斯噪声T步骤,产生一系列噪声样本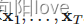 步长由方差计划控制,
步长由方差计划控制,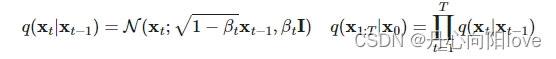
数据样本x0随着台阶逐渐失去其显着特征t变大。最终什么时候T—>∞等价于各向同性的高斯分布。
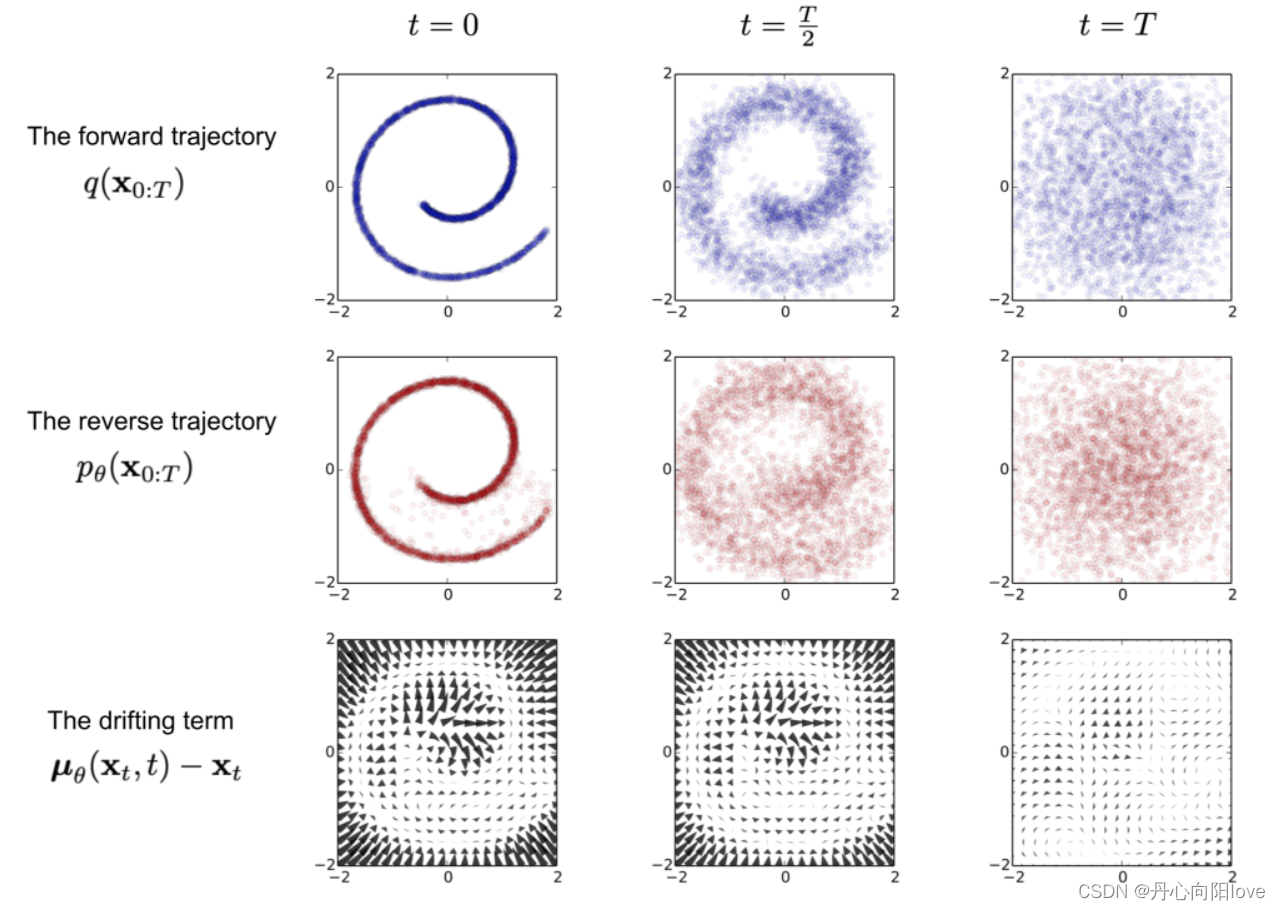
前向数学推导
上述过程的一个很好的特性是我们可以采样xt在任意时间步长使用重新参数化技巧以封闭形式。让B从0.0001取到0.02【目的是越往后添加的噪声越大】定义
和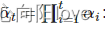

加减合并均值乘除合并方差
反向扩散过程
如果我们可以扭转上述过程并从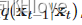
,我们将能够从高斯噪声输入中重新创建真实样本,
 请注意,如果足够小,也将是高斯的。不幸的是,我们不能轻易估计因为它需要使用整个数据集,因此我们需要学习一个模型来近似这些条件概率以运行反向扩散过程。
请注意,如果足够小,也将是高斯的。不幸的是,我们不能轻易估计因为它需要使用整个数据集,因此我们需要学习一个模型来近似这些条件概率以运行反向扩散过程。
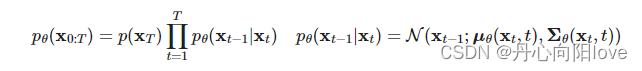
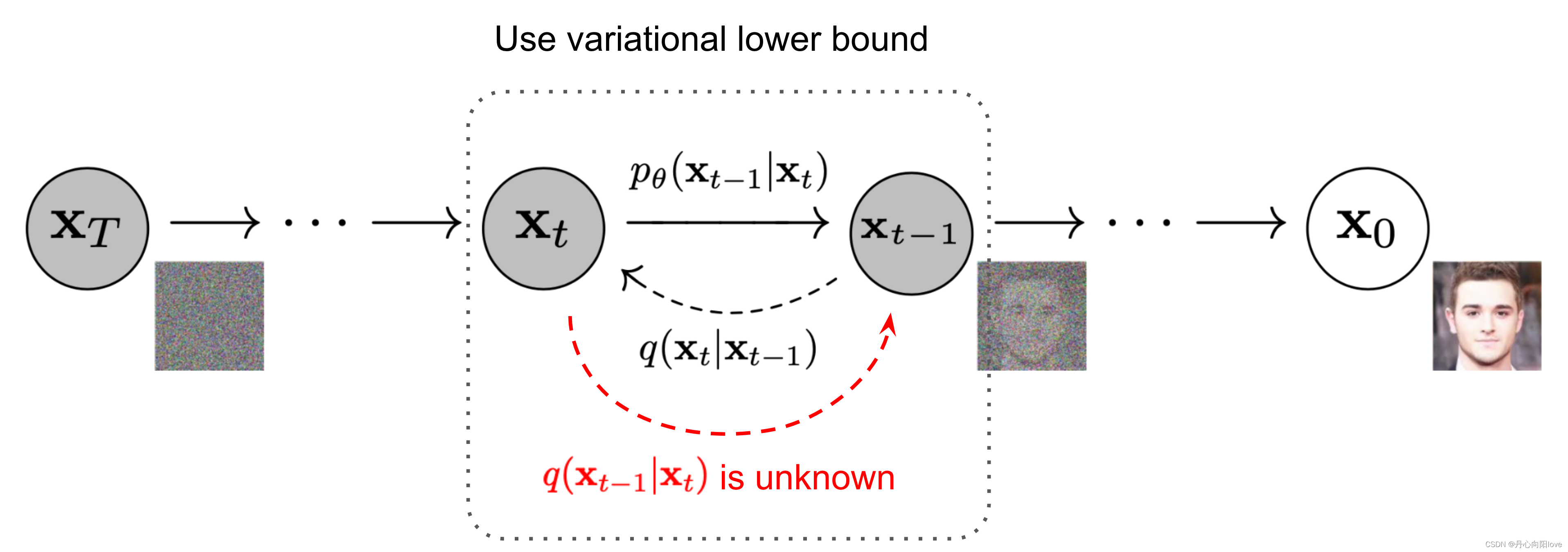

反向数学推导
原论文是基于KL散度(信息熵)进行推导的:

用贝叶斯公式推导更直观
逆条件概率在条件为x0:
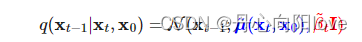
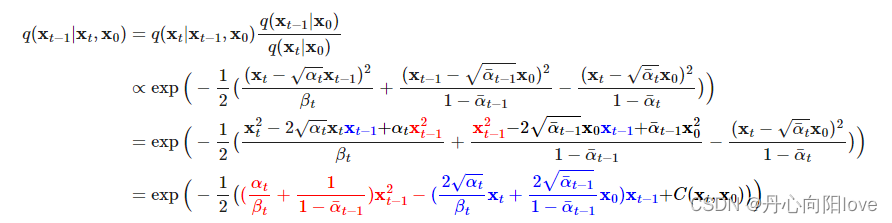
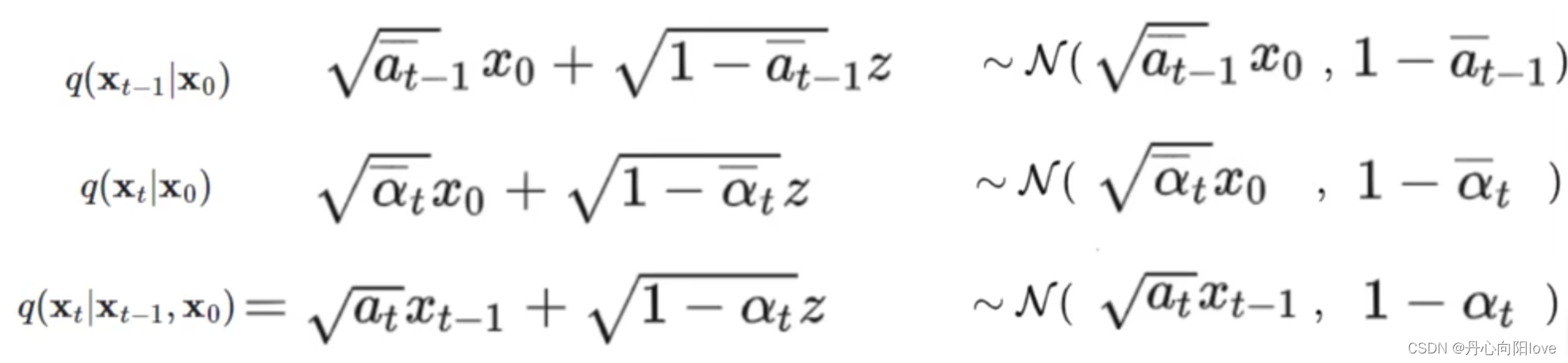
对xt-1进行配方得到:
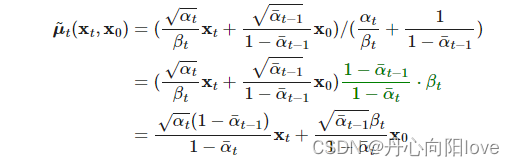

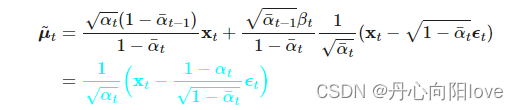
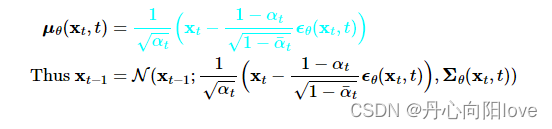
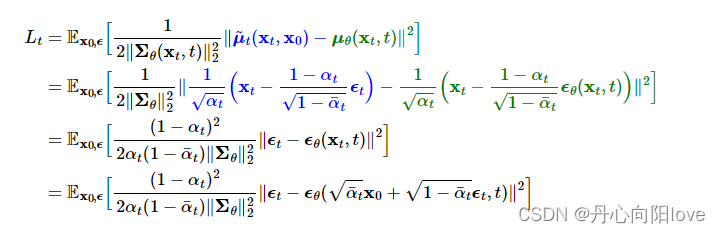

正向过程提供label z反向过程预测z

import torch
import torchvision
import matplotlib.pyplot as plt
device = "cuda" if torch.cuda.is_available() else "cpu"
def show_images(datset, num_samples=20, cols=4):
""" Plots some samples from the dataset """
plt.figure(figsize=(15,15))
for i, img in enumerate(data):
if i == num_samples:
break
plt.subplot(int(num_samples/cols + 1), cols, i + 1)
plt.imshow(img[0])
data = torchvision.datasets.StanfordCars(root=".", download=True)
show_images(data)
import torch.nn.functional as F
def linear_beta_schedule(timesteps, start=0.0001, end=0.02):
return torch.linspace(start, end, timesteps)
def get_index_from_list(vals, t, x_shape):
"""
返回所传递的值列表vals中的特定索引,同时考虑到批处理维度。
"""
batch_size = t.shape[0]
out = vals.gather(-1, t.cpu())
return out.reshape(batch_size, *((1,) * (len(x_shape) - 1))).to(t.device)
def forward_diffusion_sample(x_0, t, device=device):
"""
接收一个图像和一个时间步长作为输入,并 返回它的噪声版本
"""
noise = torch.randn_like(x_0)
sqrt_alphas_cumprod_t = get_index_from_list(sqrt_alphas_cumprod, t, x_0.shape)
sqrt_one_minus_alphas_cumprod_t = get_index_from_list(
sqrt_one_minus_alphas_cumprod, t, x_0.shape
)
#均值+方差
return sqrt_alphas_cumprod_t.to(device) * x_0.to(device) \
+ sqrt_one_minus_alphas_cumprod_t.to(device) * noise.to(device), noise.to(device)
# 界定测试时间表
T = 300
betas = linear_beta_schedule(timesteps=T)
# 预先计算闭合形式的不同项
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, axis=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value=1.0)
sqrt_recip_alphas = torch.sqrt(1.0 / alphas)
sqrt_alphas_cumprod = torch.sqrt(alphas_cumprod)
sqrt_one_minus_alphas_cumprod = torch.sqrt(1. - alphas_cumprod)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
from torchvision import transforms
from torch.utils.data import DataLoader
import numpy as np
IMG_SIZE = 64
BATCH_SIZE = 128
# 数据转换
def load_transformed_dataset():
data_transforms = [
transforms.Resize((IMG_SIZE, IMG_SIZE)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(), # Scales data into [0,1]
transforms.Lambda(lambda t: (t * 2) - 1) # Scale between [-1, 1]
]
data_transform = transforms.Compose(data_transforms)
train = torchvision.datasets.StanfordCars(root=".", download=True,
transform=data_transform)
test = torchvision.datasets.StanfordCars(root=".", download=True,
transform=data_transform, split='test')
return torch.utils.data.ConcatDataset([train, test])
#tensor转化成图像
def show_tensor_image(image):
reverse_transforms = transforms.Compose([
transforms.Lambda(lambda t: (t + 1) / 2),
transforms.Lambda(lambda t: t.permute(1, 2, 0)), # CHW to HWC
transforms.Lambda(lambda t: t * 255.),
transforms.Lambda(lambda t: t.numpy().astype(np.uint8)),
transforms.ToPILImage(),
])
# Take first image of batch
if len(image.shape) == 4:
image = image[0, :, :, :]
plt.imshow(reverse_transforms(image))
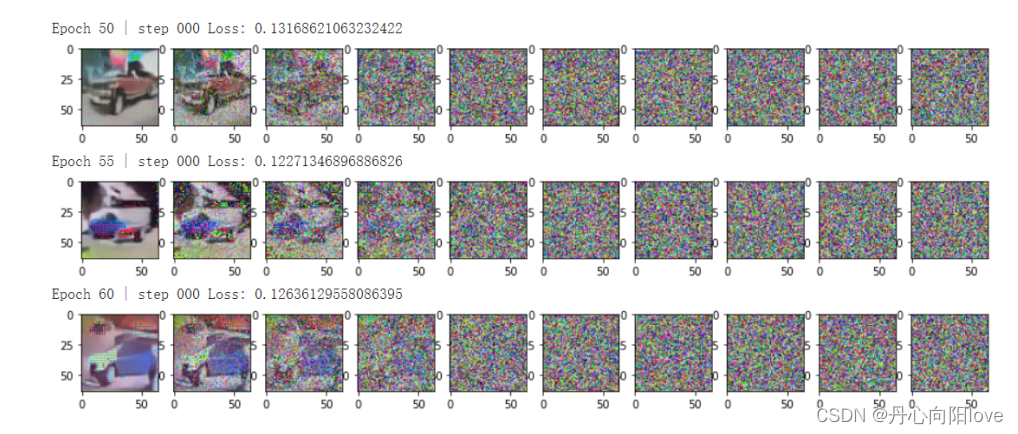
data = load_transformed_dataset()
dataloader = DataLoader(data, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
# 模拟正向扩散
image = next(iter(dataloader))[0]
plt.figure(figsize=(15,15))
plt.axis('off')
num_images = 10
stepsize = int(T/num_images)
for idx in range(0, T, stepsize):
t = torch.Tensor([idx]).type(torch.int64)
plt.subplot(1, num_images+1, int(idx/stepsize) + 1)
image, noise = forward_diffusion_sample(image, t)
show_tensor_image(image)
3、Stable Diffussion
Stable Diffussion没有单独的论文
Stable Diffusion is a latent text-to-image diffusion model. Thanks to a generous compute donation from Stability AI and support from LAION, we were able to train a Latent Diffusion Model on 512×512 images from a subset of the LAION-5B database. Similar to Google’s Imagen, this model uses a frozen CLIP ViT-L/14 text encoder to condition the model on text prompts. With its 860M UNet and 123M text encoder, the model is relatively lightweight and runs on a GPU with at least 10GB VRAM. See this section below and the model card.
High-Resolution Image Synthesis with Latent Diffusion Models+CLIP
提出问题
问题1、直接在像素空间中操作,扩散模型DM消耗数百个GPU天,且由于一步一步顺序计算,推理非常昂贵【1000 V100 days in [Prafulla Dhariwal and Alex Nichol. Diffusion models beat gans on image synthesis. CoRR, abs/2105.05233, 2021])】
问题2、图像、文本、boundboxs等条件的加入
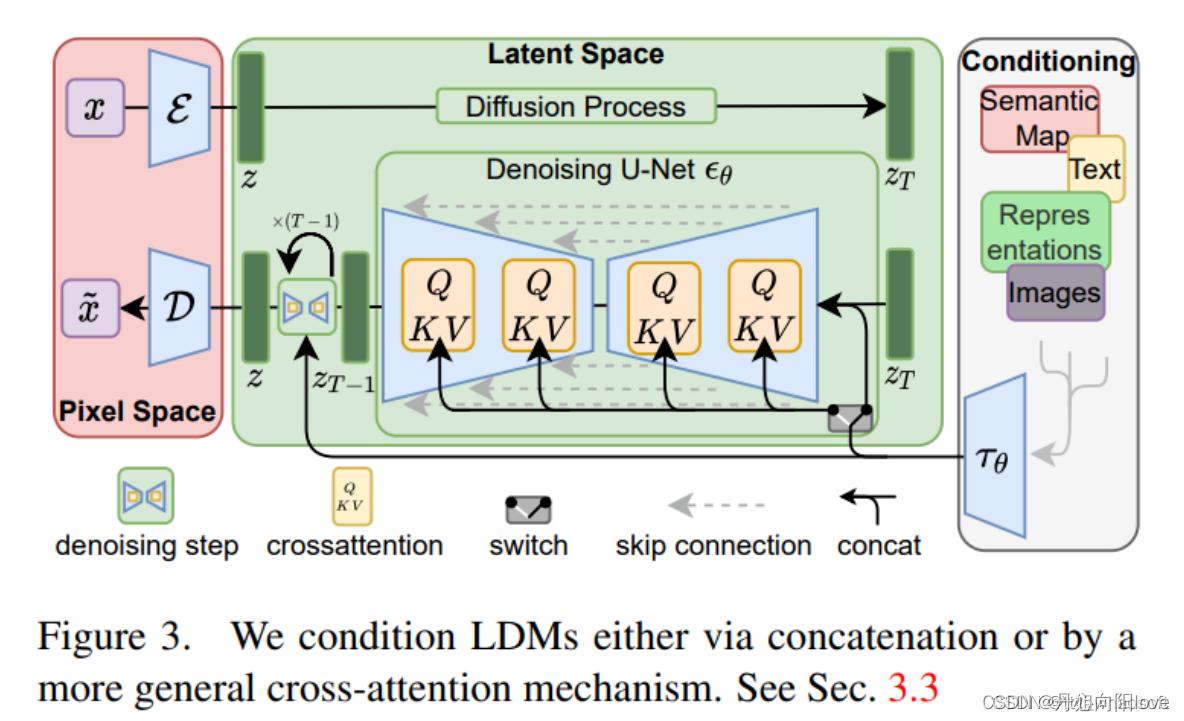
1、将训练分为两个不同的阶段:首先,训练一个自动编码器,它提供一个在感知上与数据空间等价的低维(因此是有效的)表示空间。因为在学习得到的潜在空间中训练dm。这种方法称为“潜扩散模型(Latent Diffusion Models,ldm)”。只需训练一次通用的自动编码阶段,就可以用于多次DM训练或探索可能完全不同的任务,比如各种图像到图像、文本到图像任务。
2、设计了一个将transformers连接到DM的UNet骨干的结构,并支持任意类型的基于token的条件机制。基于交叉注意力的通用条件机制,实现了多模态训练。用它来训练类条件模型、文本到图像模型和布局到图像模型
图像的感知压缩编码
本文的感知压缩编码模型基于之前的工作,由一个通过结合感知损失和基于patch GAN【马尔可夫辨别器,输出n*n的矩阵以矩阵均值作为True/False输出,每个数据代表原图中的一个感受野也就是一片patch】对抗训练的自动编码器组成。这确保了局部的真实感,并依赖像素空间损失(如L2或L1目标)所带来的模糊。给定RGB空间中的图像,编码器将x编码为潜在表示,解码器D从潜在表示中重建图像给出,其中。
编码器通过因子f=H/h=W/w对图像进行下采样,本文也研究了不同的下采样因子f的效果。
为避免过于任意自由的高方差潜空间,用两种不同的正则化进行了实验。第一个是KL-reg,对学习到潜空间的正太分布施加轻微的kl惩罚,类似于VAE;另一种VQ-reg(见VQGAN)。
因为后续DM用于处理学习到的潜在空间z = E(x)的二维结构,所以使用相对“温和”折中的压缩率并实现非常好的重构。这与之前的方法形成对比,它们依赖于学习到的空间z的任意1D顺序来对其分布进行自回归建模,而忽略了z的大部分固有结构。因此,本文压缩编码可以更好保留x的细节。
自重构损失函数 视觉感知损失函数和辨别损失函数组成
扩散模型
扩散模型的训练目标是,希望预测的噪声和真实噪声一致,正向加随机噪声,并把噪声作为label训练逆向过程,逆向过程以正向噪声为label进行降噪,具体详见扩散模型的章节。
潜在扩散模型
通过训练过的由E和D组成的感知压缩模型,现在有了一个高效的、低维的潜在空间,其中高频的、难以察觉的细节被抽象出来。与高维像素空间相比,该空间更适合likelihood-based的生成模型,因为它们现在可以(1)专注于数据的重要语义,(2)在低维、计算效率更高的空间中进行训练。
与以前的工作不同的是,在高度压缩的离散潜在空间中,它们依赖自回归的、基于注意力的transformer模型,这里利用模型提供的特定于图像的归纳偏差,UNet从二维卷积层构建和学习,进一步集中在感知上最相关的学习上:
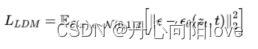

条件机制

条件式生成
通过在ldm中引入基于交叉注意力的条件机制,为ldm打开了以前在扩散模型中未探索的各种条件模式引导的生成任务。
文本到图像任务。训练一个1.45B参数kl正则化的LDM,条件输入是LAION-400M上的文本prompt。使用BERT-tokenizer并实现τθ作为transformer来推断潜码,通过(多头)交叉注意映射到UNet。学习语言表示和视觉合成的领域特定知识,这种结合产生了一个强大的模型,可以很好地推广到复杂的、用户定义的文本。
布局到图像任务。应用classifier-free diffusion guidance大大提高了样本质量。为了进一步分析基于交叉注意力的条件机制的灵活性,还训练模型在OpenImages上基于语义布局合成图像的任务,在COCO上基于finetune合成图像。
图像到图像任务。本文还用它来进行语义合成、超分辨率和修复等任务。为了进行语义合成,使用景观(landscapes)图像与配对的语义标签数据集,在256分辨率(384分辨率裁剪来)的输入尺寸上进行训练。实际上,模型可以泛化到更大的分辨率,并且当以卷积方式计算时,可以生成高达百万像素的图像。基于此,应用到超分辨率模型和图像修复模型,生成512到1024间的大分辨率图像
问题:Latent Diffusion Model 利用attention是为了找到文本与图像embeding之间的相关关系,diffusion model为什么要用attention【为了发论文?】
4、CLIP【ConnectingText and Images】
文本-图像对
常规的图像分类模型往往都基于有类别标签的图像数据集进行全监督训练,例如在Imagenet上训练的Resnet,Mobilenet,在JFT上训练的ViT等。这往往对于数据需求非常高,需要大量人工标注;同时限制了模型的适用性和泛化能力,不适于任务迁移。而在我们的互联网上,可以轻松获取大批量的文本-图像配对数据。Open AI团队通过收集4亿(400 million)个文本-图像对((image, text) pairs),以用来训练其提出的CLIP模型。文本-图像对的示例如下:

模型结构【对比学习】
CLIP的模型结构其实非常简单:包括两个部分,即文本编码器(Text Encoder)和图像编码器(Image Encoder)。Text Encoder选择的是Text Transformer模型;Image Encoder选择了两种模型,一是基于CNN的ResNet(对比了不同层数的ResNet),二是基于Transformer的ViT
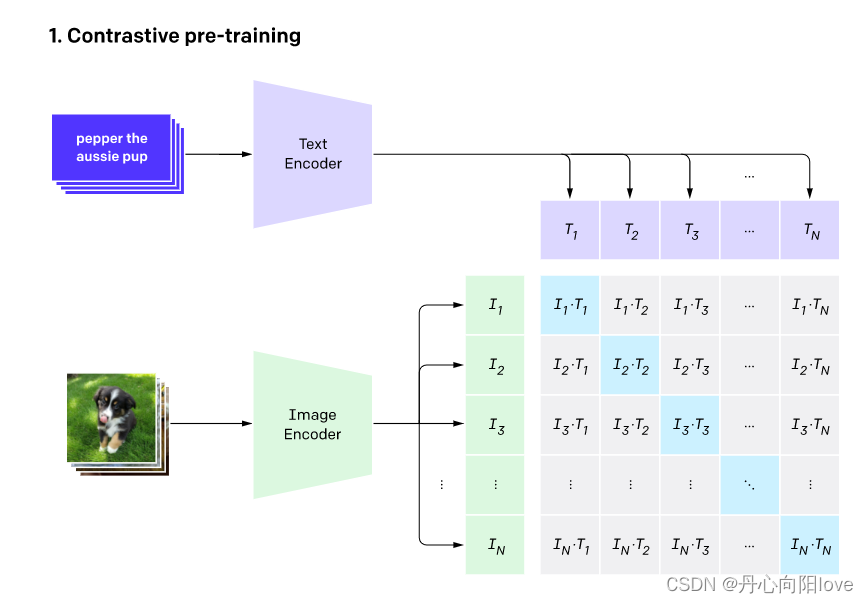
训练过程

# 分别提取图像特征和文本特征
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# 对两个特征进行线性投射,得到相同维度的特征,并进行l2归一化
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# 计算缩放的余弦相似度:[n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# 对称的对比学习损失:等价于N个类别的cross_entropy_loss
labels = np.arange(n) # 对角线元素的labels
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
训练成果
通过大批量的文本-图像预训练后, CLIP可以先通过编码,计算输入的文本和图像的余弦相似度,来判断数据对的匹配程度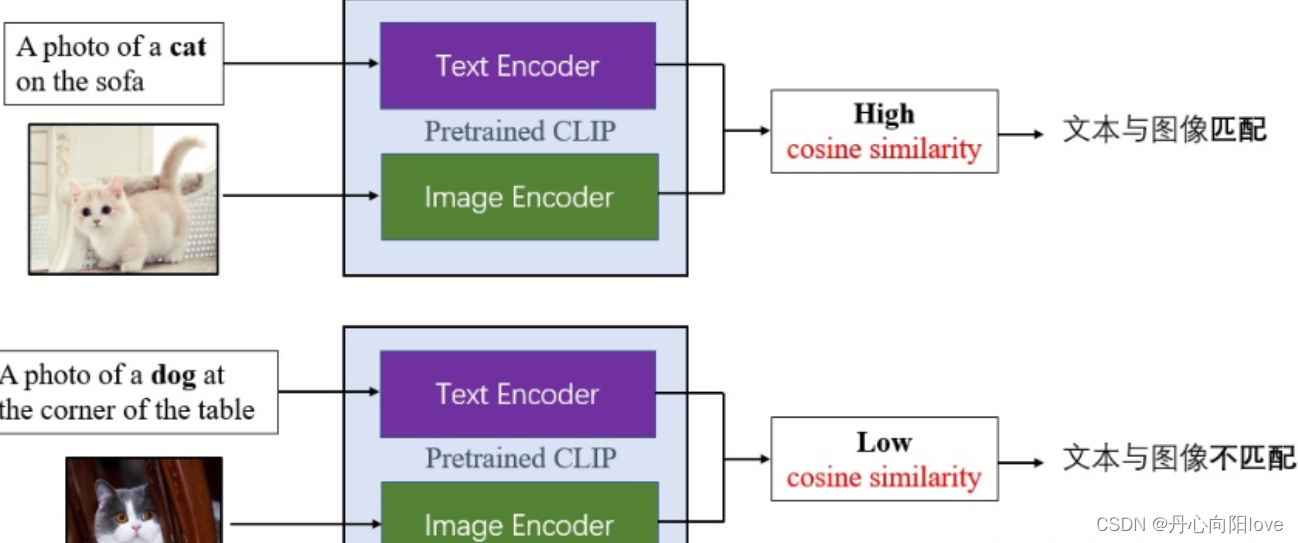
我们看到上面的示例为正样本,下面的示例为负样本。两对数据的图片其实都是猫,但负样本的文本将其描述成了狗,所以计算出的余弦相似度低,CLIP模型可以认定其文本与图像不匹配。
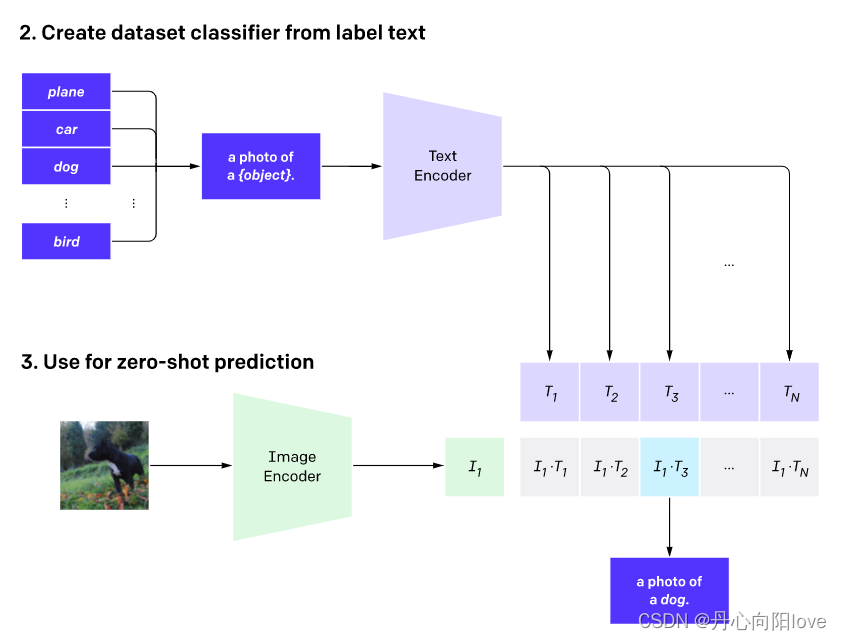
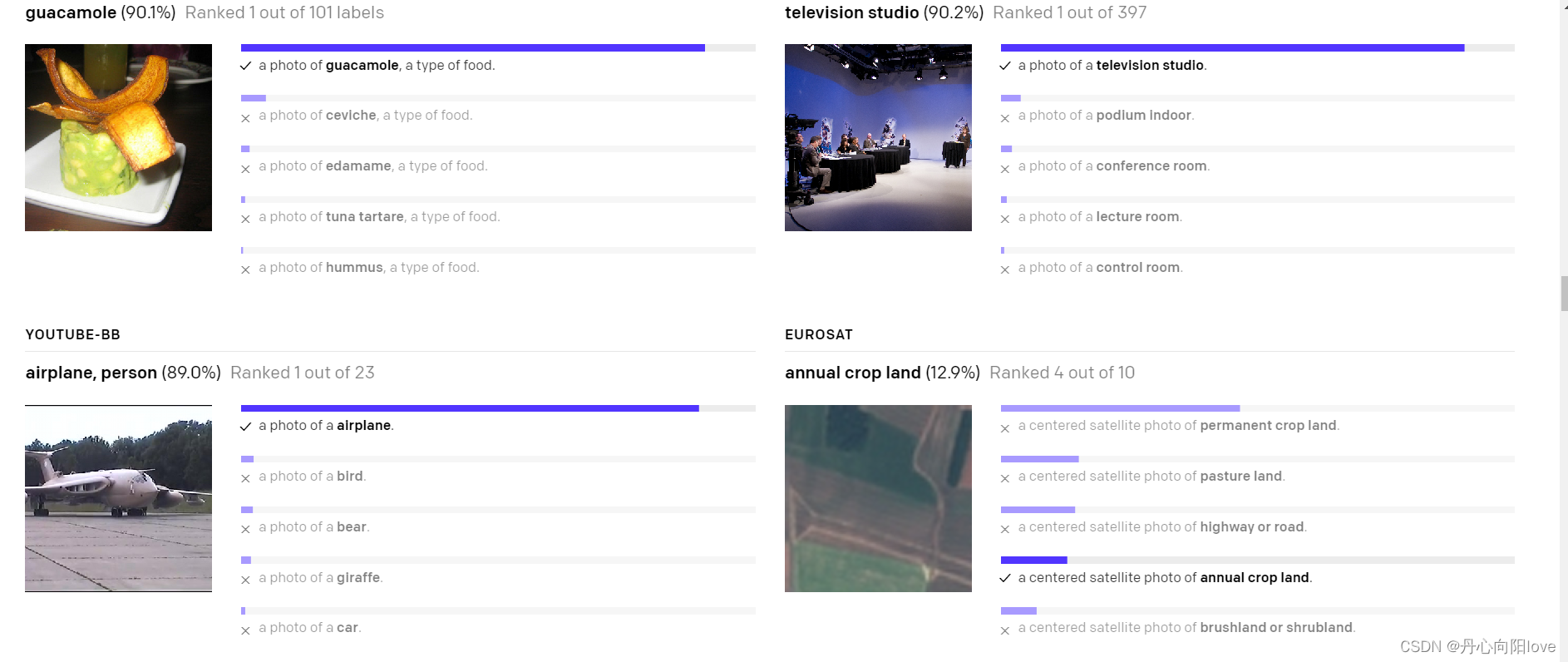
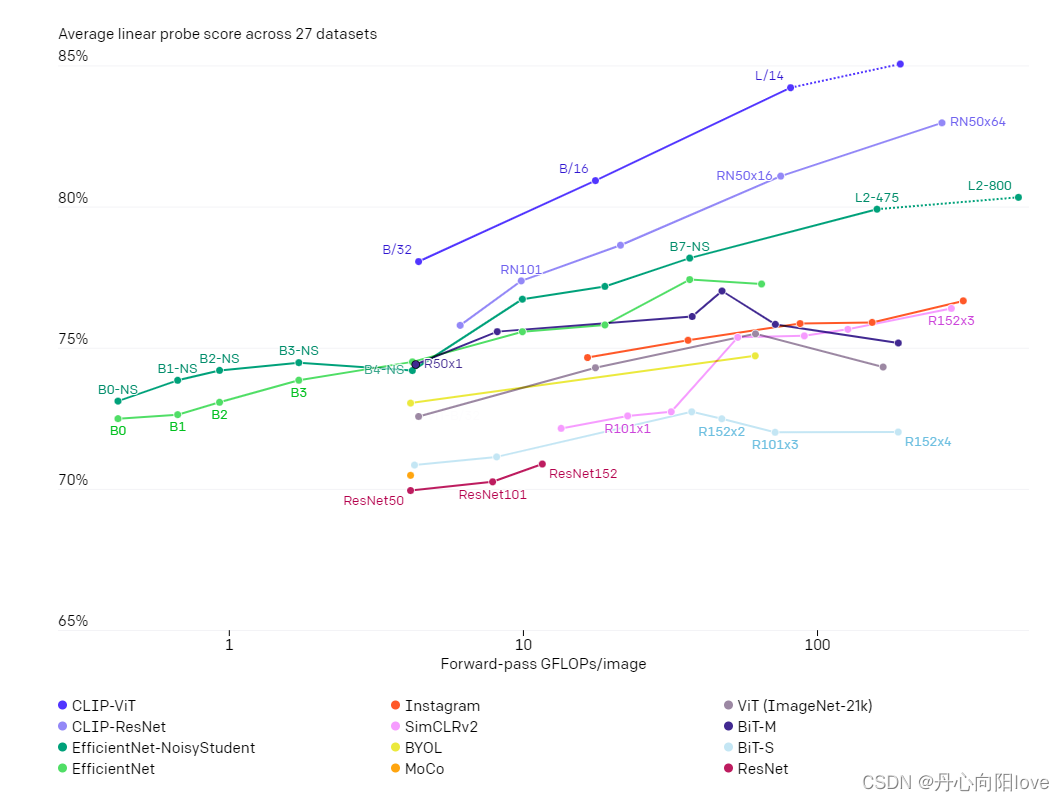
5、VQGAN
VAE
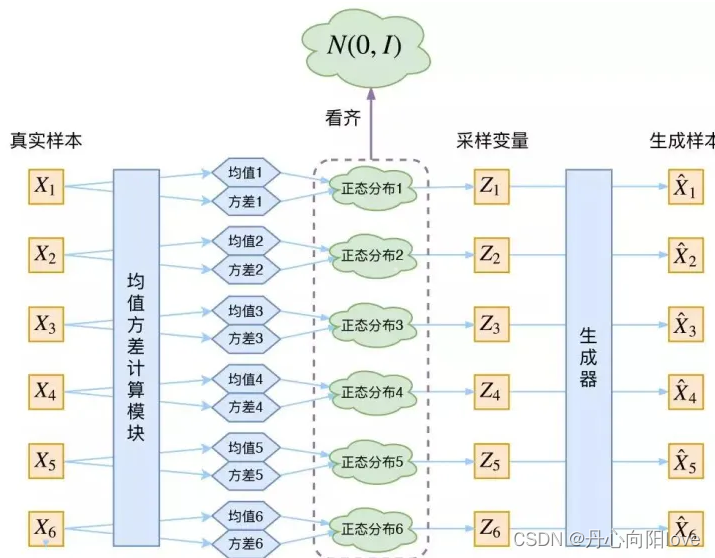
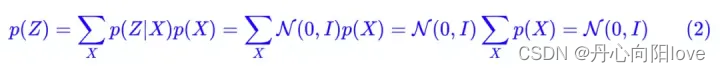
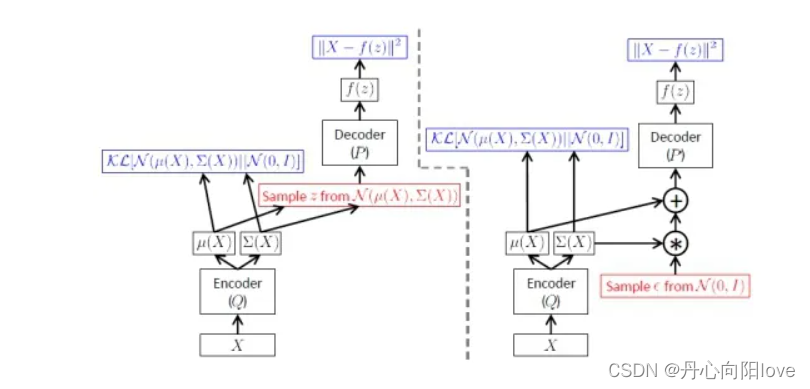
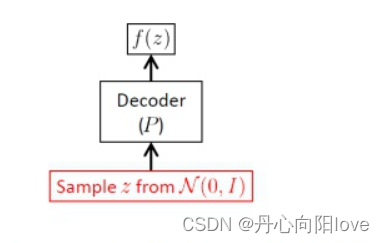
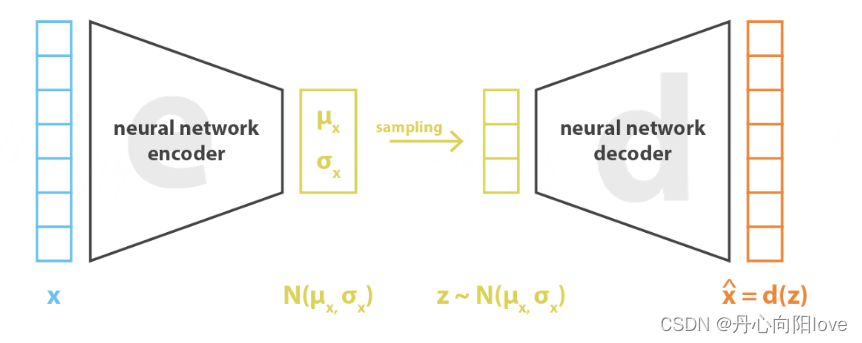
损失为重构误差+KL散度
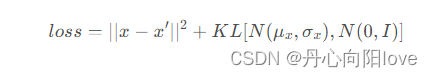
VQ-VAE
VAE 具有一个最大的问题就是使用了固定的先验(正态分布),其次是使用了连续的中间表征,这样会导致图片生成的多样性并不是很好以及可控性差。为了解决这个问题,VQ-VAE( Vector Quantized Variational Autoencoder)选择使用离散的中间表征,同时,通常会使用一个自回归模型来学习先验( PixelCNN)。在 VQ-VAE 中,其中间表征就足够稳定和多样化,从而可以很好的影响 Decoder 部分的输出 ,帮助生成丰富多样的图片。因此,后来很多的文本生成图像模型都基于 VQ-VAE 。
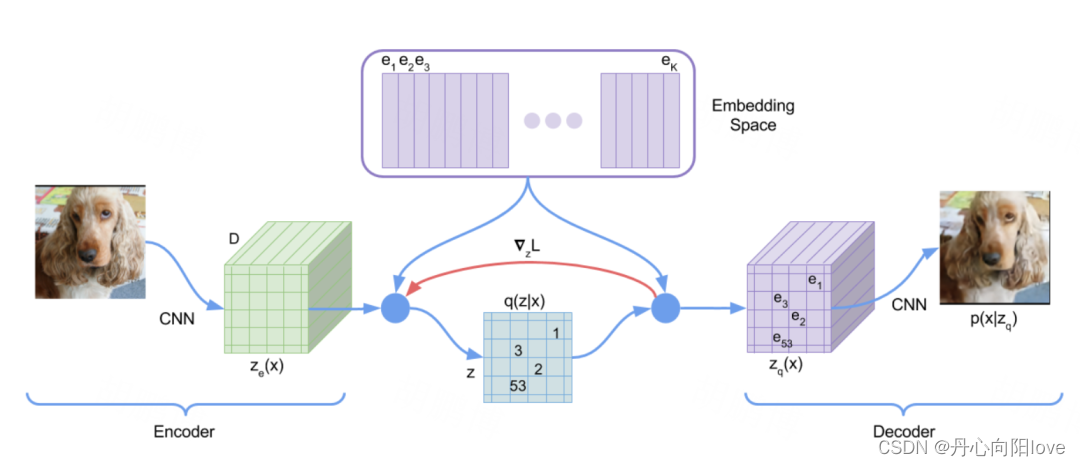
VQ-VAE 的算法流程为:
1、首先设置 K 个向量作为可查询的 Codebook。
2、输入图片通过编码器 CNN 来得到 N 个中间表征 z e ( x ) ,然后通过最邻近算法,在Codebook 中查询与这个 N 个中间表征最相似的向量。
3、将 Codebook 中查询的相似向量放到对应 z e ( x ) 的位置上,得到 z q ( x )
4、解码器通过得到的中间表征 z q ( x ) 重建图片
VQGAN
VQGAN的突出点在于其使用codebook来离散编码模型中间特征,并且使用Transformer(GPT-2模型)作为编码生成工具。
codebook的思想在VQVAE中已经提出 ,而VQGAN的整体架构大致是将VQVAE的编码生成器从pixelCNN 换成了Transformer,并且在训练过程中使用PatchGAN的判别器加入对抗损失。以下两节将更详细介绍codebook和Transformer两部分的运作机制
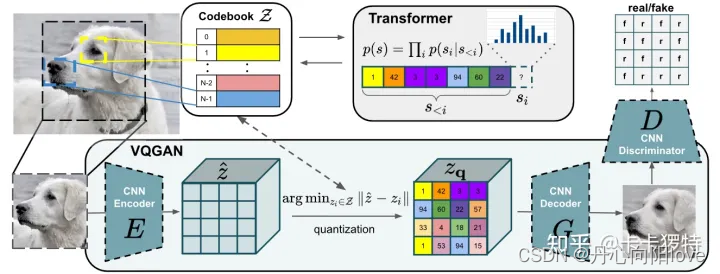
VQGAN-CLIP
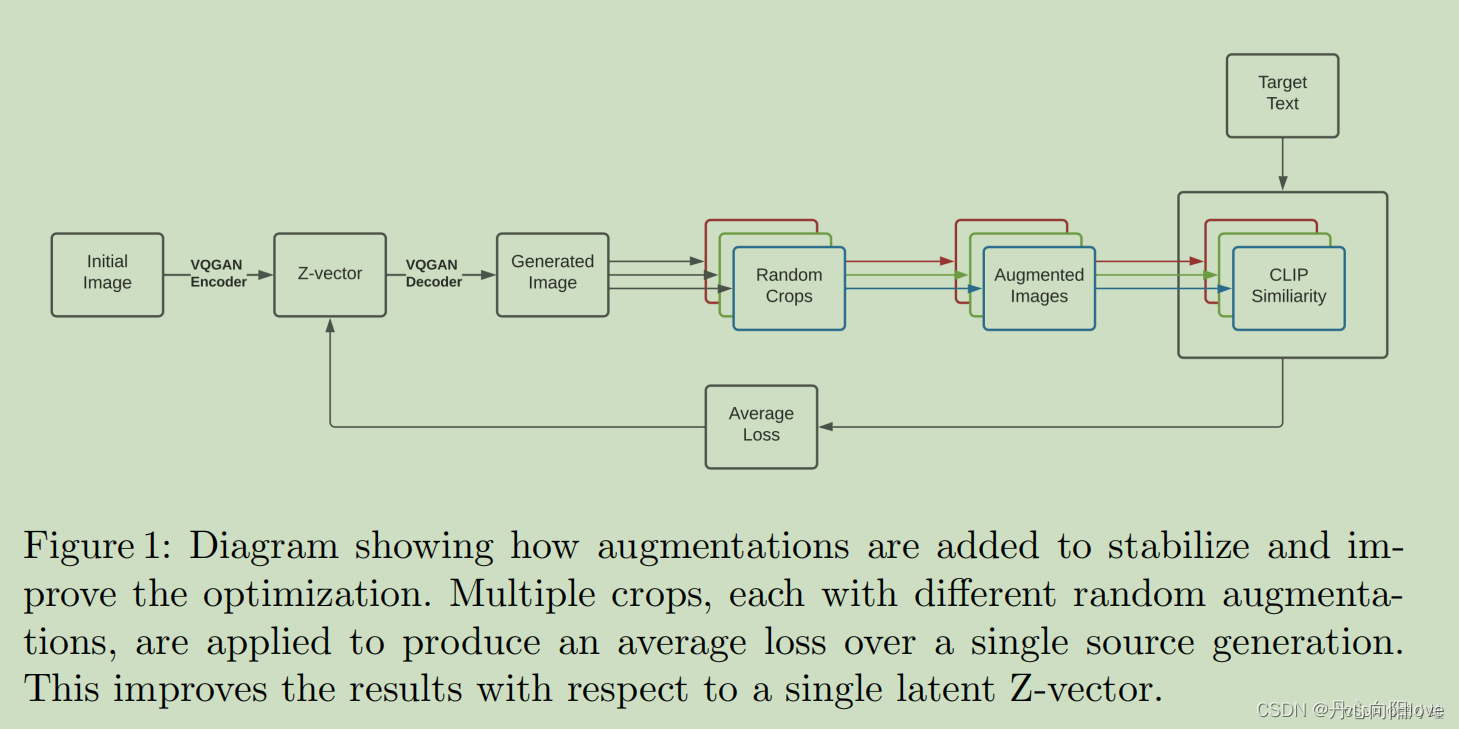
从一个文本提示符开始,并使用一个GAN迭代地生成候选图像,在每一步都使用CLIP来改进图像,图表展示了如何添加数据增强以稳定和改进优化过程。多重剪切(Multipe crops),每一种都有不同的随机增强(augmentations),以在一个单张生成图片上产生平均损失。这改进了相对于单一潜在z向量的结果。
6、DALLE-2
CLIP+GLIDE【Text Conditional Diffusion Model】
鸟瞰图
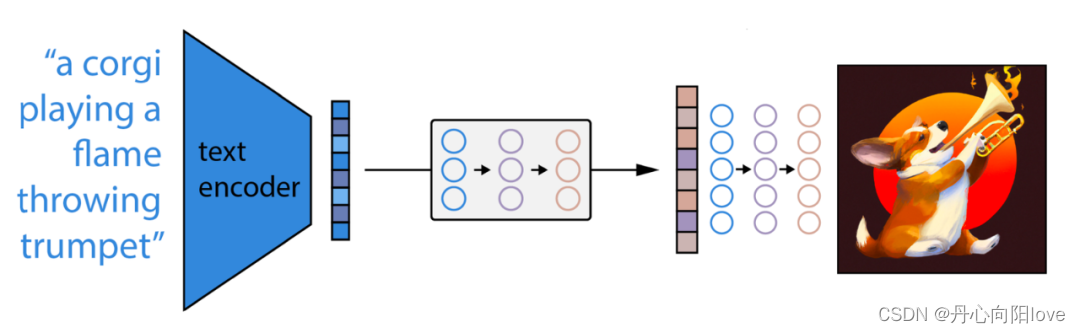
DALL-E 2 的工作非常简单:
- 首先,将文本 prompt 输入到经过训练以将 prompt 映射到表征空间的文本编码器中;
- 接下来,称为先验的模型将文本编码映射到相应的图像编码,该图像编码捕获文本编码中包含的 prompt 的语义信息;
- 最后,图像解码模型随机生成图像,该图像是该语义信息的视觉表现。
流程分解
step1:链接文本与视觉语义的关联——CLIP
训练 CLIP 的基本原则非常简单:
- 首先,所有图像及其相关标题都通过它们各自的编码器,将所有对象映射到一个 m 维空间。
- 然后,计算每个(图像,文本)对的余弦相似度。
- 训练目标是同时最大化 N 个正确编码图像 / 标题对之间的余弦相似度,并最小化 N 2 – N 个不正确编码图像 / 标题对之间的余弦相似度。
具体可以查看前面CLIP章节
step2:视觉语义生成图像
训练后,CLIP 模型被冻结,DALL-E 2 进入下一个任务——学习反转 CLIP 刚刚学习的图像编码映射。CLIP 学习了一个表征空间,在该空间中,很容易确定文本和视觉编码的相关性,但我们的兴趣在于图像生成。因此,我们必须学习如何利用表征空间来完成这项任务。OpenAI 使用其先前模型 GLIDE (https://arxiv.org/abs/2112.10741) 的修改版本来执行此图像生成。GLIDE 模型学习反转图像编码过程,以便随机解码 CLIP 图像嵌入。
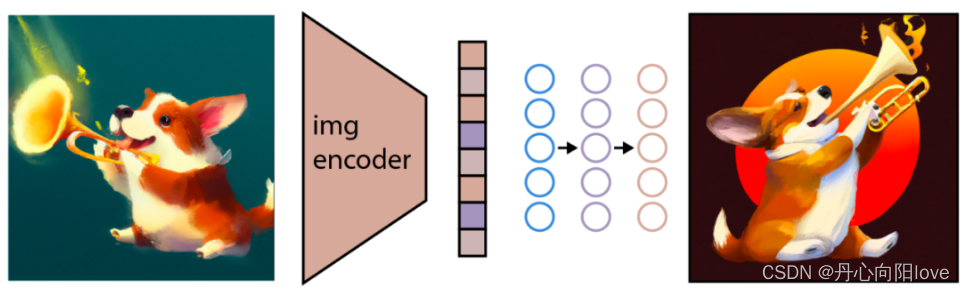
如上图所示,应该注意的是,目标不是构建一个自动编码器并在给定嵌入的情况下准确地重建图像,而是生成一个在给定嵌入的情况下保持原始图像显著特征的图像。为了执行这个图像生成,GLIDE 使用了一个扩散模型【具体扩散模型的内容可查看对应章节】
GLIDE 训练
虽然 GLIDE 不是第一个扩散模型,但它的重要贡献在于修改了它们以允许生成文本条件图像。特别是,扩散模型从随机采样的高斯噪声开始。起初,还不清楚如何调整此过程以生成特定图像。如果在人脸数据集上训练扩散模型,它将可靠地生成逼真的人脸图像;但是如果有人想要生成一张具有特定特征的脸,比如棕色的眼睛或金色的头发怎么办?GLIDE 通过使用额外的文本信息增强训练来扩展扩散模型的核心概念,最终生成 text-conditional 图像。我们来看看 GLIDE 的训练过程:
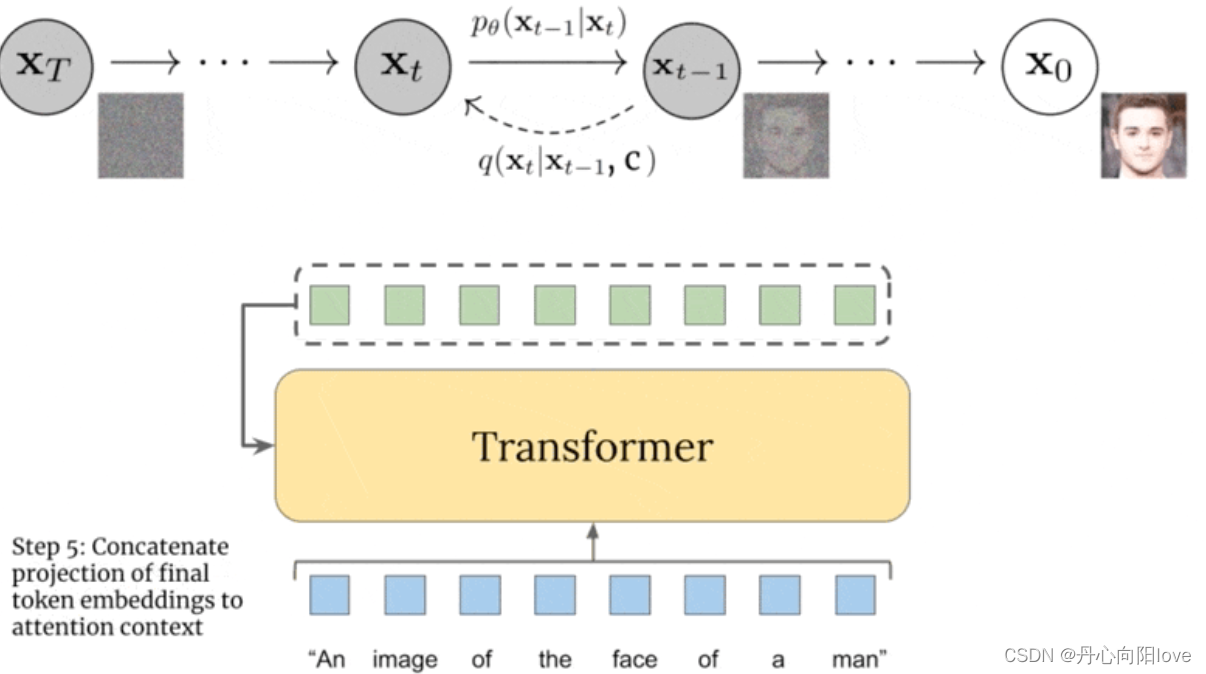
step3:从文本语义映射到相应的视觉语义
虽然修改后的 GLIDE 模型成功地生成了反映图像编码捕获的语义的图像,但我们如何实际去寻找这些编码表征?换句话说,我们如何将 prompt 中的文本条件信息注入图像生成过程?
除了我们的图像编码器,CLIP 还学习了一个文本编码器。DALL-E 2 使用另一个模型,作者称之为先验模型,以便从图像标题的文本编码映射到其相应图像的图像编码。DALL-E 2 作者对先验的自回归模型和扩散模型进行了实验,但最终发现它们产生的性能相当。鉴于扩散模型的计算效率更高,因此它被选为 DALL-E 2 的先验模型。
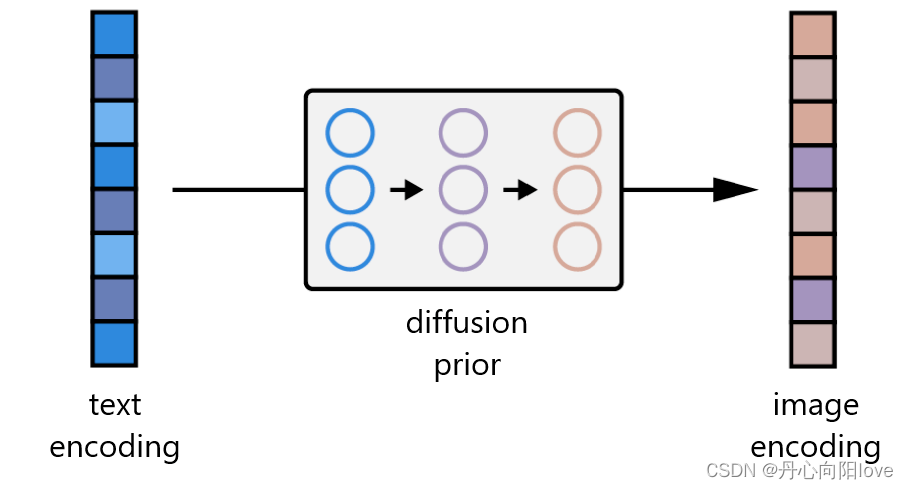
事先训练
DALL-E 2 中的扩散先验由一个仅有解码器的 Transformer 组成。它使用因果注意力mask 在有序序列上运行: - tokenized 的文本 / 标题。
- 这些 token 的 CLIP 文本编码。
- 扩散时间步长的编码。
- 噪声图像通过 CLIP 图像编码器。
- 最终编码,其来自 Transformer 的输出用于预测无噪声 CLIP 图像编码。
流程汇总
至此,我们拥有了 DALL-E 2 的所有功能组件,只需将它们链接在一起即可生成文本条件图像:
- 首先,CLIP 文本编码器将图像描述映射到表征空间。
- 然后扩散先验从 CLIP 文本编码映射到相应的 CLIP 图像编码。
- 最后,修改后的 GLIDE 生成模型通过反向扩散从表征空间映射到图像空间,生成许多可能的图像之一,这些图像在输入说明中传达语义信息。
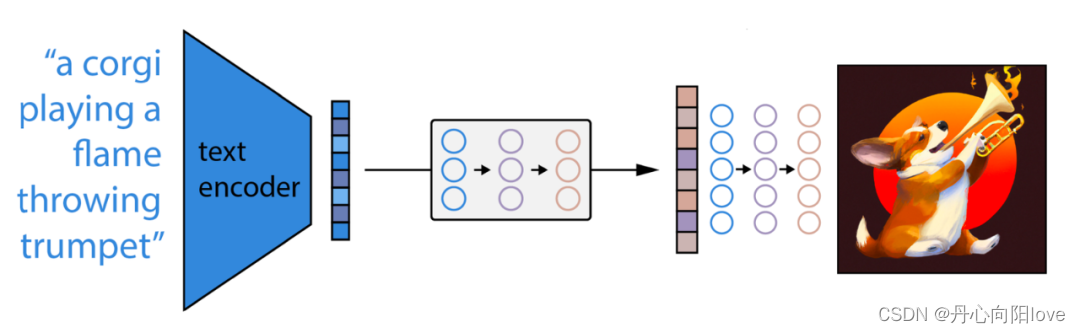
总结
Stable diffusion与Dalle2之间的区别:
Stable diffusion将图像编码为隐空间,扩散模型学习隐空间到标准正态分布的映射,文本编码作为条件控制
Dalle2,扩散模型直接学习文本空间到图像空间之间的映射关系
想要获得完整代码及资料的朋友,可关注微信公众号:丹心论数 后台私信DM获取。
文章出处登录后可见!