LSS: Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
文章目录
论文精读
本文提出一个模型,输出多视角的摄像头数据,可以直接推断出在BEV坐标系下的语义信息。
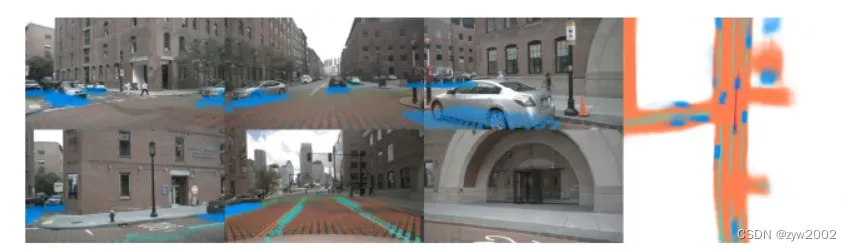
车辆(蓝色), 可以驾驶的区域(橙色),车道线(绿色)
摘要(Abstract)
自动驾驶汽车感知的目标是从多个传感器提取语义表示,并将这些表示融合到一个单一的“鸟瞰”坐标框架中,以供运动规划使用。
我们提出了一种新的端到端架构,可以直接从任意数量的摄像机中提取给定图像数据的场景鸟瞰图表示。
我们方法背后的核心思想是将每个图像单独“Lift”成一个特征截锥。对于每个相机,然后将所有的截锥“Splat”到栅格化的鸟瞰网格中。
通过在整个相机设备上进行训练,我们提供的证据表明,我们的模型不仅能够学习如何表示图像,而且能够学习如何将来自所有相机的预测融合到场景的单一内聚表示中,同时对校准误差具有鲁棒性。在标准的鸟瞰任务,如目标分割和地图分割,我们模型优于所有基线和先前的工作。
为了学习运动规划的密集表示,我们表明,通过我们的模型推断的表示,通过“Shoot”模板轨迹到我们的网络输出的鸟瞰成本图,实现了可解释的端到端运动规划。
我们对我们的方法进行基准测试, 对比使用激光雷达的深度预测模型。
1. 介绍(Introduction)
多传感器感知
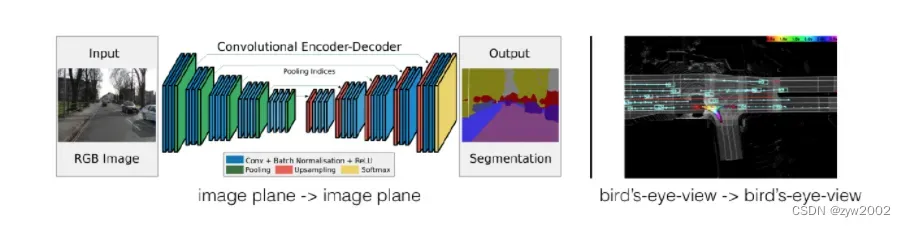
计算机视觉算法通常以一幅图像作为输入,输出一幅图像与坐标框架无关的预测,例如分类。或者在与输入图像相同的坐标系中进行预测,例如目标检测、语义分割或泛视分割。
这种范式与开箱即用自动驾驶的感知设置不匹配。在自动驾驶中,给出多个传感器作为输入,每个传感器都有不同的坐标框架,感知模型最终的任务是在自车框架中产生预测,供下游计划者消费,如图所示。
- 一个简单的方法
有许多简单、实用的策略可以将单幅图像范式扩展到多视图设置。例如,对于来自n个摄像机的3D物体检测问题,可以对所有输入的图像分别应用一个单幅图像检测器,然后根据被检测到物体的摄像机的内参和外参,转变成自车坐标系下。
这种单视图范式到多视图设置的扩展有三个有价值的对称性:
(1)平移不变性:如果图像中的像素坐标全部移位,则输出将移位相同的量。全卷积单幅图像对象检测器具有这个属性,多视图扩展从它们继承了这个属性。
(2)排列不变性:最终结果与来自n个摄像机视图的排列顺序无关。
(3)自我坐标系的平移/旋转不变性:在给定的图像中,无论捕获图像的相机相对于自我汽车位于哪里,同样的物体将被检测到。相当于说,自车坐标系旋转/平移,输出也将随之旋转/平移。
上述简单方法的缺点是,使用来自单幅图像检测器的后处理检测会阻止人们从自车框架中做出的预测中进行区分,一直到传感器输入。
因此,该模型不能以数据驱动的方式学习什么是跨相机融合信息的最佳方式。这也意味着反向传播不能用于利用来自下游计划器的反馈自动改进感知系统。
- 本文工作:提出Lift-Splat网络
本文提出Lift-Splat网络,保留了上述3个对称性的特点,且是端到端可微的方法。首先通过生成棱台形状的上下文特征点云,将图像“提升(lift)”到3D,然后将这些棱台“splat(可理解为投影)”到参考平面,以便于进行运动规划的下游任务 。此外,还提出“shoot(也可理解为投影)”提案轨迹到参考平面的方法来进行可解释的端到端运动规划。实验表明本文方法能够学习到从可能的输入分布中融合信息的有效机制。
2. 相关工作(Related Work)
我们从多个相机的图像数据中学习统一表示的方法建立在传感器融合和单目目标检测的最新工作基础上。来自Nutonomy、Lyft、Waymo和Argo的大规模多模态数据集,最近已经使完全依赖摄像头输入的自车的整个360度场景的完整表示学习成为可能。我们用Lift-Splat架构来探索这种可能性。
2.1 单目目标检测(Monocular Object Detection)
单目目标检测器是由它们如何从图像平面到给定三维参考坐标系的转换建模来定义的。一种标准的技术是在图像平面上应用成熟的2D目标检测器,然后训练第二个网络将2D检测框回归到3D检测框。
在nuScenes基准测试中,目前最先进的3D对象检测器使用了一种体系结构,该体系结构训练标准2d检测器,并通过损失来预测深度,该损失试图将错误的深度和错误的边界框造成的错误分离出来。这些方法在3D目标检测基准上取得了很好的性能,因为在图像平面上的检测排除了单目深度预测的模糊性。
一种最近取得成功的方法是分别训练一个网络进行单目深度预测,另一个网络分别进行鸟瞰图检测。这些方法被称为“伪雷达”。伪雷达经验成功的直观原因是,伪雷达能够训练一个鸟瞰网络,该网络运行在检测最终评估的坐标坐标系中,相对于图像平面,欧氏距离更有意义。
第三类单目物体探测器使用三维物体原语,根据它们在所有可用相机上的投影获取特征。Mono3D通过在地平面上生成三维建议,通过投影到可用图像上进行评分,从而在KITTI上实现了最先进的单目目标检测。正交特征变换建立在Mono3D的基础上,它将一个混合立方体的体素投影到图像上以收集特征,然后训练第二个“BEV”CNN以体素中的特征为条件在3D中进行检测。我们的模型解决了这些模型的一个潜在性能瓶颈,即像素为每个体素贡献相同的特征,而不依赖于该像素处对象的深度。
2.2 基于鸟瞰图框架的推测(Inference in the Bird’s-Eye-View Frame)
为了在鸟瞰图框架中直接执行推理,使用外在和内在的模型最近受到了广泛的关注。MonoLayout从单个图像执行鸟瞰推断,并使用一种对抗性的损失,以鼓励模型绘制看似合理的隐藏对象。在并发工作中,金字塔占用网络提出了一种转换器架构,将图像表示转换为鸟瞰表示。同时,FISHING Net并行工作提出了一种多视图体系结构,既能分割当前时间步中的对象,又能执行未来预测。我们在第5节中展示了我们的模型优于以往的经验工作。这些体系结构,以及我们的体系结构,使用的数据结构类似于来自机器学习图形社区的“多平面”图像。
3. 方法(Method)
3.1 Lift:潜在的深度分布(Lift: Latent Depth Distribution)
- Lift: 对每个图像进行单独处理,获得了每个2D像素点在3D空间中的特征
第一个阶段的任务是对来自多个摄像机的图像单独进行处理。这个阶段的操作目的是将每个图片从二维升到统一的三维坐标系下。
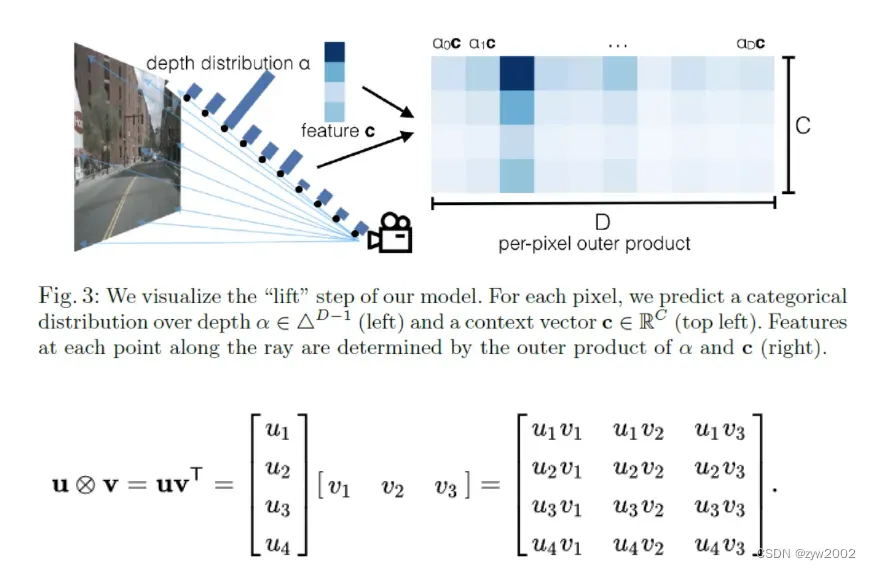
单目传感器融合的挑战在于,我们需要将深度转换为参考坐标系坐标,但与每个像素相关的“深度”本质上是模糊的。我们提出的解决方案是为每个像素生成所有可能深度的表示。
具体来说,是将深度空间离散化成D段,则可以生成 的点云,对应的是一个棱台状的空间。
对于每个像素 对应的坐标是
, 预测一个上下文向量
(即常见的卷积特征)和深度分布
则点云
处的上下文特征是
3.2 Splat:柱体池化 (Splat: Pillar Pooling)
- Splat: 通过像素的2D坐标值和深度值,以及相机的内参和外参,计算出像素在车身坐标系中的3D坐标。
借鉴了pointPillars中的做法,把Lift步骤得到的点云转换成Pillars, 其中Pillars是无限高的体素。具体做法是,把每个点分配到离他最近的Pillars中,然后执行求和池化得到一个 的张量,再对该张量进行CNN操作得到鸟瞰图的预测结果。
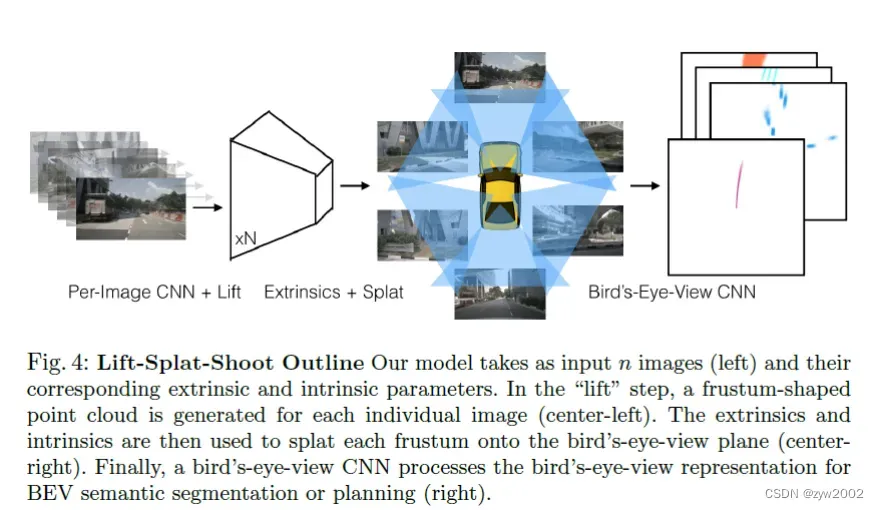
将多个相机中的像素点投影在同一张俯视图中,先过滤掉感兴趣域(以车身为中心200*200范围)外的点。然后需要注意的是,在俯视图中同一个坐标可能存在多个特征,这里有两个原因:1是单张2D图像不同的像素点可能投影在俯视图中的同一个位置,2是不同相机图像中的不同像素点投影在俯视图中的同一个位置,例如不同相机画面中的同一个目标。对于同一个位置的多个特征,作者使用了sum-pooling的方法计算新的特征,最后得到了200x200xC的feature,源码中C取64。
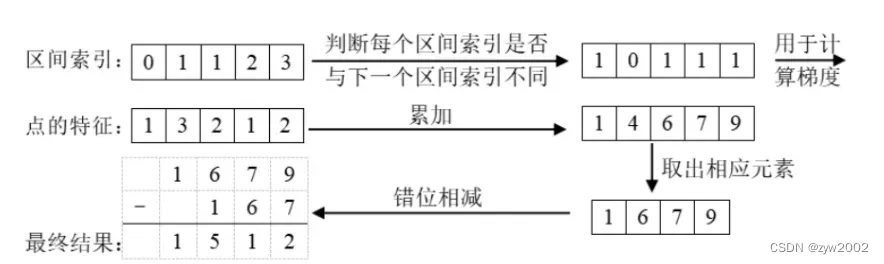
- 棱台池化累积和技巧
就像OFT使用积分图像来加快他们的池化步骤一样,我们应用类似的技术来加快总和池化。考虑到生成的点云的大小,效率对于训练我们的模型至关重要。我们不是填充每个支柱然后执行求和池化,而是通过使用打包和利用“累积技巧”来避免填充求和池化。这个操作有一个解析梯度,可以有效地计算,以加快自动梯度
该技巧是基于本文方法用图像产生的点云形状是固定的,因此每个点可以预先分配一个区间(即BEV网格)索引,用于指示其属于哪一个区间。按照索引排序后,按下列方法操作:
3.3 Shoot:运动规划 (Shoot: Motion Planning)
测试阶段若使用推断的代价图进行规划,可以通过将不同轨迹投影到BEV平面,评估代价后选择代价最小的轨迹。
本文将 “规划”视为预测给定传感器观测 下自车
个模板轨迹
的分布,即
,定义为
对于给定真实轨迹,寻找 T 中最近邻模板轨迹,然后使用交叉熵损失训练。
实际应用中,模板轨迹集 T 是通过数据集中专家轨迹的K均值聚类得到的。
参考
https://github.com/nv-tlabs/lift-splat-shoot
Lift, Splat, Shoot: Encoding Images from Arbitrary Camera Rigs by Implicitly Unprojecting to 3D
手撕BEV的开山之作:lift, splat, shoot(没完全shoot)_哔哩哔哩_bilibili
独热编码(One-Hot)最简洁理解_sereasuesue的博客-CSDN博客_one-hot
文章出处登录后可见!