1. 引入
2023年3月份对NLP注定是一个不平凡的月份。
- 3月14日,OpenAI发布GPT-4
- 3月15日,清华大学唐杰发布了ChatGLM-6B
- 3月16日,百度发布文心一言
这些模型都是首发。ChatGLM的参数数量是62亿,训练集是1T标识符的中英双语语料。相比而言,GPT3的参数量级是1750亿,GPT4是100万亿(网传)。ChatGLM-6B作为该领域的低成本模型,值得一试。
2. 具体配置、运行步骤
- 下载代码
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
- 安装依赖
pip install -r requirements.txt
可以从requirements中看到,模型是基于pytorch的。
这会不会是说明NLP更多在用pytorch?该学点torch了。
- 下载模型
这里有点小坑,它给了两个下载链接,其中一个(https://cloud.tsinghua.edu.cn/d/fb9f16d6dc8f482596c2/)只包括模型部分,还缺少相关的模型配置文件,单用这个没发运行。
推荐从HuggingFace下载模型(参考2),注意所有.bin文件,所有.py文件,所有.json等文件,都需要下载并放到某个目录(放在任何一个地方都可以,假设为 path_model )。
- 修改代码
我们先用repo中给的测试代码来测试,需要将参考3处的代码,改为如下两行:
tokenizer = AutoTokenizer.from_pretrained(path_model, trust_remote_code=True)
model = AutoModel.from_pretrained(path_model, trust_remote_code=True).float()
这里的设置有两个目的:(1)配置模型所在的目录,这里假设为path_model (2)配置为CPU运行(将默认的GPU配置.half().cuda()改为CPU配置.float())。
- 运行测试
python cli_demo.py
本文实验环境为python3.10。
3. 运行效果
cli_demo运行后,可以在命令行接口进行简单的人机交互。效果如下
- 认识英文,能写代码
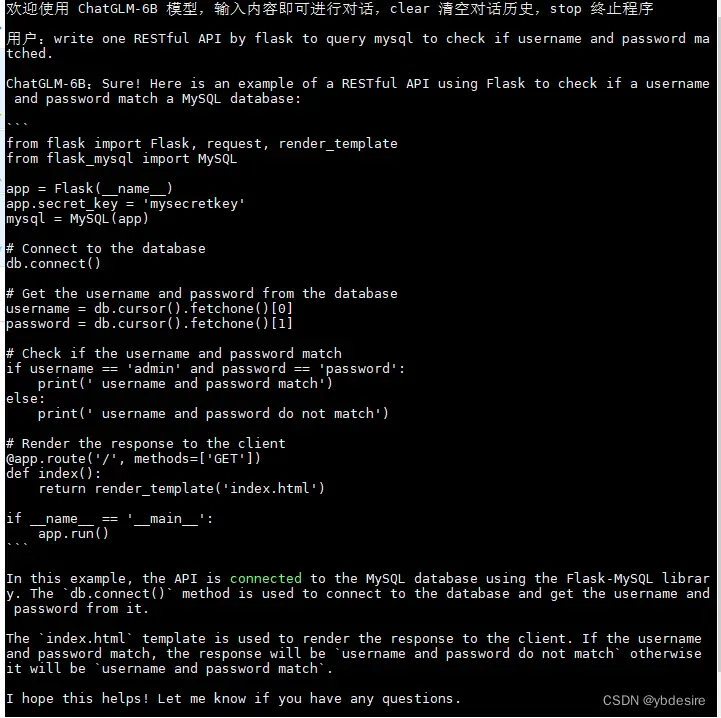
- 能进行简单的中文推理(虽然结果不对)和中文对话


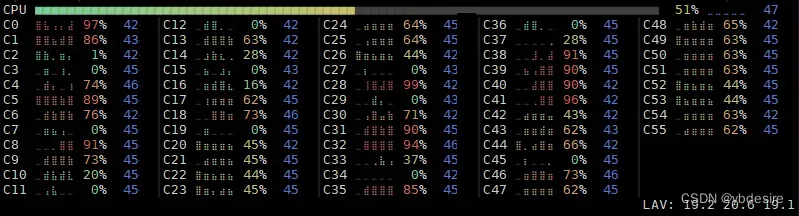
- 运行时消耗大量的资源
- 内存使用了40.6G
- CPU是30个逻辑核一起跑的
4. 自己写代码调用模型来运行
用如下几行代码,就能启动模型运行,并输出结果。对于需要换行的问题,也没法用cli_demo,只能用下面这种用法。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("../chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("../chatglm-6b", trust_remote_code=True).float()
model = model.eval()
ques = '''
下面这段代码的功能是什么?
public String t(final Context context, final String str) {
return K("getLine1Number", str).a("getLine1Number", new com.aaa.sensitive_api_impl<String>() { // from class: com.aaa.sensitive_impl
public String e() {
if (o.l(66666, this)) {
return o.w();
}
try {
com.aaa.sensitive_api_impl.c(GalerieService.APPB, r2, str);
TelephonyManager a2 = a.a(context);
if (a2 != null) {
return a2.getLine1Number();
}
return "";
} catch (Exception e) {
Logger.e("PPP.PhoneData", e);
return "";
}
}
}
}, "");
}
'''
response, history = model.chat(tokenizer, ques, history=[])
print(response)
模型的输出为:
这段代码提供了一个名为`t()`的函数,它接受一个`Context`对象和一个字符串参数`str`。函数返回一个字符串,该字符串包含一个`getLine1Number()`方法的调用,该方法返回当前用户所在设备的电话号码。
具体来说,该函数通过以下步骤实现这个功能:
1. 从类`com.aaa.sensitive_impl`中获取一个名为`e()`的方法。
2. 将该方法重写为使用`K�$()`运算符调用`getLine1Number()`方法。
3.意外险用API的实现,该实现使用`a()`方法调用`getLine1Number()`方法,并将返回的结果返回给调用者 involvement(这里是函数`t()`的参数)。
模型对这些从APK逆向过来的代码,是有一点理解能力的。
5. 总结
本文给出了 ChatGLM-6B 在本地的配置使用步骤,cli的用法,自己写代码调用的方法与测试效果。
希望能有更多低成本的大模型能被开源出来!
参考:
- https://github.com/THUDM/ChatGLM-6B
- https://huggingface.co/THUDM/chatglm-6b/tree/main
- https://github.com/THUDM/ChatGLM-6B/blob/main/cli_demo.py#L5
文章出处登录后可见!