1.准备
- coco2017数据集
- coco格式标签
- edgeai-yolov5-yolo-pose(yolov7中的pose也是从这里改过去的,有一点不同)
yolo-pose - 创建coco_kpts文件夹
#其中coco_kpts文件夹与edgeai-yolov5-yolo-pose处于同一目录下,格式如下:
edgeai-yolov5
│ README.md
│ ...
│
coco_kpts
│ images
│ └─────train2017
│ │ └───
| | '
│ └─val2017
| └───
| .
│ annotations
| labels
│ └─────train2017
│ │ └───
| | '
│ └─val2017
| └───
| .
| train2017.txt
| val2017.txt
2.环境(略,自己搭建)
权重在原文
3.测试(detect.py)
报错说什么数组大小异常多半是你忘了加–kpt-label
python test.py --data coco_kpts.yaml --img 640 --conf 0.001 --iou 0.65 --weights "XXXXX.pt" --kpt-label

4.训练(train.py)
python train.py --data coco_kpts.yaml --cfg yolov5s6_kpts.yaml --batch-size 64 --img 640 --kpt-label
建议action=‘store_true’,设置为default=‘True’
5.转onnx(export.py,坑)
export.py不在根目录,而在models路径下下面,剩下的坑,略。
6.推理(inference.py,坑)
提示,原文给的onnx文件是可以用点,主要还是5的坑,
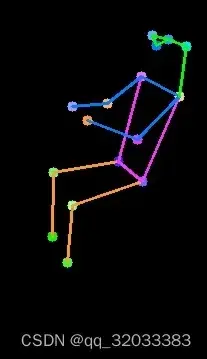
不过代码有点问题,所以需要稍微改下代码,不过难度不大,锻炼下自己。使用官方图片,成功推理后其结果如下图所示。
7.pose图生成(detect.py,略)
错误与环境问题
1.AttributeError: Cant get attribute SPPF on module models.common
解决方法:
在model/common.py文件中加上如下代码
import warnings
class SPPF(nn.Module):
#Spatial pyramid pooling layer used in YOLOv3-SPP
def __init__(self, c1, c2, k=5):
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_ * 4, c2, 1, 1)
self.m = nn.MaxPool2d(kernel_size=k,stride=1,padding=k//2)
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning
y1=self.m(x)
y2=self.m(y1)
return self.cv2(torch.cat([x,y1,y,self.m(y2)],1))
2.AttributeError: ‘Upsample’ object has no attribute ‘recompute_scale_factor’
解决方法:
找到X:\xxx\edgeai-yolov5-yolo-pose\venv\Lib\site-packages\torch\nn\modules\upsampling.py (直接点击pycharm跳转)
找到forward方法
# def forward(self, input: Tensor) -> Tensor:
# return F.interpolate(input, self.size, self.scale_factor, self.mode, #self.align_corners,
#recompute_scale_factor=self.recompute_scale_factor #原来的,删除本行内容即可
#)
def forward(self, input: Tensor) -> Tensor:
return F.interpolate(input, self.size, self.scale_factor, self.mode, self.align_corners)
3.val: WARNING: Ignoring corrupted image and/or label …\coco_kpts\images\train2017\000000581921.jpg: cannot reshape array of size 55 into shape (2)
解决方法:
A.找到X:\xxx\edgeai-yolov5-yolo-pose\utils\datasets.py
def img2label_paths(img_paths):
# Define label paths as a function of image paths
sa, sb = os.sep + 'images' + os.sep, os.sep + 'labels' + os.sep # /images/, /labels/ substrings
#return ['txt'.join(x.replace(sa, sb, 1).rsplit(x.split('.')[-1], 1)) for x in img_paths]#原来的
return [x.split('.',1)[0] + '.txt' for x in img_paths]#修改后新的
B.你忘了加–kpt-label参数,调用的代码错误,位置自己找
4.RuntimeError: result type Float can’t be cast to the desired output type long int
(上方indices.append((b, a, gj.clamp_(0, gain[3] – 1), gi.clamp_(0, gain[2] – 1))) # image, anchor, grid indices)
yolov5-master版本和yolov5-5.0/yolov5-6.1等版本下的utils\loss.py文件不一致
在loss.py中搜 for i in range(self.nl)
替换前
#anchors = self.anchors[i]
替换后
anchors, shape = self.anchors[i], p[i].shape
在loss.py搜 indices.append
替换前
#indices.append((b, a, gj.clamp_(0, gain[3] - 1), gi.clamp_(0, gain[2] - 1))) # image, anchor, grid indices
替换后
indices.append((b, a, gj.clamp_(0, shape[2] - 1), gi.clamp_(0, shape[3] - 1))) # image, anchor, grid
5.关键点异常,面部关键点不在身体(锻炼下自己的搜索能力吧)
6.转onnx文件,报错:export failure: PyTorch convert function for op ‘conv2d_clamp_prepack’ not implemented.
不知道是不是版本问题?报错PyTorch版本1.12.1,成功的版本1.8.2
(但这版本CoreML export failure,‘torch._C.Node’ object has no attribute ‘ival’)
2022/12/28补充以下更新:
6.1
CoreML export failure,‘torch._C.Node’ object has no attribute ‘ival’解决方法是在export.py中将92行注释掉
ts = optimize_for_mobile(ts)
参考链接https://github.com/ultralytics/yolov5/issues/2961
但我这样做了以后,依旧报错。忘了截图是啥问题了(可以留言告诉我,我懒得折腾版本了),总之,查询以后发现是版本问题
支持macOS 10.14的coremltools的最新版本是4.1,而现在一般是coremltools5.2,它不支持macOS 10.14
进入到对应的虚拟环境中,输入以下命令(查询版本命名:conda list coremltools)

pip uninstall coremltools
完成以后,输入安装4.1版本
pip install coremltools==4.1

改版本后如果取消92行的注释,会报错。所以依旧注释,确认在coremltools=4.1的环境中,重新导出。
好的,搞定导出。
什么,你要支持之后的版本?可能需要麻烦你自己搞定,如果愿意,可以留言帮助其他人。
7.detect.py #126行 这里有错误,1是写错了,2是没有适配关键点
if save_txt_tidl: # Write to file in tidl dump format
#for *xyxy, conf, cls in det_tidl: #写错了
for *xyxy, conf, cls in det:#作者小失误
适配代码(略)
8.xtcocotools unable to run: No module named ‘xtcocotools’
解决方法:
在虚拟环境中(建议python=3.7),3.8.特别是3.9 问题太多。大佬可以自己解决
pip install xtcocotools
9.No matching distribution found for onnxruntime==1.10.0
如需Python版本不要过高,否则之后的python版本只能安装onnxruntime>=1.12.0
在对应的虚拟环境中输入
pip install onnxruntime==1.10.0
10.更多错误,略
单分类改多分类和多关键点(略)
原作者有部分错误(我在留言中已指出,Ta也解释了原因,但我记得好像还有其他问题)。另外他是yolov7(但改代码部分不太影响,可以调通)
多分类和多关键点
COCO关键点数据
annotation{
"keypoints": [x1,y1,v1,...], #关键点坐标及标志位 v
"num_keypoints": int, #关键点数量(要求v>0)
"id": int,
"image_id": int, #图像id号,对应图像的文件名
"category_id": int, #只有人,所以为1
"segmentation": RLE or [polygon], #iscrowd 为 0 时是polygon格式,为1时是 RLE格式,代表分割图(用多边形框出人体)
"area": float, #矩形框的面积
"bbox": [x,y,width,height], #矩形框左上角坐标(x,y)和矩形框的宽高
"iscrowd": 0 or 1,
}
在key_points 关键字中 x,y表示坐标值,
v的值有三个
| V | 含义 |
|---|---|
| 0 | 没有该点 |
| 1 | 该点存在但是被遮挡了 |
| 2 | 该点存在且没有被遮挡 |
具体的标记规则建议参考coco的标记
关键点的json数据集转txt(coco keypoints键点,略)
在yolov5的yolo转txt的代码上增加读取Json中关键点信息转换就行。
坑在于,建议使用Json阅读器来弄,用nodepad++打开,数据异常(导致不知道怎么写代码,数据都不对,能写出来才怪了)
自己动动手,不难(小提示,使用format(XXX, ‘.6f’)强制实现6位小数,round函数输出可以小于6位)
如何标记coco格式的关键数据
我使用了部分网友自己写的程序,发现会有点位数据与官方数据不一致的问题。
建议直接使用官方coco-annotator调通以后进行打点,多分类也在标记时进行。
厚颜无耻的给上另外一篇我的文章链接coco-annotator安装使用
如果你搞定了标记和转txt,那么你的数据会比官方给出的数据略大是正常的。官方的数据把部分数据移除了,原因如下图嘛。


因为不能直接复制很多内容,格式方面有一些问题,很烦,懒得调整了。
文章出处登录后可见!