环境模型需要学习两个函数:状态转移函数,和奖励函数。
多个智能体整体联合学习
若采用centralized world model进行环境模型的学习,此时环境模型需要在给定联合的观测,和给定联合的动作空间下
,预测出下一时刻的联合观测
和及时奖励
。这类方法的典型代表是MAMBPO: Sample-efficient multi-robot reinforcement learning using learned world models。
此时环境模型的学习与单智能体的学习并无太大差别,无非是观测空间维度扩大,动作空间维度扩大。
此类建模方式优点:原理简单,较好实现。
此类建模方式缺点:在此类模型中也可以做多尺度,此时的多尺度是整体上的多尺度,并非具体到每个单个智能体上的多尺度。因此整体上来看,具备一定的丰富采样规划的能力,但是并没有具体到每个单个智能体,多尺度采样那么丰富。
智能体分开学习环境模型
智能体分开学习各自环境模型的问题在于整体的奖励如何给到各个智能体,奖励无法分配的话,对于各自的智能体将无法学习各自的环境模型,因为各个环境模型中需要对各自的奖励进行预测。
举例来说如下:假设有两个智能体和
, 有两个动作选项,选择来上班奖励是1,不来上班奖励是0。此时整个状态空间和奖励函数可以描述为:
- 智能体
选择不来上班,智能体
也选择不来上班,此时获得的奖励为0。
- 智能体
- 智能体
- 智能体
此时,如果仅依据观测数据,智能体和智能体
的是否选择来上班的奖励应该是多少呢?
假设智能体选择不来上班的奖励为
,智能体
选择来上班的奖励为
,智能体
选择不来上班的奖励为
,智能体
选择来上班的奖励为
。那么他们之间的关系需要满足如下方程:
变化得:
将和
代入
和
有:
因此只要满足即可满足上述关系。我们可以验证一下,假设
,那么,依据
和
有
。可以发现上述结果依旧满足约束:
而与实际真实单个智能体的真实奖励结果不一致。因此网络训练将无法收敛。
此时需要引入额外的先验知识,若奖励模型共享,对于相同状态的输入,奖励输出相同,则可以引入限制条件。则约束条件将会变为:
此方程联立将会有唯一正确解。
优点:有理论上的保障。
缺点:智能体需要为同构的。
HPP
除此之外还有一些方法来处理decentralized的多智能体问题。
中,期望学习两个导航智能体,在地图的各自两端,目标是期望其尽快相遇。
文中学习两个预测模块:self-prediction()和
other-prediction()。
self-prediction()基于自身的历史信息预测下一个状态的信息。
其中是一些位置信息,
是一些观测信息,
是在时间
到
这段时间固定的目标。而对于
other-prediction同样可以实现类似的预测。
此时,基于全局信息的预测就可以实现对全局奖励的预测。
这里只需要预测出下一个状态的位置信息即可,因为策略动作就是直接到那个位置即可。奖励也是基于位置信息预测得到的,并且奖励的计算方式人为给定,整体算法如下所示:
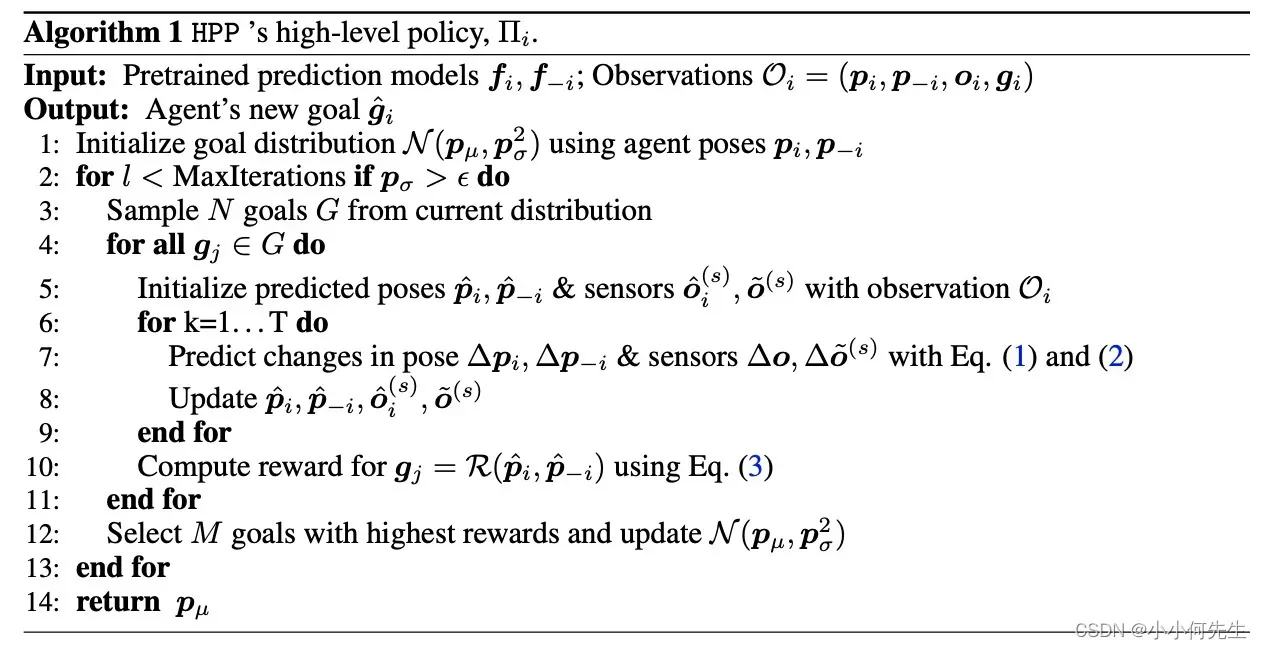
总的来看,HPP确实是可以实现各个智能体单独规划,但是联合的奖励计算是人为给定的,并且策略也不是网络计算得到的输出。并且是各个单独的智能体往前搜索步之后,再计算总的奖励,最后将搜索出来的比较好的
个结果作为需要达到的目标。
总体给我的感觉是,任务比较简单,要是再复杂一点,智能体数量多一点,这个算法可能效果并不会很好,但是每个智能体依据预测的其它智能体的位置往前搜索之后再计算总的奖励的思路还是不错,因为预测了其它智能体的信息,也就是有全局观测,也能够巧妙避开了奖励分配的问题,而是采用全局奖励的预测。
AORPO
Model-based Multi-agent Policy Optimization with Adaptive Opponent-wise Rollouts
AORPO这篇文章同样也是实现对对手模型的预测,然后基于预测的对手模型再做状态转移。预测对手模型可以表示为,基于预测的结果再做状态转移即可得到
,从而实现了对于环境模型的学习。但是奖励部分并未进行学习,只是基于状态转移学习得到的数据来优化了一下策略,是典型大dyna-style的基于模型的强化学习方法,整体算法如下:

异构多智能体环境学习
基于上述两篇预测对手行为的文章来看,此时回到最开始的问题约束上:
智能体选择不来上班的奖励为
,智能体
选择来上班的奖励为
,智能体
选择不来上班的奖励为
,智能体
选择来上班的奖励为
。那么他们之间的关系需要满足如下方程:
若此时智能体能够预测出
的行为,同样能够对上述约束添加额外条件。比如,假设预测出
的行为为来上班
,那智能体
如果来上班得到的奖励会是
,智能体
选择不来上班得到的奖励将会是
。此时智能体
依旧会选择来上班这个行为来获取更高的联合奖励,从而实现最终的规划策略一致。
若采用decentralized world model进行环境模型的学习,想要每个智能体都具备单独的,不同尺度的规划能力,可以采用增加一个其它智能体的行为预测模块,将其它智能体的行为预测出来。此时对联合动作空间下的奖励建模可以表示为
, 当给定状态
的情况下,
也将预测出来,相对来说也是给定,此时智能体
采取不同的动作
就能获得不同的全局奖励
,就能够进行学习到环境模型
和
的情况下进行策略规划。从而在不进行奖励分解的情况下,实现单个智能体单独具备策略规划的能力。
优点:支持异构。
缺点:要学的东西相对会多一点。训练难度加大。
文章出处登录后可见!