零基础手把手训练实践:图像分类模型
-基于达摩院modelscope
导读:图像分类模型是最简单的,也是最基础的计算机视觉任务,应用非常广泛。本文将手把手介绍零基础训练图像分类模型的实践过程。文章主要介绍如何在标注好的数据集基础上,进行微调,使模型能够在新的数据上重新适配一个新的分类任务。
阅读完本文,你将了解如何使用ViT模型在14种花卉数据集上进行分类的微调训练,进而了解大部分分类任务的微调过程。
首先,打开ModelScope的官网(https://www.modelscope.cn/home),进入模型库。
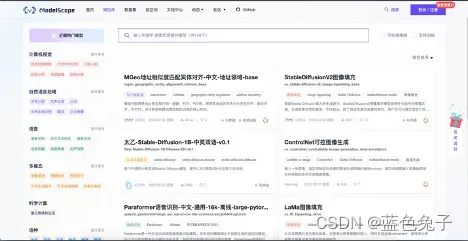
模型库页面可以看到有很多不同的模型,我们选择:计算机视觉 – 视觉分类 – 通用分类。模型库中有很多通用模型,这些模型都比较经典,有些是目前比较火的一些开源模型,大家都可以在上面进行尝试。本文主要以ViT图像分类-中文-日常物品这个模型为实例,演示如何进行分类任务的微调。
首先打开这个任务。因为之后要用notebook进行训练,所以需要登录一下。新用户注册会送100个小时的GPU算力。
任务中首先介绍了整个模型的基本情况:有关于日常物体分类模型的概要介绍,模型的简单描述,以及推理的示例代码。
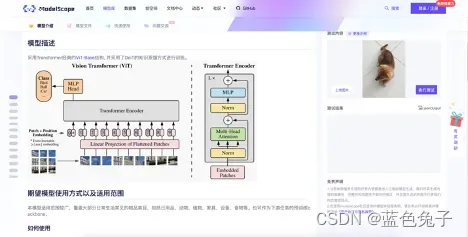
示例代码的使用十分简单,除了引用依赖包之外,只需两行代码就可以调用模型进行分类任务的测试。页面右上方也有在线模型的体验,可视化了推理的过程。可以选择自己上传图片或者用示例图片进行测试,点击执行测试就可以看到结果。刚开始执行的时候会稍微有些慢,因为要下载模型,之后就会快一些。
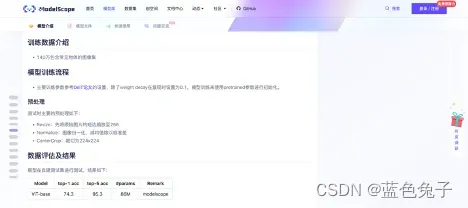
其次还有一些模型数据的简介、模型训练流程、数据评估及结果。
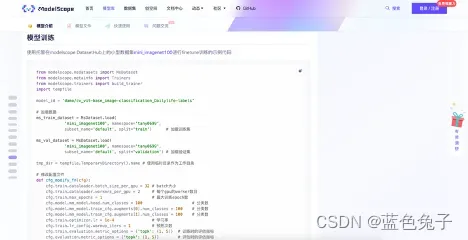
接下来是模型训练的示例代码,也是本文的重点。示例代码中用的是一个稍小的数据集mini_imagenet100,100个分类进行fine-tune训练的示例,对演示来说还是比较大的。所以我们会在这个代码的基础上进行修改,来适配更小的数据集,稍后会对模型中的参数进行更为详细的讲解。
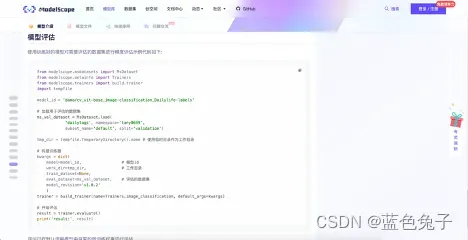
这里是模型评估的示例代码,展示模型如何对数据集中的校验集进行评估,稍后也会进行详细的讲解。这就是整个任务页面的大致内容。
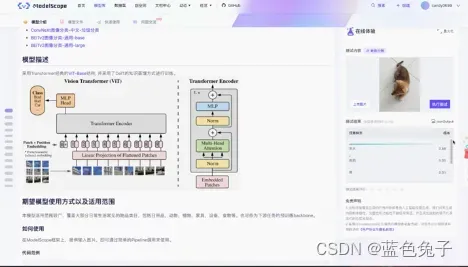
上面的在线体验已经得到了一个测试结果,这里显示了top5的结果,排名第一的是柴犬,所以这张图片的分类结果就是柴犬。
为了方便实验,我们首先把notebook打开。Notebook有两种选择,一种是PAI-DSW,一种是阿里云弹性计算。我们选择第二种,用免费的GPU资源进行计算。选择后点击快速启动。这个启动会稍微久一些,可以让它在后台启动。
接下来我们来讲解模型的一些基本情况。模型是transformer模型在视觉中的一个应用,我们简称为ViT。ViT模型,是自然语言领域中的transformer模型在计算机视觉上的一个开山之作。ModelScope上的模型采用的是基于transformer的ViT-Base结构,并在此基础上加入了蒸馏token进行知识蒸馏,也就是采用了DeiT的知识蒸馏的训练方式。
我们的训练数据是从海量的开源数据中进行搜索和整理的,保留了出现频率较高的一些常见的物体,大概包含1300多种日常物品,比如有一些常见的动物、植物、家具和食品等。目前模型可以识别1300多种日常物品,大家可以通过模型链接查看开源代码,还可以通过论文的链接去详细查看论文。
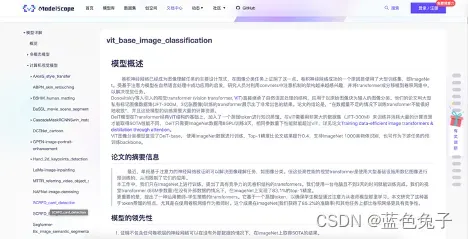
大家还可以在我们官网的文档中心 – 模型详解– 计算机视觉模型中找到我们配置的模型,这里有非常详细的介绍,包括论文的详解等。这是我们今天要用来做实验的ViT模型的简介,在此不做详细介绍。
另外关于我们要用的数据集,可以通过点击上方菜单栏中的数据集-图像-图像分类,就会看到很多可以用来做实验的数据集。
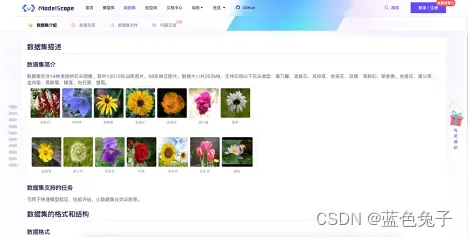
这里我们用的数据集是花朵分类数据集。这个数据集包含了14种类型的花朵图像,如风吟草、蒲公英、菊花等常见的花朵类型。整个数据只有200MB,比较小,适合我们线上训练微调过程的演示。用14种花朵的小数据集去重新fine-tune刚才介绍的ViT模型,使模型能够识别这14种花朵。
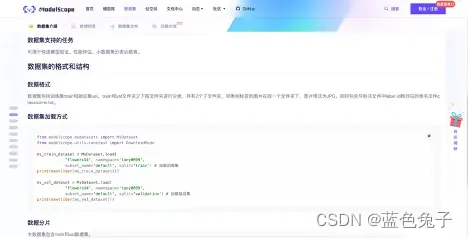
数据集的格式主要分为训练集和验证集,这里有描述的相关格式:是按照train和valid文件夹进行分类,共有2个文件夹,同类别标签的图片在同一个文件夹下,图片格式都为JPG格式,还有一个标签文件是classname.txt。
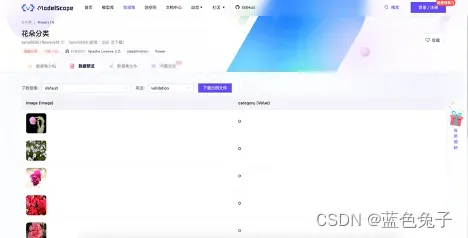
在数据预览里面可以看到数据的标注情况。比如在校验集中,左边是数据图片,右边是对应的标签。训练集也是一样的。
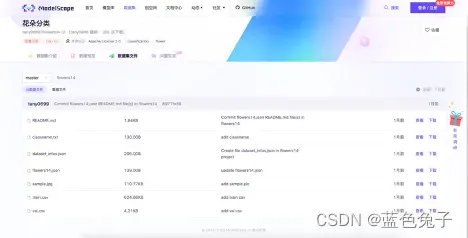
数据集文件是整个数据集的文件,其中包含了csv格式的校验集标签文件、训练集的标签文件、还有包含了flowers14.json。
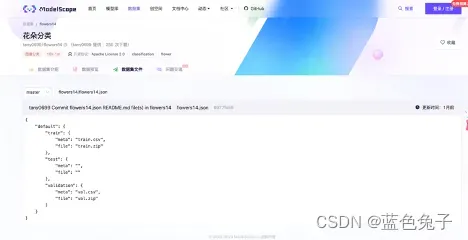
Flowers14.json文件里面描述了整个数据之间的关系,比如在训练集中,meta就是标签文件,file就是用来训练的图片的压缩文件,校验集同理。classname.txt文件中将标签对应的类别名称按顺序列了出来。
在数据文件里面是数据的压缩文件。
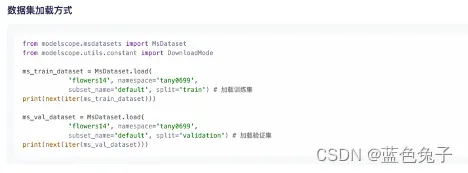
数据集的加载也非常简单,一行代码即可。我们引入依赖包之后,load数据集。加载数据集需要填入训练集名称和命名空间,就是对应数据名称下面的小字部分 。
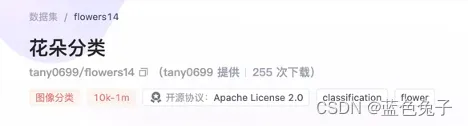
flowers14对应数据集名称,tany0699对应命名空间。加载训练集时split选择train,加载校验集时split选择validation。这就是数据集的一些基本情况。
回到模型训练页面,打开之前启动的notebook。
跳转后需要登录ModelScope和阿里云绑定的账号。
打开一个Python3的文件,可以选择对文件进行重命名,我们主要是为了对新的数据集重新进行训练。回到刚才的模型界面,把fine-tune的示例代码拷贝过来。
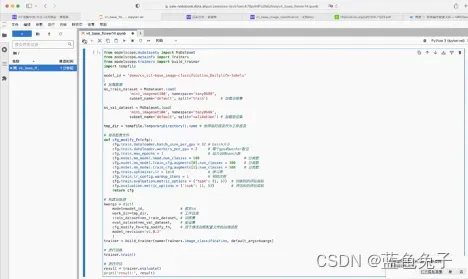
代码拷贝过来之后,我们对这些参数进行修改。首先引入ModelScope内部的依赖包,如果大家本地有GPU的话,也可以在本地做训练。在本地训练要预先安装好ModelScope的library,官方文档有介绍如何安装。
安装好之后,我们就可以通过线上免费的notebook来进行实验了。首先model_id对应的是模型在Model Hub上的地址,对于我们这个任务来说是没有变化的。之后是加载数据集,分别是加载训练集和校验集,数据加载方式之前已经介绍过了。将我们新的数据集的数据加载方式的示例代码拷贝过来替换掉就可以。
接下来是修改模型的配置文件。配置文件中会包含多种配置内容,主要需要修改的只有几项。首先是batch-size的大小,主要根据训练数据的大小和GPU显存的大小来设置;第二行是加载数据集的worker数量;最大训练的epoch数,就是对整个数据集迭代的次数,这里设置为1,主要是因为时间关系,只训练一次迭代。下面三行是分类数目,要把它改为数据集对应的分类数目,所以这里都改为14。学习率这里,因为我们只迭代一次,为了更好更快的收敛,可以把它改的稍微大一点。大家可以根据自己实际的训练次数来修改这个超参。预训练次数也设置为1;评估指标,对于分类任务来说,我们现在用的是精度来评估,精度中有top1和top5,这两个指标都要重新进行评估。
接下来构建训练器。训练器是用build_trainer的接口;name是分类的类型,这里是image_classification,是图像分类的意思。我们需要改的主要是参数kwargs。参数主要有model_id,就是之前提到的模型地址;word_dir,工作目录,就是训练后产生的模型权重保存的目录。示例中用的是一个临时目录,这里可以改为真实目录,比如改为vit_base_flower;train_dataset设置的是加载后的训练集;eval_dataset设置的是加载后的验证集;cfg_modify_fn是配置文件的回调函数;model_revision模型的版本,可以对应到模型文件(master按钮)里面,可以随意选一个版本,比如1.0.2,这样模型的训练器就构建好了。
之后使用trainer.train()就可以进行训练。训练完成后即可使用trainer.evaluate()进行评估,评估后将结果打印出来。然后按下shift + enter键运行代码,让模型开始训练。
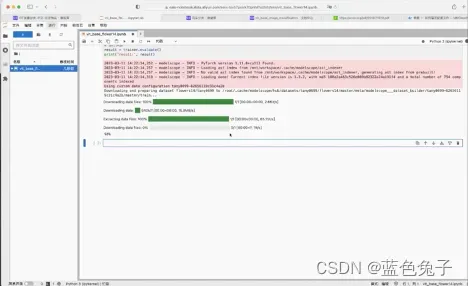
刚开始会比较慢,因为需要先下载数据集和模型预训练的权重。
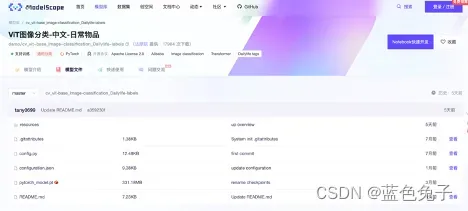
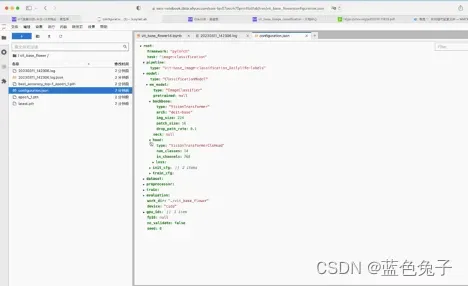
再来看一下模型文件。模型文件也比较简单,主要有两部分,一部分是预训练的权重,名字是固定的(pytorch_model.pt);另一部分就是整个模型的配置文件(configuration.json),主要是定义整个模型如何配置,如何训练和如何评估的。
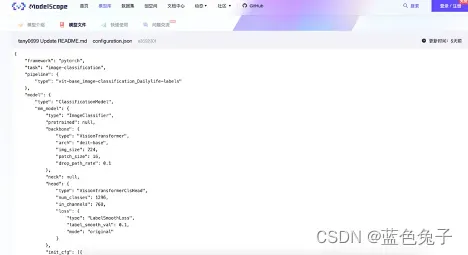
配置文件中,因为是基于pytorch进行训练,所以架构保持不变。任务是图像分类,pipline的名称也保持不变,定义模型类型保持不变。mm_model是兼容mm classification的模型的配置文件,backbone定义的是VisionTransformer,结构是deit-base,输入图像大小是224,patch_size大小是16等等这些参数都保持不变。Head是VisionTransformerClsHead,num_classes类别数默认的是1296,是日常物品的分类数目,这里我们需要改为14,因为新的数据集分类是14种。Loss用的是LabelSmoothLoss。还有一些初始化的参数都可以进行修改。训练用的与增强方式使用了Mixup和CutMix,这些参数也可以进行设置。
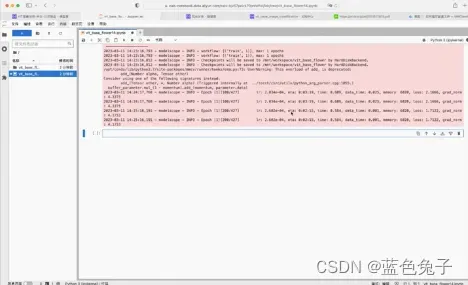
回到训练过程, epoch数,当前学习率,还有预计剩余时间,用的显存和loss的情况都可以打印出来。
回到配置文件。
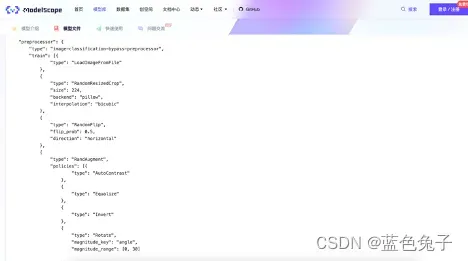
预处理器中的类型不变;训练过程,如加载图片,随机缩放和裁剪尺寸224,随机翻转和数据增强等都可以在文件中进行设置,最后是归一化;校验集同理,裁剪图片,resize到256,然后做一个crop到224,最后进行归一化。
训练过程中用到的batch_size的数目,worker的数目,最大迭代次数,以及评估的时候每间隔几次迭代就进行评估(这里是1次),使用accuracy进行评估,间隔1次迭代保存一次模型权重,最多保存权重数量20,优化器里的设置,包括优化类型,学习率等参数都可以在文件里进行修改。学习率的策略可以用CosineAnnealing,以及一些相关参数也可以进行定义。最后是评估的配置也可以进行设置,比如评估时batch_size的大小,worker数目,用的accuracy的方式进行评估,以及选择是top1还是top5的评估方式。
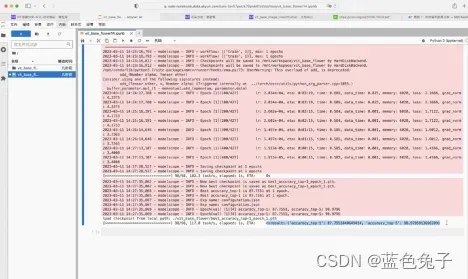
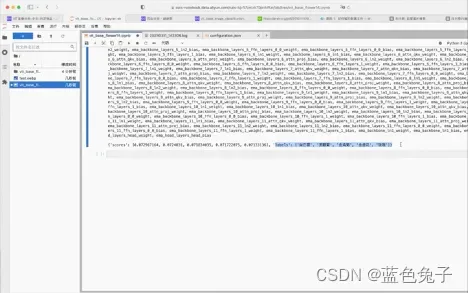
训练已经完成,可以看到结果已经打印出来:top1的精度是87.75,top5的精度是98.97 。训练一次,大概需要3分钟左右。
刚才训练的权重已经保存在了工作目录中。目录下有两个log文件,是训练过程的log,和刚才打印的结果完全一样。有一个模型的配置文件,和刚才讲过的配置文件是一模一样的。比如我们刚才改过的类别数,现在已经改为了14,因为刚才用的是回调函数,直接修改参数也被保存到了文件中。还有每个epoch保存的权重,现在只训练了一次,所以只有一个epoch_1。还有最后保存的权重的软连接,以及一个在训练过程中,校验集保存最好的模型权重。
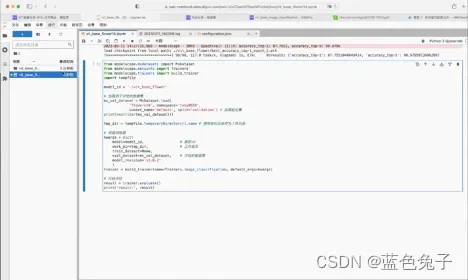
模型训练好之后,需要对它进行评估。可以评估训练好的模型在校验集上的性能。我们可以把模型评估的示例代码直接拷贝过来,同样的,数据集可以修改成刚才实验加载过的校验集,这是对新的校验集的评估。之前的model_id是Model Hub中的模型,现在改为训练保存的工作目录。但要注意,模型目录下的模型权重文件名称是固定的pytorch_model.pt,所以需要将权重文件重命名为pytorch_model.pt。工作目录可以用临时工作目录,校验集就是需要评估的数据集。训练器构建完成后,调用trainer.evaluate()进行评估,评估后将结果打印出来。按下shift + enter键运行代码,开始评估。
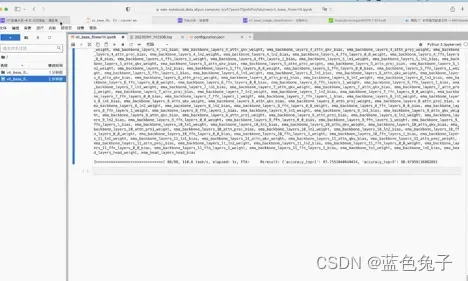
评估过程比较快,从打印出来的结果可以看到top1的结果是87.75,top5是98.97,和训练结果完全相同。
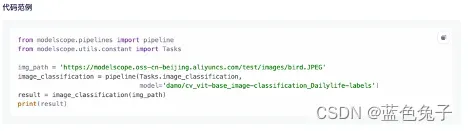
模型训练好后,可以进行推理,推理代码可以直接从模型任务页面拷贝过来。
要用训练好的模型,首先要加载依赖包,然后用pipline构建推理的pipline。这里输入的任务类型保持不变,模型改为刚才训练好的模型路径:vit_base_flower。图片地址可以是一个可访问的url,也可以是一个本地的图片路径。现在可以随便下载一张图片,比如向日葵的图片,命名为test.webp。本地下载好之后,可以直接将图片拖进界面中进行上传,然后将图片名称拷贝过来。将图片地址改为本地路径./test.webp,就可以对这张图片进行分类测试了。
推理结果中显示top5的结果,排第一的是向日葵,那么对这张图片分类预测的结果就是向日葵。但是对应的概率都很低,说明训练不是特别充分。因为只训练了一次迭代,所以还有很大的改进空间。大家可以去调整超参,尝试训练,比如最大epoch数可以调大一些,学习率可以调小一点,多训练一些可能会有更好的效果。
整个分类模型的预训练过程就到此结束了。
ModelScope中还有很多其他的分类模型,其他模型的训练流程和今天训练的任务流程是差不多的。比如ViT图像分类-通用模型和刚才训练的模型是完全一样的,但预训练的数据集是不一样的。日常物品模型用的是我们自建的数据集,通用模型是用的公开的ImageNet 1k的数据集。除此以外,还有比较实用的实时分类NextViT模型,比较适用于工业,因为速度快,分类效果也不错。其他模型,比如垃圾分类,大家也可以看一下。还有最近比较火的BEiT,是v2版本,大家也可以fine-tune一下。每个任务都会有模型简介、模型描述、以及一些链接,还有推理代码、微调训练代码以及评估代码,可以直接复制直接运行。
图像分类的微调训练教程就到此为止,大家如果感兴趣,可以到ModelScope官网(https://www.modelscope.cn/home)去进一步了解和尝试。
注意:如果是公开的模型/公开的创空间应用,则代码中不需要以下授权代码:
from modelscope.hub.api import HubApi
YOUR_ACCESS_TOKEN = '请从ModelScope个人中心->访问令牌获取'
api = HubApi()
api.login(YOUR_ACCESS_TOKEN)文章出处登录后可见!