DIVFusion: Darkness-free infrared and visible image fusion
(DIVFusion:无暗区红外与可见光图像融合)
红外与可见光图像融合是一种重要的图像增强技术,其目的是在极端环境下生成目标显著、纹理丰富的高质量融合图像。然而,现有的图像融合方法都是针对正常光照条件下的红外和可见光图像而设计的。在夜景场景中,由于可见光图像严重退化,现有方法存在纹理细节弱、视觉感知差等问题,影响后续的视觉应用。为此,提出了一种无暗度的红外与可见光图像融合方法(DIVFusion),该方法合理地照亮了暗度,有利于互补信息的融合。为了提高夜间可见光图像的融合质量,首先设计了一种场景亮度解纠缠网络(scene-illumination disentangled network (SIDNet)),在保留源图像信息特征的同时,去除夜间可见光图像的光照退化。然后,设计了一种纹理-对比度增强融合网络**(texture–contrast enhancement fusion network(TCEFNet))**,用于融合互补信息,增强融合特征的对比度和纹理细节。此外,色彩一致性损失被设计来减轻来自增强和融合的色彩失真。最后,充分考虑了弱光图像增强与图像融合之间的内在联系,实现了两者的有效耦合和互补。该方法能够以端到端的方式生成具有真实的色彩和显著对比度的融合图像。
介绍
由于技术限制和拍摄环境的影响,由同一设备捕获的单个图像往往不能提供整个场景的全面描述。因此,图像融合技术应运而生,它可以从不同的源图像中提取最有意义的信息,并将其融合成融合图像。融合图像通常包含更丰富的信息并促进后续应用。在图像融合领域,红外与可见光图像融合是应用最广泛的图像融合技术。可见光图像包含丰富的纹理信息,更适应视觉感知。通过获取丰富的热辐射信息,红外图像可以突出车辆、行人等重要目标,即使在弱光或其它极端恶劣的环境中。因此,红外与可见光图像融合不仅可以减少数据冗余,而且可以生成对比度显著、纹理细节丰富的高质量图像。由于这些优点,红外与可见光图像融合技术在军事监视、目标检测、车辆导航等方面具有良好的应用前景。
到目前为止,已经提出了相当多的红外和可见光图像融合方法,这些方法可以分为两大类:传统方法和基于深度学习的方法。传统的方法通常包括以下三个步骤。首先,利用特定的变换从源图像中提取特征,这是特征提取阶段。然后在特征融合阶段采用一定的融合策略对这些特征进行融合。最后,在特征重构阶段,根据相应的逆变换,由合并后的特征重构融合图像。根据所应用的数学变换,传统的红外和可见光图像融合方法可以进一步分为五类,包括基于多尺度变换、基于稀疏表示、基于显著性、基于子空间和基于混合的方法。
深度学习的兴起为红外和可见光图像融合提供了更多的可能性,基于深度学习的方法通常可以获得比传统方法更理想的性能。基于深度学习的方法根据网络架构可以进一步分为三类:基于CNN的方法、基于AE的方法和基于GAN的方法。基于神经网络的方法可以通过精心设计的网络结构和损失函数实现特征提取、特征融合和特征重构,并获得独特的融合结果。与基于神经网络的方法不同,基于AE的方法利用自动编码器完成特征提取和特征重构,而特征融合则通过特定的融合策略完成。基于神经网络的方法将生成对抗机制引入到红外与可见光图像融合领域。基于GAN的融合方法包括生成器和鉴别器。具体地说,鉴别器用于约束由生成器生成的融合结果的分布,使其尽可能接近源图像,而无需监督。
现有的基于深度学习的方法虽然能够有效地融合可见光和红外图像中的重要和互补信息,但仍存在一些需要解决的问题。
首先,现有的方法都是针对正常光照条件设计的,从而忽略了夜间可见光图像中光照退化的困难。在低光照条件下,现有的融合方法仅利用红外信息来弥补可见光图像光照退化造成的场景缺陷。因此,夜间可见光图像中丰富的场景信息无法在融合图像中表达,偏离了红外与可见光图像融合任务的初衷。
其次,直观的解决方案是使用先进的弱光增强算法对可见光图像进行预增强,然后通过融合方法对源图像进行合并。然而,将图像增强和图像融合作为单独的任务来处理常常会导致不兼容的问题,从而导致如图1(c)所示的较差的融合结果。具体地,由于夜景的弱光,夜间可见光图像具有轻微的颜色失真。弱光增强算法改变了光源的颜色分布,并在一定程度上进一步放大了整个图像中的颜色失真。此外,在融合过程中,由于Y通道应用的融合策略改变了源图像的饱和度分布,融合图像也会出现颜色失真,如图1(b)和(c)所示。

为了解决红外和可见光图像融合中的上述挑战,我们通过在网络中耦合视觉增强和图像融合技术来实现增强任务对融合任务的促进。为了获得具有良好视觉感知的信息融合图像,该方法的关键是在很大程度上消除两个任务之间的不相容性。为此,本文首先将通道注意机制与Retinex理论相结合,设计了一个场景亮度解纠缠网络(SIDNet)。具体地说,考虑到增强和融合任务的耦合,在特征级应用Retinex理论从混合特征中去除退化光照,同时生成增强的可见光图像和红外图像的特征。其次,设计了一个纹理-对比度增强融合网络(TCEFNet),该网络包含梯度保持模块(GRM)和对比度增强模块(CEM),实现了特征融合和特征增强。GRM通过一阶和二阶梯度残差流最大化特征梯度提取。CEM考虑多尺度深度特征,并结合注意机制实现特征级对比度增强。此外,我们提出了一种颜色一致性损失的方法,以保留更多的可见信息,同时减轻颜色失真。具体地说,我们基于可见光图像的RGB颜色空间构造了一个角度损失,可以有效地减少夜间弱光对颜色信息的破坏。
贡献
1)提出了一种新的视觉增强的红外和可见光图像融合框架,以增强视觉感知并融合互补信息,特别是在极低光照条件下。
2)设计了一种场景亮度解纠缠网络(SIDNet),用于剥离退化的光照特征,增强两种模态的独特特征,实现视觉增强。构造了纹理-对比度增强融合网络,在增强对比度的同时增强纹理,实现了互补信息的有效融合。
3)为了保证融合图像的视觉质量,我们设计了一种颜色一致性损失函数,它可以减少融合图像中的颜色失真,并将更多的可见域信息注入到融合图像中。
4)我们的融合结果具有更明亮的场景和更高的对比度,没有颜色失真,同时从源图像中获得互补信息,如图1(d)所示。行人检测实验证明了我们的结果在高级视觉任务中的促进作用。
相关工作
Deep learning-based fusion methods
Fusion methods based on CNN
基于卷积神经网络(CNN)的红外与可见光图像融合算法利用复杂的损失函数和网络结构实现特征提取、聚合和图像重构。PMGI是基于CNN的代表性工作,其设计了损失中的梯度和强度比,以引导网络直接生成最终的融合图像。但是,通过手动调整改变了梯度信息的保留,这造成了纹理结构的一些损失。上述问题在以后的版本中得到了改进,即,SDNet。为了在很大程度上将红外图像的对比度信息注入到融合图像中,在STDFusionNet中利用显著目标掩模来辅助融合任务。考虑到多尺度特征在融合过程中的优势,RXDNFuse结合了ResNet和DenseNet的结构优势,更全面地提取不同层次的特征,实现有效的融合。为了完成不同分辨率下的融合任务,Li等人利用元学习的优势,仅部署一个CNN模型就完成了红外和可见光图像的融合,大大扩展了融合模型的应用范围。为了更好地将融合任务与高级视觉任务相结合,Tang等人应用了一种新的语义损失,以使融合图像对高级视觉任务友好。此外,最近引入了类似于CNN的Transformer结构,它在各种视觉任务中实现了令人印象深刻的性能。因此,Ma等人设计了一种基于Transformer架构的通用融合方法,其中注意力引导的跨域模块可以整合全局互补信息。尽管如此,光照条件也是融合任务中不应忽略的问题,PIAFusion 考虑了光照,但模型过于简单,无法在复杂环境中调整光照。
Fusion methods based on auto-encoder
随着研究的深入,研究者提出了基于auto-encoder巨大的融合方法。他们中的大多数使用auto-encoder从源图像中提取特征,实现图像重建。特征融合过程主要适用于手工设计的融合规则。一个典型的AE-based融合方法,即DenseFuse,包括卷积层,融合层,和dense块。考虑到自动编码器结构的有限特征提取能力,Li等人进一步提出了NestFuse和RFN-Nest。前者引入了网络中的嵌套连接,可以从源图像中提取多尺度特征;后者设计了一种新颖的细节保留损失函数和特征增强损失函数,迫使网络获得更高集成度的细节特征。由于多尺度特征不能消除源图像中的冗余信息,Jian等人采用注意机制来集中注意源图像的显著目标和纹理细节。为了提供融合领域中可解释性的初步探索,DRF将源图像分解为场景分量和属性分量,并分别进行融合。虽然DRF考虑了特征提取的可解释性,但它忽略了融合规则的可解释性,即,手工制作的融合规则不一定适合于合并深度特征。因此,Xu等人进一步提出了一种可学习的融合规则,该规则评估特征中每个像素对分类结果的重要性,进而进一步提高网络的可解释性。
Fusion methods based on GAN
生成式对抗网络(generative adversarial network,GAN)具有无监督估计概率分布的强大能力,非常适合图像融合等无监督任务。FusionGAN是将GAN应用于图像融合领域的先驱,它在融合图像和可见光图像之间建立了一个生成式的对抗框架,使融合图像能够更大程度地获得纹理结构。然而,单一的对抗性博弈很容易导致不平衡的融合。为了改善这一问题,Ma等人提出了双鉴别器条件生成对抗网络(即DDcGAN ),以实现平衡图像融合,其中红外和可见光图像都参与对抗过程。
AttentionFGAN在DDcGAN的基础上增加了多尺度注意机制,保留了红外图像的前景目标信息和可见光图像丰富的背景细节特征。然而,具有双重鉴别器的生成式对抗网络不容易训练。在此基础上,Ma等进一步提出了具有多分类约束的生成式对抗网络,可用于平衡红外和可见光图像之间的信息。然而,这些方法追求更好的视觉质量,但忽略了对后续高级视觉任务的融合结果的促进。Liu等人针对融合和检测的联合问题提出了双层优化公式。
然而,现有的基于深度学习的融合方法和传统的融合方法都强调红外和可见光图像互补信息的注入和平衡,而忽略了极端环境,如最常见的光照退化。在夜间环境中,严重的黑暗场景急剧地劣化可见图像,导致融合图像不再提供良好的视觉感知。因此,相应的高级视觉任务可能会受到严重影响。夜间融合是红外与可见光图像融合的一个重要应用场景,但现有的融合方法无法实现。为此,迫切需要设计一种适用于夜间等极端条件下的无暗度红外与可见光图像融合方法。
Retinex-based image enhancement methods
Retinex-based
Retinex理论是一种颜色恒常性的计算理论。作为人类视觉感知的模型,它假设观察到的图像可以分解为反射率和照度,表示为:

其中𝑅和𝐿分别表示原始图像的反射率和照度。反射率𝑅描述了在任何亮度条件下都可以认为是一致的对象的固有属性。照明𝐿取决于对象上的环境光。
随后,Retinex模型被引入到弱光增强问题中。Jobson等人首先使用单尺度Retinex(SSR)从暗图像中剥离照明,并将反射率视为增强图像。然而,简单的分解导致严重的颜色失真。MSRCR被提出来改善先前方法的颜色失真问题。然而,上述方法的最终增强结果往往看起来不自然,并在某些地方过度增强。Wang等人提出联合增强对比度和保持照明的自然性。为了解决图像分解效率低和收敛慢的问题,Hao等人提出了半解耦分解模型,该模型𝑅𝐿以更合理的方式估计和。
随着深度学习的出现,光线增强社区也试图利用网络来估计反射率和照明的地图。RetinexNet结合Retinex理论设计深度网络,其中包含一个分解模块和一个照明调整模块。基于RetinexNet,Zhang等人开发了KinD ,其另外设计了一种新型网络以实现反射恢复。为了提高KinD在调节光照水平方面的灵活性,他们对KinD进行了修订,并提出了一个多尺度照度注意模块。此外,Zhang等人在以无监督方式完成有效分解之前提供了有效的直方图均衡化。特别地,它们规则化直方图均衡化增强的图像和恢复的图像之间的相似性。在此基础上,利用Retinex理论在特征层次上去除退化光照,实现图像增强。
方法
Problem formulation
当夜间可见光图像出现光照退化时,夜间红外与可见光图像融合问题可分为两个子问题:可见光图像增强和红外与可见光图像融合。然而,现有的弱光增强算法与融合算法的简单结合存在严重的不兼容问题。因此,如何对增强和融合任务进行联合建模,并在两者之间架起差距,成为夜间红外与可见光图像融合的关键。针对上述问题,我们设计了SIDNet和TCEFNet联合算法,以最大限度地缩小弱光增强和图像融合之间差距。前者用于在特征级剥离退化的可见光图像的照度分量。具体而言,SIDNet采用自动编码器和信道注意机制对两幅源图像进行重构,保留了源图像的有用信息,促进了后续的融合任务。后者从纹理和对比度方面实现了特征融合,增强了整体视觉感知。图2示意性地示出了总体框架。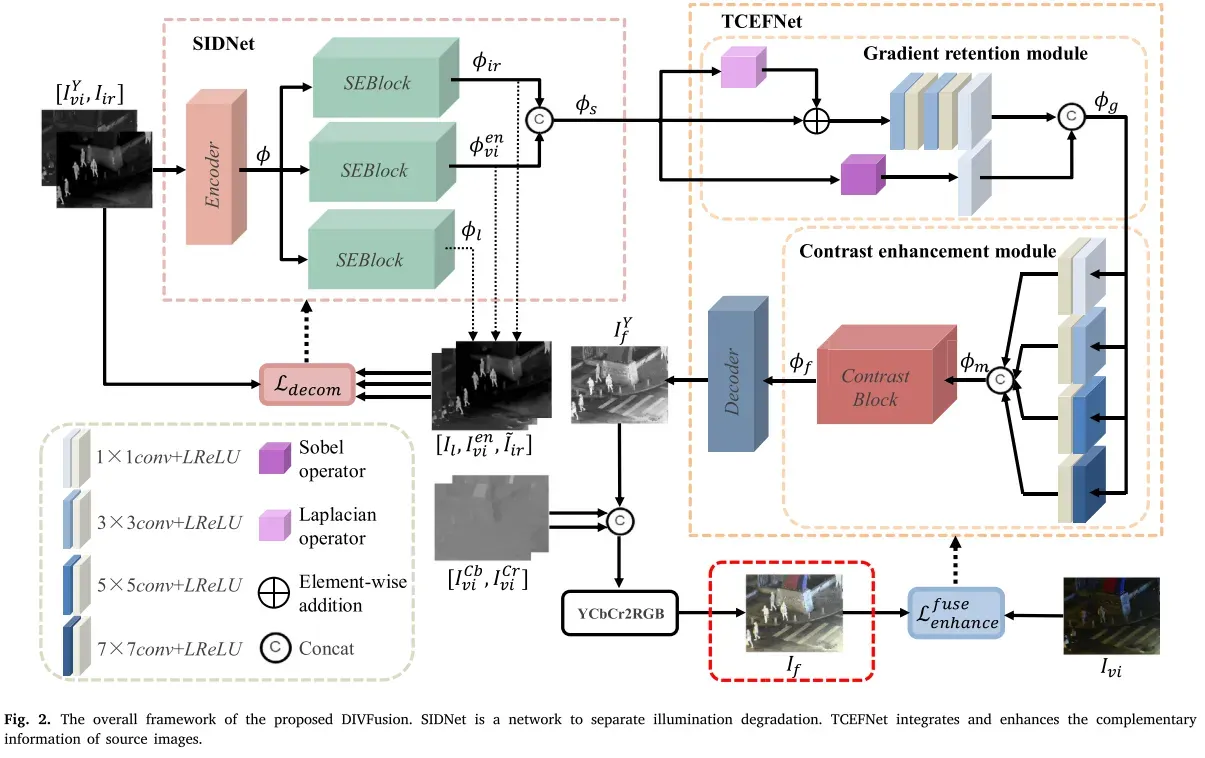
更具体地,给定一对严格配准的红外图像𝐼𝑖𝑟和可见光图像𝐼𝑣𝑖。它们在信道维度上被级联,并被馈送到𝐸(·)的SIDNet的编码器中,如图3所示,
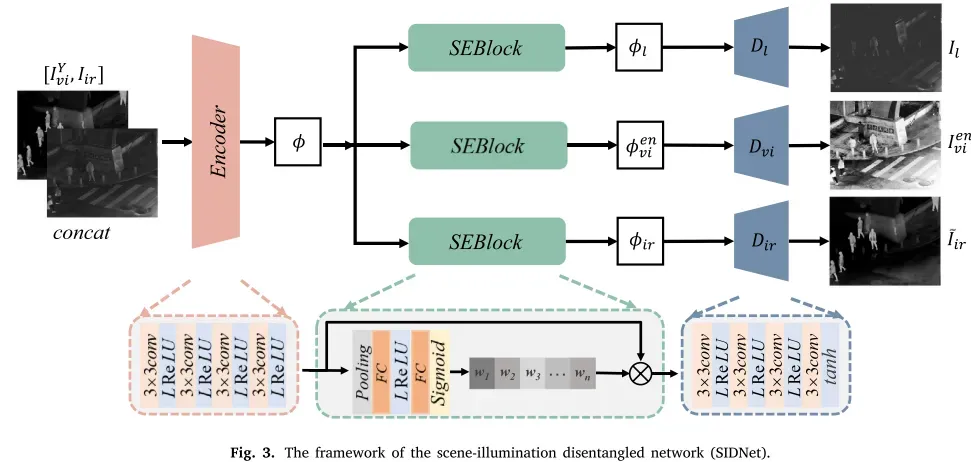
以便获得𝜙具有两个域信息的混合特征。上述过程可表述如下:

其中𝑣𝑖表示可见图像的Y通道。其次,将两个域信息的混合特征输入到三个压缩和激励模块(SEblock)中。SEblocks旨在从混合特征中选择红外和可见光图像的特定领域特征表示。此外,SIDNet的另一个作用是分离可见光图像的亮度分量。因此,我们在特征层面上利用Retinex理论将可见光图像分解为退化的光照特征和增强的可见光特征。然后,将三个SEblock与Retinex理论相结合,最终得到红外特征、退化照度特征和增强的可见光特征。整个过程可以表示为:
其中,𝐷𝑙(·)、𝐷𝑣𝑖(·)、𝐷𝑖𝑟(·)分别表示照度重建解码器、增强可见光解码器和红外解码器。𝐼𝑙、𝑣𝑖、𝐼𝑖𝑟分别表示可见光图像、Y通道上增强的可见光图像和重建的红外图像的退化照度分量。值得一提的是,只有增强的可见光特征Font metrics not found for font: .𝑣𝑖和红外特征𝜙𝑖𝑟在信道维度中被级联作为SIDNet的输出,其被定义为:

在此基础上,设计了TCEFNet,它包含两个模块,GRM和CEM。GRM的具体设计如图4(a)所示。SIDNet的输出特征直接输入到GRM中,以增强特征的细粒度表示。我们使用Sobel算子和Laplacian算子联合增强混合特征。特征级的纹理增强过程表示为:
CEM应用不同的卷积核,即。1×3×3、5×5,7×7,扩大认知领域的网络。之后,功能包含多尺度信息块的对比中得到强化。对比块的架构如图4所示(b)。
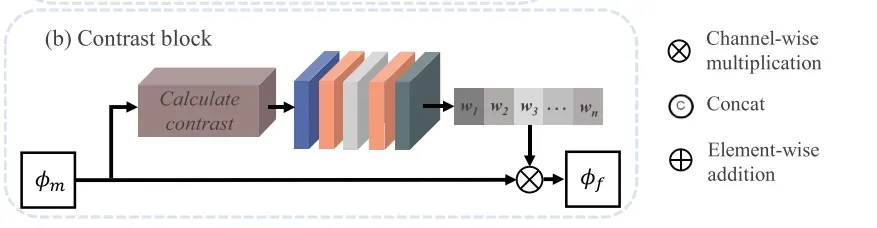
基于通道注意机制,对比度块计算特征的对比度,并为较高对比度的特征分配较高的权重,以实现对比度增强。具体配方如下:
最后,解码器对融合后的图像𝑓进行重构𝐷。需要强调的是,这
𝑓只是Y通道增强的可见光图像与红外图像的融合结果,红外图像具有明亮的场景,但缺少颜色信息。融合图像的重建可以表示为:

所获得的𝑓是第一个连接𝐶𝑏,𝐶𝑟通道的原始可见图像在通道维度以得到初始彩色融合图像。由于Y通道融合图像
𝑓只注重亮度增强和图像融合,而忽略了色度的适宜性,使得初始融合图像存在严重的颜色失真。然后,将融合后的图像转换到RGB空间,利用颜色一致性损失对颜色分布进行校正。具体来说,
𝑓在RGB空间中进行调整和优化,直到它与𝐶𝑏、𝐶𝑟原始可见图像的和通道相匹配为止,这样可以消除颜色失真并保持场景亮度。将初始融合图像转换到RGB空间的过程如下:

Network architecture
如图2所示,我们设计了场景-亮度解纠缠网络和纹理-对比度增强融合网络。下面介绍这两种网络。
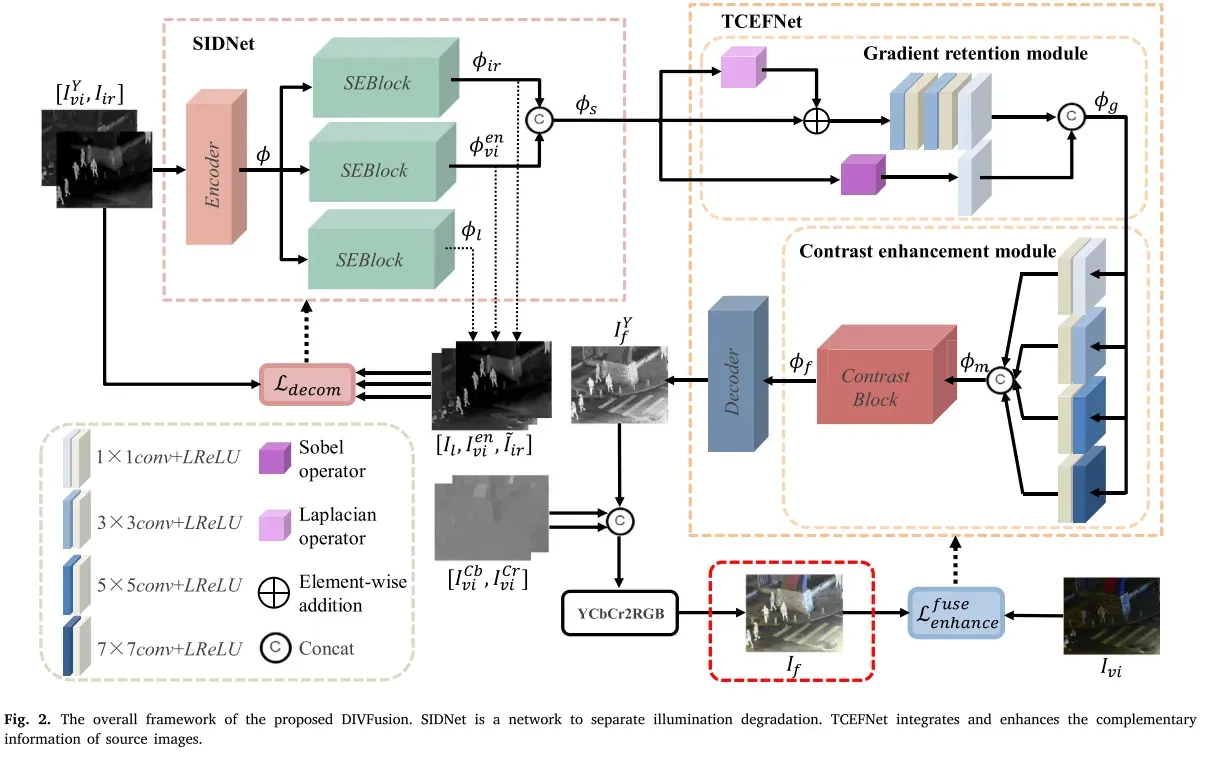
Scene-illumination disentangled network (SIDNet)
SIDNet的具体结构如图3所示,它由一个编码器、三个并行的SEblock和三个并行的解码器组成。该编码器包含4个卷积层,其核大小为3 × 3,激活函数为LReLU(Leaky Rectified Linear Unit)。紧接着是三个SE块,用于增强互补信息和去除退化照明。SEblock包括最大池层、全连接层、LReLU层、全连接层和sigmoid层。解码器由4个3 × 3卷积层组成。除最后一层的激活函数为Tanh外,其余各层的激活函数均为LReLU。我们在训练阶段期间仅生成增强图像、退化照明图像和重建的红外图像。 我们的模型直接生成红外特征和增强的可见光特征,然后在推理阶段将它们馈送到后续的网络中。
Texture–contrast enhancement fusion network (TCEFNet)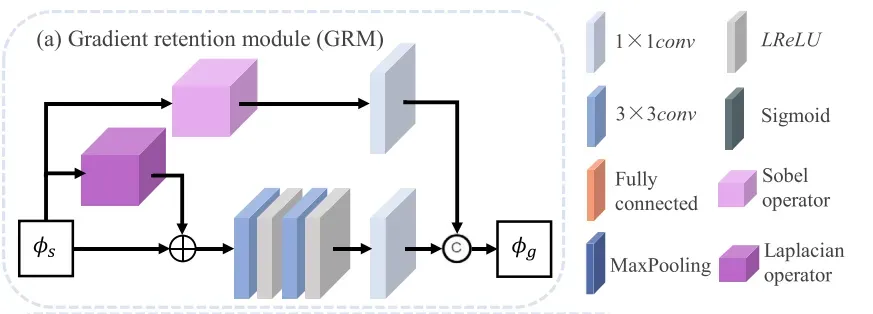
TCEFNet由两个模块组成,即:梯度保持模块(GRM)和对比度增强模块(CEM)。GRM的具体设计如图4(a)所示。GRM是resblock的变体,其获得主流和两个残余流。主流采用两个带有LReLU的3 × 3卷积层和一个1 × 1卷积层。第一个残差流集成了Sobel算子以保留特征的强纹理,并集成了1 × 1卷积层以消除通道维度的差异。在图4(a)中,第二残差流采用Laplacian算子。特别地,引入Laplacian算子进一步仔细地提取特征的弱纹理。然后,纹理增强的第一阶段通过经由逐元素加法将GRM的输入和第二残差流的输出相加来完成。然后,将主流和第一残余流的输出在通道维度上级联,以捕获具有细粒度细节的深度特征并实现第二阶段的纹理增强。
增强的特征被馈送到图2中所示的CEM。同尺度卷积阻碍了不同特征中多尺度信息的提取。因此,使用具有不同核大小的四个卷积层来捕获多尺度深度特征。为了减少CEM中的信息丢失,不同的卷积操作没有池化层。卷积层的核大小分别为1 × 1、3 × 3、5 × 5、7 × 7。卷积层的激活函数为LReLU。然后,如图4(b)所示,将获得的特征在通道维度中级联并发送到对比度块。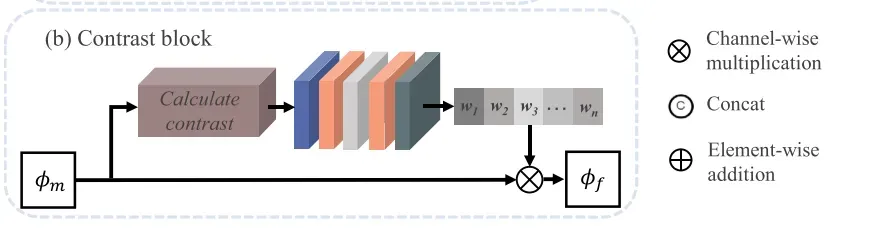
Loss function
Decomposition loss
为了确保我们的SIDNet在特征级去除可见光图像的退化照明,我们设计了包含以下五项的分解损失函数:

其中𝑟𝑒𝑐𝑜𝑛和分别
𝑟𝑒𝑐𝑜𝑛是红外和可见光图像重建损失函数。它们强制混合特征包含更多具有高保真度的互补信息。
和
𝑠𝑚𝑜𝑜𝑡ℎ分别是相互一致性损失和光照平滑度损失,它们指导SIDNet从混合特征中生成退化的光照分量。在训练过程中,感知损失L𝑝𝑒𝑟约束增强的可见特征的生成。𝜆1、𝜆2、𝜆3、𝜆4、𝜆5表示控制每个损失项的折衷的超参数。
红外和可见光重建损失可以驱动SIDNet尽可能多地恢复原始图像,生成冗余度更少的高保真特征,定义为:

上述两种损失函数只能约束最终重建的红外和可见光图像,而不能约束光照分量。因此,为了从原始可见图像中剥离退化照明分量,我们进一步应用以下两个损失函数,以基于KinD 和RetinexNet 中的照明定义来具体约束照明分量的生成,其表达如下
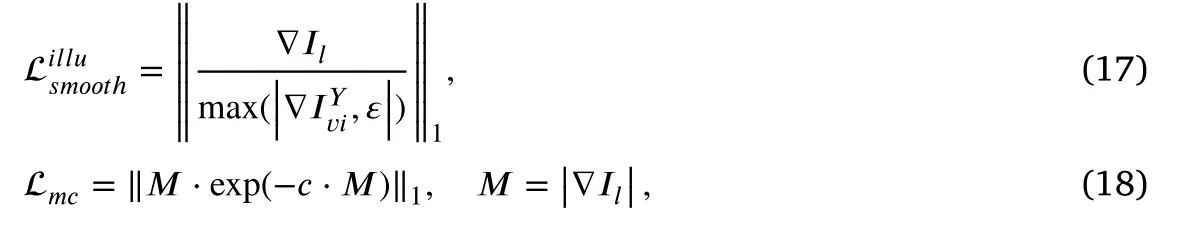
其中▽是包含𝑥和𝑦方向的Sobel算子。𝜀 是一个很小的正常数(本文中为0.01),以防止除数为零。这些函数降低了结构边界上过度平滑的风险。c是控制相互一致性损失形状的参数(本文中为10),其目的是增加图像的中等梯度部分。
和
𝑠𝑚𝑜𝑜𝑡ℎ的结合使得生成的照明分量在物理上与定义更加一致。
由于缺乏ground truth信息来指导训练过程,很坚韧通过间接损失函数从弱光可见光图像中恢复增强的可见光图像。幸运的是,直方图均衡化增强图像的特征可以提供丰富的纹理和亮度信息。为此,采用VGG特征约束弱光可见光图像Y通道与直方图均衡化增强图像之间的感知相似性。自定义感知损耗如下:

在预训练的VGG-19网络中,浅层特征关注纹理信息,深层特征更关注语义信息。为了有效地提高后续高级视觉任务的性能,我们期望增强的特征包含更多的深层语义信息。因此,我们只选择VGG-19网络的最后两层来实现深度特征提取,即:从层𝑐𝑜𝑛𝑣4_1和𝑐𝑜𝑛𝑣5_1提取特征以联合地测量特征相似性。
Enhancement-fusion loss
我们期望训练一个优化的TCEFNet用于图像融合、特征增强和颜色均衡。增强-融合损失的确切定义表示如下:
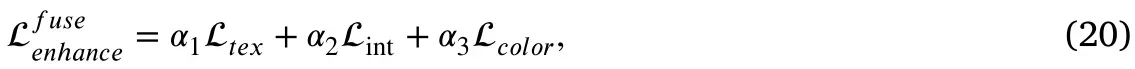
文章出处登录后可见!