数据分析实训第8章企业所得税预测分析(无警告、无报错、分析很齐全)
前言
这些天抽空把数据挖掘再重温了一遍,再次做这题时,查看网上的答案发现,很多都存在着一些问题,因此自己特意写了一下,代码无一报错或者警告,大家可以放心使用。
一、背景介绍
1.选题
选择第8章实训任务——企业所得税预测分析
2.分析企业所得税预测背景
(1)企业所得税简介与需求
企业所得税,是对我国境内的企业和其他取得收入的组织的生产经营所得和其他所得征收的一种所得税。在我国,企业所得税的纳税人是企业和其他取得收入的组织,包括各类企业、事业单位、社会团体、民办非企业单位和从事经营活动的其他组织。企业所得税税率为25%的比例税率,非居民企业为20%。企业应纳所得税额=当期应纳税所得额*适用税率,应纳税所得额=收入总额-准予扣除项目金额。
我国的企业所得税只对利润征收,常用比例税率,对大多数企业来说承担相同的税负水平,有利于促进公平。同时采用比例税率的企业所得税相比于其他国家实行的累进税率更有利于促使企业改善经营管理,努力降低成本,提高盈利水平。同时我国现行的企业所得税也有利于发挥政府在对纳税人投资、产业结构调整、促进经济发展。企业所得税也是国家建设筹集财政资金的重要途经之一,意义重大。
对企业所得税进行预测分析,有利于促进企业纳税人自觉纳税的意识,有利于打击逃税、漏税等行为,保障国家税收的正常稳定进行,为国家建设打下坚实的财政资金基础。因此建立正确有效的企业所得税预测模型是十分有必要的。
(2)企业所得税预测数据基础情况
此次建模采用的数据集包括2004–2015全社会固定资产投资额、城市商品零售价格指数、建筑业总产值、限额以上连锁店(公司)零售额等数据。
(3)企业所得税预测分析目标
a. 分析识别影响企业所得税的特征数据
b. 建立预测模型,对2014年及2015年的企业所得税进行预测,并对模型进行评价。
3.了解企业所得税预测方法
通过查阅课本、相关论文和资料,发现运用Lasso特征选择方法来研究企业所得税的影响效果相对较优。本次建模在Lasso特征选择的基础上,考虑到灰色预测对少量数据预测的优良性能,建立灰色预测模型,然后把灰色预测得到的数据结果代入训练完成的模型中,这样在充分考虑原始数据的基础上,得到比较准确的预测结果,即2014年和2015年企业所得税。
二、实训1
1.任务描述
对影响企业所得税的原始特征进行相关性分析,对原始特征间的相关性和原始特征与目标特征之间的相关性进行解读。
2.任务分析
运用相关函数计算特征之间的相关系数,对原始数据进行相关性分析。
3.训练要点
(1)掌握Python中的相关性分析方法
相关性分析是指对两个或多个具备相关性的特征元素进行分析来判断两个特征因素的相关密切程度的大小。Pearson 相关系数是最简单的相关系数之一,可用来判断两个特征X和Y之间的线性相关的强弱,通常用r或ρ表示,它的取值范围为[-1,1]。
Pearson相关系数的计算方式如下:若两个向量X=(x1,x2,…,xn),Y=(y1,y2,…yn)
则Pearson相关系数为:
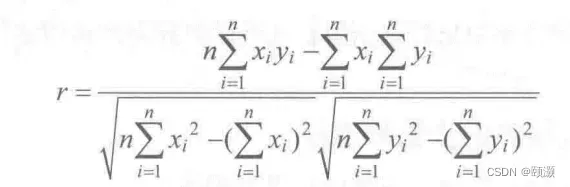
(2)理解并会用Python实现企业所得税预测相关特征的相关性分析
(3)对相关性分析结果进行解读
4.实现思路及步骤
(1)求取原始数据特征之间的Pearson相关系数
(2)判断各个特征之间的相关性
5.任务实现
求取原始数据特征之间的Pearson相关系数
import numpy as np
import pandas as pd
inputfile = '../data/income_tax.csv' #读取数据文件
data = pd.read_csv(inputfile) #读取数据
#保留两位小数
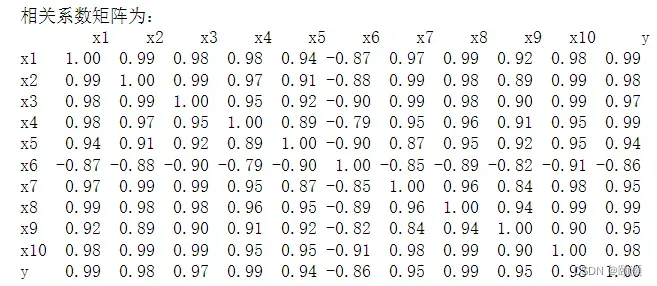
print('相关系数矩阵为:','\n',np.round(data.iloc[1:,1:].corr(method = 'pearson'), 2))
(2)判断各个特征之间的相关性
由获得的Pearson相关系数矩阵可得,选取的各特征与y的相关性都比较强,不过规模以上国有及国有控股工业企业亏损面(x6)与企业所得税(y)的线性关系呈现较强的负相关关系。其余特征均与企业所得税呈现高度的正相关关系,按相关性从大到小,依次是 x1,x4,x8,x2,x10,X3,x7,x9,x5。同时,各特征之间存在着严重的多重共线性,例如特征x2,x3,x10与除了x6、x9之外的特征存在严重的共线性,x7、x8和x1、x2存在严重的共线性,……综上可得选取的各特征与y的相关性都很强,可以用作企业所得税预测分析的关键特征,但这些特征之间存在着信息的重复,需要对特征进行进一步筛选。
注:虽然x6与y的Pearson相关系数是-0.86,是负相关,和其他特征与y呈现的高度的正相关不同,但是也不能忽视其影响,因为它的负相关性是比较强的,对企业所得税的影响比较大,故此处选择留下x6是合理的。
三、实训2
1.任务描述
对影响企业所得税的因素进行特征筛选,选取出对企业所得税有关键影响的特征,为下一步的模型构建奠定基础。
2.任务分析
(1)了解掌握Lasso回归模型
Lasso回归方法属于正则化方法中的是压缩估计。以缩小特征集为思想,通过构造一个惩罚函数从而得到一个较为精炼的模型,将特征的系数进行压缩从而使某些回归系数变为0,进而达到特征选择的目的,Lasso回归方法广泛地应用于模型改进与选择。
Lasso回归方法多适用于原始特征中存在多重线性的情况,可以弥补最小二乘估计法和逐步回归局部最优估计的不足,很好地进行特征的选择,解决多重共线性的问题。但是当有一组高度相关的特征时,Lasso回归方法倾向于选择其中的一个特征,忽视其他所有的特征,这会导致结果的不稳定性。
在本次预测中,各原始特征存在着严重的多重共线性,多重共线性问题已成为主要问题,这里采用Lasso回归方法进行特征选取是恰当的。
(2)解读Lasso回归结果
3.训练要点
(1)理解Lasso回归模型,掌握其场景及优缺点。
(2)掌握使用Lasso回归使用进行特征选取的方法。
(3)理解并掌握上述过程的Python代码实现。
4.实现思路及步骤
(1)建立Lasso回归模型
(2)对Lasso回归结果进行解读
5.代码实现
在构建Lasso模型时,我一开始时没有对数据进行预处理,直接调用Lasso()函数,但是无论入值怎么修改,得到的数据用于后续的模型中,得到的2014年和2015年的预测值和真实值的误差还是很大。当入值越大,“惩罚函数”的惩罚力度越大,导致部分关键特征因素也被筛除了,造成的误差越大,但是如果入值取小时,由于训练次数太小,不能够达到关键特征筛选的目的。自己查阅相关资料,发现可以对数据进行标准化,然后通过模型先算出来一个各个列之间共线性关系的值,手动的去掉一些无关的列。
下面是具体的构建过程,导入数据集,进行数据标准化,调用Lasso()函数,建立Lasso模型,筛选出对企业所得税有关键影响因素的特征数据,同时保存筛选出的数据到income_tax_deal.csv文件中。
import numpy as np
import pandas as pd
from sklearn.linear_model import Lasso
inputfile = '../data/income_tax.csv' #读取数据文件
data = pd.read_csv(inputfile) #读取数据
data_train = data.iloc[:,1:11].copy();
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train-data_mean)/data_std; #数据标准化
#建立模型
lasso = Lasso(alpha=1000,random_state=1234) #设置λ的值为1000
lasso.fit(data_train,data['y'])
print('相关系数为:',np.round(lasso.coef_,5)) #相关系数保留五位小数
#计算相关系数非0的个数为
print('相关系数非零个数为:',np.sum(lasso.coef_!=0))
mask=lasso.coef_ !=0
print('相关系数是否为0:',mask)
mask=np.insert(mask,0,[False])
#选取出对企业所得税有关键影响因素的特征
# mask=np.insert(mask,0,[False]) #第一列为年份,在读入新表格的时候要排除
#书上的代码缺少对mask数组的再次过滤,过滤出非零的数据
mask = np.append(mask,False)
outputfile = '../tmp/income_tax_deal.csv' #输出数据文件
new_income_tax = data.iloc[:, mask] #返回相关系数非零的数据
new_income_tax.to_csv(outputfile) #存储对企业所得税有关键影响因素的特征数据
print('输出数据的维度为:',new_income_tax.shape) #查看输出数据的维度
结果是:

建立Lasso模型计算出相关系数,对相关系数进行分析处理,得出相关系数非零的个数有5个,这些是影响企业所得税的关键因素:第二产业增加值(x1)、城市商品零售价格指数(x4)、建筑业企业利润总额(x5)、规模以上国有及国有控股工业企业亏损面(x6)、限额以上连锁店(公司)零售额(x9)。
四、实训3
#企业所得税灰色预测
import numpy as np
import pandas as pd
from GM11 import GM11 #引入自编的灰色预测函数
#数据抽取
inputfile = '../tmp/income_tax_deal.csv' #输入的数据文件
inputfile1 = '../data/income_tax.csv' #输入的原数据文件
new_income_tax = pd.read_csv(inputfile) # 读取经过特征选择后的数据
data = pd.read_csv(inputfile1) #读取总的数据
#预处理
new_income_tax.index = range(2004, 2016)
new_income_tax.loc[2014] = None
new_income_tax.loc[2015] = None
l = ['x1', 'x4','x5','x6','x9']
for i in l:
#as_matrix自0.23.0起不推荐使用该方法,因此应to_numpy改为使用
f = GM11(new_income_tax.loc[range(2004,2014),i].to_numpy())[0]
new_income_tax.loc[2014,i] = f(len(new_income_tax)-1) #2014预测结果
new_income_tax.loc[2015,i] = f(len(new_income_tax)) #2015预测结果
new_income_tax[i] = new_income_tax[i].round(2)
outputfile = '../tmp/income_tax.csv_deal_GM11.xls' #灰色预测后保存的路径
y = list(data['y'].values)
new_income_tax['y'] = y
new_income_tax.to_excel(outputfile,engine='openpyxl')
print('预测结果为:',new_income_tax.loc[2014:2015,:])
导入灰色预测函数,读取上一步经过特征选择过的数据集,使用灰色预测函数对其进行处理建立灰色预测模型。

由上述结果可以清晰的看出灰色预测的精确度是非常高的,对于2014年和2015年的x1、x4、x5、x6、x9的预测是比较准确的,为下面的支持向量回归预测打下了比较好的数据基础,同时企业所得税2014与2015年的预测是非常准确的。
向量回归模型
将上一步灰色预测的结果代入企业所得税建立的向量回归预测模型
#企业所得税支持向量回归预测模型
import numpy as np;
import pandas as pd;
from sklearn.svm import LinearSVR
import matplotlib.pyplot as plt
from sklearn.metrics import explained_variance_score,mean_absolute_error, mean_squared_error,median_absolute_error,r2_score
inputfile = '../tmp/income_tax.csv_deal_GM11.xls' #灰色预测后保存的路径
data = pd.read_excel(inputfile) #读取数据
feature = ['x1', 'x4','x5','x6','x9']
data_train = data.loc[0:11,:]
data_mean = data_train.mean()
data_std = data_train.std()
data_train = (data_train - data_mean)/data_std #将数据数据标准化
x_train = data_train[feature].values #特征数据
y_train = data_train['y'].values #标签数据
linearsvr = LinearSVR() #调用LinearSVR()函数
linearsvr.fit(x_train,y_train)
x = ((data[feature] - data_mean[feature])/ data_std[feature]).values #进行预测,并还原结果。
data[u'y_pred'] = linearsvr.predict(x) * data_std['y'] + data_mean['y']
## SVR预测后保存的结果
outputfile = '../tmp/income_tax_corr_GM11_SVR.xls'
data.to_excel(outputfile,engine='openpyxl')
data.index = range(2004,2016)
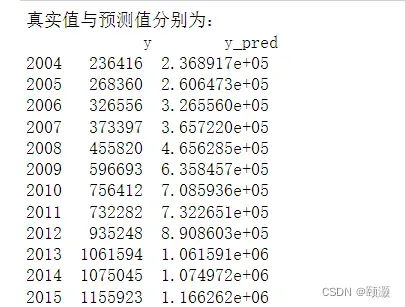
print('真实值与预测值分别为:','\n',data[['y','y_pred']])
print('预测图为:',data[['y','y_pred']].plot(subplots = True,
style=['b-o','r-*'],xticks=data.index[::2]))

由上述的结果和预测图可以清楚的看到预测值与真实值非常接近,模型对2014年和2015年的企业所得税的预测是准确的。
(5)模型评价
print('企业所得税回归模型的平均绝对误差为:',
mean_absolute_error(data['y'].iloc[0:11],data['y_pred'].iloc[0:11]))
print('企业所得税回归模型的均方误差为:',
mean_squared_error(data['y'].iloc[0:11],data['y_pred'].iloc[0:11]))
print('企业所得税回归模型的中值绝对误差为:',
median_absolute_error(data['y'].iloc[0:11],data['y_pred'].iloc[0:11]))
print('企业所得税回归模型的可解释方差值为:',
explained_variance_score(data['y'].iloc[0:11],data['y_pred'].iloc[0:11]))
print('企业所得税回归模型的R方值为:',
r2_score(data['y'].iloc[0:11],data['y_pred'].iloc[0:11]))

由上述的评价结果可得,平均绝对误差与中值绝对误差较小,可解释方差值和R的平方值十分接近1,表明建立的支持向量回归模型拟合效果优良,可以用于企业所得税的预测。
文章出处登录后可见!