

个人名片:
🐅作者简介:一名大二在校生,热爱生活,爱好敲码!
\ 💅个人主页 🥇:holy-wangle
➡系列内容: 🖼️ tkinter前端窗口界面创建与优化
🖼️ Java实现ATP小系统
✨个性签名: 🍭不积跬步,无以至千里;不积小流,无以成江海
大家五一假期好!休息了几天,今天准备捋捋思路把之前泰迪杯的比赛经历记录一下,分享各位想练手或者参加比赛的小伙伴们

泰迪杯比赛流程回顾:
第一阶段:
第一阶段:报名时间,时间:2月18日-4月14日。这个比赛开始的时候还是比较早的,在今年2月18日已经出题了,2月18日-4月14日是报名时间而已,还有很多时间给你学习对应的知识。这个出题就是指题目的背景和题目的问题已经给了大家,不过没有具体的数据,有示例数据,不过有点难支撑做题,就拿今年的泰迪杯A题来说,如下图:

这个是需要解决的问题的第一问,但是在示例数据里面,你找不到一个阳性人员,都是阴性的,所以很难支撑你继续做题,不过你可以自己创造一些,先做出来也是可以的对吧!哈哈!
第二阶段:
第二阶段是选题时间,时间:4月15日-4月24日。这个时间段我们可以进行具体选择题目去做,一般我觉得应该在报名阶段就可以选择对应的题目了,而且这个时候具体数据已经公布了,所以这个时间就记得在官网的界面点击选择对应的题目,并且已经可以开始对题目进行试做了,不要等到第三阶段才开始做。
第三阶段:
第三阶段是作品的完成时间,时间:4月25日-4月28日。因为每一道题目有对应的题目的结果和论文需要提交作为评奖参考,所以这个阶段是进行提交的时间,我觉得我们在第二阶段就应该把对应题目做好了,这个时间可以再修改一下论文或者代码什么的。
第四阶段:
第四阶段是测试结果提交时间,时间:4月29日-4月30日。这个阶段不一定所有题目都存在,就比如今年的C题,那个题目不用进行模型测试,所有不用进行测试结果提交。
A题模型的建立思想:
这是题目:

这是我的解决思路流程图:
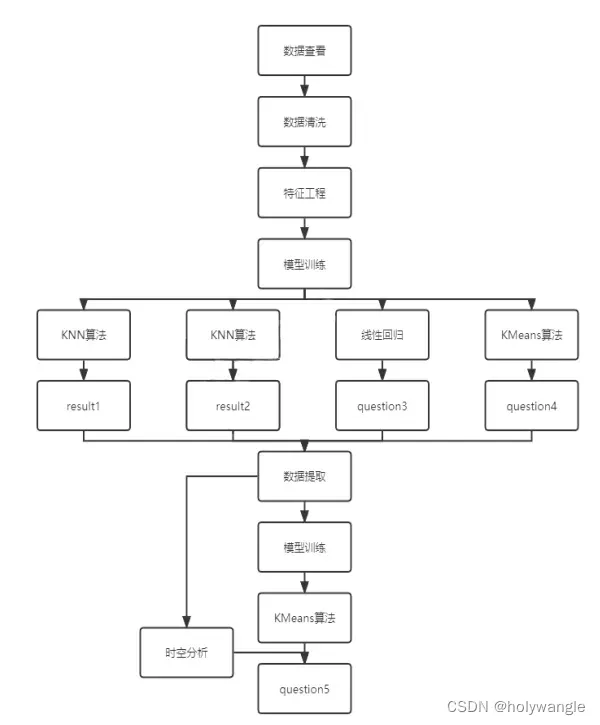
问题一分析:
问题内容:根据题目描述,问题 1 需要根据核酸检测中阳性人员的出行时间与场所,追踪密接者并将结果保存到“result1.csv”文件中。
建模思路:
1.数据预处理
首先,需要对提供的疫情数据进行预处理,以便进行后续的分析。数据预处理包括数据清洗、数据集成、数据转换等方面,可以考虑使用 Python 中的 pandas 库进行数据处理。需要将阳性人员的出行时间和场所信息与其他密接者的信息进行整合,得到一个完整的数据集。
2. 密接者追踪 密接者追踪是指根据阳性人员的出行时间和场所信息,找到与其有过密切接触的人员。可以利用机器学习、网络分析等方法进行密接者追踪。例如,可以使用 k-近邻算法来找到与阳性人员有过密切接触的其他人员,或者使用社交网络分析来找到与阳性人员有过接触的人员。
3. 结果输出 最后,需要将密接者的信息保存到“result1.csv”文件中。可以使用 Python 中的 pandas 库将结果输出到 csv 文件中,并根据要求设置好文件格式。
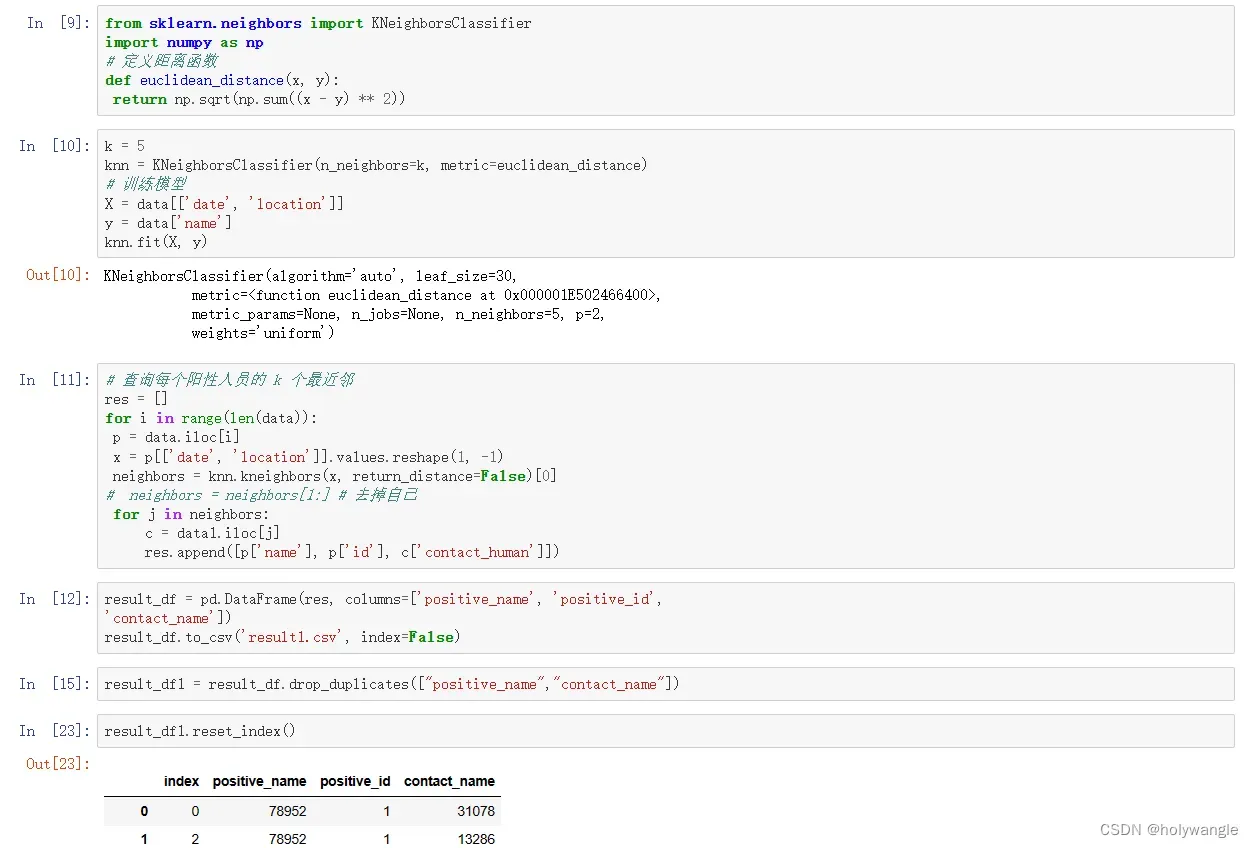
问题二分析:
问题内容:问题 1 的结果,根据密接者的出行时间与场所追踪相应的次密接者,将结果保存到“result2.csv”文件中。
建模思路:
问题 2 要求根据问题 1 的结果,进一步追踪次密接者的信息,并将结果保存到“result2.csv”文件中。具体来说,需要对问题1 中找到的密接者再次进行追踪,找到与其有过密切接触的其他人员。
1. 对问题 1 中找到的每个密接者,遍历其接触时间和场所信息,找到与其有过密切接触的其他人员;
2. 定义距离函数,计算两个人员之间的距离;
3. 使用 k-近邻算法方法,找到每个密接者的k 个最近邻;
4. 将结果保存到“result2.csv”文件中,包括密接者和次密接者的姓名、身份证号、电话号码、接触时间和地点等信息。
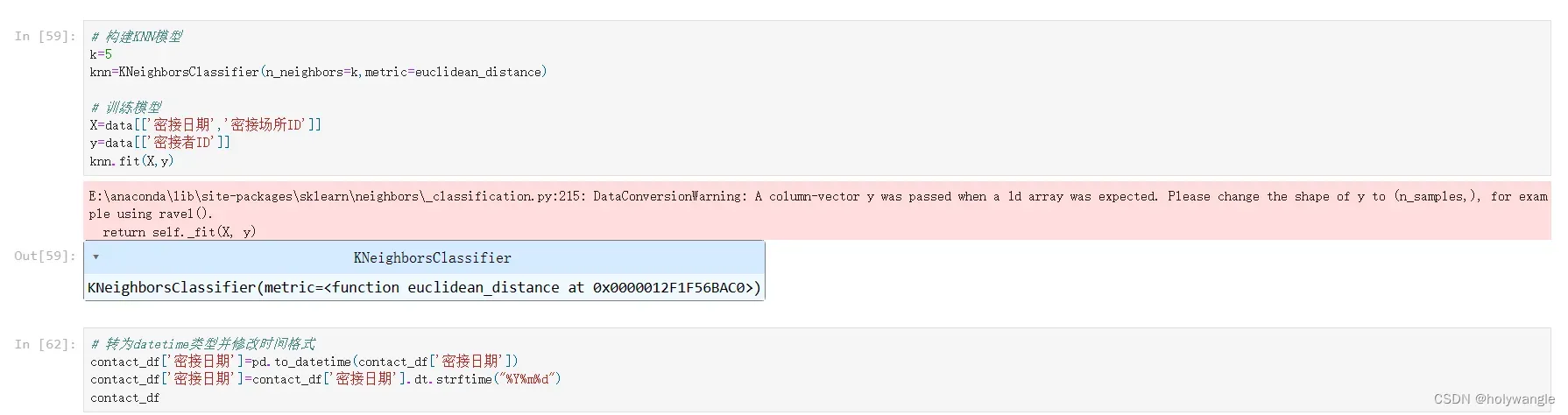
问题三分析:
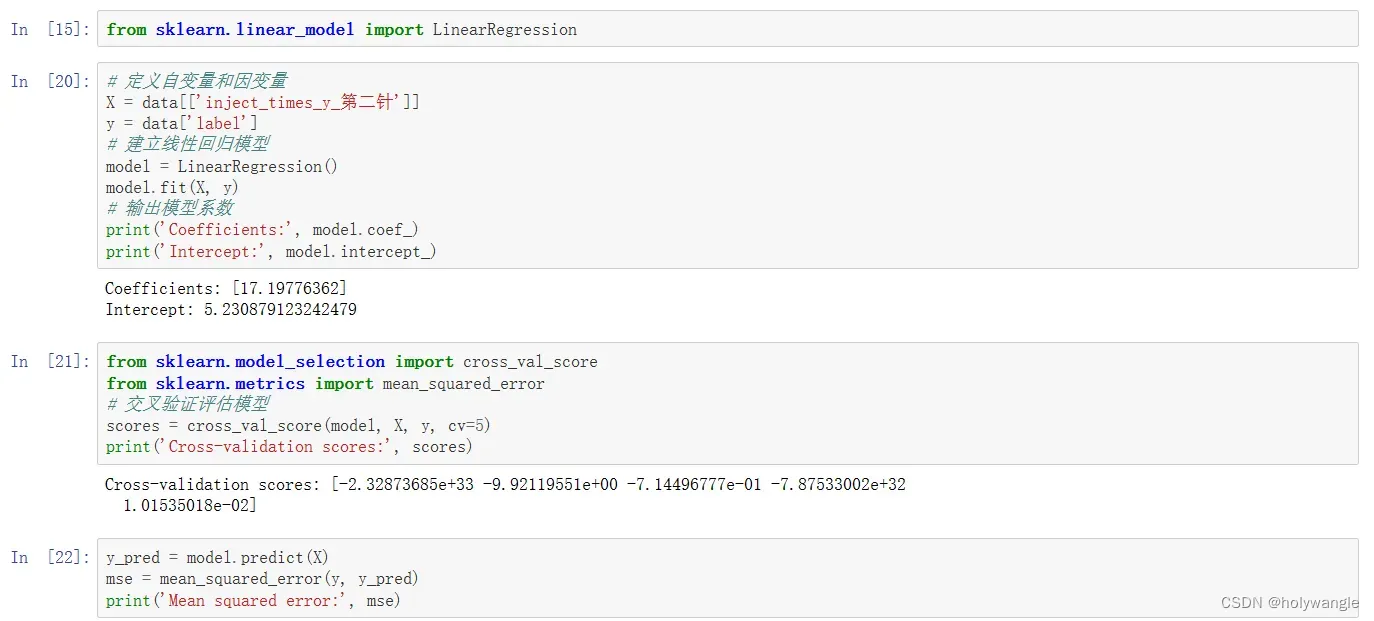
问题内容:建立模型,分析接种疫苗对病毒传播指数的影响。
问题 3 要求建立模型,分析接种疫苗对病毒传播指数的影响。具体来说,需要研究疫苗接种率和病毒传播指数之间的关系,探究疫苗接种对病毒传播的影响。
建模思路:
1. 收集数据:收集疫苗接种率和病毒传播指数的数据,可以使用公开数据集或者实地调查等方法。
2. 数据预处理:对收集到的数据进行预处理,包括数据清洗、缺失值处理、数据标准化等步骤。
3. 建立模型:根据疫苗接种率和病毒传播指数的数据,建立数学模型来研究二者之间的关系。可以使用回归分析、时间序列分析等方法来建立模型。
4. 模型评估:对建立的模型进行评估,检验其预测能力和可靠性。
以上就是一个简单的数学建模思路,建立了疫苗接种率和病毒传播指数之间的线性关系模型,并评估了模型的性能。当然,在实际应用中,可能需要考虑更多的因素,如病毒变异、疫苗有效性等因素,需要建立更加复杂的模型来研究问题。
问题四分析:
问题内容:根据阳性人员的数量及辐射范围,分析确定需要重点管
控的场所。
建模思路:问题 4 要求根据阳性人员的数量及辐射范围,分析确定需要重点管控的场所。具体来说,需要研究阳性人员的分布情况,确定哪些场所可能存在聚集感染的风险,以便重点管控,防止疫情扩散。
数学建模思路:
1. 收集数据:收集阳性人员的分布情况数据,包括阳性人员的数量、位置信息等。
2. 地理信息处理:将收集到的阳性人员信息转换为地理信息,如使用地理信息系统(GIS)进行处理,将阳性人员的位置信息转换为地图上的点。
3. 热力图分析:使用热力图分析方法,对阳性人员分布情况进行可视化分析,找出可能存在聚集感染风险的区域。
4. 聚类分析:对热力图分析结果进行聚类分析,找出可能存在聚集感染风险的场所,确定重点管控区域。
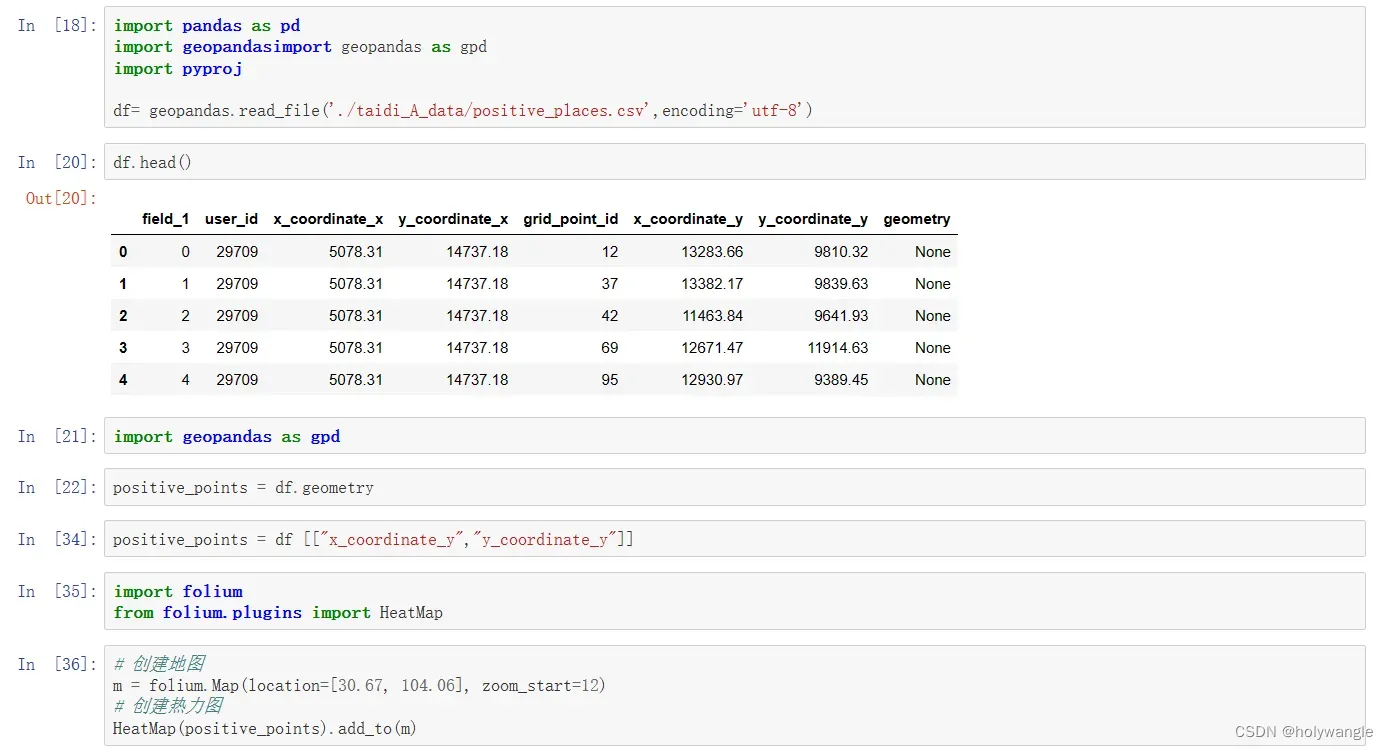
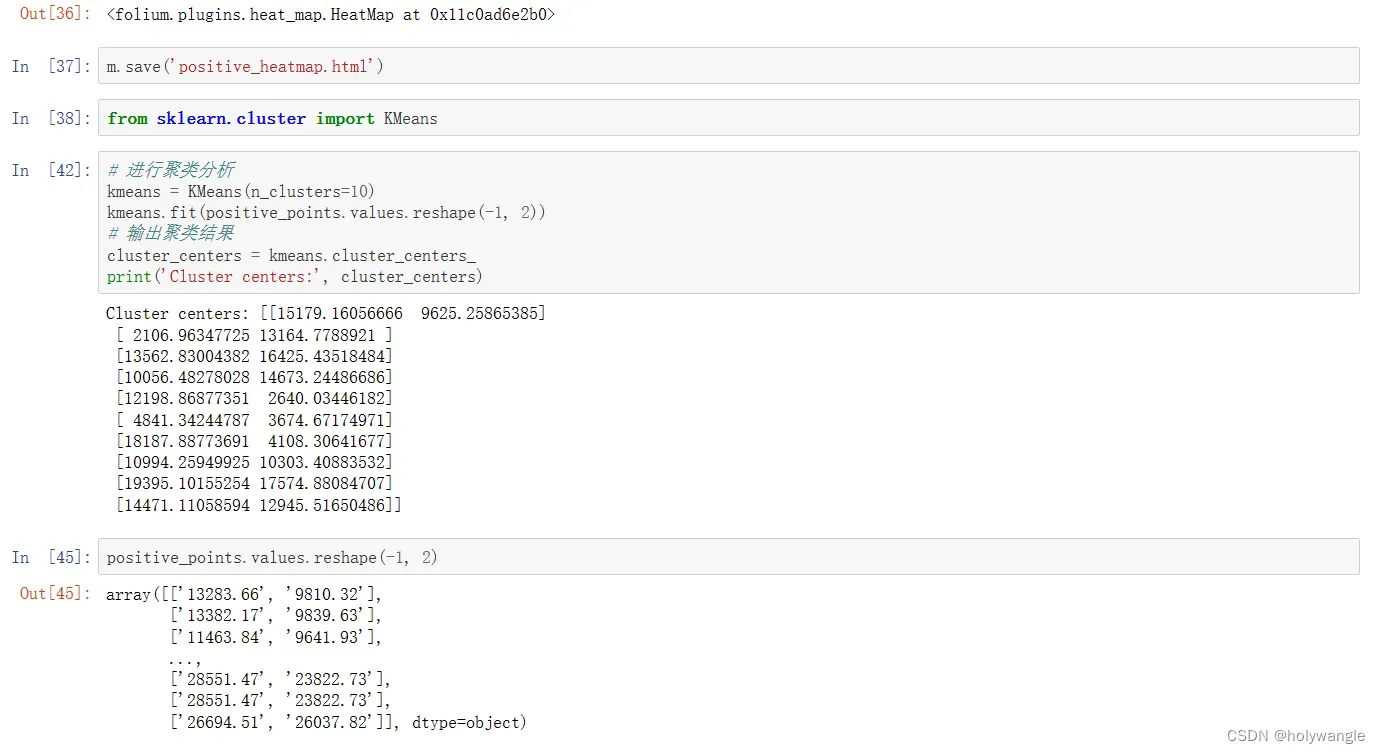
问题五分析:
问题内容:为了更精准地进行疫情防控和人员管理,你认为还需要收集哪些相关数据。基于这些数据构建模型,分析其精准防控的效果。
思路:问题 5 要求针对疫情防控和人员管理,提出需要收集哪些相关数据,并基于这些数据构建模型,分析其精准防控的效果。
建模思路:
1. 收集人员管理和疫情防控相关数据:收集人员管理和疫情防控相关数据,包括但不限于以下方面:
• 人员信息:包括个人基本信息、行程轨迹、接触史等。
• 疫情信息:包括确诊人数、疑似人数、治愈人数、死亡人数等。
• 地理信息:包括人员所在位置、疫情发生地点等。
2. 构建数据模型:将收集到的数据转换为数学模型,例如使用图论、时空分析等方法进行数据建模。
3. 分析精准防控效果:基于数据模型,分析其在疫情防控和人员管理中的精准防控效果,例如预测疫情发展趋势、人员流动趋势等,提供决策参考。
总结:
这个比赛多查资料是真谛。而且论文也是重要参考的,记得要花很多很多很多时间写论文,伙伴们!!!
上面提供的思路也只是给各位参考参考而已,希望大神来指点指点,一起学习。
这个代码格式是ipynb格式的,我这里不可能一条条复制,所以有需要的伙伴们点赞评论收藏之后都可以私聊我要代码资料哦,谢谢!

感谢各位的观看,创作不易,能不能给哥们来一个点赞呢!!!
好了,今天的分享就这么多了,有什么不清楚或者我写错的地方,请多多指教!
私信,评论我呗!!!!!!
关注我下一篇不迷路哦!
文章出处登录后可见!