文章目录
- 0 前言
- 1 课题背景
- 2 数据库依赖
- 导入依赖包
- 3 分析服饰行业笔记数据趋势数据
- 3.1数据一览
- 3.2 可视化分析
- 3.3 可视化分析
- 4. 分析服饰行业内容关键词数据
- 4.1 数据一览
- 4.2 可视化分析
- 5. 分析服饰行业品类数据
- 5.1 数据一览
- 5.2 可视化分析
- 6. 分析服饰行业年龄分布数据
- 6.1 数据一览
- 6.2 可视化分析
- 7. 分析服饰行业粉丝地域分布数据
- 7.1 数据一览
- .2 可视化分析
- 7.3 可视化分析
- 7.4 可视化分析
- 8. 分析服饰行业评论热词数据
- 8.1 数据一览
- 8.2 可视化分析
- 9 最后
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 大数据毕业设计 小红书数据分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:4分
🧿 选题指导, 项目分享:
https://gitee.com/dancheng-senior/project-sharing-1/blob/master/%E6%AF%95%E8%AE%BE%E6%8C%87%E5%AF%BC/README.md
1 课题背景
小红书是一个生活方式平台和消费决策入口,截至2019年7月,小红书用户数已超过3亿;截至到2019年10月,小红书月活跃用户数已经过亿,其中70%新增用户是90后。
在小红书社区,用户通过文字、图片、视频笔记的分享,记录了这个时代年轻人的正能量和美好生活,小红书通过机器学习对海量信息和人进行精准、高效匹配。小红书旗下设有电商业务。
分析角度:
服饰行业趋势
小红书粉丝用户画像
小红书笔记📒热门分析
小红书服装行业营销策略
2 数据库依赖
导入依赖包
import numpy as np
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import *
from pyecharts.components import Table
3 分析服饰行业笔记数据趋势数据
3.1数据一览
# 读取服饰行业笔记数据趋势数据
data_trend = pd.read_excel(r'/服饰行业笔记数据趋势.xlsx')
# 查看数据,据了解数据内容
data_trend.head(5)
# 查看数据信息
data_trend.info()
# 转化日期列数据类型
data_trend['日期'] = data_trend['日期'].astype('str')
# 将当日总数据处理为每篇笔记的平均数据
for i in ['当日点赞数','当日收藏数','当日评论数','当日分享数','当日阅读数']:
data_trend[i.replace('当日', '平均')] = round(data_trend[i]/data_trend['当日笔记篇数'],2)
data_trend.drop(i, axis=1, inplace=True)
# 查看处理后的服饰行业笔记数据趋势数据
data_trend.head(5)
# 聚合各行业近三十日的每日数据
data_trend_by_industry = data_trend.groupby(['行业名称']).agg(
{'当日笔记篇数': lambda x:round(np.mean(x),2),
'平均点赞数': lambda x:round(np.mean(x),2),
'平均收藏数': lambda x:round(np.mean(x),2),
'平均评论数': lambda x:round(np.mean(x),2),
'平均分享数': lambda x:round(np.mean(x),2),
'平均阅读数': lambda x:round(np.mean(x),2),
'平均互动量': lambda x:round(np.mean(x),2),
}).reset_index()
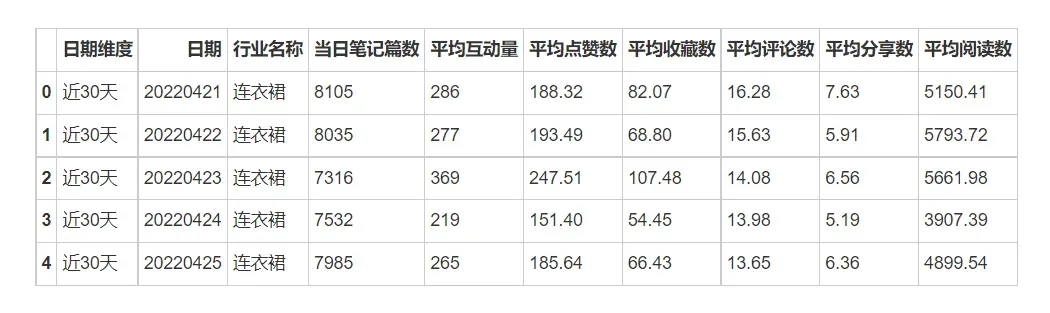
data_trend_by_industry.head(5)
3.2 可视化分析
# 近三十天小红书服饰行业数据-相关系数热力图
data_trend_corr=data_trend.corr()
rows = data_trend_corr.index.size
cols = data_trend_corr.columns.size
# 热力图所需数据
data_trend_corr_heatmap = [[i, j, round(float(data_trend_corr.iloc[i, j]), 3)] for i in range(rows) for j in range(cols)]
heatmap_trend_corr = HeatMap(
init_opts=opts.InitOpts(
width='950px',
)
)
heatmap_trend_corr.add_xaxis(
data_trend_corr.index.tolist(),
)
heatmap_trend_corr.add_yaxis(
'相关系数',
data_trend_corr.columns.tolist(),
data_trend_corr_heatmap,
label_opts=opts.LabelOpts(
is_show=True,
position='inside'),
)
heatmap_trend_corr.set_global_opts(
title_opts=opts.TitleOpts(
title='相关系数热力图',
subtitle='近三十日小红书服饰行业数据',
pos_left='center'),
legend_opts=opts.LegendOpts(
is_show=False,
),
xaxis_opts=opts.AxisOpts(
type_='category',
splitarea_opts=opts.SplitAreaOpts(
is_show=True,
areastyle_opts=opts.AreaStyleOpts(
opacity=1
)
),
axislabel_opts=opts.LabelOpts(
font_size=14,
rotate=-25,
),
interval=0
),
yaxis_opts=opts.AxisOpts(
name='',
type_='category',
splitarea_opts=opts.SplitAreaOpts(
is_show=True,
areastyle_opts=opts.AreaStyleOpts(
opacity=1
)
),
axislabel_opts=opts.LabelOpts(
font_size=14
),
interval=0
),
visualmap_opts=opts.VisualMapOpts(
min_=-1,
max_=1,
is_show=False,
)
)
heatmap_trend_corr.render_notebook()
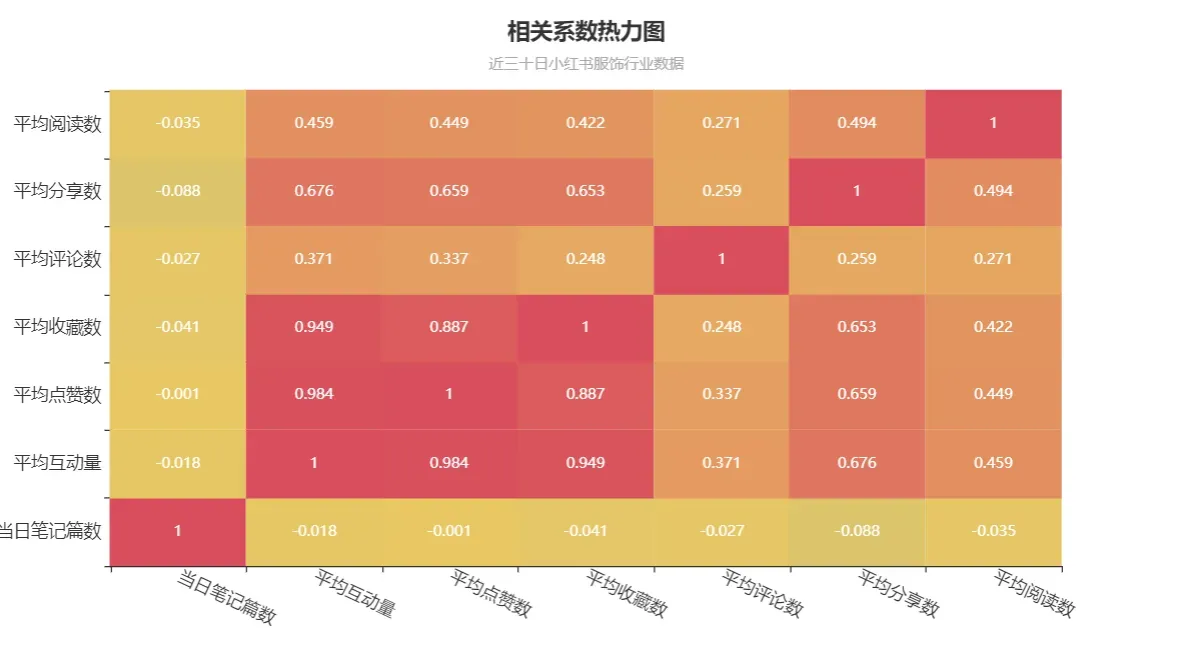
由可视化结果可见服饰行业笔记数据各因素间的相关程度;
当日笔记篇数与其他因素都是没有什么相关性,因为其他因素都是根据单篇笔记得到的互动数据,与总的笔记篇数无关;
平均互动量与平均点赞数和平均收藏数相关性最大,互动量这个值大概率是根据点赞数和/或收藏数计算得到的;
其他因素之间多为(弱)正相关。
3.3 可视化分析
def bar_chart(desc, title_pos):
data_trend_by_industry_top10 = data_trend_by_industry.sort_values(desc, ascending=False).head(10).round(2)
print(desc + 'top10: ' + str(data_trend_by_industry_top10['行业名称'].tolist()))
chart = Bar()
chart.add_xaxis(
data_trend_by_industry_top10['行业名称'].tolist()
)
chart.add_yaxis(
'',
data_trend_by_industry_top10[desc].tolist()
)
chart.set_global_opts(
xaxis_opts=opts.AxisOpts(
is_scale=True,
axislabel_opts={'rotate': '-25'},
splitline_opts=opts.SplitLineOpts(
is_show=True,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
yaxis_opts=opts.AxisOpts(
is_scale=True,
name='',
type_='value',
splitline_opts=opts.SplitLineOpts(
is_show=True,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
title_opts=opts.TitleOpts(
title='服饰行业-' + desc + '-Top10',
subtitle=f'日期范围:20220421~20220520 👇',
pos_left=title_pos[0],
pos_top=title_pos[1],
title_textstyle_opts=opts.TextStyleOpts(
color='#ea517f',
font_family='cursive',
font_size=19)
),
)
return chart
# 新建组合图表Grid
grid = Grid(
init_opts=opts.InitOpts(
theme='light',
width='1300px',
height='1200px')
)
grid.add(
bar_chart('当日笔记篇数', ['5%', '3%']),
is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%', # 指定Grid中子图的位置
pos_bottom='70%',
pos_left='10%',
pos_right='60%'
)
)
grid.add(
bar_chart('平均点赞数', ['55%', '3%']),
is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='10%',
pos_bottom='70%',
pos_left='60%',
pos_right='10%'
)
)
grid.add(
bar_chart('平均收藏数', ['5%', '35%']),
is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='10%',
pos_right='60%'
)
)
grid.add(
bar_chart('平均评论数', ['55%', '35%']),
is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='40%',
pos_bottom='40%',
pos_left='60%',
pos_right='10%'
)
)
grid.add(
bar_chart('平均分享数', ['5%', '65%']),
is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='10%',
pos_right='60%'
)
)
grid.add(
bar_chart('平均阅读数', ['55%', '65%']),
is_control_axis_index=False,
grid_opts=opts.GridOpts(
pos_top='70%',
pos_bottom='10%',
pos_left='60%',
pos_right='10%'
)
)
grid.render_notebook()
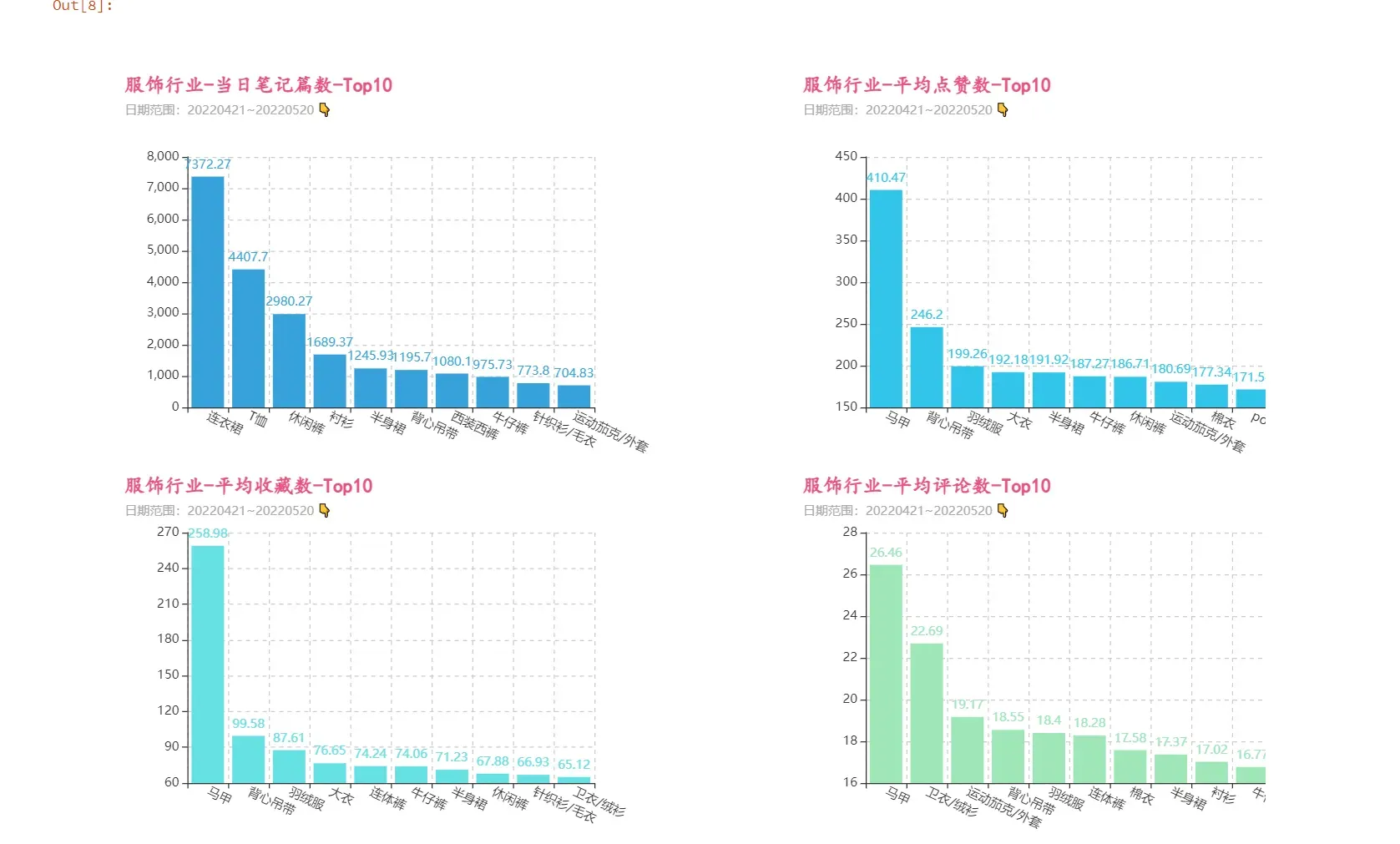
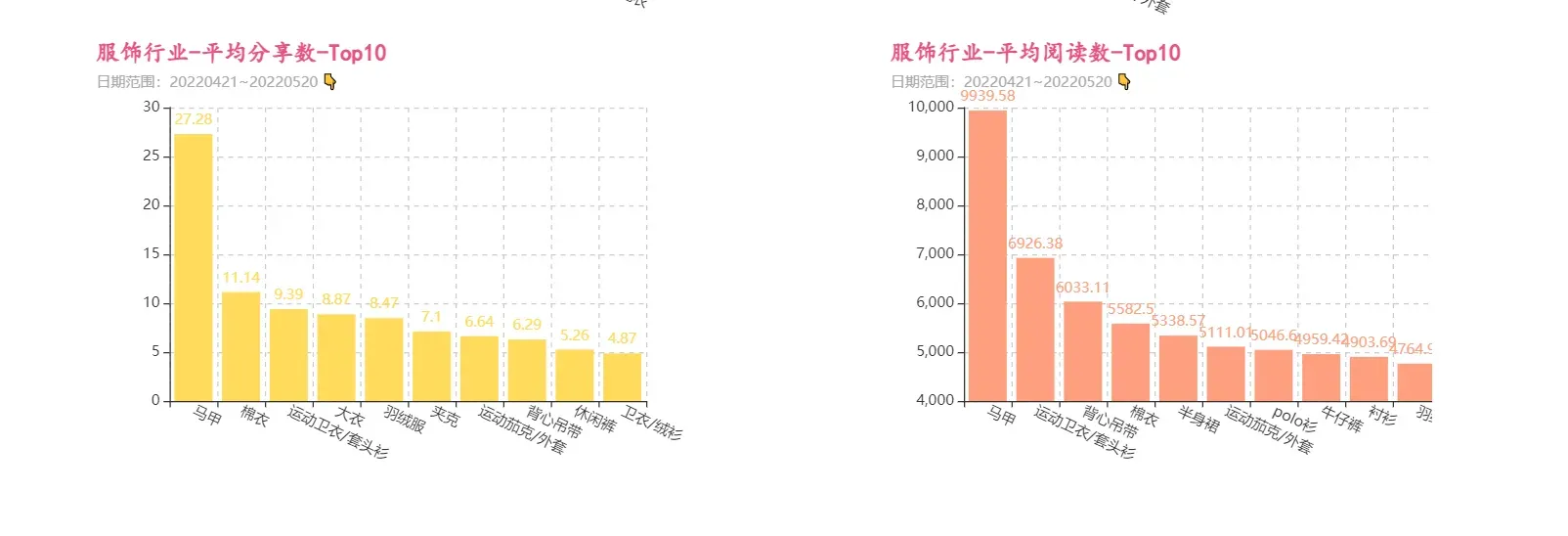
由可视化结果可知,“马甲”行业的笔记质量最高,虽然“马甲”行业的总笔记数前十都排不到,但笔记篇均数据却都一马当先。
4. 分析服饰行业内容关键词数据
4.1 数据一览
data_keyword = pd.read_excel(r'服饰行业内容关键词TOP100.xlsx')
# 查看数据,据了解数据内容
data_keyword.head(5)
# 查看数据信息
data_keyword.info()

# 按内容关键词聚合数据
data_keyword_all = data_keyword.groupby(['内容关键词']).agg(
{
'平均点赞数': 'mean',
'平均收藏数': 'mean',
'平均评论数': 'mean',
'平均分享数': 'mean',
'平均阅读数': 'mean',
'活跃数': 'mean',
}).reset_index()
4.2 可视化分析
tab = Tab()
# 关键词列表
type_list = list(data_keyword_all)[1:]
for i in type_list:
keyword_data = data_keyword_all[['内容关键词', i]].apply(lambda x: tuple(x), axis=1).values.tolist()
word_cloud_keyword = (
WordCloud(init_opts=opts.InitOpts(width='1200px', height='600px', theme='light'))
.add(series_name='评论热词',
data_pair=keyword_data,
word_size_range=[30, 150],
rotate_step=45,
textstyle_opts=opts.TextStyleOpts(font_family='cursive'),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title='以文章'+i.replace('平均','')+'为指标得到的内容关键词热词',
title_textstyle_opts=opts.TextStyleOpts(font_size=20, font_family='cursive'),
pos_left='center',
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
)
tab.add(word_cloud_keyword, i.replace('平均',''))
tab.render_notebook()

由可视化结果可见不同指标下的内容关键词热词;
以点赞、收藏和分享数为指标的情况下,“吊带合集”为最热内容关键词;
以评论数为指标的情况下,“格裙送出计划”为最热内容关键词;
以阅读数为指标的情况下,“明星撞衫”为最热内容关键词。
5. 分析服饰行业品类数据
5.1 数据一览
# 读取数据(服饰行业品类分析-大类占比.xlsx 和 服饰行业品类分析-细分品类占比.xlsx是同一数据)
data_category = pd.read_excel(r'服饰行业品类分析-大类占比.xlsx')
# 查看数据,据了解数据内容
data_category.head(5)
# 查看数据信息
data_category.info()
5.2 可视化分析
data_category = data_category.sort_values(by='笔记篇数', ascending=False)
data_category_bar = (
Bar()
.add_xaxis(data_category['大类'].tolist())
.add_yaxis('笔记篇数', data_category['笔记篇数'].tolist())
.set_global_opts(
title_opts=opts.TitleOpts(title='小红书服饰行业品类笔记数'),
datazoom_opts=opts.DataZoomOpts(is_show=True,range_start=0,range_end=30),
xaxis_opts=opts.AxisOpts(
is_scale=True,
splitline_opts=opts.SplitLineOpts(
is_show=True,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'),
),
axislabel_opts=opts.LabelOpts(
rotate=-25,
interval=0,
),
),
yaxis_opts=opts.AxisOpts(
is_scale=True,
# 网格线配置
splitline_opts=opts.SplitLineOpts(
is_show=True,
linestyle_opts=opts.LineStyleOpts(
type_='dashed'))
),
)
)
data_category_bar.render_notebook()
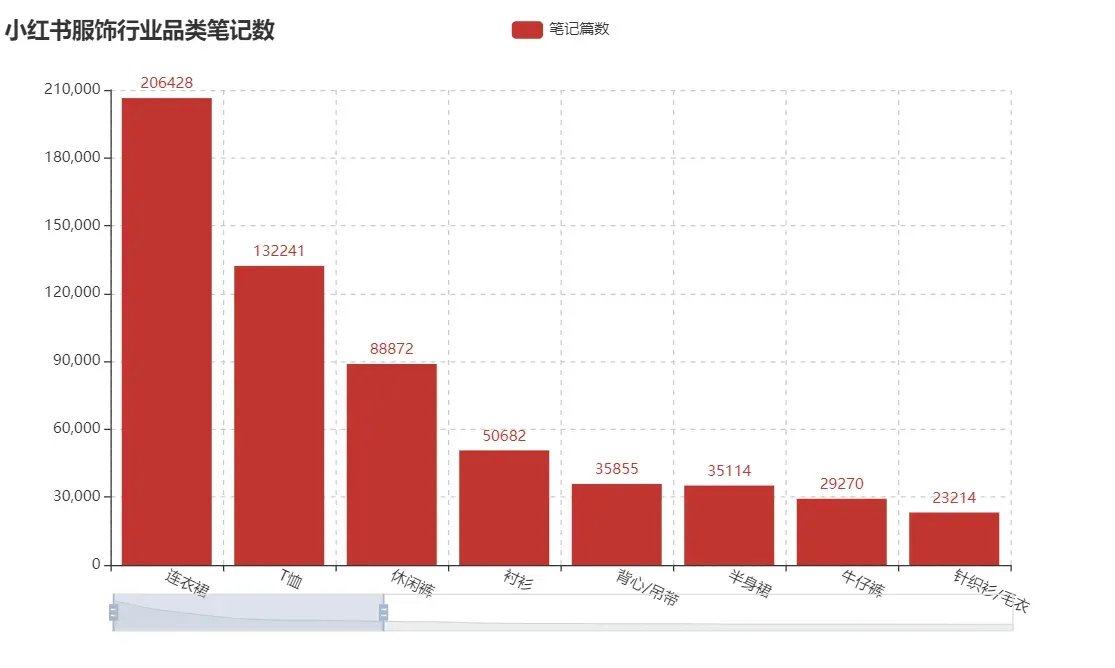
由可视化结果可知“连衣裙”、“T恤”和“休闲裤”为篇数最多的行业文章。
6. 分析服饰行业年龄分布数据
6.1 数据一览
data_age = pd.read_excel(r'服饰行业年龄分布.xlsx')
# 查看数据,据了解数据内容
data_age.head(5)
# 查看数据信息
data_age.info()
industry_list = data_age['行业名称'].unique()
industry_list
6.2 可视化分析
# 新建柱状图
salary_city_bar = Bar(
init_opts=opts.InitOpts(
# 设置图宽
width='1200xp',
# 设置柱状图主题
theme='light',
)
)
# 添加横轴数据
salary_city_bar.add_xaxis(
list(industry_list),
)
salary_city_bar.add_yaxis(
'<18',
list(data_age[data_age['年龄段']=='<18']['占比'].apply(lambda x: round(x*100,2))),
stack='年龄段',
)
salary_city_bar.add_yaxis(
'18-24',
list(data_age[data_age['年龄段']=='18-24']['占比'].apply(lambda x: round(x*100,2))),
stack='年龄段',
)
salary_city_bar.add_yaxis(
'25-34',
list(data_age[data_age['年龄段']=='25-34']['占比'].apply(lambda x: round(x*100,2))),
stack='年龄段',
)
salary_city_bar.add_yaxis(
'35-44',
list(data_age[data_age['年龄段']=='35-44']['占比'].apply(lambda x: round(x*100,2))),
stack='年龄段',
)
salary_city_bar.add_yaxis(
'>44',
list(data_age[data_age['年龄段']=='>44']['占比'].apply(lambda x: round(x*100,2))),
stack='年龄段',
)
salary_city_bar.set_series_opts(
label_opts=opts.LabelOpts(
# 不显示数据项的标签
is_show=False,
),
)
salary_city_bar.set_global_opts(
title_opts=opts.TitleOpts(
# 设置标题
title='小红书各服饰行业用户年龄分布百分比',
# 居中显示
pos_left='center',
),
tooltip_opts=opts.TooltipOpts(
# 数据项图形触发
trigger='item',
# 十字准星指示器
axis_pointer_type='cross',
),
yaxis_opts=opts.AxisOpts(
splitline_opts=opts.SplitLineOpts(
# 显示坐标轴横线
is_show=True,
)
),
xaxis_opts=opts.AxisOpts(
axislabel_opts=opts.LabelOpts(
rotate=-25,
interval=0,
),
),
legend_opts=opts.LegendOpts(
# 把图例放在标题下方
pos_top='5%',
)
)
salary_city_bar.render_notebook()
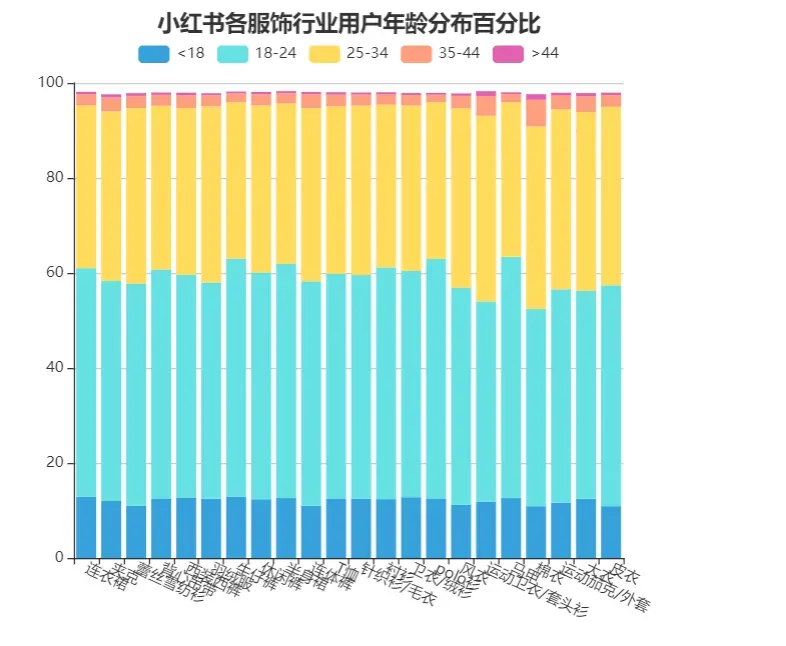
由可视化结果可知小红书服饰行业整体以18-34岁用户群体占比最多,35岁以上用户占比极少。
7. 分析服饰行业粉丝地域分布数据
7.1 数据一览
data_region = pd.read_excel(r'服饰行业粉丝地域分布.xlsx')
# 查看数据,据了解数据内容
data_region.head(5)
# 查看数据信息
data_region.info()
# 计算小红书服装行业的用户地域平均分布
data_region_by_province = data_region.groupby(['省份']).agg({'占比':lambda x:round(np.mean(x),2)}).sort_values(by='占比', ascending=False).reset_index()
data_region_by_province.head(5)
.2 可视化分析
benefitsPie = Pie(
init_opts=opts.InitOpts(
# 设置图例的宽高
width='1200px',
)
)
# 添加数据
benefitsPie.add(
'',
data_region_by_province.values,
# 设计为环形
# radius=["45%", "70%"],
radius=["35%", "60%"],
)
benefitsPie.set_global_opts(
title_opts=opts.TitleOpts(
# 设置标题
title='小红书服装行业的用户地域平均分布',
# 居中显示
pos_left='center',
),
legend_opts=opts.LegendOpts(
# 把图例放在标题下方
pos_top='5%',
),
)
benefitsPie.render_notebook()
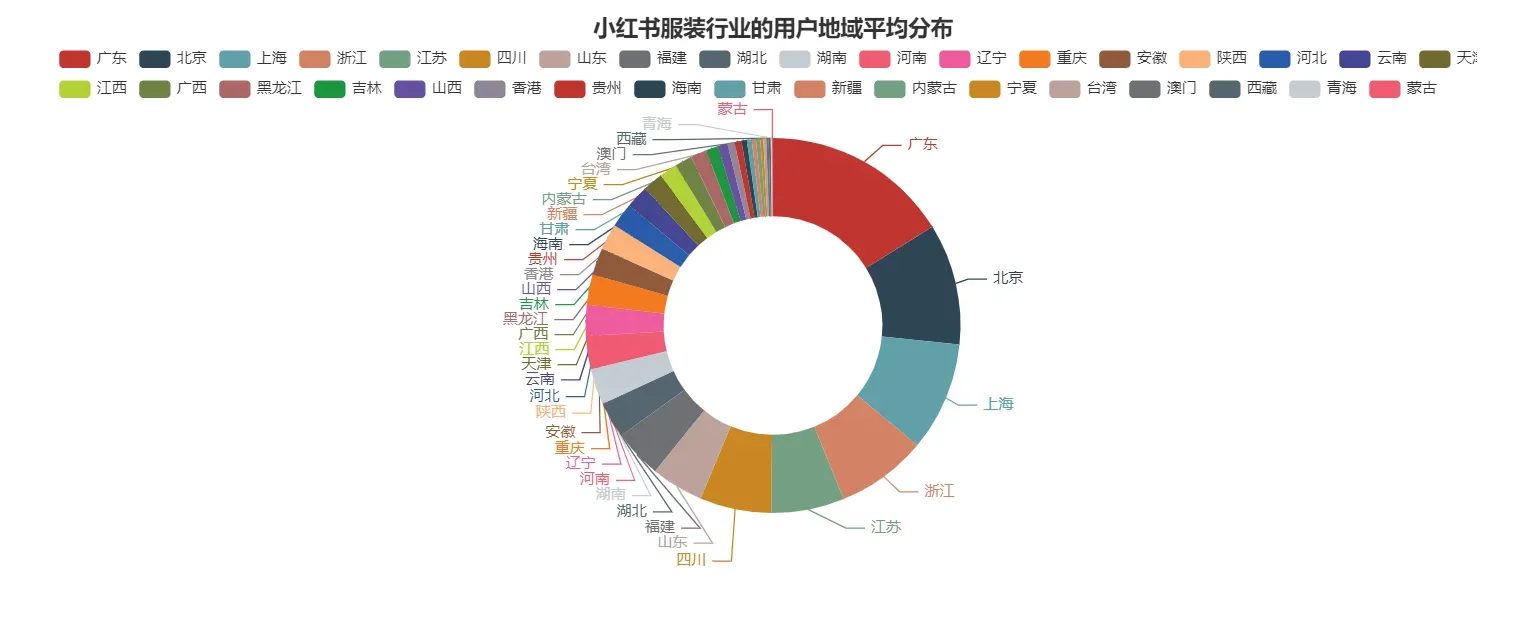
由可视化结果可知小红书服饰行业用户地域分布以广东、北京、上海占比较多。
7.3 可视化分析
map_region_industry_by_province =Map()
map_region_industry_by_province.add("用户占比", data_region_by_province.values, "china",is_map_symbol_show=False)
map_region_industry_by_province.set_global_opts(
title_opts=opts.TitleOpts(title="小红书服饰行业各省用户百分比"),
visualmap_opts=opts.VisualMapOpts(max_=16.5, is_piecewise=True)
)
map_region_industry_by_province.render_notebook()
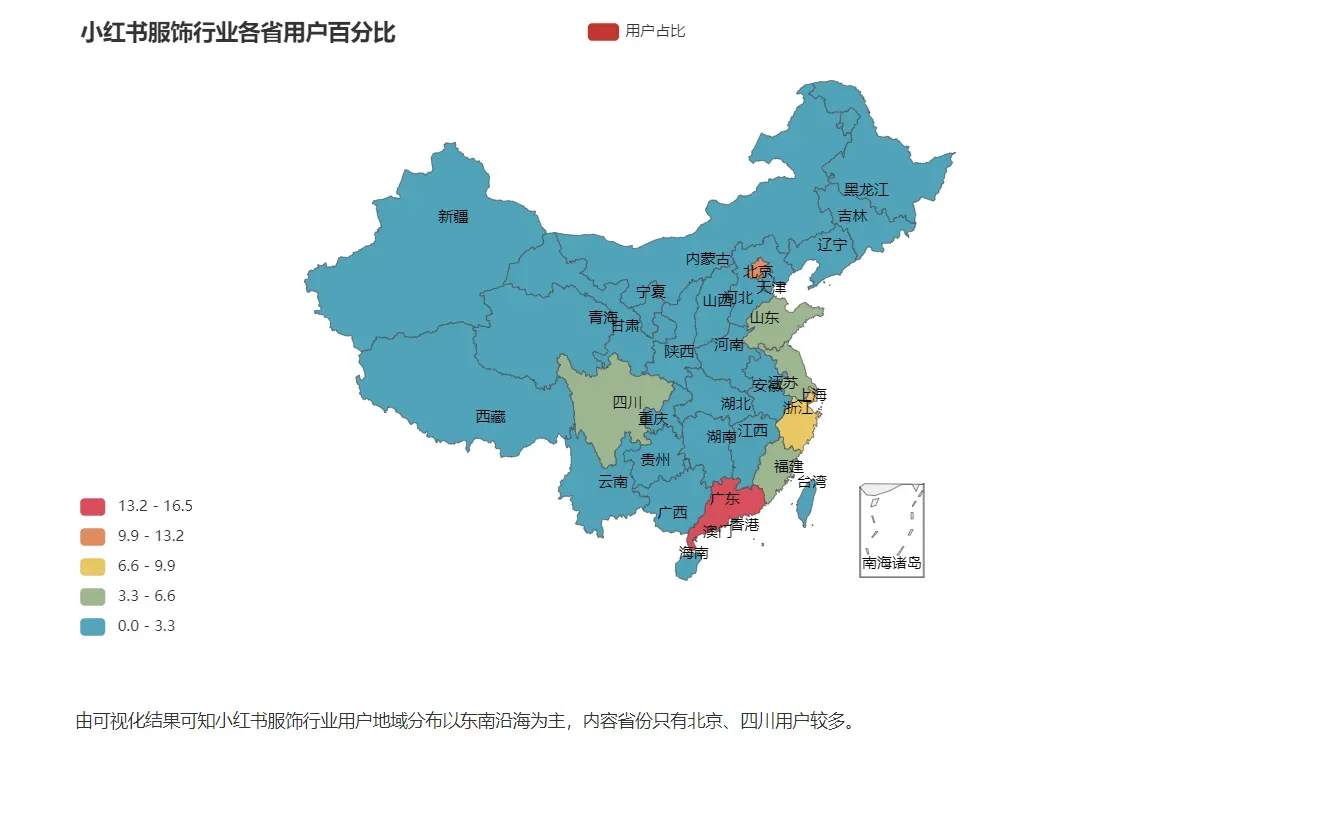
由可视化结果可知小红书服饰行业用户地域分布以东南沿海为主,内容省份只有北京、四川用户较多。
7.4 可视化分析
data_region_industry_by_province = [[i,round(np.mean(data_region[data_region['省份']==i]['占比']),2),data_region['行业名称'][data_region[data_region['省份']==i]['占比'].idxmax()]] for i in data_region['省份'].unique()]
table_region_industry_by_province = Table()
headers = ["省份", "用户百分比", "该省最多人关注的行业"]
table_region_industry_by_province.add(headers, data_region_industry_by_province)
table_region_industry_by_province.set_global_opts(
title_opts=opts.ComponentTitleOpts(title="小红书不同地域用户的分布及主要关注行业")
)
table_region_industry_by_province.render_notebook()
table_region_industry_by_province.render('table_region_industry_by_province.html')
# 不知道为什么不显示Table,可以下载打开HTML文件查看可视化结果
data_region_industry_by_province
8. 分析服饰行业评论热词数据
8.1 数据一览
data_commend = pd.read_excel(r'服饰行业评论热词.xlsx')
# 查看数据,据了解数据内容
data_commend.head(5)
# 查看数据信息
data_commend.info()
# 行业数据
industry_list = data_commend['行业名称'].unique()
industry_list
8.2 可视化分析
tab_commend = Tab()
for i in industry_list:
temp_data = data_commend[data_commend['行业名称']==i].groupby(['comment_word']).agg({'总计': sum, }).reset_index()
keyword_data = temp_data[['comment_word', '总计']].apply(lambda x: tuple(x), axis=1).values.tolist()
word_cloud_keyword = (
WordCloud(init_opts=opts.InitOpts(width='1200px', height='600px', theme='light'))
.add(series_name='评论热词',
data_pair=keyword_data,
word_size_range=[30, 150],
rotate_step=45,
textstyle_opts=opts.TextStyleOpts(font_family='cursive'),
)
.set_global_opts(
title_opts=opts.TitleOpts(
title=i+'行业评论热词',
title_textstyle_opts=opts.TextStyleOpts(font_size=25, font_family='cursive'),
pos_left='center',
),
tooltip_opts=opts.TooltipOpts(is_show=True),
)
)
tab_commend.add(word_cloud_keyword, i)
tab_commend.render_notebook()

由可视化结果可见不同行业下的文章评论热词。
9 最后
文章出处登录后可见!