问题描述
- 读取给定的语料库,根据制表符’\t’划分其文本与标签,将获得的文本仅保留汉字部分,并按字划分,保存在列表中,至少使用一种方法,统计所有汉字的出现次数,并按照从高到低的顺序排序;至少使用一种方法,统计所有字频,按照从高到低的顺序排序;至少使用一种方法,计算累计频率,按照从高到低的顺序排序
- 读取给定的语料库,根据制表符’\t’划分其文本与标签,将获得的语料使用jieba分词工具进行分词并保存至列表中,使用停用词表过滤停用词,保留非停用词, 至少使用一种方法,统计所有汉字词的出现次数,并按照从高到低的顺序排序;至少使用一种方法,统计所有词频,按照从高到低的顺序排序;至少使用一种方法,计算累计频率,按照从高到低的顺序排序
对给定的语料库对其进行字频和词频统计
文章目录
- 问题描述
- 字频统计
- 处理步骤与思路
- 结果展示
- 词频统计
- 处理步骤与思路:
- 结果展示
字频统计
处理步骤与思路
1、这个实验所用到的数据是按行保存的数据,所以可以使用python中的readline函数进行读取文件,这样得到的每一行数据就是对应的一条新闻,这些新闻又是以制表符/t来分割的,所以制表符前面的内容当作标题,制表符后面的符号当做内容,将这两部分内容放到列表中,所以这里使用到python的split函数进行分割得到对应新闻的标签和内容
2、将文本内容只保留汉字部分,去除标点符号以及空格,在这里我使用到的是python中的正则表达式,对文本中出现的各种标点符号比如中英文下的逗号、句号、感叹号等一系列标点符号进行去除,同时使用到\d和\s分别匹配数字和空格,使用正则表达式re的sub函数进行去除这些相应的符号。将文本处理好之后再使用list函数,将处理好的字符串合并成列表,完成实验要求。
file = open(file='data.txt', mode='r', encoding='utf-8')
lines = file.readlines()
lables = [] # 保存每条新闻的标签
contents = [] # 保存每条新闻的内容
i = 0
words = [] # 用来保存所有的汉字
strs = '' # 用于保存保留下的所有汉字
# 将文本文件中的内容进行分割,制表符前面的内容当作标题,制表符后面的符号当做内容,将这两部分内容放到列表中
for line in lines: # 我分析文本内容得知,每条新闻是按行存放的,所以使用python的读取行的函数就可以分离出每条新闻
lable = line.split('\t')[0]
lables.append(lable)
content = line.split('\t')[1]
contents.append(content)
# 将文本内容只保留汉字部分,去除标点符号以及空格
content = re.sub(r'\d', "", content)
content = re.sub(r'\s', "", content)
content = re.sub(pattern='[,,\-<>'《》・|~()>&\*-+"%{}=-、。.—!!??"::;;\/\.【】()\']', repl='', string=content)
strs = strs + content
# print(content)
words.extend(list(content))
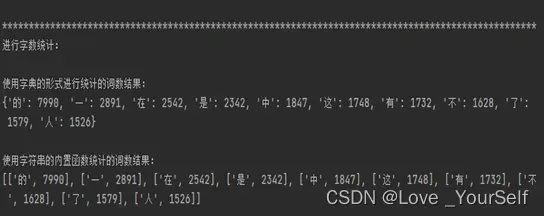
3、然后是统计所有汉字的出现次数,并按照从高到低的顺序排序,这里我使用到了两种方法,分别使用字典的方式以及字符串自带的内置函数完成每个词出现的次数。字典方式的实现是遍历之前获得的关于语句中每个词的列表,创建一个字典,键是汉字,值是对应出现的次数,然后当前遍历的字如果出现在字典中就修改当前键对应的值,如果没出现在字典中就要将其放到字典中。使用字符串的方式时使用到的函数是count函数,这个可以直接统计字符串中某一个汉字出现的次数。然后将统计好的次数按降序排列,使用到的函数为sorted函数,然后在参数选择的时候将reverse设置为True,然后就可以实现按降序排列了。
# 统计每一个汉字的出现次数,使用字典的形式进行统计
result = {}
for word in words:
res = result.get(word, 0)
if res == 0:
result[word] = 1
else:
result[word] = result[word] + 1
result = sorted(result.items(), key=lambda kv:(kv[1], kv[0]), reverse=True)
result = dict(result)
print("使用字典的形式进行统计的词数结果:")
new_a = {}
for i, (k, v) in enumerate(result.items()):
new_a[k] = v
if i == 9:
print(new_a)
break
new_a.clear()
# 统计每一个汉字的出现次数,使用字符串的内置函数
# print(strs)
result2 = []
# print('使用字符串的内置函数统计的所有的汉字数为:', end=" ")
# print(len(strs))
for w in set(strs):
num = strs.count(w)
tem = [w, num]
result2.append(tem)
result2 = sorted(result2, key=lambda x:x[1], reverse=True)
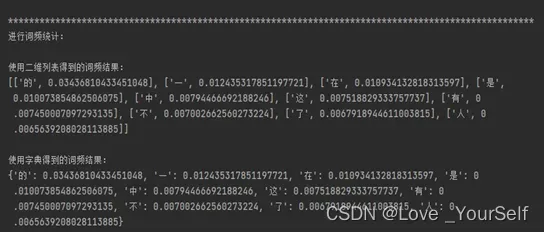
4、然后统计所有字频,也就是使用每个单词出现的频数除以所有汉字出现的频数可以得到每个汉字出现的字频,这里我也用了两张方法,一种使用的是上一问得到的排序好的汉字,得到一个N行2列的二维列表,每一行的第一列是汉字,第二列是这个汉字出现的次数,然后对这个二维列表进行操作,让第二列除以所有汉字出现的次数,就可以得到每个汉字出现的频率了。第二种方式是使用之前得到的字典,对字典的值进行修改,让每一个字典项的值除以所有汉字的次数即可。
# 统计词频,使用上一步得到二维列表
fre = []
for item in result2:
item[1] = item[1] / len(words)
fre.append(item)
print('使用二维列表得到的字频结果:')
print(fre[:10])
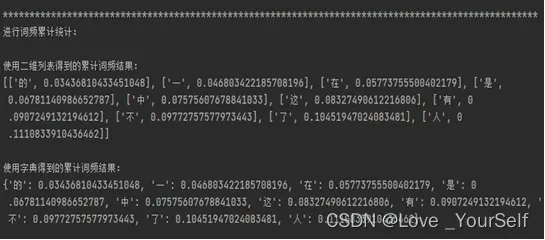
5、然后统计每个汉字的累计频率,也就是使用每个单词出现的频率加上之前的汉字的频率可以得到每个汉字出现的累计频率,这里我也用了两张方法,一种使用的是上一问得到的排序好的汉字的字频列表,这是一个N行2列的二维列表,每一行的第一列是汉字,第二列是这个汉字出现的频率,然后对这个二维列表进行操作,让第二列加上之前汉字的频率,就可以得到每个汉字出现的累计频率了。第二种方式是使用之前得到的字典,对字典的值进行修改,让每一个字典项的值加上之前汉字的频率即可。
# 统计词频累计,使用上一问得到二维列表
cum = []
sum = 0
for item in fre:
sum = sum + item[1]
item[1] = sum
cum.append(item)
print('使用二维列表得到的累计字频结果:')
print(cum[:10])
结果展示
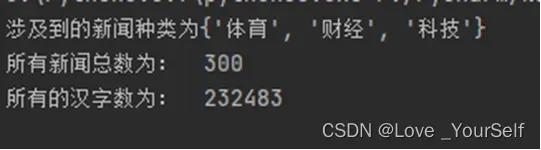
首先是新闻类别的截图
截取处理之后的汉字截图

对字数统计的截图
对字频统计的截图:
对词频累计统计的截图
词频统计
处理步骤与思路:
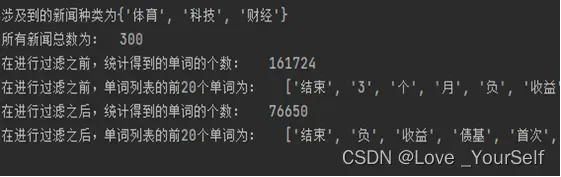
1、这个实验所用到的数据是按行保存的数据,所以可以使用python中的readline函数进行读取文件,这样得到的每一行数据就是对应的一条新闻,这些新闻又是以制表符/t来分割的,所以制表符前面的内容当作标题,制表符后面的符号当做内容,将这两部分内容放到列表中,所以这里使用到python的split函数进行分割得到对应新闻的标签和内容,最后得到的新闻的种类为3种,分别为科技, 财经和体育类的新闻,所涉及到共计新闻的总数为300条,这里使用列表的形式进行保存
file = open(file='data.txt', mode='r', encoding='utf-8')
lines = file.readlines()
lables = [] # 保存每条新闻的标签
contents = [] # 保存每条新闻的内容
for line in lines: # 分析文本内容得知,每条新闻是按行存放的,所以使用python的读取行的函数就可以分离出每条新闻
lable = line.split('\t')[0]
lables.append(lable)
content = line.split('\t')[1]
contents.append(content)
2使用jieba分词,jieba有三种不同的分词模式:精确模式、全模式和搜索引擎模式,精确模式是最常用的分词方法,全模式会将句子中所有可能的词都列举出来,搜索引擎模式则适用于搜索引擎使用。在这里不对新闻的内容进行处理直接进行分词,然后对分完之后的词也不做任何的处理得到的单词的列表是单纯进行分词之后的结果,这里的结果包含很多的没有用的信息,包括一些字符和一些空格或者是没有实际意义的词,这里得到的单词数为161724
words = []
for sentence in contents:
# 使用jieba进行分词,使用精确模式
devision_words = jieba.cut(sentence, cut_all=False)
# 将分词后的结果转化为列表,然后添加到分词列表中
words.extend(list(devision_words))
3、然后根据上一问得到的单词列表进行相应的处理,这里使用的是停用词表进行判断,如果分词之后得到的单词列表的单词在停用词表中,那么就会将这个单词进行去除,另外我还加了一些处理,将一些数字、字母和空格的字符进行了去除,如果是这种单词那么也将不会添加到最终的单词列表中,最后经过停用词表进行相应的过滤之后得到的单词的数目为76650
stop_path = r"stopwords.txt" # 停用词表的位置
stop_list = []
no_stop_words = []
for line in open(stop_path, 'r', encoding='utf-8').readlines():
stop_list.append(line.strip())
for word in words: # 使用分词后的结果然后用空格进行分割,得到每个分词
if word not in stop_list: # 如果这个分词不在停用词表中并且不是换行或者制表符就将其加入到最后的字符串中,然后加一个空格
word = re.sub(r'\d', "", word) # 去除单词中的数字
word = re.sub(r'\s', "", word) # 去除单词中的空格
word = re.sub(r'\W', "", word) # 去除单词中的字母
if word:
no_stop_words.append(word)
4、然后是统计所有单词的出现次数,并按照从高到低的顺序排序,这里我使用到了两种方法,分别使用字典的方式以及列表自带的内置函数完成每个单词出现的次数。字典方式的实现是遍历之前获得的关于语句中每个词的列表,创建一个字典,键是单词,值是对应出现的次数,然后当前遍历的单词如果出现在字典中就修改当前键对应的值,如果没出现在字典中就要将其放到字典中。使用列表的方式时使用到的函数是count函数,这个可以直接统计列表中某一个单词出现的次数。然后将统计好的次数按降序排列,使用到的函数为sorted函数,然后在参数选择的时候将reverse设置为True,然后就可以实现按降序排列了。
# 统计每一个单词的出现次数,使用字典的形式进行统计
result = {}
for word in no_stop_words:
res = result.get(word, 0)
if res == 0:
result[word] = 1
else:
result[word] = result[word] + 1
result = sorted(result.items(), key=lambda kv:(kv[1], kv[0]), reverse=True)
result = dict(result)
print("使用字典的形式进行统计的词数结果:")
new_a = {}
for i, (k, v) in enumerate(result.items()):
new_a[k] = v
if i == 9:
print(new_a)
break
new_a.clear()
5、然后统计所有单词出现的频率,也就是使用每个单词出现的频数除以所有单词出现的频数可以得到每个单词出现的词频,这里我也用了两张方法,一种使用的是上一问得到的排序好的单词,得到一个N行2列的二维列表,每一行的第一列是单词,第二列是这个单词出现的次数,然后对这个二维列表进行操作,让第二列除以所有单词出现的次数,就可以得到每个单词出现的频率了。第二种方式是使用之前得到的字典,对字典的值进行修改,让每一个字典项的值除以所有单词的次数即可。
# 统计词频,使用上一问得到的字典
cum2 = {}
sum = 0
new_a.clear()
for i, (k, v) in enumerate(fre2.items()):
sum = sum + v
new_a[k] = sum
cum2 = new_a.copy()
6、然后统计每个单词的累计频率,也就是使用每个单词出现的频率加上之前的单词的频率可以得到每个单词出现的累计频率,这里我也用了两张方法,一种使用的是上一问得到的排序好的单词的字频列表,这是一个N行2列的二维列表,每一行的第一列是单词,第二列是这个单词出现的频率,然后对这个二维列表进行操作,让第二列加上之前单词的频率,就可以得到每个单词出现的累计频率了。第二种方式是使用之前得到的字典,对字典的值进行修改,让每一个字典项的值加上之前单词的频率即可。
# 使用字典得到的累计词频结果:
for i, (k, v) in enumerate(cum2.items()):
new_a[k] = v
if i == 9:
print(new_a)
break
结果展示
这里是统计的新闻的结果,共涉及3类新闻,共计300条。
然后显示分词之后在没有进行停用词的过滤前后的对比结果
然后进行词数统计的结果

进行词频统计的结果

进行词频累计统计的结果

文章出处登录后可见!