这里介绍了Pytorch中已经训练好的模型如何使用
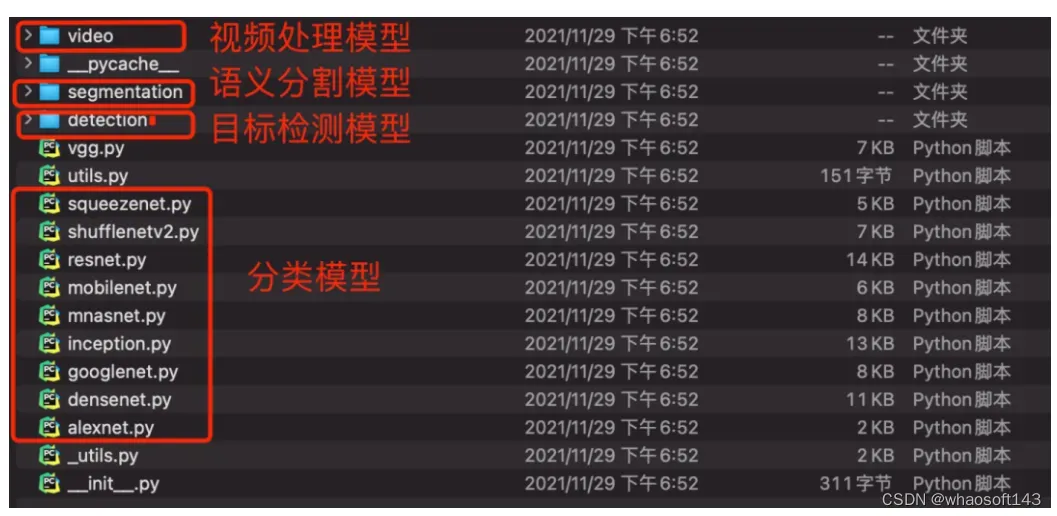
Pytorch中提供了很多已经在ImageNet数据集上训练好的模型了,可以直接被加载到模型中进行预测任务。预训练模型存放在Pytorch的torchvision中库,在torchvision库的models模块下可以查看内置的模型,models模块中的模型包含四大类,如图所示:
01 图像分类代码实现
# coding: utf-8
from PIL import Image
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 步骤一(替换sans-serif字体)
plt.rcParams['axes.unicode_minus'] = False # 步骤二(解决坐标轴负数的负号显示问题)
import json
import numpy as np
import torch
import torch.nn.functional as F
from torchvision import models, transforms
# 1.下载并加载预训练模型
model = models.resnet18(pretrained=True)
model = model.eval()
# 2.加载标签并对输入数据进行处理
labels_path = './imagenet_class_index.json'
with open(labels_path) as json_data:
idx2labels = json.load(json_data)
# print(idx2labels)
def getone(onestr):
return onestr.replace(',', ' ')
# 加载中文标签
with open('./zh_label.csv', 'r+', encoding='gbk') as f:
# print(f)
# print(map(getone, list(f)))
zh_labels = list(map(getone, list(f)))
print(len(zh_labels), type(zh_labels), zh_labels[:5])
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
# 3.使用模型进行预测
def preimg(img):
if img.mode == 'RGBA':
ch = 4
a = np.asarray(img)[:, :, :3]
img = Image.fromarray(a)
return img
im = preimg(Image.open('panda.jpg'))
transformed_img = transform(im)
inputimg = transformed_img.unsqueeze(0)
output = model(inputimg)
output = F.softmax(output, dim=1)
prediction_score, pred_label_idx = torch.topk(output, 3)
prediction_score = prediction_score.detach().numpy()[0]
print(prediction_score[0])
pred_label_idx = pred_label_idx.detach().numpy()[0]
print(pred_label_idx)
predicted_label = idx2labels[str(pred_label_idx[0])][1]
print(predicted_label)
predicted_label_zh = zh_labels[pred_label_idx[0] + 1]
print(predicted_label_zh)
# 4.预测结果可视化
fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(10, 8))
fig.sca(ax1)
ax1.imshow(im)
plt.xticks([])
plt.yticks([])
barlist = ax2.bar(range(3), [i for i in prediction_score])
barlist[0].set_color('g')
plt.sca(ax2)
plt.ylim([0, 1.1])
plt.xticks(range(3),
# [idx2labels[str(i)][1] for i in pred_label_idx],
[zh_labels[pred_label_idx[i] + 1] for i in range(3)],
rotation='45')
fig.subplots_adjust(bottom=0.2)
plt.show()
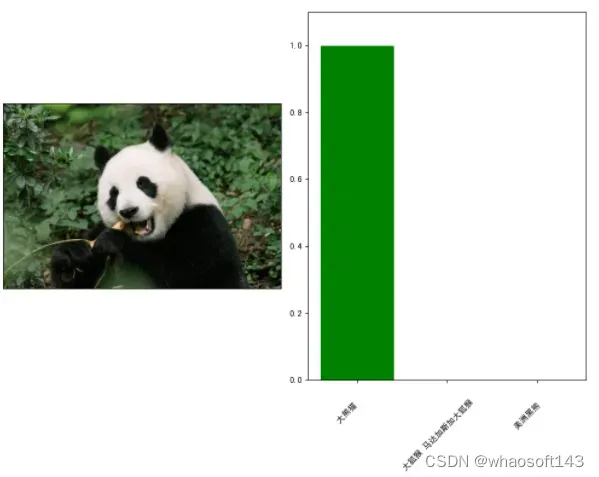
图像分类结果图
输入一张熊猫图片,右边输出模型的预测结果,如上图所示。
02 目标检测代码实现
from PIL import Image
import matplotlib.pyplot as plt
import torch
import torchvision.transforms as T
import torchvision
import torch
import numpy as np
import cv2
import random
# 加载maskrcnn模型进行目标检测
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
model.eval()
COCO_INSTANCE_CATEGORY_NAMES = [
'__background__', 'person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus',
'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'N/A', 'stop sign',
'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow',
'elephant', 'bear', 'zebra', 'giraffe', 'N/A', 'backpack', 'umbrella', 'N/A', 'N/A',
'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball',
'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket',
'bottle', 'N/A', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl',
'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza',
'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'N/A', 'dining table',
'N/A', 'N/A', 'toilet', 'N/A', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone',
'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'N/A', 'book',
'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush'
]
def get_prediction(img_path, threshold):
img = Image.open(img_path)
transform = T.Compose([T.ToTensor()])
img = transform(img)
pred = model([img])
print('pred')
print(pred)
pred_score = list(pred[0]['scores'].detach().numpy())
pred_t = [pred_score.index(x) for x in pred_score if x > threshold][-1]
print("masks>0.5")
print(pred[0]['masks'] > 0.5)
masks = (pred[0]['masks'] > 0.5).squeeze().detach().cpu().numpy()
print("this is masks")
print(masks)
pred_class = [COCO_INSTANCE_CATEGORY_NAMES[i] for i in list(pred[0]['labels'].numpy())]
pred_boxes = [[(i[0], i[1]), (i[2], i[3])] for i in list(pred[0]['boxes'].detach().numpy())]
masks = masks[:pred_t + 1]
pred_boxes = pred_boxes[:pred_t + 1]
pred_class = pred_class[:pred_t + 1]
return masks, pred_boxes, pred_class
def random_colour_masks(image):
colours = [[0, 255, 0], [0, 0, 255], [255, 0, 0], [0, 255, 255], [255, 255, 0], [255, 0, 255], [80, 70, 180],
[250, 80, 190], [245, 145, 50], [70, 150, 250], [50, 190, 190]]
r = np.zeros_like(image).astype(np.uint8)
g = np.zeros_like(image).astype(np.uint8)
b = np.zeros_like(image).astype(np.uint8)
r[image == 1], g[image == 1], b[image == 1] = colours[random.randrange(0, 10)]
coloured_mask = np.stack([r, g, b], axis=2)
return coloured_mask
def instance_segmentation_api(img_path, threshold=0.5, rect_th=3, text_size=10, text_th=3):
masks, boxes, pred_cls = get_prediction(img_path, threshold)
img = cv2.imread(img_path)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
for i in range(len(masks)):
rgb_mask, randcol = random_colour_masks(masks[i]), (random.randint(0, 255), random.randint(0, 255), random.randint(0, 255))
img = cv2.addWeighted(img, 1, rgb_mask, 0.5, 0)
cv2.rectangle(img, boxes[i][0], boxes[i][1], color=randcol, thickness=rect_th)
cv2.putText(img, pred_cls[i], boxes[i][0], cv2.FONT_HERSHEY_SIMPLEX, text_size, randcol, thickness=text_th)
plt.figure(figsize=(20, 30))
plt.imshow(img)
plt.xticks([])
plt.yticks([])
plt.show()
instance_segmentation_api('./horse.jpg')


03 语义分割代码实现
import torch
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from torchvision import models
from torchvision import transforms
# 加载deeplabv3模型进行语义分割
model = models.segmentation.deeplabv3_resnet101(pretrained=True)
model = model.eval()
transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
def preimg(img):
if img.mode == 'RGBA':
ch = 4
a = np.asarray(img)[:, :, :3]
img = Image.fromarray(a)
return img
img = Image.open('./horse.jpg')
plt.imshow(img)
plt.axis('off')
plt.show()
im = preimg(img)
inputimg = transform(im).unsqueeze(0)
tt = np.transpose(inputimg.detach().numpy()[0], (1, 2, 0))
plt.imshow(tt)
plt.axis('off')
plt.show()
output = model(inputimg)
print(output['out'].shape)
output = torch.argmax(output['out'].squeeze(),
dim=0).detach().cpu().numpy()
resultclass = set(list(output.flat))
print(resultclass)
def decode_segmap(image, nc=21):
label_colors = np.array(
[(0, 0, 0), (128, 0, 0), (0, 128, 0), (128, 128, 0),
(0, 0, 128), (128, 0, 128), (0, 128, 128), (128, 128, 128),
(64, 0, 0), (192, 0, 0), (64, 128, 0), (192, 128, 0),
(64, 0, 128), (192, 0, 128), (64, 128, 128), (192, 128, 128),
(0, 64, 0), (128, 64, 0), (0, 192, 0), (128, 192, 0), (0, 64, 128)]
)
r = np.zeros_like(image).astype(np.uint8)
g = np.zeros_like(image).astype(np.uint8)
b = np.zeros_like(image).astype(np.uint8)
for l in range(0, nc):
idx = image == l
r[idx] = label_colors[l, 0]
g[idx] = label_colors[l, 1]
b[idx] = label_colors[l, 2]
return np.stack([r, g, b], axis=2)
rgb = decode_segmap(output)
print(rgb)
img = Image.fromarray(rgb)
plt.axis('off')
plt.imshow(img)
plt.show()

模型从图中识别出了两个类别的内容,索引值分别为13、15,所对应的分类名称是马和人。调用函数,通过对预测结果进行染色,得到的预测结果如上图所示。
whaosoft aiot http://143ai.com
文章出处登录后可见!
已经登录?立即刷新