目录
一、sklearn库简介
Scikit-learn(简称sklearn)是一个用于机器学习的Python库,它包含了许多常用的机器学习算法、预处理技术、模型选择和评估工具等,可以方便地进行数据挖掘和数据分析。 Scikit-learn建立在NumPy、SciPy和Matplotlib之上。
二、sklearn库安装
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple/
比如我们要安装 sklearn 1.1.1版本,那么:
pip install scikit-learn==1.1.1 -i https://pypi.tuna.tsinghua.edu.cn/simple
注意:我们在sklearn库的学习和练习过程中,所需的 sklearn 版本不一定要最新 or 最好的,因为里面可能会有一些东西在新版本被移除了,比如:load_boston(波士顿房价数据)在最新版已被移除,因此建议安装 sklearn 1.1.1版本
三、关于机器学习
在认识sklearn库前,我们要知道机器学习一般分为四个基本的步骤:
① 数据的收集和准备 → 包括数据的清洗、变换、归一化和特征提取等操作;
② 模型选择和训练 → 选择一个合适的机器学习模型,并使用收集的数据对其进行训练(什么问题选择什么模型);
③ 模型评估 → 训练完成后对模型在新数据上的表现进行评估;
④ 模型部署和优化 → 将模型部署到实际环境中,并对其进行优化,包括压缩、加速、调参;
在这四个步骤中,最宝贵的是数据的收集和准备(一批好的数据蛮贵的)。当然,在解决机器学习问题中最困难的是② 模型的选择,不同的模型更适合不同类型的数据和不同的问题。
具体可以看下表:(源自官网Choosing the right estimator — scikit-learn 1.2.2 documentation)
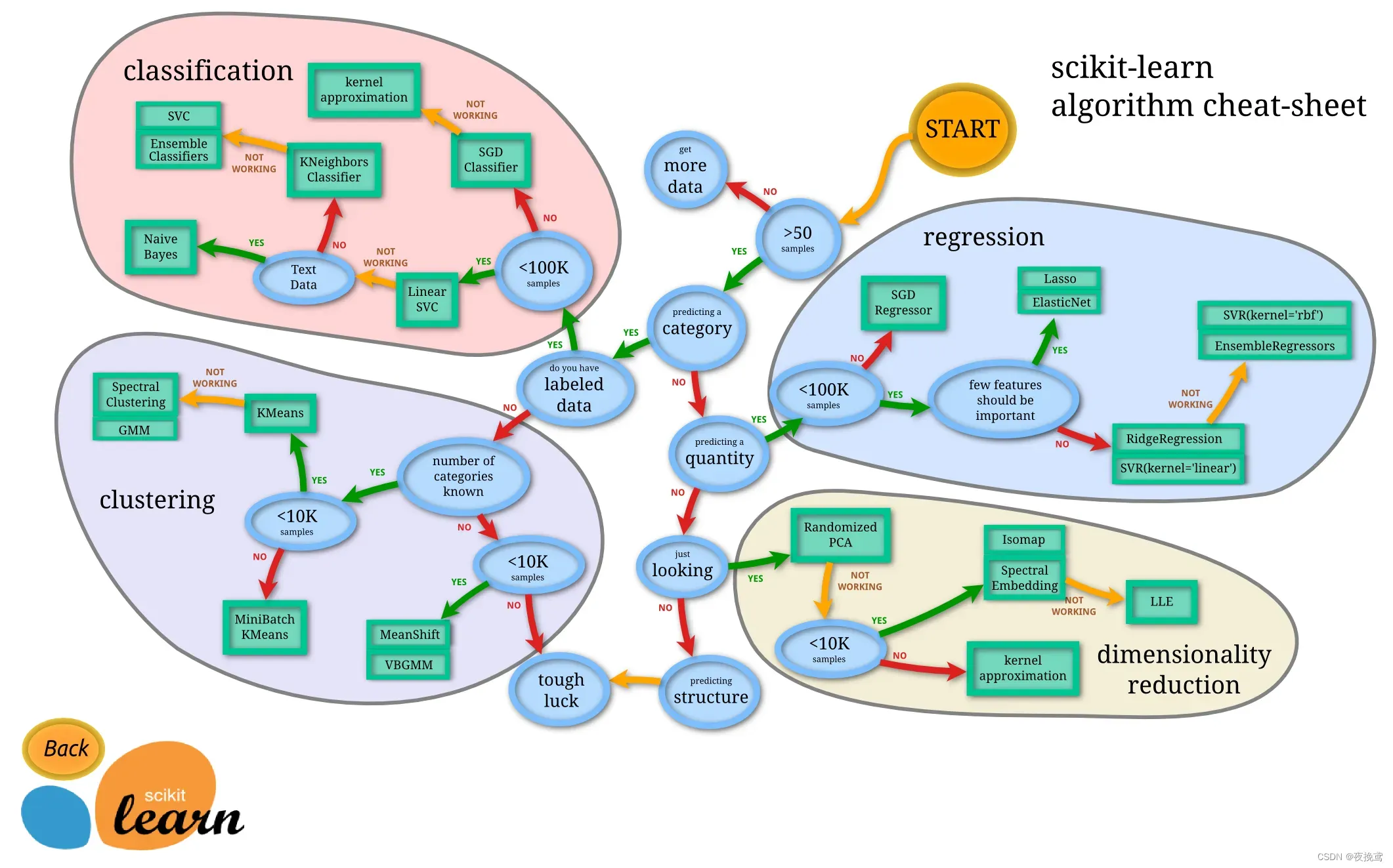
四、sklearn库在机器学习中的应用
1、数据预处理
sklearn.preprocessing模块提供了一些常用的数据预处理函数,如缩放、标准化、二值化等,可以用来对原始数据进行处理和转换,使其更适合机器学习算法的处理。
例如:
from sklearn import preprocessing
import numpy as np
# 创建一些随机数据
data = np.random.rand(5, 2)
# 标准化数据
scaler = preprocessing.StandardScaler().fit(data)
scaled_data = scaler.transform(data)
print(scaled_data)
样例输出:
[[-0.36369316 -0.88624935]
[ 1.60663227 0.65821309]
[-0.94306714 -0.8578848 ]
[ 0.67229355 1.65105326]
[-0.97216552 -0.56513221]]2、特征提取
sklearn.feature_extraction模块提供了一些常用的特征提取函数,如文本特征提取、图像特征提取等,可以用来从原始数据中提取有用的特征,以便用于机器学习算法的处理。
例如:
from sklearn.feature_extraction.text import CountVectorizer
# 创建一些文本数据
corpus = [
'This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?',
]
# 提取文本特征
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(X.toarray())
样例输出:
[[0 1 1 1 0 0 1 0 1]
[0 1 0 1 0 2 1 0 1]
[1 0 0 0 1 0 1 1 0]
[0 1 1 1 0 0 1 0 1]]3、模型选择与评估
sklearn.model_selection模块提供了一些常用的模型选择和评估工具,如交叉验证、网格搜索、评估指标等,可以用来选择最优的模型和调整模型参数,以及评估模型的性能。
例如:
from sklearn.model_selection import GridSearchCV
from sklearn import svm, datasets
# 加载数据
iris = datasets.load_iris()
# 定义模型和参数
parameters = {'kernel': ('linear', 'rbf'), 'C': [1, 10]}
svc = svm.SVC()
# 进行网格搜索
clf = GridSearchCV(svc, parameters)
clf.fit(iris.data, iris.target)
# 输出最优模型参数和得分
print(clf.best_params_)
print(clf.best_score_)
样例输出:
{'C': 1, 'kernel': 'linear'}
0.9800000000000001五、常用的sklearn函数
1、数据集划分
函数:train_test_split
用途:将数据集划分为训练集和测试集,以便用于模型的训练和评估。
样例:
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(iris.data, iris.target, test_size=0.2, random_state=42)
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)
样例输出:
(120, 4) (30, 4) (120,) (30,)2、特征选择
函数:SelectKBest
用途:选择与目标变量最相关的K个特征,以提高模型的性能和效率。
样例:
from sklearn.datasets import load_breast_cancer
from sklearn.feature_selection import SelectKBest, f_classif
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
# 加载数据集
data = load_breast_cancer()
# 划分数据集
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2, random_state=42)
# 特征选择
selector = SelectKBest(score_func=f_classif, k=10)
X_train_new = selector.fit_transform(X_train, y_train)
X_test_new = selector.transform(X_test)
# 训练模型
clf = SVC()
clf.fit(X_train_new, y_train)
# 评估模型
score = clf.score(X_test_new, y_test)
print("Accuracy:", score)
上述示例中,首先加载了一个乳腺癌数据集,然后使用train_test_split函数将数据集划分为训练集和测试集。接下来,使用SelectKBest函数进行特征选择,选择了10个最相关的特征,然后将训练集和测试集中的特征向量转换为只包含选择的特征向量的新特征向量。最后,使用支持向量机模型训练新的特征向量和目标变量,然后使用测试集评估模型性能。
3、特征缩放
函数:StandardScaler
用途:将特征缩放到均值为0、方差为1的范围内,以便提高模型的训练速度和准确性。
样例:
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
# 加载数据集
iris = load_iris()
# 缩放数据集
scaler = StandardScaler()
X_scaled = scaler.fit_transform(iris.data)
print(X_scaled[:5])
样例输出:
[[-0.90068117 1.01900435 -1.34022653 -1.3154443 ]
[-1.14301691 -0.13197948 -1.34022653 -1.3154443 ]
[-1.38535265 0.32841405 -1.39706395 -1.3154443 ]
[-1.50652052 0.09821729 -1.2833891 -1.3154443 ]
[-1.02184904 1.24920112 -1.34022653 -1.3154443 ]]4、模型训练
函数:fit
用途:对数据进行训练,以得到一个机器学习模型。
样例:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# 加载数据集
iris = load_iris()
# 训练决策树模型
clf = DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
print(clf)
5、模型预测
函数:predict
用途:对新数据进行预测,以得到模型的输出结果。
样例:
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
# 加载数据集
iris = load_iris()
# 训练决策树模型
clf = DecisionTreeClassifier()
clf.fit(iris.data, iris.target)
# 预测新数据
y_pred = clf.predict([[5.1, 3.5, 1.4, 0.2]])
print(y_pred)
输出:
[0]
文章出处登录后可见!