Reading Notes: Human-Computer Interaction System: A Survey of Talking-Head Generation
这一篇文章CSDN禁用太多东西的,有些带有人的图片就说图片违规了,所以大家如果要看对应的图片的话,可以去看我在阿里发的文章 https://developer.aliyun.com/article/1174657
Title: Human-Computer Interaction System: A Survey of Talking-Head Generation (Rui Zhen,2023)
Authors: Rui Zhen, Wenchao Song, Qiang He, Juan Cao, Lei Shi, Jia Luo
Journal: Electronics
Abstract
由于人工智能的快速发展,虚拟人被广泛应用于各种行业,包括个人辅助、智能客户服务和在线教育。拟人化的数字人可以快速与人接触,并在人机交互中增强用户体验。因此,我们设计了人机交互系统框架,包括语音识别、文本到语音、对话系统和虚拟人生成。接下来,我们通过虚拟人深度生成框架对Talking-Head Generation视频生成模型进行了分类。同时,我们系统地回顾了过去五年来在有声头部视频生成方面的技术进步和趋势,强调了关键工作并总结了数据集。
对于有关于Talking-Head Generation的方法,这是一篇比较好的综述,我想着整理一下里面比较重要的部分,大概了解近几年对虚拟人工作的一些发展和促进,因为现在虚拟人也是一个很火的方向,在应用上更是尤为突出,可以用作虚拟主播等场景,接下来列一些发展和一些重点,记录一下笔记。
Keywords: talking-head generation; virtual human generation; human–computer interaction
Introduction
虚拟人视频生成主要分为2D/3D面部重建、Talking-Head Generation、身体运动和人体运动。同时,在谈话头部生成任务中,我们需要考虑嘴唇形状和面部属性(如面部表情和眼球运动)的听觉一致性。
在Talking-Head Generation的研究中,音频驱动的嘴唇合成是一个流行的研究方向,通过输入相应的音频和任何网格顶点、面部图像或视频来合成嘴唇同步的说话头部视频。换句话说,该模型动态地将低维语音或文本信号映射到高维视频信号,这也是audio to video。
注意,文本驱动的嘴唇合成是任务的自然扩展,也就是我们常说的
text to video
在深度学习出来之前,一般来说,都会利用HMM和跨模态检索方法来做的,但是利用HMM和基于语素和视素之间映射关系的跨模态检索方法没有考虑语音的上下文语义信息。
随着计算机的发展,之后的深度学习出来以后,Talking-Head Generation的发展受到广泛关注,这是近五年的literature map,可以看到这几年中的发展,大部分来说都是2D/3D的模型。
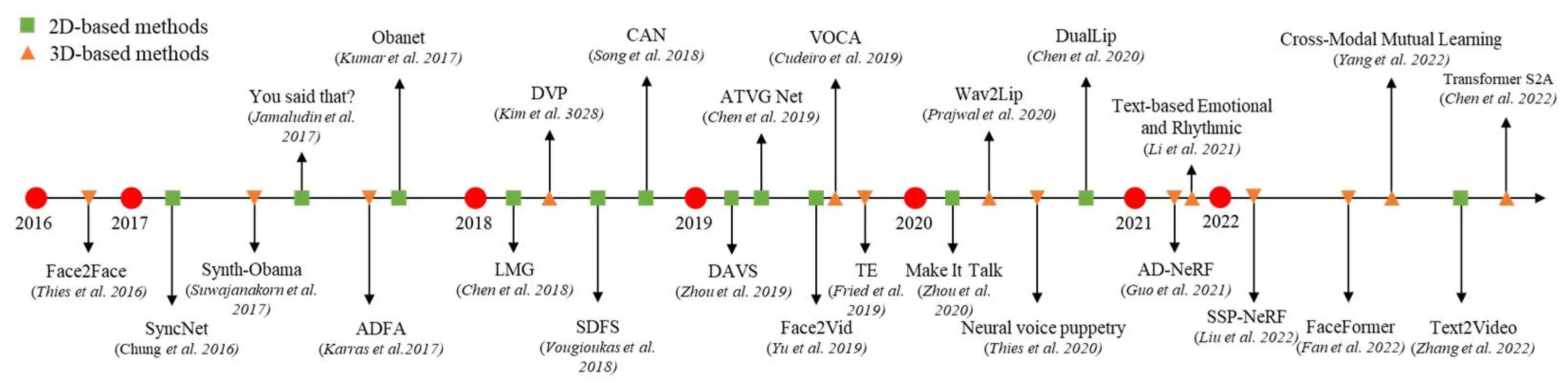
根据模型的方法结构,我们可以将头像生成技术分为流水线和端到端两种类型,如图2所示。但是,在合成头像视频时,大多数模型需要较长的时间生成视频的时间,只有一小部分模型,如 DCK ,可以在短时间内输出结果。

现在总结一下这篇文章的主要贡献:
- 我们提出了一个多模态人机交互的系统框架,为说话头生成模型的应用提供了新思路。
- 我们提出了两个分类法来对具有重要参考意义的方法进行分组,并分析了代表性方法的优缺点及其潜在联系。
- 我们总结了常用于谈话头像生成模型的数据集和评估指标。 同时,我们强调了生成视频的消耗时间作为衡量模型性能的重要性。
Human–Computer Interaction System Architecture
一般来说,这些方法是基于natural language processing, voice, and image processing的,追求与低延迟和高保真拟人化虚拟人的多模态交互。
主要由四个模块组成:
(1)系统通过自动语音识别(ASR)模块将用户输入的语音信息转换为文本信息;
(2)对话系统(DS)将ASR模块输出的文本信息作为输入;
(3)文本转语音(TTS)模块将DS输出的文本转换为逼真的语音信息;
(4)头部生成模块对作为模型输入的图片、视频或blendshape进行预处理,提取其面部特征。

-
语音模块:语音模块的ASR和TTS分别对应于人的听觉和语言功能,比如百度开源的代码 PaddleSpeech 。一个模型可以同时完成 ASR 和 TTS 任务,大大降低了模型部署的复杂度,并能更好地与其他模块协同工作。其中,可能微软的语音是做的很不错的。
-
对话系统模块:对话系统模块需要具备多轮对话的能力。 该系统需要回答特定领域的问题并满足用户聊天的需求。 如图3所示,用户语音通过ASR后,问题被传递到对话模块。 对话模块必须根据用户的问题从知识库中检索或生成匹配的答案。在这一部分,我感觉不用多说,因为已经几乎被
ChatGPT统治了,使用ChatGPT就可以是一个很好的对话系统,并且对上下文信息有一个严密的联系。 -
Talking-Head生成模块:人脸外观数据主要来自真人照片、视频或blendshape人物模型系数。以视频为例,我们首先对这些面部表情数据进行视频预处理,然后将图3中TTS的音频信号映射到人脸唇形、面部表情、面部动作等高维信号,最后,利用一个神经网络。该模型执行视频渲染并输出多模态视频数据。
在人机交互中,及时响应可以提升用户体验。但是,整个系统的延时等于各个数据处理模块所消耗时间的总和。其中,语音模块和对话模块已经被广泛的用户商业化,可以满足人机交互的实时性要求。目前,头部生成模型渲染和输出多模态视频需要很长时间。因此,我们需要提高说话头生成模型的数据处理效率,减少多模态视频的渲染时间,减少人机交互系统扩展的响应时间。虽然虚拟人在京东的ViDA-MAN等部分商用产品中已经实现了低时延响应,但生产周期长、成本高、便携性差等问题也是不容忽视的问题。
Talking-Head Generation
Talking-Head Generation即唇部运动序列生成,旨在合成与驱动源(一段音频或文本)相对应的唇部运动序列。在合成嘴唇运动的基础上,说话头部的视频合成还需要考虑其面部属性,例如面部表情和头部运动。
前面我们有提到过,图 1 显示说话头部的图像维度可以分为基于 2D 和基于 3D 的方法。
-
2D-based methods:在基于 2D 的方法中,说话头生成主要使用landmarks、语义图或其他类似图像的表示来解决问题,比如来对齐嘴唇,比如可以用两个解码器把说话人的身份和语音进行解耦,以生成不受说话人身份影响的视频。
-
3D-based methods:目前的大多数方法都是直接从训练视频中重建 3D 模型,然后进行渲染,这些会更容易驱动,但是缺点就是成本比较高,并且基于ID,不是通用的,现在很多模型是利用了3DMM系数和一些blender shape等,并且除此之外,现在也有NeRF的方法来进行的, NeRF(Neural Radiance Fields)[38-41],它用 MLP 模拟隐式表示,可以存储 3D 空间坐标和外观信息,可用于大分辨率场景。比如AD-NeRF训练了两个 NeRFs 用于说话头部合成的头部和驱动渲染,并获得了良好的视觉效果。
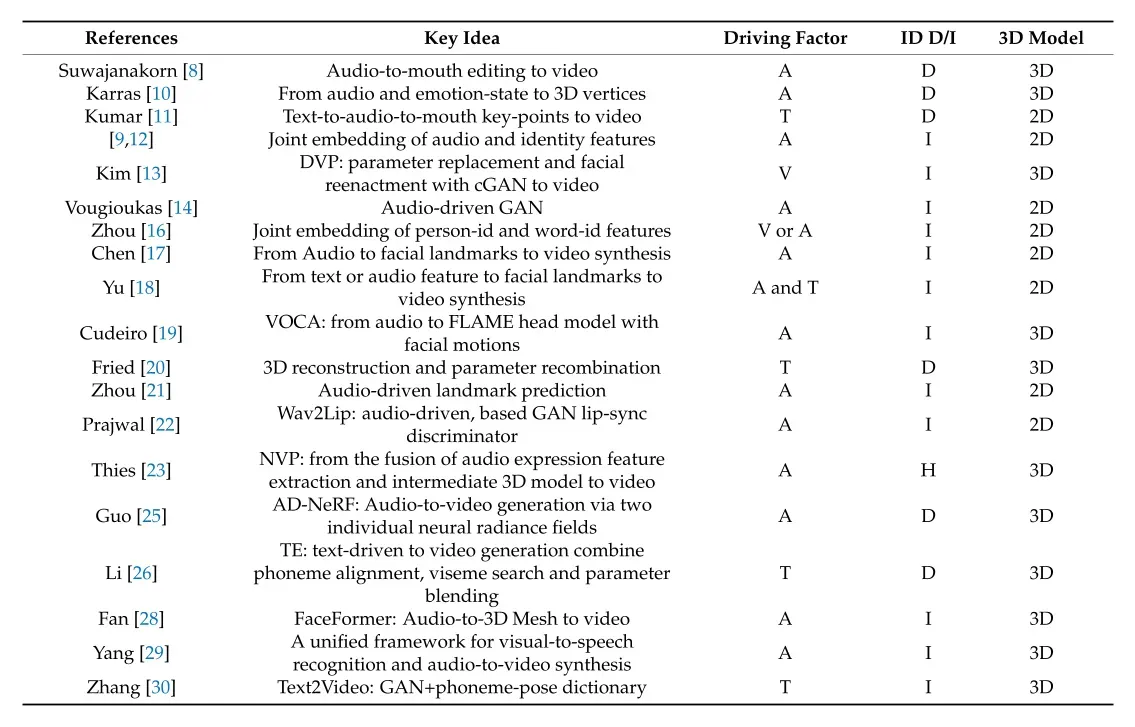
Problem Formulation
以及除此之外,如图2 所示,基于深度学习的头像视频生成框架大致可以分为两种:pipeline和end-to-end。
首先我们来定义一个问题,给定输入音频 A 和主题参考视频 V,我们的说话头部视频生成旨在合成与 A 同步的动作自然视频 S。一般来说,我们会需要生成器G,音频提取特征网络E,R表示渲染网络,然后通过E来处理音频数据A,通过G来生成类似与嘴唇的信息,最后通过R和参考视频V来进行最后生成动作自然视频S。
-
在语音特征提取网络中,现有的方法通常使用梅尔频率倒谱系数(MFCC)来提取音频特征。
-
在语音到视频的渲染网络中,现有模型分别引入了U-Net、GAN、Vision Transformer(ViT)以及新兴的NeRF等网络结构。
简单提一下一些类似的架构,会作为语音->视频的渲染网络
- GAN:利用GAN的,比较好的就是Wav2lip模型,利用对唇形的方式得到更好的结果,并且提出了基于 SyncNet 的专家口型同步鉴别器。
- ViT:在使用 ViT 生成说话头部视频时,FaceFormer 提出了一种新颖的 seq2seq 架构来自回归预测面部运动
- NeRF:NeRF 是一个强大而优雅的 3D 场景表示框架。它可以使用 MLP Fθ 将场景编码到 3D 体积空间中,然后通过沿相机光线整合颜色和密度将 3D 体积渲染到图像中。我觉得一个很不错的就是AD-NeRF。
Pipeline方法
Pipeline方法主要分为两步:低维驱动源数据映射到人脸参数; 然后,使用 GPU 渲染、视频编辑或 GAN 将学习到的面部参数转换为高维视频输出。
根据人脸参数的数据类型,Pipeline方法可以分为Landmark-based、Coefficient-based和Vertex-based方法。
Landmark-based:面部特征点广泛用于各种面部分析任务,包括头部视频合成,在一些方法中,总是会出现像素抖动的问题,没有考虑视频相关帧的相关性,不过后面也提出了一些损失,除此之外,在模型的生成对抗网络部分,由于dlibdetector lip landmarks精度不够,数据集的lip landmark数据存在误差,影响了模型输出视频的效果。除了 2D 地标的方法外,低维驱动源数据到高维 3D 地标的映射也得到了广泛研究,以及语音信号不仅包含语义层面的信息,还包含语音、说话风格、情绪等信息。Coefficient-based:- 2D的系数,主动外观模型 (AAM) 是最常用的面部系数模型之一,表示形状、纹理及其相关性的变化。这是一个2D的系数,也就是AMM系数,不过这个系数的方法会存在一些问题。在将参考面转移到新对象时,AAM 系数会导致潜在的错误和有限的灵活性。
- 3D的系数,许多方法只是控制和生成嘴唇运动和面部表情,但这些方法无法在全 3D 头部控制下合成完整的谈话头部视频。而将 3D Morphable Model(3DMM,3D 人脸参数的更密集表示)引入说话头生成,该方法可以完全控制动作参数,如面部动作、表情和眼睛,或仅调整面部表情参数,其他保持不变。 3DMM系数包括刚性头部姿势参数、面部识别系数、表情系数、双目注视方向参数和球谐光照度系数。
Vertex-based:3D 面部顶点是用于说话头部视频合成的其他常用 3D 模型,在这种方法中,三维模型被表示为由一系列顶点组成的网格,每个顶点都具有一组属性,例如位置、颜色、法向量等。通过对每个顶点的属性进行计算和插值,可以生成模型表面上的像素颜色值,从而实现模型的渲染。有些方法可以预测 3D 顶点坐标,解开下表面和上表面区域的运动,并防止过度平滑,合成更合理、更逼真的说话头部视频。为了保证高保真视频质量,该模型需要大规模的高清 3D 训练数据集。
End-to-End方法
在 2018 年之前,头部视频生成的流水线方法是一个主要的研究方向。 然而,这种基于流水线的方法具有复杂的处理流程、昂贵且耗时的面部参数注释以及额外的辅助技术,例如面部标志检测和 3D/4D/5D 面部重建。 因此,许多研究人员开始探索端到端的头部说话视频合成方法。 端到端方法是指一种架构,它直接从驱动源生成说话的嘴唇(面部)视频,而不涉及任何中间环节的面部参数。
比如一个比较早的经典的End-to-End的方法,就是Speech2vid方法,它由四个模块组成:音频编码器、身份图像编码器、说话人面部图像解码器和去模糊模块。语音编码器旨在从原始音频中提取语音特征;身份图像编码器用于从输入图像中提取身份特征;说话人人脸图像解码器将语音和身份特征作为输入,通过转置卷积和上采样方法进行特征融合,输出合成图像。
除此之外,模型的缺点也很明显:
- 由于
Specch2vid没有考虑时间序列中的连续性,会产生不连贯的视频序列,存在跳帧或抖动;
- L1重建损失是对整张脸进行的,很难从单个音频中推断出一个人的多种面部表情。

以音频驱动的头像视频生成模型为例,一段音频中包含了语音、情绪、说话风格等多种信息。因此,解耦复杂的音频信息是头部视频任务中的一个重要问题。所以这个时候就有了一些策略和方法,比如利用生成对抗网络的GAN的策略进行,以及利用一些知识蒸馏的方法进行从音频输入中分离出情感、身份和语音特征。并且现在许多研究人员将面部表情、头部姿势和眨眼频率等编码属性引入模型中,以生成更自然的说话头部。
GAN-based methods:基于GAN的方法侧重于为头部视频生成模型定制更有效的学习目标,以避免仅使用图像重建损失的缺点。比如Wav2lip就是类似的方法NeRF: 除了基于 GAN 的端到端方法外,研究人员还受到了神经辐射场 (NeRF) 的启发 。比如说AD-NeRF,AD-NeRF集成的DeepSpeech音频特征被用作条件输入来学习隐式神经场景表示函数,该函数将音频特征映射到动态神经辐射场以进行说话人面部渲染。AD-NeRF可以通过学习两个独立的神经辐射场来对头部和上半身进行建模,还可以操纵动作姿势和背景替换等属性,但这种方法无法泛化不匹配的驾驶语音和说话人。然而,AD-NeRF在渲染阶段经常会出现头部和躯干分离的情况,从而导致合成视频不自然。不过,NeRF渲染速度慢也是一个不容忽视的问题,不过现有很多方法也有来提高NeRF的渲染速度了。- 除此之外,Audio-driven talking face video generation with dynamic convolution kernels 提出了一种具有动态卷积核 (
DCK) 的全卷积神经网络,用于跨模态特征融合和音频驱动的人脸视频生成,用于多模态任务,并且对不同的身份、头部姿势和音频具有鲁棒性。由于简单高效的网络架构,谈话头部视频生成模型的实时性得到显着提高。
Datasets and Evaluation Metrics
在人工智能时代,数据集是深度学习模型的重要组成部分。 同时,数据集也推动了虚拟人合成领域复杂问题的解决。 然而在实际应用中,很少有高质量的标注数据集无法满足语音合成模型的训练需求。 此外,许多机构/研究人员受到deepfake技术伦理问题的影响,这增加了获取某些数据集的难度。 例如,只允许高校、研究机构和企业的研究人员、教师和工程师申请,禁止学生申请。
Datasets
在表 2 中,我们简要突出了大多数研究人员常用的数据集,包括统计数据和下载链接。
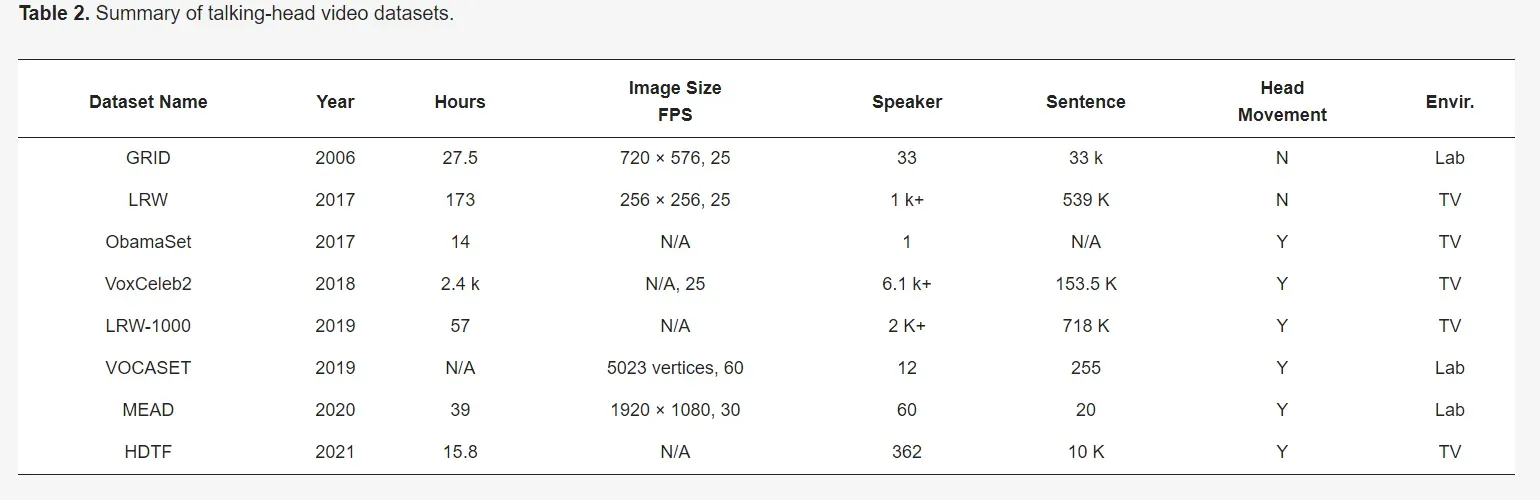
GRID 数据集是在一个有 34 名志愿者的实验室环境中记录的,这在大型数据集中相对较小,但每个志愿者说了 1000 个短语,总共有 34,000 个话语实例。 数据集的短语组成符合一定的规则。 每个短语包含六个单词,从六种单词中的每一种随机选择以形成随机短语。 六类词是“命令”、“颜色”、“介词”、“字母”、“数字”和“副词”。 数据集可在 https://spandh.dcs.shef.ac.uk//gridcorpus/ 获取,于 2022 年 12 月 30 日访问。
LRW 以各种说话风格和头部姿势而闻名,是一个收集的英语视频数据集 来自 BBC 节目,演讲者超过 1000 人。 词汇量为 500 个词,每个视频长 1.16 秒(29 帧),涉及目标词和上下文。 数据集可在 https://www.robots.ox.ac.uk/~vgg/data/lip_reading/lrw1.html 获取,于 2022 年 12 月 30 日访问。
LRW-1000 是从 2000 多个视频中收集的普通话视频数据集 词汇科目。 该数据集的目的是涵盖不同语音模式和成像条件的自然变化,以纳入现实应用中遇到的挑战。 每个类别的样本数量、视频分辨率、照明条件以及说话者姿势、年龄、性别和化妆等属性都有很大差异。 注:官方网址(http://vipl.ict.ac.cn/en/view_database.php?id=13,2022年12月30日访问)已失效,详情可前往论文页面 数据并在此处下载协议文件(https://github.com/VIPL-Audio-Visual-Speech-Understanding/AVSU-VIPL,2022 年 12 月 30 日访问。)如果您计划使用此数据集进行研究。
ObamaSet 是一个特定的视听数据集,专注于分析美国前总统巴拉克奥巴马的视觉演讲。 所有视频样本都是从他每周的地址录像中收集的。 与以前的数据集不同,它只关注巴拉克奥巴马,不提供任何人工注释。 数据集可在 https://github.com/supasorn/synthesizing_obama_network_training 获取,于 2022 年 12 月 30 日访问。
VoxCeleb2 从 YouTube 视频中提取,包括视频 URL 和话语时间戳。 同时,它也是目前最大的公共视听数据集。 尽管此数据集用于说话人识别任务,但它也可用于训练说话人头像生成模型。 但数据集需要申请获取下载权限,以防止数据集被滥用。 许可申请网址为https://www.robots.ox.ac.uk/~vgg/data/voxceleb/,2022年12月30日访问。由于数据集庞大,需要300G+存储空间,支持下载 工具。 下载方法在https://github.com/walkoncross/voxceleb2-download,2022年12月30日访问。
VOCASET 是一个 4D 人脸数据集,具有大约 29 分钟的 4D 人脸扫描,同步音频来自 12- 比特扬声器(六名女性和六名男性),并以 60 fps 的速度记录 4D 面部扫描。 作为具有代表性的高质量 4D 面对面视听数据集,Vocaset 极大地促进了 3D VSG 的研究。 数据集可在 https://voca.is.tue.mpg.de/获取,于 2022 年 12 月 30 日访问。
MEAD ,多视图情感视听数据集,是一个大规模、高质量的情感视听数据集。 与以前的数据集不同,它侧重于自然情感语音的面部生成,并考虑了多种情绪状态(三个强度级别上的八种不同情绪)。 数据集可在 https://wywu.github.io/projects/MEAD/MEAD.html获取,于 2022 年 12 月 30 日访问。
HDTF 是一个大型的野外高分辨率视听数据集,代表高清说话人脸数据集。 HDTF 数据集由大约 362 个 15.8 小时的不同视频组成。 原始视频的分辨率为 720 P 或 1080 P。每个裁剪视频的大小都调整为 512 × 512。数据集可在 https://github.com/MRzzm/HDTF 获取,于 2022 年 12 月 30 日访问。
Evaluation Metrics
Talking-Head Generation的评估任务是一个开放性问题,需要从客观和主观两个方面对生成结果进行评估。
这些指标可以分为三种类型:视觉质量、视听语义一致性和基于定量模型性能评估的实时性。
-
Visual Quality:重建误差测量(例如,均方误差)是评估生成的视频帧质量的自然方法。然而,重建误差只关注像素对齐,忽略了全局视觉质量。现在大多数有峰值信噪比 (PSNR)、结构相似性指数度量 (SSIM) 和学习感知图像块相似性 (LPIPS) 来评估生成的全局视觉画面质量。由于PSNR、SSIM等指标不能很好地解释人类感知,而LPIPS在视觉相似度判断上更接近人类感知,因此推荐使用LPIPS来定量评估生成内容的视觉质量。
-
Audio-visual semantic consistency:生成视频与驱动源的语义一致性主要包括视听同步和语音一致性。对于视听同步,地标距离 (LMD) 计算合成视频帧和地面实况帧之间唇部区域地标的欧几里德距离。另一个同步评估指标使用SyncNet来预测生成的帧和地面实况的偏移量。 -
Real-time performance:生成说话头部视频的时间长度是现有模型的重要指标。在人机交互的实际应用中,人们对等待时间、视频质量等因素非常敏感。因此,模型应该在不牺牲视觉质量或视听语义连贯性的情况下尽快生成视频。 -
Delayed Talking-Head Synthesis Model:有研究提出了一种带有 DCK 的新颖的全卷积网络,用于音频驱动的有声视频生成的多模态任务。由于简单而有效的网络架构和视频预处理,说话头生成的实时性能有了显着提高。Live speech portraits: Real-time photorealistic talking-head animation提出了一个实时系统,可以生成个性化的逼真头部动画,仅由超过 30 fps 的音频信号驱动。然而,许多研究忽略了实时性能,我们应该将其视为未来的关键评估指标。
现如今,在生成高质量、低延迟的数字人类视频时,很多研究者并没有将实时性作为模型的评价指标。因此,许多模型生成视频的速度太慢,无法满足应用程序的要求。例如,要生成无背景的 256×256 分辨率面部视频,ATVGnet 需要 1.07 秒,You Said That 需要 14.13 秒,X2Face 需要 15.10 秒,DAVS 需要 17.05 秒,1280 × 720 分辨率视频带背景需要更长的时间。虽然 Wav2lip 合成带有背景的视频只需要 3.83 s,但面部下半部分的清晰度低于其他区域。
许多研究试图建立一个新的评估基准,并提出了十几种虚拟人视频生成的评估指标。因此,现有的虚拟人视频生成评价指标并不统一。除了客观指标,还有主观指标,比如用户研究。
Future Directions
对于未来发展的方向,作者讲了几个方法和想法
Dataset construction and methods for learning with fewer samples:顾名思义,也就是需要高质量的数据集,高质量的数据集有利于模型生成逼真、生动、逼真的头部说话视频。现有的开源数据集主要由野生视频组成,部分用于视觉语音识别任务。此外,当前方法的局限性在于,基于深度学习的头部说话视频生成方法主要依赖于标记数据。除此之外,还可以把目光放在知识蒸馏和少镜头学习。The realistic talking-head video generation with spontaneous movement:人类对合成视频中的任何运动变化都很敏感,他们会不自觉地注意嘴唇、眼睛、眉毛和说话时自发的头部运动。我们的视听一致性当然是非常重要的,但是很少可以从音频中推断出眼睛和头部运动以及情绪特征等隐含特征。最近,基于对嘴唇运动的研究,许多开始探索眨眼和头部姿势等隐式特征在说话头部视频生成中的应用。特别是在人机对话系统中,TTS模块合成的语音不如野外音频所包含的信息丰富。Talking-head video generation detection:这种生成技术的发展实际上极大地威胁着社会发展,滥用头像视频生成技术和人物图片或视频可能会降低虚假信息的制作成本,促进其传播,并导致严重的道德和法律问题,尤其是对名人或政客而言。Talking-Head Generation、假视频识别和检测是自然共生的任务。同时,头部视频生成模型输出的内容自然逼真,给相关取证工作带来了极大的困难和挑战,引起了众多研究者的关注。并且,现有的许多方法都侧重于提高模型的性能,而忽略了模型可解释性差的问题。所以说,可解释且稳健的视频生成检测对于加速技术开发和防止技术滥用非常重要。Multi-person talking-head video generation:在语音识别任务中,ASR模型可以根据输入语音的声纹差异识别说话人的数量,划分说话人和语音内容。多人头像视频生成,将一段语音不同声纹映射到不同头像的面部关键点信息,是一项具有挑战性的任务。可以应用于生活中的很多场景,比如播新闻时的新闻连线。当然,将单个头部说话视频生成方法转移到多个头部头部视频生成任务可能不是最优的。
除此之外,考虑到基于深度学习的人头生成模型的实时性问题无法解决,该领域还有很大的研究空间。
-
G-based talking-head generation method:随着元宇宙概念的引入,用于在游戏、电影等场景中创建虚拟角色的计算图形(CG)公司推出了虚拟人生成程序。*目前,可用于创建虚拟人类说话头的程序包括 Nvidia Omniverse 中的 Audio2Face(https://www.nvidia.cn/omniverse/apps/audio2face/,2022 年 12 月 30 日访问。),Meta-Human Creator( https://www.unrealengine.com/zh-CN/metahuman,于 2022 年 12 月 30 日访问。)在 Epic 的虚幻引擎中,数字人类(https://unity.com/demos/enemies#digital-humans,于 30 日访问2022 年 12 月。)*现在,基于CG程序的虚拟人头实时渲染,有Audio2Face和Meta-Human Creator结合输出渲染视频的方法。同时,一些研究人员通过让模型学习来学习语音、嘴唇和表情参数。它将虚拟人的动作生成算法与3D引擎相结合,实时输出渲染的卡通图像视频,例如华为的手语数字化仪和基于3D人体网格的姿势引导生成。对于说话人头的深度生成,将深度学习方法与CG程序相结合,保证了视频渲染的实时性。虽然它具有巨大的应用潜力,但高昂的费用是虚拟人头视频输出的缺点。语音到动画(S2A)技术是一种从给定的语音中自动估计同步面部动画参数,并基于渲染引擎(如虚幻引擎 4(UE4))生成具有这些预测参数的最终动画化身的方法。 -
A method based on NeRF (Neural Radiance Fields) rendering:计算机视觉领域,利用深度神经网络对物体和场景进行编码是一个新的研究方向。 NeRF 是一种隐式神经表征,可以从多个角度的图像中渲染出任何视角的清晰照片。其中,AD-NeRF 将 NeRF 引入到头部视频生成中。尽管原生 NeRF 算法的渲染速度较慢,无法实时生成说话的头部视频,但许多研究人员提出了多种方法来提高 NeRF 的渲染速度。例如,DONeRF 可以在单个 GPU 上每秒渲染 20 帧,而 PlenOctrees for Real-time Rendering of Neural Radiance Fields比传统 NeRF 快 3000 多倍。 -
A method for fusing speech recognition (ASR) and computer vision:随着输入语音数据的不断增加,Streaming ASR实时输出语音识别的文本结果。其中,流解码器CTC、RNN-T和LAC的发展推动了Streaming ASR的快速发展。相比之下,在深度生成的计算机视觉领域,没有模型可以实时输出说话的头部视频。因此,在实时人头视频生成研究中,可以将ASR领域的流解码器引入人头视频生成模型中,以降低视频生成的实时率。
文章出处登录后可见!