NCCL
Overview of NCCL
NCCL : NVIDIA Collective Communications Library 英伟达集体通信库
提供集合通信和点对点通信的 发送/接收原语。不是个成熟的并行编程框架;而是一个加速GPU内通信的库
NCCL 提供如下集体通信原语(collective communication primitives):
- AllReduce
- Broadcast
- Reduce
- AllGather
- ReduceScatter
他也允许点到点的收发通信,包括:散播(scatter),聚集(gather),或者all-to-all 操作。
通信处理器间的紧密同步是集合通信的关键方面。 基于CUDA的集体的传统地实现是通过 CUDA 内存复制操作和CUDA内核来进行本地削减 (redection) 。NCCL, 实现了每个集合在单一内核上处理通信和计算操作。这样就允许实现快速同步和减少达到峰值带宽所需要的资源。
NCCL 方便地消除了开发人员在特定机器上优化他们的应用的需求。NCCL 提供了节点内或跨界节点的多GPU 的快速的集体(collectives)。它支持各种互联技术,包括PCIe, NVLINK, InfiniBand Verbs, and IP sockets.
除了性能,变成易用性也是NCCL设计的考虑因素,NCCL使用见到的C API 可以从多种编程语言轻松访问。
NCCL几乎兼容任何多GPU并行化模型,例如:
- 单线程控制所有的GPU
- 多线程的,例如每个GPU由一个线程控制
- 多进程的,例如 MPI
NCCL 在深度学习框架有巨大的作用,AllReduce 集合大量应用于神经网络训练。 通过 NCCL 提供的多 GPU 和多节点通信,可以有效扩展神经网络训练。
集合操作 Collective Operations
集合操作需要被每个rank(rank 是指的CUDA设备) 待用来组成一个完整的集合操作。如果不这样做,将导致其他队伍无限期地等待。
AllRedeuce
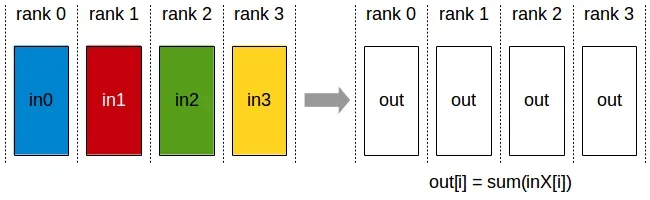
AllReduce 操作对跨设备的数据执行规约操作,并将结果写入每个rank的接收缓冲区。
AllReduce 操作与rank的排序无关。
AllReduce 以 K个数组开始,这些数组含有各自独立的N个值。并以N个值相同的S数组结束。 对于每个rank,S[i] = V0[i] + V1[i] +…+Vk-1[i]
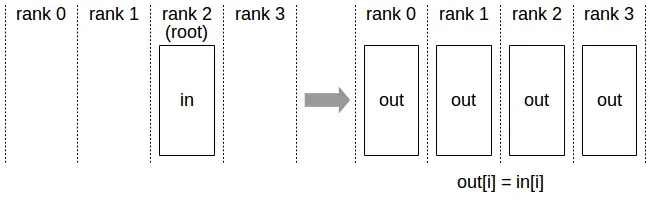
Broadcast
将一个root rank的N的元素的buffer 复制到所有rank上
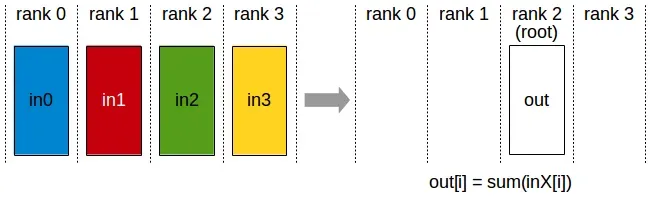
Reduce
执行过程和allReduce相似,不过仅仅将结果写入特定的 root rank
一个reduce 操作后,执行broadcast操作效果和 allreduce一样
AllGather
K个rank中,每个rank中N个值,聚集在一起。输出结果按照rank 标号排序。
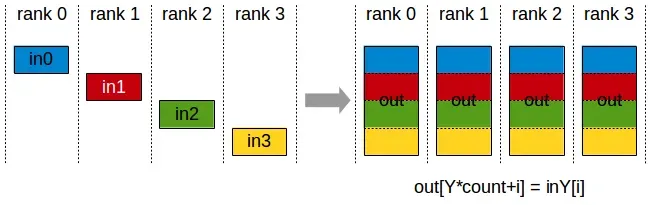
ReduceScatter
执行起来和reduce类似,不过结果会散布在各个rank的block中。每个rank 根据其标号获得一部分数据。
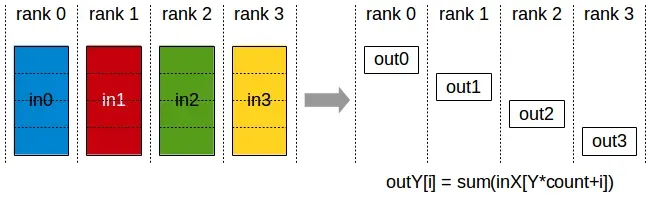
ReduceScatter 会受rank布局的影响。
ring-allreduce
参考 : 知乎文章 CSDN文章
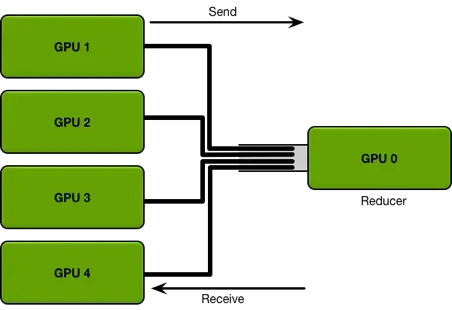
GPU分布式计算,GPU1~4卡,负责网络参数的训练,每个卡上布置了相同的深度学习网络,每个卡都分配到不同的数据的minibatch。每张卡训练结束后将网络参数同步到GPU0,也就是Reducer这张卡上,然后再求参数变换的平均下发到每张计算卡,整个流程有点像mapreduce的原理。
涉及两个问题:
-
每一轮训练迭代都需要所有的卡将数据同步完,做一次reduce才算结束。 如果卡数比较少的情况下,其实影响不大,但是如果并行的卡很多的时候,就涉及到计算快的卡需要去等待计算慢的卡的情况,造成计算资源的浪费。
-
每次迭代所有的计算GPU卡都需要针对全部模型参数,跟Redcue卡进行通信。数据量大,通信开销大,随卡的数量增多开销会线性增长。
Ring Allredcue ,通过将GPU卡的通信模型拼接成一个环形,从而减少卡数增加带来的资源消耗。
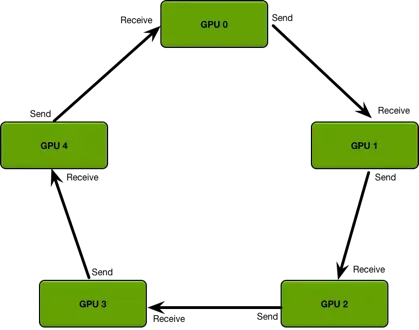
该算法的过程主要分成两步:1、scatter-reduce 2、allgather
1、 scatter-reduce
如果有n块GPU,将GPU上的数据划分成n块,并指定GPU的左右邻居
然后开始n-1次操作,在第 i 次操作时, GPU j会将自己的第 (j-i)%n 快数据发送给GPU j+1,并接受来自 GPU j-1的 (j-i-1)%n 的数据,如下图
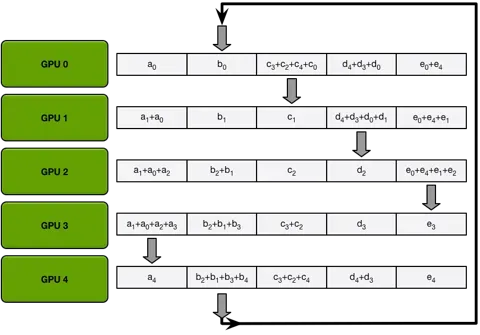
当n-1次操作完成后,ring-allreduce的第一大步scatter-reduce就已经完成了,此时,第i块gpu的第(i + 1) % n块数据已经收集到了所有n块gpu的第(i + 1) % n块数据,那么,再进行一次allgather就可以完成算法了。
第二部: allgather,通过n-1传递把第 i 块 GPU的第 (i+1)%n 块数据传递给其他GPU。
最后每个GPU就变成了如下所示:
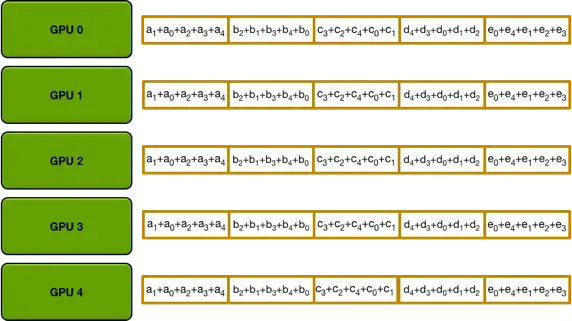
一下图来自 https://blog.csdn.net/dpppBR/article/details/80445569
举一个3gpu的例子:
首先是第一步,scatter-reduce:

然后是allgather的例子:
文章出处登录后可见!