问题描述:
下面是一个非常简单的读取并打印文件内容的示例:
with open('test.txt', 'r') as f:
contents = f.read()
print(contents)在test.txt文本文件中,只有一个 `你` 字:
test.txt
你但是,我们在运行这段代码时,出现了如下的错误:
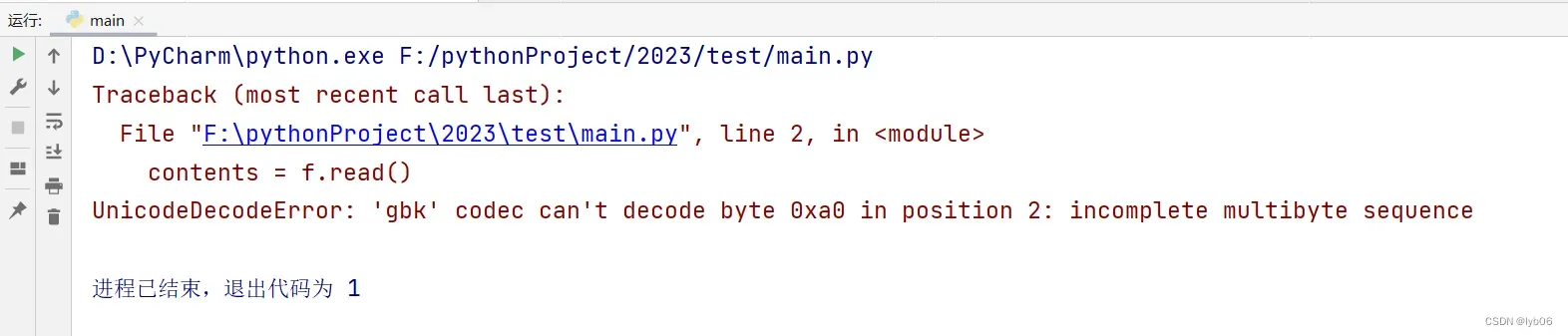
报错:
UnicodeDecodeError: 'gbk' codec can't decode byte 0xa0 in position 2: incomplete multibyte sequence分析问题:
首先我们得知道这个错误是什么意思。
报错翻译过来就是:
Unicode解码错误:“gbk”编解码器无法解码位置2的字节0xa0:不完整的多字节序列
通过了解报错信息,我们知道了这是一个解码的错误。要分析这个错误,我们首先要对Python的字符编码有一个基本的认识。
对于Python字符编码的问题,大家可以看看我的这篇博文:
一文搞懂Python字符编码(编码方式、乱码和报错原因)_lyb06的博客-CSDN博客
在这篇博文中,我不仅介绍了字符编码,还分析了这个报错出现的具体原因,但这里我们主要探讨解决方法,就不做赘述了。想了解具体原因可看该文第3、4部分。
现在我们知道了这个错误是因为我们使用gbk(Windows 平台,默认编码是 gbk)对文本进行解码时,有一处地方多出了一个字节无法解码。gbk将一个汉字编码为2个字节,也就是每两个字节可解码为一个汉字,而一个字节无法解码,故报错,这也就解释了报错信息后面的:incomplete multibyte sequence(不完整的多字节序列)。
出现这种问题,一般是由于该文本文件是用utf-8编码的(utf-8将一个汉字编码为3个字节),但我们却使用gbk来解码。由于二者对于汉字的编码方式是不一样的,解码时又恰好出现了多余的无法解码的字节,因此就出现了报错。
为什么要说恰好出现多余的无法解码的字节?
因为有种特殊情况不会报错!用utf-8编码了两个汉字(6个字节),此时用gbk可以将其解码为3个汉字(6个字节分为3份2个字节,可以对应3个汉字),这种情况不会报错,但显示的信息不一样,就是我们常说的乱码 ,详情见上面提到的博文。
你可将读取的test.txt文件中的内容改为两个汉字 “你好” ,在运行一下这个代码,你会发现没有报错,但是打印出的信息就不是 ‘你好’ 了。
5、要解决这个问题,我们就要让Python用utf-8来解码文件。
解决方法:
在使用open() 时,我们添加参数 encoding=’utf-8’。使用这个参数,相当于我们就告诉了Python:我们这个文件是用utf-8编码的,你一会儿对这个文件解码的时候,就用utf-8解码,不要用gbk解码。
with open('test.txt', 'r', encoding='utf-8') as f:
contents = f.read()
print(contents)输出:
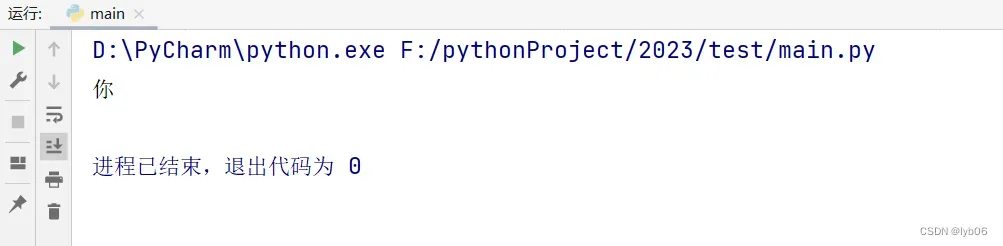
成功!问题解决。
文章出处登录后可见!