文章目录
- TensorRT Execution Provider
- Install
- Requirements
- Build
- Usage
- Configurations
- 环境变量
- 执行提供程序选项
- Performance Tuning
- Samples
- Reference
TensorRT Execution Provider
借助 TensorRT 执行提供程序,与通用 GPU 加速相比,ONNX 运行时可在相同硬件上提供更好的推理性能。
ONNX 运行时中的 TensorRT 执行提供程序利用 NVIDIA 的TensorRT深度学习推理引擎来加速其 GPU 系列中的 ONNX 模型。Microsoft 和 NVIDIA 密切合作,将 TensorRT 执行提供程序与 ONNX Runtime 集成。
Install
Jetson Zoo中的 Jetpack 提供了预构建的包和 Docker 映像。
Requirements
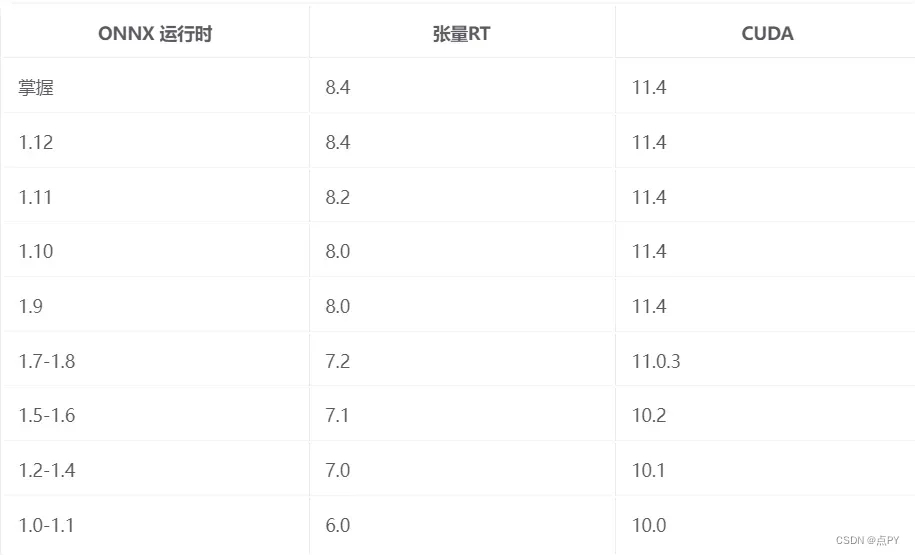
Build
参考构建说明。
ONNX 运行时的 TensorRT 执行提供程序是使用 TensorRT 8.4 构建和测试的。
Usage
C++
Ort::Env env = Ort::Env{ORT_LOGGING_LEVEL_ERROR, "Default"};
Ort::SessionOptions sf;
int device_id = 0;
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_Tensorrt(sf, device_id));
Ort::ThrowOnError(OrtSessionOptionsAppendExecutionProvider_CUDA(sf, device_id));
Ort::Session session(env, model_path, sf);
C API 详细信息在此处。
TENSORRT 子图的形状推断
如果模型中的某些算子不受 TensorRT 支持,ONNX Runtime 将对图进行分区,仅将支持的子图发送到 TensorRT 执行提供者。因为 TensorRT 要求子图的所有输入都具有指定的形状,所以如果没有输入形状信息,ONNX 运行时将抛出错误。在这种情况下,请先在此处运行脚本,对整个模型进行形状推断。
Python
要使用 TensorRT 执行提供程序,您必须在实例化 InferenceSession 时显式注册 TensorRT 执行提供程序。请注意,建议您还注册 CUDAExecutionProvider 以允许 Onnx Runtime 将节点分配给 TensorRT 不支持的 CUDA 执行提供程序。
import onnxruntime as ort
# set providers to ['TensorrtExecutionProvider', 'CUDAExecutionProvider'] with TensorrtExecutionProvider having the higher priority.
sess = ort.InferenceSession('model.onnx', providers=['TensorrtExecutionProvider', 'CUDAExecutionProvider'])
Configurations
有两种方法可以配置 TensorRT 设置,通过环境变量或通过执行提供程序选项 API。
环境变量
可以为 TensorRT 执行提供程序设置以下环境变量。
-
ORT_TENSORRT_MAX_WORKSPACE_SIZE:TensorRT 引擎的最大工作空间大小。默认值:1073741824 (1GB)。
-
ORT_TENSORRT_MAX_PARTITION_ITERATIONS:TensorRT 模型分区中允许的最大迭代次数。如果在达到最大迭代次数时目标模型无法成功分区,则整个模型将回退到其他执行提供程序,例如 CUDA 或 CPU。默认值:1000。
-
ORT_TENSORRT_MIN_SUBGRAPH_SIZE:分区后子图中的最小节点大小。较小的子图将回退到其他执行提供程序。默认值:1。
-
ORT_TENSORRT_FP16_ENABLE:在 TensorRT 中启用 FP16 模式。1:启用,0:禁用。默认值:0。请注意,并非所有 Nvidia GPU 都支持 FP16 精度。
-
ORT_TENSORRT_INT8_ENABLE:在 TensorRT 中启用 INT8 模式。1:启用,0:禁用。默认值:0。请注意,并非所有 Nvidia GPU 都支持 INT8 精度。
-
ORT_TENSORRT_INT8_CALIBRATION_TABLE_NAME:为 INT8 模式下的非 QDQ 模型指定 INT8 校准表文件。注意 QDQ 模型不应该提供校准表,因为如果模型中有任何 Q/DQ 节点,TensorRT 不允许加载校准表。默认情况下,名称为空。
-
ORT_TENSORRT_INT8_USE_NATIVE_CALIBRATION_TABLE:选择在 INT8 模式下用于非 QDQ 模型的校准表。如果为 1,则使用原生 TensorRT 生成的校准表;如果为 0,则使用 ONNXRUNTIME 工具生成的校准表。默认值:0。 **注意:请在推断前将最新的校准表文件复制到 ORT_TENSORRT_CACHE_PATH。校准表特定于模型和校准数据集。每当生成新的校准表时,应清理或替换路径中的旧文件。
-
ORT_TENSORRT_DLA_ENABLE:启用 DLA(Deep learning accelerator)。1:启用,0:禁用。默认值:0。请注意,并非所有 Nvidia GPU 都支持 DLA。
-
ORT_TENSORRT_DLA_CORE:指定要在其上执行的 DLA 内核。默认值:0。
-
ORT_TENSORRT_ENGINE_CACHE_ENABLE:启用 TensorRT 引擎缓存。使用引擎缓存的目的是在 TensorRT 可能需要很长时间来优化和构建引擎的情况下节省引擎构建时间。引擎将在第一次构建时被缓存,因此下次创建新的推理会话时,引擎可以直接从缓存中加载。为了验证加载的引擎是否可用于当前推理,引擎配置文件也被缓存并与引擎一起加载。如果当前输入形状在引擎配置文件的范围内,则可以安全地使用加载的引擎。否则,如果输入形状超出范围,则将更新配置文件缓存以覆盖新形状,并且将根据新配置文件重新创建引擎(并在引擎缓存中刷新)。请注意,每个引擎都是为特定设置创建的,例如模型路径/名称、精度(FP32/FP16/INT8 等)、工作区、配置文件等,以及特定的 GPU,并且它不可移植,因此必须确保这些设置不会改变,否则需要重新构建引擎并再次缓存。1:启用,0:禁用。默认值:0。警告:如果发生以下任何更改,请清理所有旧引擎和配置文件缓存文件(.engine 和 .profile):
- 模型更改(如果模型拓扑、opset 版本、运营商等有任何更改)
- ORT 版本更改(即从 ORT 版本 1.8 移动到 1.9)
- TensorRT 版本变更(即从 TensorRT 7.0 迁移到 8.0)
- 硬件变化。(引擎和配置文件不可移植,并且针对特定的 Nvidia 硬件进行了优化)
-
ORT_TENSORRT_CACHE_PATH:如果 ORT_TENSORRT_ENGINE_CACHE_ENABLE 为 1,则指定 TensorRT 引擎和配置文件的路径,如果 ORT_TENSORRT_INT8_ENABLE 为 1,则指定 INT8 校准表文件的路径。
-
ORT_TENSORRT_DUMP_SUBGRAPHS:将转换为onnx格式的TRT引擎的子图转储到文件系统。这可以帮助调试子图,例如通过使用trtexec –onnx my_model.onnx和检查解析器的输出。1:启用,0:禁用。默认值:0。
-
ORT_TENSORRT_FORCE_SEQUENTIAL_ENGINE_BUILD:在多 GPU 环境中跨提供者实例按顺序构建 TensorRT 引擎。1:启用,0:禁用。默认值:0。
One can override default values by setting environment variables ORT_TENSORRT_MAX_WORKSPACE_SIZE, ORT_TENSORRT_MAX_PARTITION_ITERATIONS, ORT_TENSORRT_MIN_SUBGRAPH_SIZE, ORT_TENSORRT_FP16_ENABLE, ORT_TENSORRT_INT8_ENABLE, ORT_TENSORRT_INT8_CALIBRATION_TABLE_NAME, ORT_TENSORRT_INT8_USE_NATIVE_CALIBRATION_TABLE, ORT_TENSORRT_ENGINE_CACHE_ENABLE, ORT_TENSORRT_CACHE_PATH and ORT_TENSORRT_DUMP_SUBGRAPHS. 例如在 Linux 上
将默认最大工作空间大小覆盖为 2GB
导出 ORT_TENSORRT_MAX_WORKSPACE_SIZE=2147483648
将默认最大迭代次数覆盖为 10
导出 ORT_TENSORRT_MAX_PARTITION_ITERATIONS=10
将默认最小子图节点大小覆盖为 5
导出 ORT_TENSORRT_MIN_SUBGRAPH_SIZE=5
在 TENSORRT 中启用 FP16 模式
导出 ORT_TENSORRT_FP16_ENABLE=1
在 TENSORRT 中启用 INT8 模式
导出 ORT_TENSORRT_INT8_ENABLE=1
使用原生 TENSORRT 校准表
导出 ORT_TENSORRT_INT8_USE_NATIVE_CALIBRATION_TABLE=1
启用 TENSORRT 引擎缓存
导出 ORT_TENSORRT_ENGINE_CACHE_ENABLE=1
执行提供程序选项
TensorRT 配置也可以通过执行提供程序选项 API 进行设置。当每个模型和推理会话都有自己的配置时,这很有用。在这种情况下,执行提供程序选项设置将覆盖任何环境变量设置。所有配置都应该明确设置,否则将采用默认值。环境变量和执行提供程序选项之间存在一对一的映射,如下所示,
ORT_TENSORRT_MAX_WORKSPACE_SIZE <-> trt_max_workspace_size
ORT_TENSORRT_MAX_PARTITION_ITERATIONS <-> trt_max_partition_iterations
ORT_TENSORRT_MIN_SUBGRAPH_SIZE <-> trt_min_subgraph_size
ORT_TENSORRT_FP16_ENABLE <-> trt_fp16_enable
ORT_TENSORRT_INT8_ENABLE <-> trt_int8_enable
ORT_TENSORRT_INT8_CALIBRATION_TABLE_NAME <-> trt_int8_calibration_table_name
ORT_TENSORRT_INT8_USE_NATIVE_CALIBRATION_TABLE <-> trt_int8_use_native_calibration_table
ORT_TENSORRT_DLA_ENABLE <-> trt_dla_enable
ORT_TENSORRT_DLA_CORE <-> trt_dla_core
ORT_TENSORRT_ENGINE_CACHE_ENABLE <-> trt_engine_cache_enable
ORT_TENSORRT_CACHE_PATH <-> trt_engine_cache_path
ORT_TENSORRT_DUMP_SUBGRAPHS <-> trt_dump_subgraphs
ORT_TENSORRT_FORCE_SEQUENTIAL_ENGINE_BUILD <-> trt_force_sequential_engine_build
此外,还可以通过执行提供程序选项设置 device_id。
C++ API 示例
Ort::SessionOptions session_options;
OrtTensorRTProviderOptions trt_options{};
trt_options.device_id = 1;
trt_options.trt_max_workspace_size = 2147483648;
trt_options.trt_max_partition_iterations = 10;
trt_options.trt_min_subgraph_size = 5;
trt_options.trt_fp16_enable = 1;
trt_options.trt_int8_enable = 1;
trt_options.trt_int8_use_native_calibration_table = 1;
trt_options.trt_engine_cache_enable = 1;
trt_options.trt_engine_cache_path = "/path/to/cache"
trt_options.trt_dump_subgraphs = 1;
session_options.AppendExecutionProvider_TensorRT(trt_options);
PYTHON API 示例
import onnxruntime as ort
model_path = '<path to model>'
providers = [
('TensorrtExecutionProvider', {
'device_id': 1,
'trt_max_workspace_size': 2147483648,
'trt_fp16_enable': True,
}),
('CUDAExecutionProvider', {
'device_id': 1,
'arena_extend_strategy': 'kNextPowerOfTwo',
'gpu_mem_limit': 2 * 1024 * 1024 * 1024,
'cudnn_conv_algo_search': 'EXHAUSTIVE',
'do_copy_in_default_stream': True,
})
]
sess_opt = ort.SessionOptions()
sess = ort.InferenceSession(model_path, sess_options=sess_opt, providers=providers)
Performance Tuning
有关性能调优,请参阅此页面上的指南:ONNX 运行时性能调优
当/如果使用onnxruntime_perf_test,使用标志-e tensorrt
Samples
此示例展示了如何在 TensorRT 执行提供程序上运行 Faster R-CNN 模型。
-
从这里的 ONNX 模型库下载 Faster R-CNN onnx 模型。
-
通过运行形状推断脚本推断模型中的形状
python symbolic_shape_infer.py --input /path/to/onnx/model/model.onnx --output /path/to/onnx/model/new_model.onnx --auto_merge
- 用新模型替换原来的模型,运行 ONNX Runtime build 目录下的 onnx_test_runner 工具。
./onnx_test_runner -e tensorrt /path/to/onnx/model/
Reference
https://onnxruntime.ai/docs/execution-providers/TensorRT-ExecutionProvider.html
文章出处登录后可见!