排序系列篇:

最早的关于list-wise的文章发表在Learning to Rank: From Pairwise Approach to Listwise Approach中,后面陆陆续续出了各种变形,但是也是万变不离其宗,本文梳理重在原理。
1. 为什么要List-wise loss
pairwise优缺点
优点:
- 一些已经被验证的较好的分类模型可以直接拿来用。
- 在一些特定场景下,其pairwise features 很容易就可以获得。
缺点:
- 其学习的目标是最小化文档对的分类错误,而不是最小化文档排序的错误。学习目标和实际目标(MAE,NDCG)有所违背。
- 训练过程可能是极其耗时的,因为生成的文档对样本数量可能会非常多。
那么本篇论文是如何解决这些问题呢?
在pointwise 中,我们将每一个<query, document> 作为一个训练样本来训练一个分类模型。这种方法没有考虑文档之间的顺序关系;而在pariwise 方法中考虑了同一个query 下的任意两个文档的相关性,但同样有上面已经讲过的缺点;在listwise 中,我们将一个<query,documents> 作为一个样本来训练,其中documents 为与这个query 相关的文件列表。
论文中还提出了概率分布的方法来计算listwise 的损失函数。并提出了permutation probability 和top one probability 两种方法。下面会详述这两种方法。
2. 方法介绍
2.1. loss输入格式
假设我们有m 个 querys:
每个query 下面有n 个可能与之相关的文档(对于不同的query ,其n 可能不同)
对于每个query 下的所有文档,我们可以根据具体的应用场景得到每个文档与query 的真实相关度得分。
我们可以从每一个文档对得到该文档的打分,
与文档集合
中的每个文档打分,可以得到该query 下的所有文档的特征向量:
并且在已知每个文档真实相关度得分的条件下:
我们可以构建训练样本:
要特别注意的是:这里面一个训练样本是,而这里的
是一个与query 相关的文档列表,这也是区别于pointwise 和pairwise 的一个重要特征。
关于
paper里面的相关描述:

2.2. loss计算
那么有训练样本了,如何计算loss 呢?
假设我们已经有了排序函数 f ff,我们可以计算特征向量的得分情况:
显然我们学习的目标就是,最小化真实得分和预测得分的误差:
L 为 listwise 的损失函数。
2.2.1. 概率模型
假设对于某一个query 而言,与之可能相关的文档有,假设某一种排序的结果为
对于n 个文档,有n! 种排列情况。这所有的排序情况记为。假设已有排序函数,那么对于每个文档,我们都可以计算出相关性得分
。 显然对于每一种排序情况,都是有可能发生的,但是每一种排列都有其最大似然值。
我们可以这样定义某一种排列的概率(最大似然值):
其中表示对分数的归一化处理。
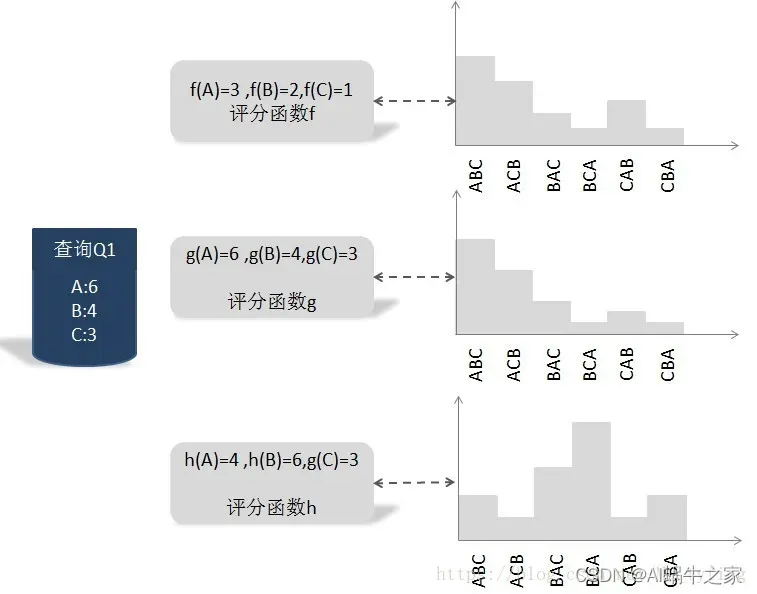
例如有三个文档 ,其排序函数计算每个文档得分为
,则该种排序概率为:
对于另外一种排序,例如 ,则这种排列概率为:
很明显,< 3,2,1 >这个排序的打分最低,< 1,2,3 >这个排序的打分最高。
2.2.2. Top K Probability
上面那种计算排列概率的方式,其计算复杂度达到,太耗时间,由此论文中提出了一种更有效率的方法 top one。我们在这里推广到top k来分析总结。
上面计算某一种排序方式概率:
排在第一位的有 种情况,排在第二位的有
种情况,后面依次类推。相当与利用 top
来计算。
那么 top 计算:
同理,这里的计算复杂度为,即为
种不同排列,大大减少了计算复杂度。
如果,就蜕变成论文中top 1 的情况,此时有 n 种不同排列情况:
对于种不同的排列情况,就有 N!/(N−k)! 个排列预测概率,就形成了一种概率分布,再由真实的相关性得分计算相应的排列概率,得到真实的排列概率分布。由此可以利用 cross−entropy 来计算两种分布的距离作为损失函数:
例如一个查询下有三个文档:
文章出处登录后可见!