论文地址:https://arxiv.org/pdf/2211.05100.pdf
相关博客
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
【自然语言处理】【ChatGPT系列】WebGPT:基于人类反馈的浏览器辅助问答
【自然语言处理】【ChatGPT系列】FLAN:微调语言模型是Zero-Shot学习器
【自然语言处理】【ChatGPT系列】ChatGPT的智能来自哪里?
【自然语言处理】【ChatGPT系列】大模型的涌现能力
一、简介
预训练语言模型已经成为了现代自然语言处理pipeline中的基石,因为其在少量的标注数据上产生更好的结果。随着ELMo、ULMFiT、GPT和BERT的开发,使用预训练模型在下游任务上微调的范式被广泛使用。随后发现预训练语言模型在没有任何额外训练的情况下任务能执行有用的任务,进一步证明了其实用性。此外,根据经验观察,语言模型的性能随着模型的增大而增加(有时是可预测的,有时是突然的),这也导致了模型规模越来越多的趋势。抛开环境的问题,训练大语言模型(LLM)的代价仅有资源丰富的组织可以负担的起。此外,直至最终,大多数LLM都没有公开发布。因此,大多数的研究社区都被排除在LLM的开发之外。这在不公开发布导致的具体后果:例如,大多数LLM主要是在英文文本上训练的。
为了解决这些问题,我们提出了BigScience Large Open-science Open-access Multilingual Language Model(BLOOM)。BLOOM是在46种自然语言和13种编程语言上训练的1760亿参数语言模型,其是由数百名研究人员合作开发和发布的。训练BLOOM的计算力是由来自于法国公共拨款的GENCI和IDRIS,利用了IDRIS的Jean Zay超级计算机。为了构建BLOOM,对于每个组件进行了详细的设计,包括训练数据、模型架构和训练目标、以及分布式学习的工程策略。我们也执行了模型容量的分析。我们的总体目标不仅是公开发布一个能够和近期开发的系统相媲美的大规模多语言的语言模型,而且还记录其开发中的协调过程。
二、BLOOM
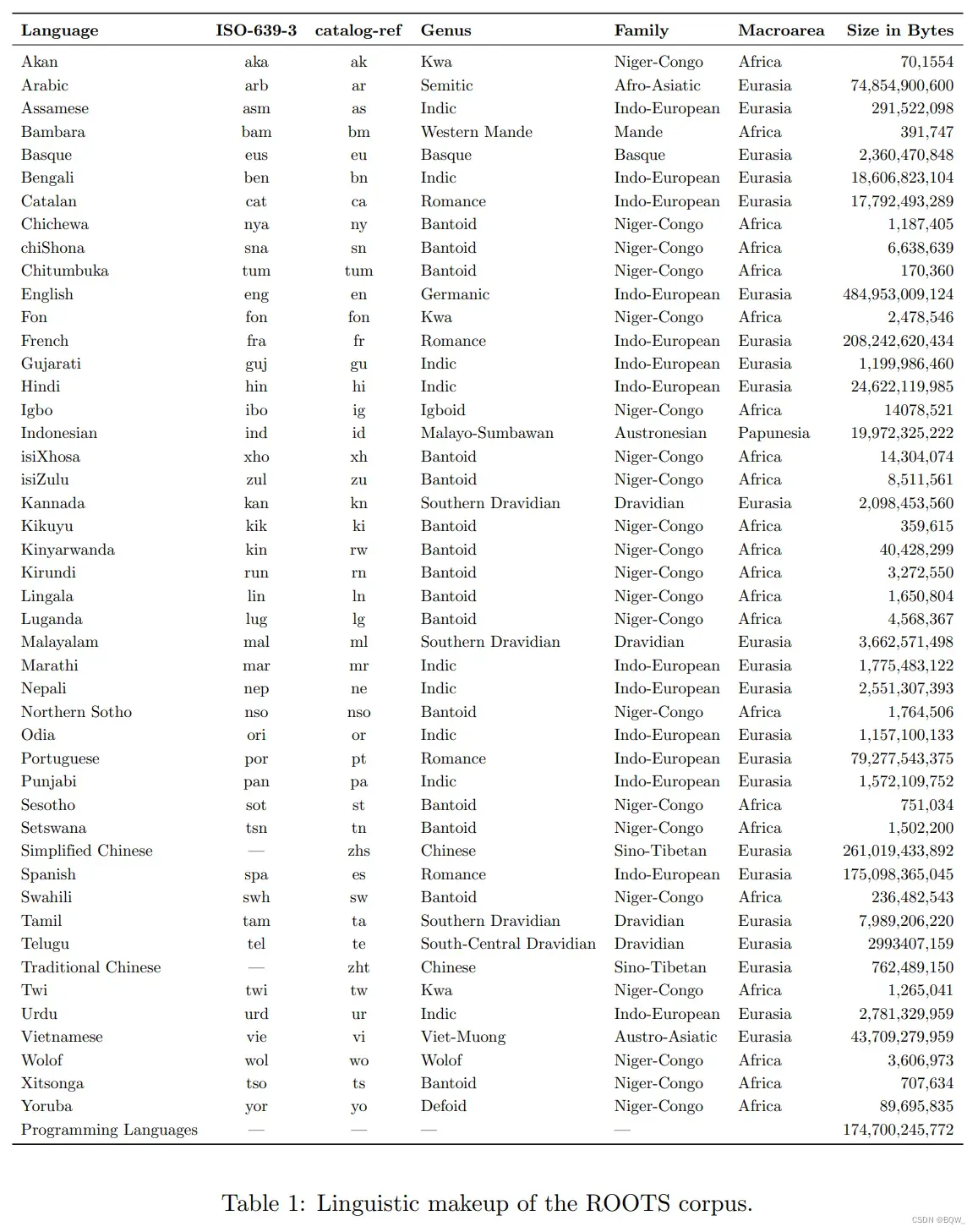
1. 训练数据
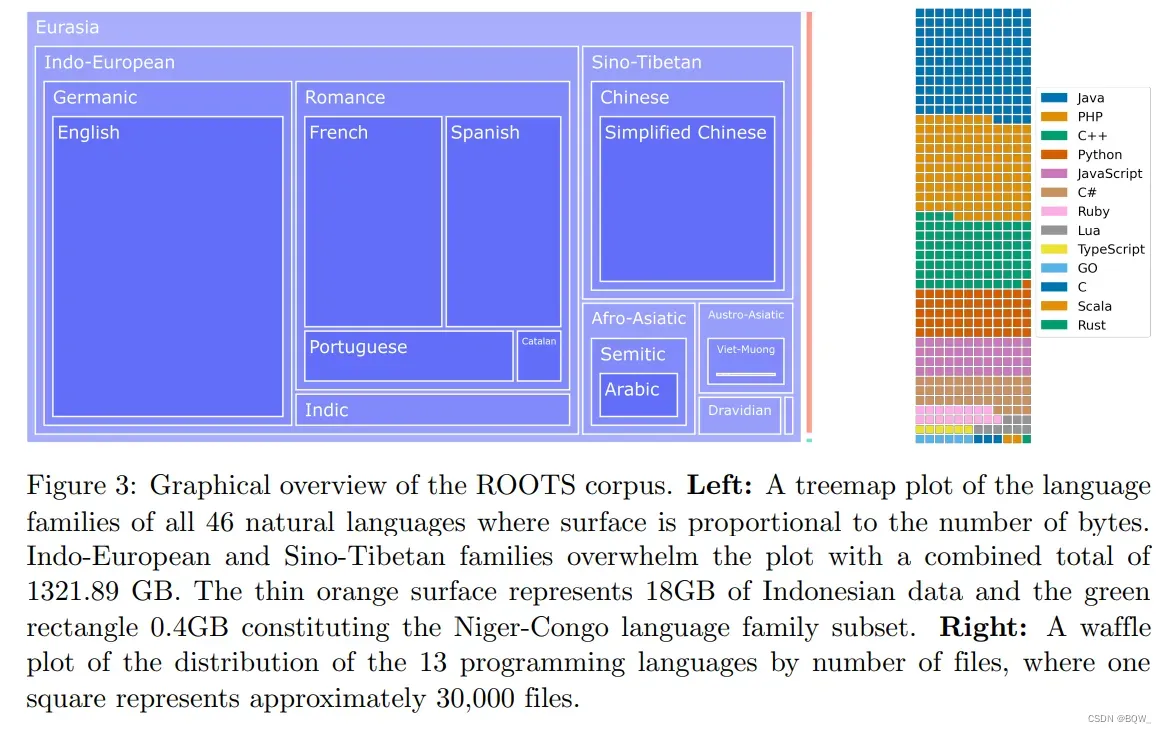
BLOOM是在一个称为ROOTS的语料上训练的,其是一个由498个Hugging Face数据集组成的语料。共计1.61TB的文本,包含46种自然语言和13种编程语言。上图3展示了该数据集的高层概览,上表1则详细列出了每种语言及其语属、语系和宏观区域。除了产生了语料库之外,该过程也带来了许多组织和技术工具的开发和发布。
1.1 数据管理
大型文本语料库是由人创建且关于人的。不同的人或者机构可以”合法”地拥有这些数据,称为这些数据的权利所有任。随着机器学习开发人员将这些数据收集并整理成为越来越大的数据集时,考虑数据相关的利益方对于开发也越来越重要,包括:开发这、数据主体和权利所有人。
BigScience旨在结合技术、法律、社会学等多学科知识来解决这些问题。该组织在两个不同时间尺度上关注两个主要的目标:设计一个长期的国际数据治理结构,该结构会优先考虑数据权利所有人,并为BigScience项目直接使用的数据提供具体建议。第一个目标的进展在Jernite et al.工作中展示,其进一步激发了数据管理的需求,并描述了一个由数据托管人、权利所有人和其他参与方组成的网络。这些参与者的交互旨在考虑数据和算法上的隐私、知识产权和用户权利。特别地,这种方法依赖于数据提供者和数据主机之间的结构化协议,从而指定数据的用途。
虽然无法在项目开始到模型训练这相对短暂时间内建立一个完整的国际组织,但是我们也努力从这个过程中吸取了经验教训:(1) BigScience会尽量从数据提供者那里获得明确的数据使用许可;(2) 在预处理的最终阶段之前,保持单源独立并维护其可追溯性。(3) 对构成整个语料库的各个数据源采用一种组合发布的方式,从而促进可复用性和后续的研究。在Hugging Face的组织”BigScience Data”中可以访问并可视化ROOTS语料库资源。
1.2 数据源
确定了数据管理策略,接下来就是决定训练语言的构成。本阶段由若干个目标驱动,这些目标有着内在的冲突。这些内存的冲突包括:构建一个使世界上尽可能多的人可以访问的语言模型,同时也需要有足够知识来管理与先前规模相当数据集的语言来改善标准文档,以及遵循数据和算法的主体权利。
-
语言的选择
基于这些考虑,我们采用渐进的方式来选择语料库中包含的语言。首先列出8个世界上使用人数最多的语言,在项目早期积极推广这些语言并邀请该语言的流利使用者加入项目。然后,根据社区的建议将原始选择中的Swahili扩展至Niger-Congo语言类别,Hindi和Urdu扩展至Indic languages。最终,我们提出若某个语言有多于3个流利语言使用者参与,则可以添加至支持列表。
-
源的选择
语料库的最大部分是由研讨会参与者和研究团队策划的,他们共同编写了”BigScience Catalogue”:涵盖了各种处理后或者未处理的语言列表。这采用了由Machine Learning Tokyo、Masakhane和LatinX in AI等社区所组织的hackathons形式。作为这些源的补充,其他的工作组参与者编译了特定语言的资源,例如Arabic-focused Masader repository。这种自下而上的方法共确定了252个源,每种语言至少有21个源。此外,为了增加西班牙语、中文、法语和英语资源的地理覆盖范围,参与者通过pseudocrawl确定了被添加至语料中语言的本地相关网址。
-
GitHub代码
通过Google’s BigQuer上的GitHub数据集合来进一步补充该目录中的编程语言数据集,然后使用精准匹配进行去重。
-
OSCAR
为了不偏离使用网页作为预训练数据源的标准研究,并且满足BLOOM尺寸计算代价的数据量需求,我们进一步使用版本为21.09的OSCAR作为数据源,对应于2021年2月的Common Crawl快照,其占用了最终语料的38%。
1.3 数据预处理
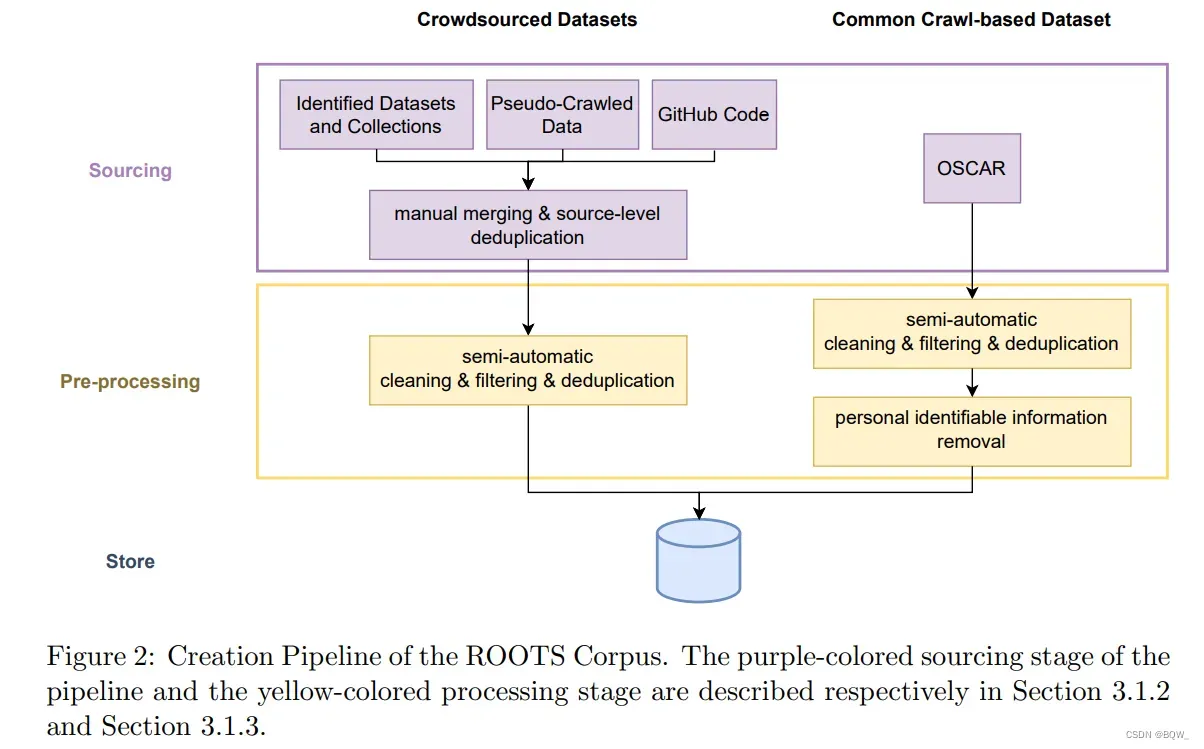
在确定了数据源之后,数据处理涉及多个数据管理的步骤。上图2可以看到构建ROOTS的pipeline总体视图。在这个过程中开发的所有工具都可以在GitHub上找到。
-
获得源数据
第一步涉及到从确定的数据源中获得文本数据,这包含从各种格式的NLP数据集中下载和提取文本字段、从档案中抓取和处理大量的PDF文件、从目录中的192个网站条目和数据工作组成员选择的另一些地理上不同的456个网站中提取和预处理文本。后者需要开发新工具来从Common Crawl WARC文件中的HTML中抽取文本。我们能够从539个网络的所有URL中找到并提取可用的数据。
-
质量过滤
在获得文本后,我们发现大多数源中包含了大量的非自然语言,例如预处理错误、SEO页面或者垃圾。为了过滤非自然语言,我们定义了一组质量指标,其中高质量文本被定义为“由人类为人类编写的”,不区分内容或者语法的先验判断。重要的是,这些指标以两种主要的方法来适应每个源的需求。首先,它们的参数,例如阈值和支持项列表是由每个语言的流利使用者单独选择的。第二、我们首先检测每个独立的源来确定哪些指标最有可能确定出非自然语言。这两个过程都是由工具进行支持来可视化影响。
-
去重和隐私编辑
最终,我们使用两种重复步骤来移除几乎重复的文档,并编辑了从OSCAR语料中确定出的个人身份信息。因为其被认为是最高隐私风险的来源,这促使我们使用基于正则表达式的编辑,即使表达式有一些假阳性的问题。
1.4 Prompted数据集
多任务提示微调(也称为instruction tuning)涉及到对预训练语言模型的微调,微调的数据集由通过自然语言提示构成的大量不同任务组成。T0证明了在多任务混合的prompted数据集上微调的模型具有强大的zero-shot泛化能力。此外,T0优于那些数量级大但是没有经过这种微调的语言模型。受这些结果启发,我们探索了使用现有自然语言数据集来进行多任务prompted微调。
T0是在Public Pool of Prompt(P3)子集上进行训练的,其是一个各种现有的、开源的应用自然语言数据集的prompt集合。该prompt集合是通过BigScience合作者参与的一系列黑客马拉松创建的,其中黑客马拉松参与者为170+数据集编写了2000+的prompt。P3中的数据集覆盖了各种自然语言任务,包括情感分析、问答、自然语言推理,并且排除了有害的内容或者非自然语言。PromptSource,一个开源工具包促进了自然语言prompt的创建、共享和使用。
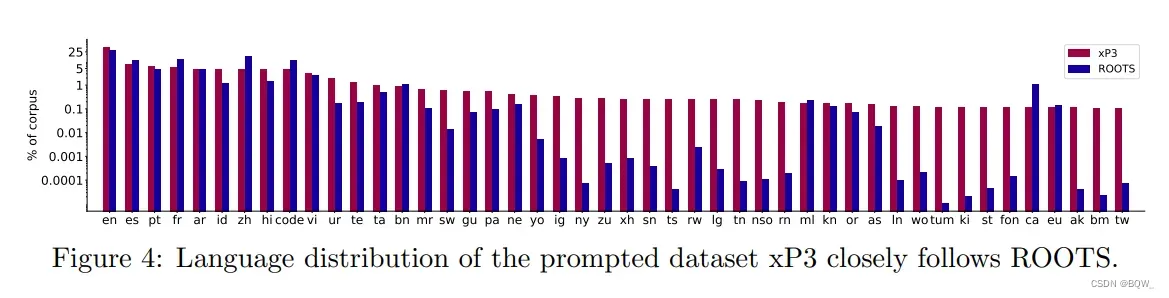
对BLOOM预训练之后,我们应用相同的大规模多任务微调,使BLOOM具有多语言zero-shot任务泛化能力。我们称得到的模型为BLOOMZ。为了训练BLOOMZ,我们扩展了P3来包含非英语中新数据集和新任务,例如翻译。这产生了xP3,它是83个数据集的提升集合,覆盖46种语言和16中任务。正如上图4所述,xP3反映了ROOTS的语言分布。xP3中的任务包含跨语言和单语言。我们使用PromptSource来收集这些prompts,为prompt添加额外的元数据,例如输入和目标语言。为了研究多语言prompt的重要性,我们还将xP3中的英语提示用机器翻译为相应的数据集语言,来生成一个称为xP3mt的集合。
2. 模型架构
2.1 设计方法
架构设计的选择空间非常大,不可能完全探索。一种选择是完全复制现有大模型的架构。另一方面,大量改进现有架构的工作很少被采纳,采用一些推荐的实践可以产生一个更好的模型。我们采用中间立场,选择已经被证明了可扩展性良好的模型家族,以及在公开可用的工具和代码库中合理支持的模型家族。我们针对模型的组件和超参数进行了消融实验,寻求最大限度的利用我们最终的计算预算。
-
消融实验设计
LLM的主要吸引力是其以”zero/few-shot”的方式执行任务的能力:足够大的模型可以简单的从in-context指令和例子执行新的任务,不需要在监督样本上训练。由于对100B+模型微调很麻烦,我们评估架构决策专注在zero-shot泛化能力上,并且不考虑迁移学习。具体来说,我们衡量了不同任务集合的zero-shot表现:29个任务来自于EleutherAI Language Model Evaluation Harness(EAI-Eval),9个任务来自T0的验证集(T0-Eval)。两者之间有很大的重叠:T0-Eval中仅有一个任务是不在EAI-Eval,尽管两者的所有prompt都不同。
此外,也使用更小的模型进行了消融实验。使用6.7B模型对预训练目标进行消融实验,使用1.3B模型对位置嵌入、激活函数和layer normalization进行消融实验。近期,Dettmers在大于6.7B的模型上发现了相变,观察到了”异常特征”出现。那么在1.3B规模上是否能够外推自最终模型尺寸上?
-
超出范围的架构
我们没有考虑mixture-of-experts(MoE),因为缺乏适合大规模训练它的广泛使用的基于GPU的代码库。类似地,我们也没有考虑state-space模型。在设计BLOOM时,它们在自然语言任务中一种表现不佳。这两种方法都很有前景,现在证明了在大规模MoE上有竞争力的结果,并在较小规模上使用具有H3的state-space模型。
2.2 架构和预训练目标
虽然大多数现代语言模型都是基于Transformer架构,但是架构实现之间存在着显著的不同。显然,原始的Transformer是基于encoder-decoder架构的,许多流行的模型仅选择encoder-only或者decoder-only方法。当前,所有超过100B参数的state-of-the-art模型都是decoder-only模型。这与Raffel等人的发现相反,在迁移学习方面encoder-decoder模型显著优于decoder-only模型。
在我们工作之前,文献缺乏不同架构和预训练目标的系统性评估zero-shot泛化能力。我们在Wang et al.(2022a)等人的工作中探索了这个问题,其探索了encoder-decoder和decoder-only架构以及与causal、prefix和masked language modeling预训练模型的相互作用。我们的结果显示,经过预训练之后,causal decoder-only模型的表现最好,验证了state-of-the-art LLM的选择。
2.3 建模细节
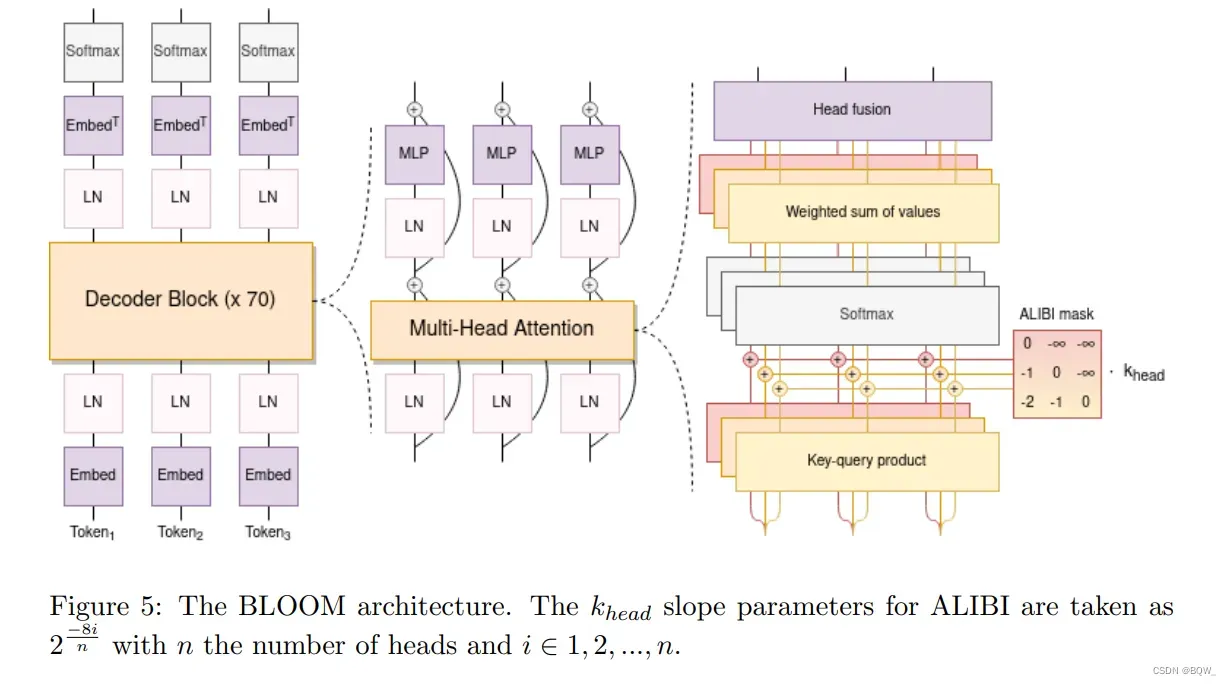
在选择架构和预训练目标之外,对原始Transformer架构提出了许多的更改。例如,可选的位置嵌入方案或者新颖的激活函数。我们执行了一系列的实验来评估每个修改,在Le Scao et al.的causal decoder-only模型上。我们在BLOOM中采用了两种变化:
-
ALiBi位置嵌入
相比于在embedding层添加位置信息,ALiBi直接基于keys和queries的距离来衰减注意力分数。虽然ALiBi的最初动机是它能够外推至更长的序列,我们发现其在原始序列长度上也能够带来更平衡的训练以及更好的下游表现,超越了可学习embeddings和旋转embeddings。
-
Embedding LayerNorm
在训练104B参数模型的初步试验中,我们尝试在嵌入层后立即进行layer normalization,正如bitsandbytes库及其StableEmbedding层所推荐的那样。我们发现这可以显著的改善训练稳定性。尽管我们在
Le Scao et al.工作中发现其对zero-shot泛化有惩罚,但我们还是在BLOOM的第一个embedding层后添加了额外的layer normalization层来避免训练不稳定性。注意初步的104B实验中使用float16,而最终的训练上使用bfloat16。因为float16一直被认为是训练LLM时观察的许多不稳定的原因。bfloat16有可能缓解对embedding LayerNorm的需要。上图5中展示了BLOOM的全部架构。
3. Tokenization
tokenizer的设计选择通常被忽略,倾向于”默认”设置。举例来说,OPT和GPT-3都使用GPT-2的tokenizer,训练用于English。由于BLOOM训练数据的多样性本质,需要谨慎的设计选择来确保tokenizer以无损的方式来编码句子。
3.1 验证
我们将本文使用的tokenizer(Acs,2019)与现有的单语言tokenizer进行比较,作为完整性检测的指标。Fertility被定义为每个单词或者每个数据集被tokenizer创造的subword数量,我们使用感兴趣语言的Universal Dependencies 2.9和OSCAR子集来衡量。在一个语言上有非常高的Fertility相比于单语言tokenizer可能表明在下游多语言上的性能下降。我们的目标是在将我们的多语言tokenizer与对应但语言tokenizer进行比较时,确保每种语言的fertility能力较低不超过10个百分点。在所有的实验中,Hugging Face Tokenizers库被用来设计和训练测试的tokenizers。
3.2 tokenizer训练数据
我们最初使用ROOTS的非重复子集。然而,一项在tokenizer的词表上的定性研究揭示了训练数据的问题。例如,在早期版本的tokenizer上,我们发现完整URLs存储为tokens,这是由几个包含大量重复的文档导致的。这个问题促使我们移除tokenizer训练数据中的重复行。
3.3 词表大小
大的词表尺寸能够降低过度分割某些句子的风险,特别是对低资源语言。我们使用150k和250k词表尺寸来执行验证实验,以便与现有的多语言建模文献进行比较。与单语言tokenizer相比,我们最终确定的词表尺寸是250k tokens来达到最初的fertility目标。因为,词表尺寸决定了embedding矩阵的尺寸,为了GPU效率embedding尺寸必须被128整除,为了使用张量并行必须被4整除。我们最终使用了250680词表尺寸,具有200个为未来应用保留的token,例如使用占位token剔除私有信息。
3.4 Byte-level BPE
tokenizer是一个使用Byte Pair Encoding(BPE)算法进行训练的、可学习的子词tokenzier。为了在tokenization的过程中不丢失信息,tokenizer从bytes开始创建合并,而不是以字符作为最小单位。这种方式,tokenization永远不会产生未知的tokens,因为所有256个字节都可以被包含在tokenizer的词表中。此外,Byte-level BPE最大化了语言之间的词表共享。
3.5 规范化
在BPE算法上游,为了尽可能地获得最通用的模型,没有对文本进行规范化。在所有情况下,添加诸如NFKC这样的unicode规范化并不能减少fertility超过0.8%,但是代价是使模型不那么通用。例如,导致和22以相同方法被编码。
3.6 Pre-tokenizer
我们的pre-tokenization有两个目标:产生文本的第一个划分,并且限制由BPE算法产生的令牌序列的最大长度。pre-tokenization规模使用的是下面的正则表达式:?[^(\S|[.,!?...。,、|_])]+,其将单词分开同时保留所有的字符,特别是对编程语言至关重要的空格和换行符序列。我们不使用在其他tokenizers中常见的以英文为中心的划分。我们也没有在数字上使用划分,这导致了Arabic和code的问题。
4. 工程
4.1 硬件
模型在Jean Zay上训练,其是由法国政府资助的超级计算机,归属于GENCI所有,由法国国家科学研究中心(CNRS)的国家计算中心IDRIS运行。训练BLOOM花费了3.5个月才完成,并消耗了1082990计算小时。在48个节点上进行训练,每个有8 NVIDIA A100 80GB GPUs(总共384个GPUs);由于在训练过程中硬件可能损坏,我们也保留了4个备用节点。这些节点装备了2x AMD EPYC 7543 32-Core CPUs和512 GB的RAM,而存储采用混合全闪存和硬盘驱动的SpectrumScale(GPFS)并行文件系统。
4.2 框架
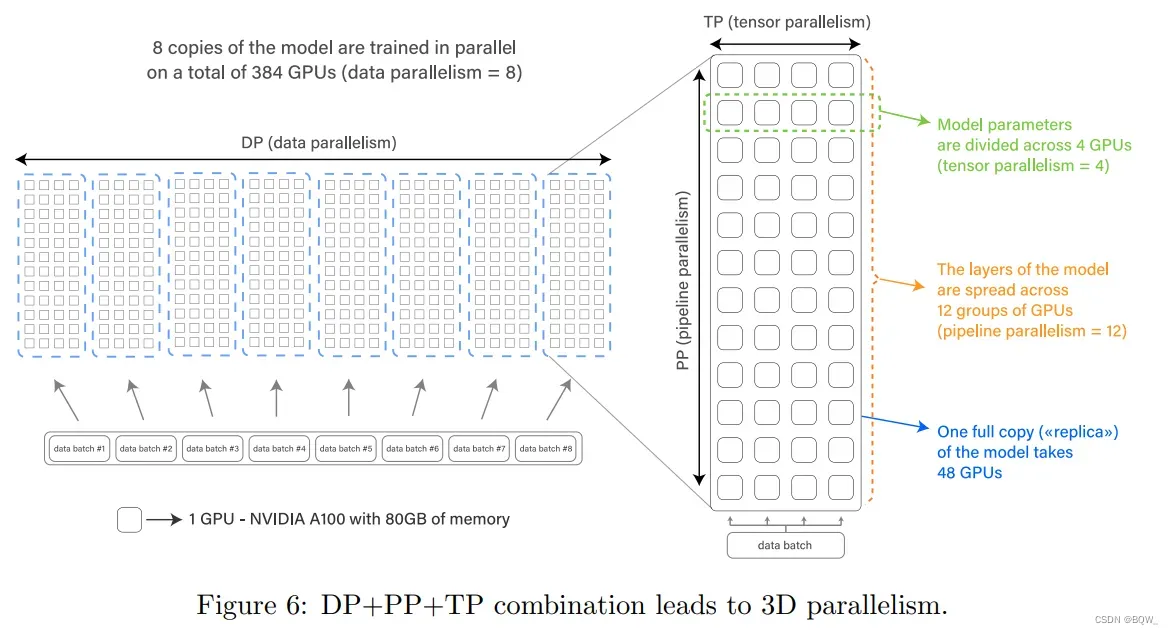
BLOOM使用Megatron-DeepSpeed训练,一个用于大规模分布式训练的框架。其由两部分组成:Megatron-LM提供Transformer实现、张量并行和数据加载原语,而DeepSpeed提供ZeRO优化器、模型流水线、通过分布式训练组件。这个框架允许我们使用3D并行来高效训练—融合了三种互补的分布式深度学习方法。这些方法描述如下:
-
数据并行(Data parallelism, DP)
复制多份模型,每个副本被放置在不同设备上,并输入数据分片。该过程是并行完成的,所有模型副本在每个训练step结束时同步。
-
张量并行(Tensor parallelism, TP)
跨多个设备来划分模型的独立层。这种方式,我们不把整个激活张量或者梯度张量放在单个GPU上,而是把这个张量的碎片放在单个GPU上。该技术有时被称为水平并行或者层内模型并行。
-
流水线并行(Pipeline parallelism, PP)
在多个GPU上划分模型的层,每个GPU仅放置模型层的一小部分。这有时也称为垂直并行。
最终,Zero Redundancy Optimizer(ZeRO)运行不同的进程仅持有部分数据(参数、梯度和优化器状态)以及一个训练step所需要的数据。我们使用ZeRO stage 1,意味着仅优化器状态以这种方法进行分片。
上面描述的四个组件组合在一起,可以扩展至数百个GPU,具有极高的GPU利用率。我们能在A100 GPU的最快配置下实现156 TFLOPs,实现了理论峰值312 TFLOPs的一半。
4.3 浮点数格式
在初步的实验中,104B参数模型在NVIDIA V100 GPUs,我们观察到数值不稳定,导致不可逆的训练发散。我们假设这些不稳定来自于最初使用的IEEE float16,动态范围非常有限的16-bit浮点数格式,可能导致溢出。我们最终获得了支持bfloat16格式的权限,其具有同float32相同的动态范围。另一方面,bfloat16精度仍然低很多,这促使我们使用混合精度训练。该技术在float32精度上执行精度敏感的操作,例如梯度累积和softmax,余下的操作则使用低精度,这允许实现高表现和训练稳定性之间的平衡。最终,我们以bfloat16混合精度执行最终的训练,其被证明解决了训练不稳定的问题。
4.4 融合CUDA核
一般来说,GPU无法在检索数据同时执行这些计算。此外,现代GPU的计算性能远远高于每个操作(被称为GPU编程中的核)所需的内存传输速度。核融合是一种基于GPU计算的优化方法,通过在一次内核调用中执行多个连续操作。该方法提供了一种最小化数据传输的方法:中间结果留在GPU寄存器中,而不是复制到VRAM,从而节省开销。
我们使用了Megatron-LM提供了几个定制化融合CUDA核。首先,我们使用一个优化核来执行LayerNorm,以及用核来融合各种缩放、掩码和softmax操作的各种组合。使用Pytorch的JIT功能将一个偏差项添加至GeLU激活中。作为一个使用融合核的例子,在GeLU操作中添加偏差项不会增加额外的时间,因为该操作受内存限制:与GPU VRAM和寄存器之间的数据传输相比,额外的计算可以忽略不计。因此融合这两个操作基本上减少了它们的运行时间。
4.5 额外的挑战
扩展至384个GPU需要两个修改:禁止异步CUDA内核启动(为了方便调试和防止死锁),并将参数组划分至更小的子组(以避免过多的CPU内存分配)。
在训练过程中,我们面临硬件故障的问题:平均来说,每周有1-2个GPU故障。由于备份节点可用并自动使用,并且每三个小时保存一次checkpoint,因此这不会显著影响训练吞吐量。在数据loader中Pytorch死锁bug和磁盘空间故障会导致5-10h的停机时间。考虑到工程问题相对稀疏,而且由于只有一次损失峰值,该模型很快就恢复了,因此人工干预的必要性低于类似项目。
5. 训练
-
预训练模型
我们使用上表3中详细描述的超参数来训练BLOOM的6个尺寸变体。架构和超参数来自于我们的实验结果(Le Scao et al.)和先前的训练大语言模型(Brown et al.)。非176B模型的深度和宽度大致遵循先前的文献(Brown et al.),偏离的3B和7.1B只是为了更容易适合我们训练设置。由于更大的多语言词表,BLOOM的embedding参数尺寸更大。在开发104B参数模型的过程中,我们使用了不同的Adam
参数、权重衰减和梯度裁剪来对目标稳定性进行实验,但没有发现其有帮助。对于所有模型,我们在410B tokens使用cosine学习率衰减调度,在计算允许的情况下,将其作为训练长度的上限,并对375M tokens进行warmup。我们使用权重衰减、梯度裁剪,不使用dropout。ROOTS数据集包含341B tokens的文本。然而,基于训练期间发布的修订scaling laws,我们决定在重复数据上对大模型进行额外25B tokens的训练。由于warmup tokens + decay tokens大于总的token数量,所以学习率衰减始终未达到终点。
-
多任务微调
微调的BLOOMZ模型维持了与BLOOM模型相同架构超参数。微调的超参数大致基于T0和FLAN。学习率则是将对应预训练模型的最小学习率加倍,然后再四舍五入。对于较小的变体,全局batch size乘以4来增加吞吐量。模型在13B tokens上进行微调,最优checkpoint根据独立的验证集选择。经过1-6B tokens微调后,性能趋于平稳。
-
对比微调
我们还使用了SGPT Bi-Encoder方案对1.3B和7.1B参数的BLOOM模型进行对比微调,以训练产生高质量文本嵌入的模型。我们创建了用于多语言信息检索的SGPT-BLOOM-1.7B-msmarco,以及用于多语言语义相似度的SGPT-BLOOM-1.7B-nli。然而,近期的基准测试发现,这种模型也能够推广到各种其他的嵌入任务,例如bitext挖掘、重排或者下游分类的特征抽取。
6. 发布
开放性是BLOOM开发的核心,并且我们希望确保社区可以轻易的使用它。
6.1 Model Card
遵循发布机器学习模型的最优实践,BLOOM模型连同详细的Model Card一起发布,其描述了技术规范、训练细节、预期用途、范围外用途和模型的局限。跨工作组的参与者共同来产生最终的Model Card和每个checkpoint的card。
6.2 Licensing
考虑到BLOOM可能带来的潜在有害用例,我选择了不受限制的开发访问和负责任的使用之间取得平衡,包括行为使用准则来限制模型对潜在有害用例的应用。这些条款通常被包含在”Responsible AI Licenses(RAIL)“,社区在发布模型时所采用的Licenses。与BLOOM开始时采用的RAIL license显著区别是,它分离了”源代码”和”模型”。它还包括了模型的”使用”和“派生工作”的详细定义,来确保明确识别通过prompting、微调、蒸馏、logits使用和概率分布的下游使用。该license包含13项行为使用限制,这些限制根据BLOOM Model Card描述的预期用途和限制,以及BigScience道德章程来确定。该license免费提供模型,用户只要遵守条款,就可以自由使用模型。BLOOM的源代码已经在Apache 2.0开源许可证下提供访问。
三、评估
评估主要专注在zero-shot和few-shot设置。我们的目标是呈现出BLOOM与现有LLMs相比的准确图景。由于这些模型的规模,基于prompt的方法和few-shot “in-context learning”要比微调更加常见。
1. 实验设计
1.1 Prompts

基于最近关于prompt对于语言模型性能影响的研究,我们决定建立一个语言模型评估套件,该套件允许我们改变基础任务数据,以及用于“上下文”化任务的prompting。我们的prompt是先于BLOOM发布开发的,没有使用模型进行任何先验改进。我们以这种方式设计prompt的目的是,模拟新用户期望BLOOM的zero-shot或者one-shot结果。
我们使用promptsource来为每个任务生成多个prompt。我们遵循Sanh et al.(2022)使用的流程,prompt是由众包生成的,因此能够看到prompt的不同长度和风格。为了提升质量和明确性,对每个prompt执行多个同行评审。
上表5展示了一些用于WMT’14任务的最终prompt。由于资源限制,我们还为许多没有包含在本文中的任务生成prompt。所有任务的所有prompt都可以公开访问。
1.2 基础设施
我们的框架通过集成promptsource库来扩展EleutherAI’s Language Model Evaluation Harness。我们发布了Prompted Language Model Evaluation Harness作为开源库供人们使用。我们使用这个框架来运行实验和聚合结果。
1.3 数据集
-
SuperGLUE
我们使用SuperGLUE分类任务评估套件的子集,特别是:Ax-b、Ax-g、BoolQ、CB、WiC、WSC和RTE任务。我们排除了余下的任务,因为它们需要的计算量比我们所考虑的所有任务加起来还多一个量级。这些任务是纯英文的,主要是为了方便与先前的工作比较。我们也注意到,这些任务上使用zero-shot和one-shot prompted设置的性能没有被广泛报告。T0的第一个例外,但是模型是instruction-tuned,因此不能直接和BLOOM以及OPT进行比较。对于每个任务,我们从promptsource中随机挑选5个样本,然后在prompt集合上评估所有的模型。
-
Machine Translation(MT)
我们在三个数据集上评估BLOOM:WMT14
和
、Flores-101和DiaBLa。我们使用BLEU实现的sacrebleu进行评估。在生成过程使用贪心解码,直至EOS token,对于1-shot则添加 \n###\n。
-
Summarization
我们在WikiLingua数据集上评估摘要。WikiLingua是多语言摘要数据集,由WikiHow文章和逐步的摘要对。与BLOOM尺寸相当的模型通常没有报告one-shot条件自然语言生成。PaLM是第一个例外,其报告了WikiLingua;然而,仅考察了模型的英文摘要能力。作为对比,我们通过评估源语言的抽象摘要来测试BLOOM的多语言能力。我们专注在9种语言(阿拉伯语、英语、西班牙语、法语、印地语、葡萄牙语、越南语和中文),这些都是BigScience的目标。
1.4 Baseline模型
- mGPT:在60种语言上训练的GPT风格的模型;
- GPT-Neo、GPT-J-6B、GPT-NeoX:在Pile上训练的GPT风格模型族;
- T0:在P3数据集上经过多任务promoted微调的T5变体;
- OPT:一个GPT风格模型,在混合数据集上训练;
- XGLM:在CC100变体上训练的GPT风格多语言模型;
- M2M:在Wikipedia和mC4上使用masked和causal目标函数训练的encoder-decoder模型;
- mTk-Instruct:在Super-NaturalInstructions数据集上进行多任务prompted微调的T5变体;
- Codex:在来自GitHub的代码上微调的GPT模型;
- GPT-fr:在法语文本上训练的GPT风格模型;
2. Zero-Shot效果
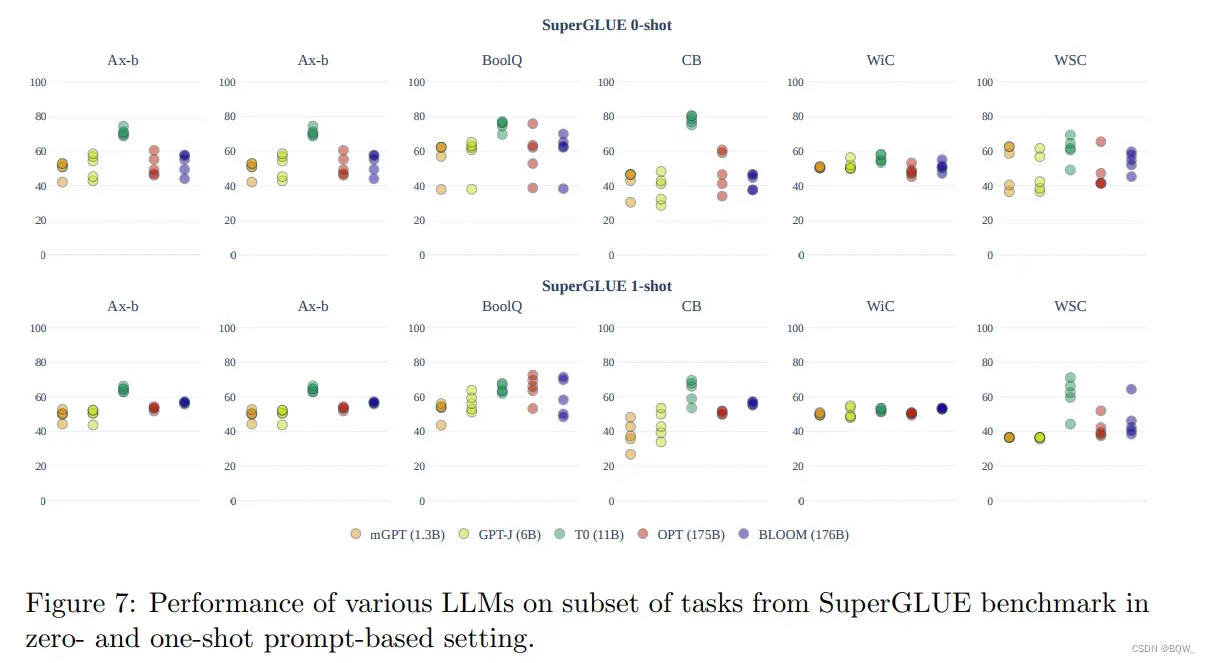
在自然语言理解和生成任务中,我们发现预训练语言模型的zero-shot性能都接近随机。上图7展示了zero-shot的性能。
2.1 SuperGLUE
在SuperGLUE上,虽然在一些独立的prompt上展示了大概10个点的性能改善,但是各个prompt的平均改善接近随机。除了T0模型,其展现出很强的效果。然而,这个模型是在多任务设置中微调的,为了改善zero-shot prompting的效果。
2.2 机器翻译
在zero-shot设置中,机器翻译的结果非常糟糕。生成结果有两个主要的问题:(1) 过度生成;(2) 不能够产生正确的语言。
3. One-Shot结果
3.1 SuperGLUE
上图7展示也展示了one-shot的效果。相比于zero-shot的效果,所有prompt和模型在SuperGLUE上one-shot效果变异性降低了。总的来说,one-shot的设置下并没有显著的改善:模型的精度仍然是接近随机的。我们对不同模型尺寸的BLOOM进行额外的分析。作为baseline,我们还衡量了相似大小OPT模型的one-shot准确率。OPT和BLOOM模型族随规模轻微改善。BLOOM-176B在Ax-B、CB和WiC上优于OPT-175B。
3.2 机器翻译
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-BL4WvdO9-1675687454712)(.\图\BLOOM_T8.png)]](https://aitechtogether.com/wp-content/uploads/2023/04/760c54a3-9ee7-4eea-998b-833dd100b9a2.webp)
在1-shot设置中,我们使用XGLM prompt在Flores-101开发测试集上测试集中语言方向。我们从相同数据集中随机选择1-shot样本,这可能与过去的工作不同。我们按照高资源语言对、高至中资源语言对、低资源语言对以及Romance语言族分离不同的结果。根据语言在ROOTS中比例,将语言分类为低、中、高资源。对于高资源和中高资源语言对,我们与具有615M参数的M2M-124模型的监督结果进行比较。此外,我们比较了XGLM(7.5B) 1-shot结果和32-shot AlexaTM结果。**对于高资源语言翻译以及高资源语言至中资源语言的翻译,结果都不错。**这表明BLOOM具有良好的多语言能力。相比于监督的M2M模型,在1-shot设置中通常结果相当甚至更好,在许多情况下结果与AlexaTM相当。
**许多低资源语言的翻译质量都很好,与监督M2M模型相当甚至更好。**然而,在Swahili和Yoruba之间的效果相当糟糕,因为在BLOOM训练数据中存在不足。
3.3 摘要
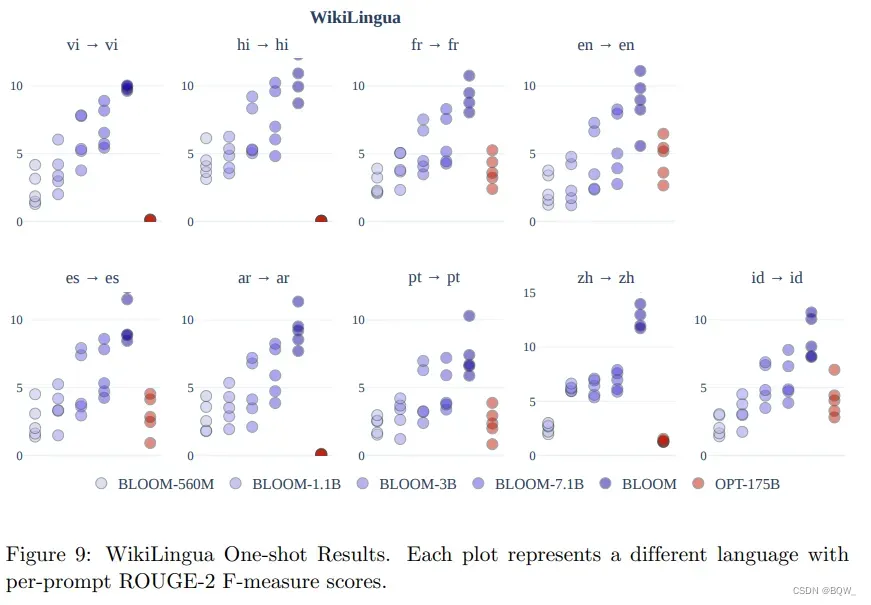
上图9展示了BLOOM和OPT-175B的one-shot结果比较。每个点表示一个pre-prompt分数。关键结论是,BLOOM在多语言摘要方面比OPT获得了更高的性能,并且随着模型参数增加而性能增加。我们怀疑这是由于BLOOM的多语言训练。
4. 多任务微调
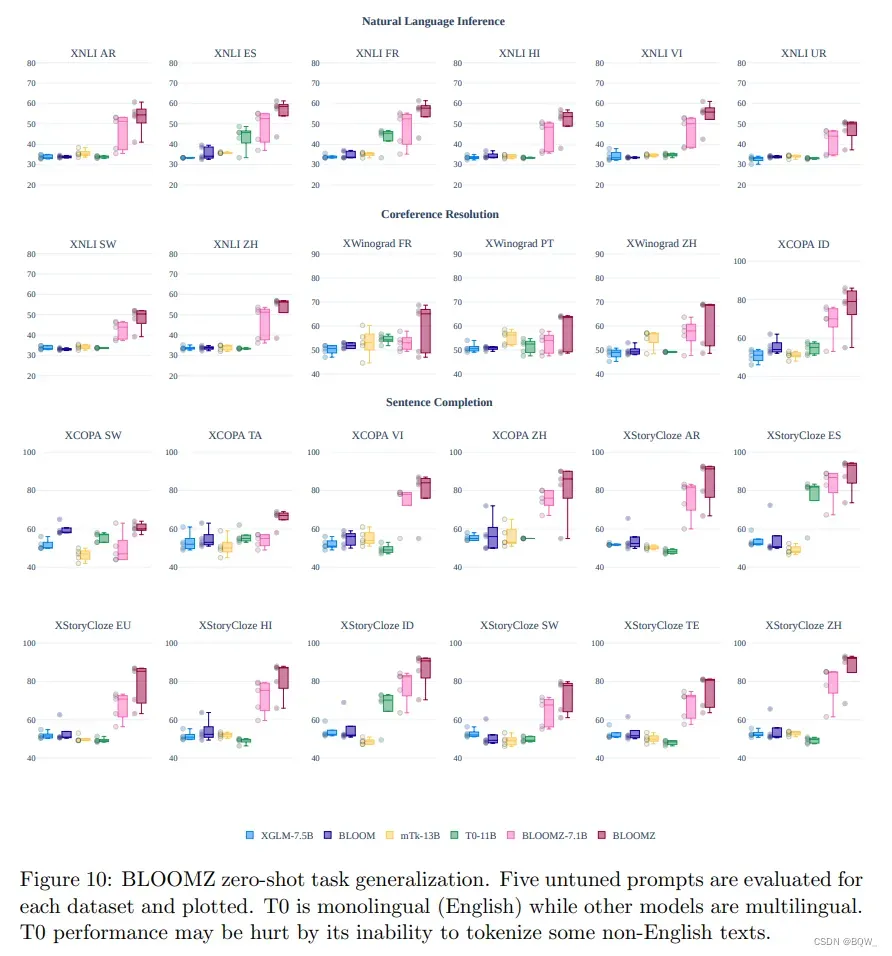
基于最近在多任务微调上的工作,我们探索使用多语言多任务微调来改善BLOOM模型的zero-shot效果。我们使用xP3语料来在BLOOM上执行多语言多任务微调。我们发现zero-shot表现的能力显著增强。上图10,我们比较了BLOOM和XLGM模型与多任务微调BLOOMZ、T0和mTk-Instruct的zero-shot效果。BLOOM和XGLM的表现解决随机基线。经过多语言多任务微调(BLOOMZ),zero-shot的效果显著改善。尽管在多任务上进行了微调,由于T0是单语言英语模型,它在多语言数据集上表现很差。然而,由Muennighoff et al.提供的额外结果表明,当控制大小和架构,在xP3的英文数据集上微调的模型仍然优于T0。这可以是由于T0微调的数据集(P3)包含的数据集和prompt的多样性低于xP3。
5. 代码生成
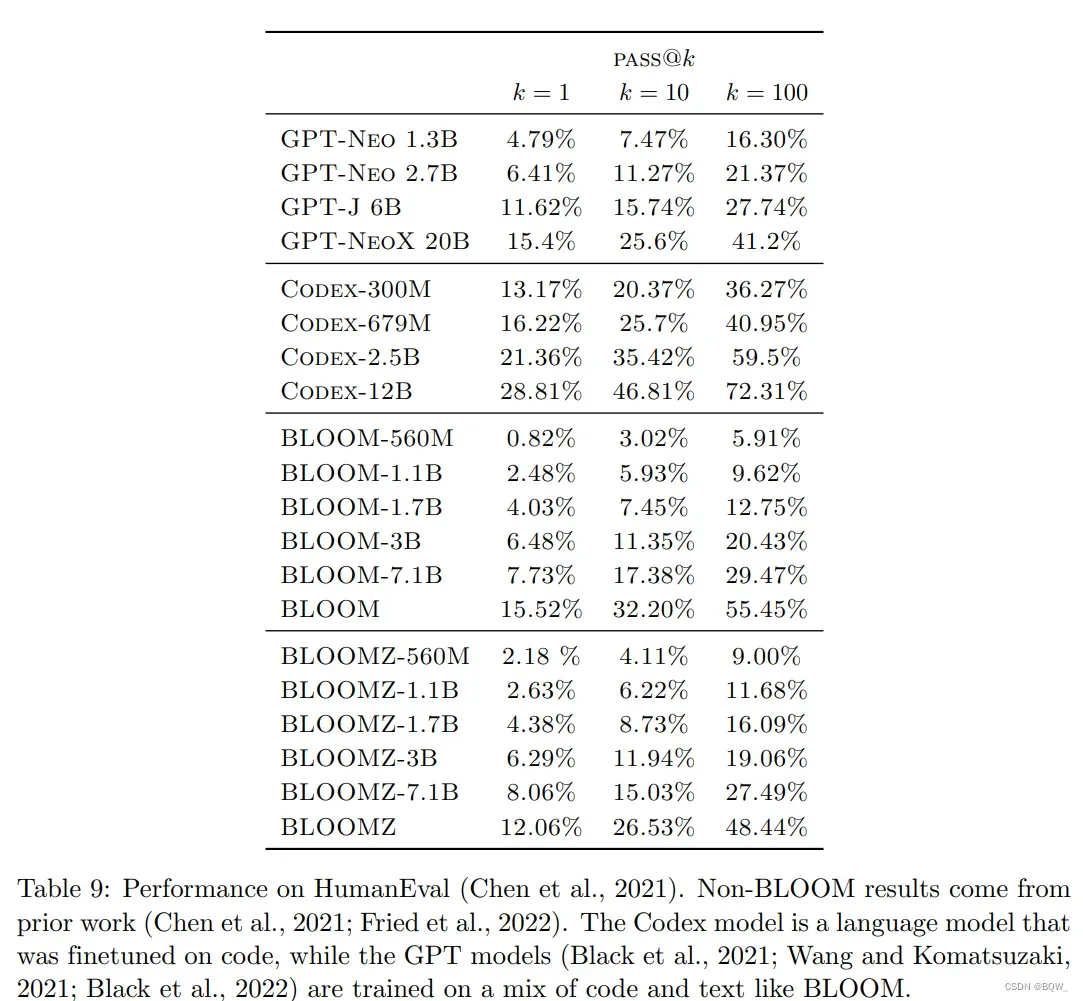
BLOOM预训练语料ROOTS包含大约11%的代码。上表9,展示了BLOOM在HumanEval上基准结果。我们发现预训练的BLOOM的效果与在Pile上训练的类似大小的GPT模型。Pile包含英文数据和大约13%的代码,这类似于ROOTS中的代码数据源和比例。Codex模型,其单独在代码上进行微调,比其他的模型强的多。相比于BLOOM模型,多任务微调的BLOOMZ模型并没有显著改善。我们假设这是因为微调数据集xP3并没有包含大量的纯代码。
文章出处登录后可见!