本文介绍基于Python语言,遍历文件夹并从中找到文件名称符合我们需求的多个.txt格式文本文件,并从上述每一个文本文件中,找到我们需要的指定数据,最后得到所有文本文件中我们需要的数据的合集的方法。
首先,我们来明确一下本文的具体需求。现有一个文件夹,其中含有大量的.txt格式文本文件,如下图所示;同时,这些文本文件中,文件名中含有Point字段的,都是我们需要的文件,我们接下来的操作都是对这些我们需要的文件而言的;而不含有Point这个字段的,那么我们就不需要。
随后,在每一个我们需要的文本文件(也就是文件名中含有Point字段的文件)中,都具有着如下图所示的数据格式。我们希望,基于第1列(红色框内所示的列)数据(这一列数据表示波长),找到几个指定波长数据所对应的行,并将这些行所对应的后5列数据都保存下来。
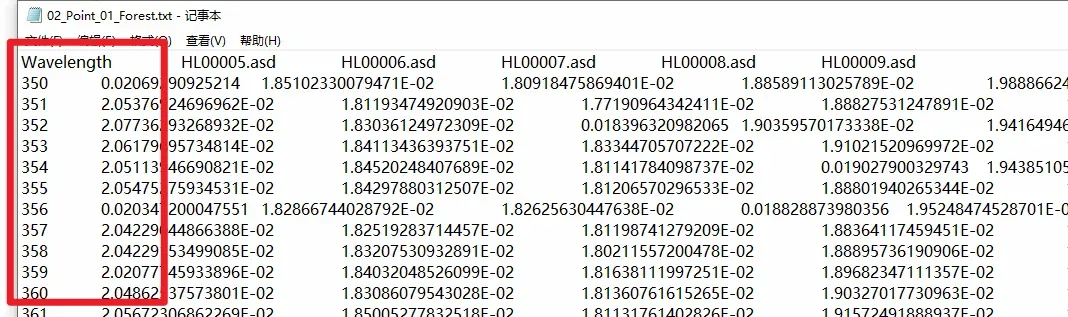
此外,前面也提到,文件名中含有Point字段的文本文件是有多个的;因此希望将所有文本文件中,符合要求的数据行都保存在一个变量,且保存的时候也将文件名称保存下来,从而知道保存的每一行数据,具体是来自于哪一个文件。
知道了需求,我们就可以开始代码的书写。其中,本文用到的具体代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Fri Jul 7 23:39:43 2023
@author: fkxxgis
"""
import os
import pandas as pd
original_file_folder = "E:/03_Experiment/202306HuaiLai/HuaiLai_20230627_SpectralCurve"
result_file_path = "E:/03_Experiment/202306HuaiLai/HuaiLai_20230627_SpectralCurve/Result.csv"
target_wavelength = [490, 561, 665, 702, 863]
result_all_df = pd.DataFrame()
for file in os.listdir(original_file_folder):
if file.endswith(".txt") and file[3] == "P":
file_path = os.path.join(original_file_folder, file)
df = pd.read_csv(file_path, delimiter = "\t")
select_df = df[df["Wavelength"].isin(target_wavelength)]
select_df.insert(0, "file_name", file)
data_append = select_df.iloc[1 : , 2 : ]
result_df = pd.DataFrame()
result_df = pd.concat([select_df.iloc[[0]].reset_index(drop = True), pd.DataFrame(data_append.values.flatten()).transpose()], axis = 1)
result_df.columns = range(result_df.shape[1])
result_all_df = pd.concat([result_all_df, result_df], axis = 0, ignore_index = True)
上述代码具体的含义如下所示。
首先,我们导入了需要使用的库——os库用于文件操作,而pandas库则用于数据处理;接下来,我们定义了原始文件夹路径 original_file_folder 和结果文件路径 result_file_path。然后,我们创建一个空的DataFrame对象result_all_df,用于存储所有处理后的结果。
再接下来,通过使用os.listdir()函数,我们遍历指定文件夹中的文件。我们通过条件过滤,只选择以.txt结尾且文件名的第四个字母是P的文件——这些文件就是我们需要的文件。随后,对于每个满足条件的文件,我们构建了文件的完整路径file_path,并使用pd.read_csv()函数读取文件的内容。在这里,我们使用制表符作为分隔符,并将数据存储在DataFrame对象df中。
然后,我们根据给定的目标波长列表target_wavelength,使用条件筛选出包含目标波长的数据行,并将文件名插入到选定的DataFrame中,即在第一列插入名为file_name的列——这一列用于保存我们的文件名。
接下来,在我们已经提取出来的数据中,从第二行开始,提取每一行从第三列到最后一列的数据,将其展平为一维数组,从而方便接下来将其放在原本第一行的后面(右侧)。然后,我们使用pd.DataFrame()函数将展平的数组转换为DataFrame对象;紧接着,我们使用pd.concat()函数将原本的第一行数据,和展平后的数据按列合并(也就是放在了第一行的右侧),并将结果存储在result_df中。
最后,我们将每个文件的处理结果按行合并到result_all_df中,通过使用pd.concat()函数,指定axis=0表示按行合并。由于我这里的需求是,只要保证文本文件中的数据被提取到一个变量中就够了,所以没有将结果保存为一个独立的文件。如果需要保存为独立的.csv格式文件,大家可以参考文章Python读取Excel文件并复制指定的数据行(https://blog.csdn.net/zhebushibiaoshifu/article/details/131615610)。
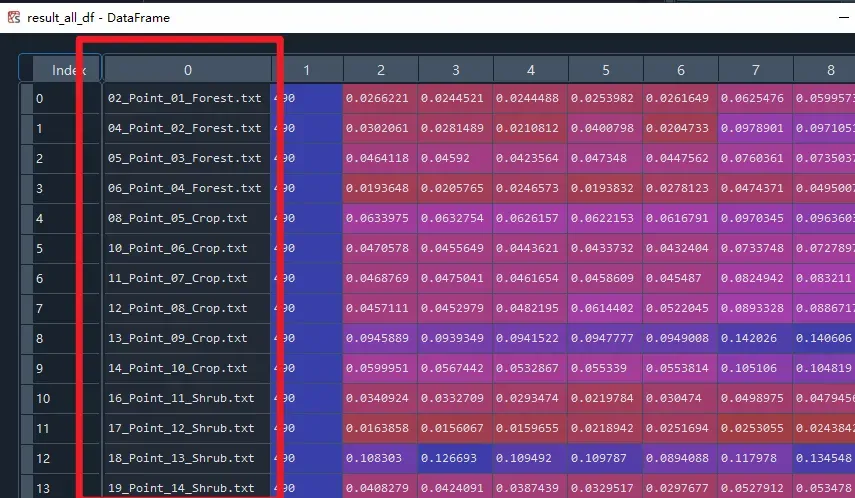
运行上述代码,即可看到保存我们提取出来的数据的结果的变量result_all_df的具体情况如下图所示。可以看到,已经保存了我们提取出来的具体数据,以及数据具体来源文件的文件名称;并且从一个文本文件中提取出来的数据,都是保存在一行中,方便我们后期的进一步处理。
至此,大功告成。
欢迎关注:疯狂学习GIS
文章出处登录后可见!