目录
专栏导读

专栏订阅地址:https://blog.csdn.net/qq_35831906/category_12375510.html

1网络爬虫概述
网络爬虫(Web Crawler),也称为网络蜘蛛、网络机器人,是一种自动化程序,用于在互联网上浏览和抓取信息。爬虫可以遍历网页,收集数据,提取信息,以便于进一步处理和分析。网络爬虫在搜索引擎、数据采集、信息监测等领域发挥着重要作用。
1.1 工作原理
初始URL选择: 爬虫从一个或多个初始URL开始,这些URL通常是你希望开始爬取的网站的主页或其他页面。
发送HTTP请求: 对于每个初始URL,爬虫会发送HTTP请求以获取网页内容。请求可以包括GET、POST等不同的HTTP方法,也可以设置请求头、参数和Cookies等。
接收HTTP响应: 服务器将返回一个HTTP响应,其中包含网页的HTML代码和其他资源,如图片、CSS、JavaScript等。
解析网页内容: 爬虫使用HTML解析库(如Beautiful Soup或lxml)解析接收到的HTML代码,将其转换为文档对象模型(DOM)结构。
数据提取和处理: 通过DOM结构,爬虫从网页中提取所需的信息,如标题、正文、链接、图片等。这可以通过CSS选择器、XPath等方法实现。
存储数据: 爬虫将提取的数据存储到本地文件、数据库或其他存储系统中,以供后续分析和使用。
发现新链接: 在解析网页时,爬虫会找到新的链接,并将其加入待爬取的URL队列中,以便继续爬取更多页面。
重复流程: 爬虫循环执行上述步骤,从初始URL队列中取出URL,发送请求,接收响应,解析网页,提取信息,处理和存储数据,发现新链接,直到完成爬取任务。
控制和维护: 爬虫需要设置适当的请求频率和延时,以避免对服务器造成过大负担。还需要监控爬虫的运行情况,处理错误和异常。
1.2 应用场景
搜索引擎:搜索引擎使用爬虫来抓取网页内容,建立索引,以便用户搜索时能够快速找到相关信息。
数据采集:企业、研究机构等可以使用爬虫从互联网上采集数据,用于市场分析、舆情监测等。
新闻聚合:爬虫可以从各个新闻网站抓取新闻标题、摘要等,用于新闻聚合平台。
价格比较:电商网站可以使用爬虫抓取竞争对手的产品价格和信息,用于价格比较分析。
科研分析:研究人员可以使用爬虫来获取科学文献、学术论文等信息。
1.3 爬虫策略
通用爬虫(General Crawler)和聚焦爬虫(Focused Crawler)是两种不同的网络爬虫策略,用于在互联网上获取信息。它们的工作方式和应用场景有所不同。
通用爬虫(General Crawler): 通用爬虫是一种广泛用途的爬虫,它的目标是尽可能地遍历互联网上的大量网页,以收集和索引尽可能多的信息。通用爬虫会从一个起始URL开始,然后通过链接跟踪、递归爬取等方式探索更多的网页,构建一个广泛的网页索引。
通用爬虫的特点:
- 目标是收集尽可能多的信息。
- 开始于一个或多个起始URL,然后通过链接跟踪扩展。
- 适用于搜索引擎和大型数据索引项目。
- 需要考虑网站的robots.txt文件和反爬虫机制。
聚焦爬虫(Focused Crawler): 聚焦爬虫是一种专注于特定领域或主题的爬虫,它选择性地爬取与特定主题相关的网页。与通用爬虫不同,聚焦爬虫只关注某些特定的网页,以满足特定需求,如舆情分析、新闻聚合等。
聚焦爬虫的特点:
- 专注于特定主题或领域。
- 根据特定的关键词、内容规则等选择性地爬取网页。
- 适用于定制化需求,如舆情监控、新闻聚合等。
- 可以更精准地获取特定领域的信息。
在实际应用中,通用爬虫和聚焦爬虫有各自的优势和用途。通用爬虫适合用于构建全面的搜索引擎索引,以及进行大规模数据分析和挖掘。聚焦爬虫则更适合于定制化需求,能够针对特定领域或主题获取精准的信息。
1.4 爬虫的挑战
网站结构变化:网站结构和内容可能随时变化,需要对爬虫进行调整和更新。
反爬虫机制:一些网站采取了反爬虫措施,如限制请求频率、使用验证码等。
数据清洗:从网页中提取的数据可能包含噪音,需要进行清洗和整理。
法律和道德问题:爬虫需要遵守法律法规,尊重网站规则,不要滥用和侵犯他人权益。
总结: 网络爬虫是一种自动化程序,用于从互联网上获取信息。它通过发送请求、解析网页、提取信息等步骤,实现数据的采集和整理。在不同的应用场景中,爬虫发挥着重要的作用,但也需要面对各种挑战和合规性问题。
2 网络爬虫开发
2.1 通用的网络爬虫基本流程
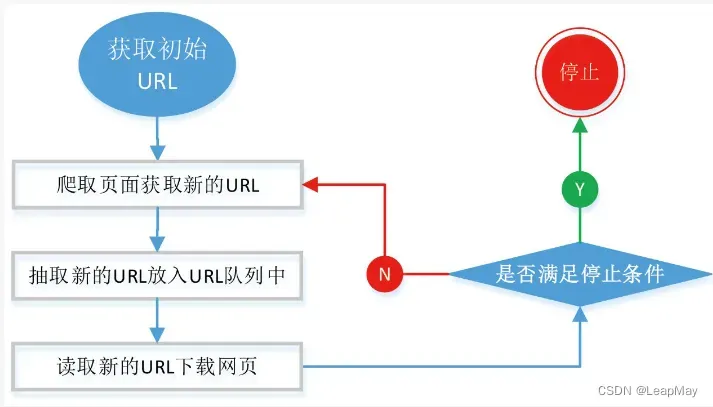
2.2 网络爬虫的常用技术
网络爬虫是一种自动化的程序,用于从互联网上收集数据。常用的网络爬虫技术和第三方库包括以下内容:
1. 请求和响应处理:
- Requests: 用于发送HTTP请求和处理响应的库,方便爬虫获取网页内容。
- httpx: 类似于
requests,支持同步和异步请求,适用于高性能爬虫。2. 解析和提取数据:
- Beautiful Soup: 用于解析HTML和XML文档,并提供简单的方法来提取所需数据。
- lxml: 高性能的HTML和XML解析库,支持XPath和CSS选择器。
- PyQuery: 基于jQuery的解析库,支持CSS选择器。
3. 动态渲染网页:
- Selenium: 自动化浏览器库,用于处理动态渲染的网页,如JavaScript加载内容。
4. 异步处理:
- asyncio和aiohttp: 用于异步处理请求,提高爬虫的效率。
5. 数据存储:
- SQLite、MySQL、MongoDB: 数据库用于存储和管理爬取的数据。
- CSV、JSON: 简单格式用于导出和导入数据。
6. 反爬虫和IP代理:
- User-Agent设置: 设置请求的User-Agent头部来模拟不同浏览器和操作系统。
- 代理服务器: 使用代理IP来隐藏真实IP地址,避免IP封禁。
- 验证码处理: 使用验证码识别技术来处理需要验证码的网站。
7. Robots.txt和网站政策遵守:
- robots.txt: 检查网站的
robots.txt文件,遵循网站的规则。- 爬虫延迟: 设置爬虫请求的延迟,避免对服务器造成过大负担。
8. 爬虫框架:
- Scrapy: 一个强大的爬虫框架,提供了许多功能来组织爬取过程。
- Splash: 一个JavaScript渲染服务,适用于处理动态网页。
2.3 网络爬虫常用的第三方库
网络爬虫使用多种技术和第三方库来实现对网页的数据获取、解析和处理。以下是网络爬虫常用的技术和第三方库:
1. 请求库: 网络爬虫的核心是发送HTTP请求和处理响应。以下是一些常用的请求库:
- Requests: 简单易用的HTTP库,用于发送HTTP请求和处理响应。
- httpx: 现代化的HTTP客户端,支持异步和同步请求。
2. 解析库: 解析库用于从HTML或XML文档中提取所需的数据。
- Beautiful Soup: 用于从HTML和XML文档中提取数据的库,支持灵活的查询和解析。
- lxml: 高性能的XML和HTML解析库,同时支持XPath和CSS选择器。
3. 数据存储库: 存储爬取到的数据是爬虫的重要环节之一。
- SQLAlchemy: 强大的SQL工具包,用于在Python中操作关系数据库。
- Pandas: 数据分析库,可用于数据清洗和分析。
- MongoDB: 非关系型数据库,适合存储和处理大量的非结构化数据。
- SQLite: 轻量级的嵌入式关系数据库。
4. 异步库: 使用异步请求可以提高爬虫的效率。
- asyncio: Python的异步IO库,用于编写异步代码。
- aiohttp: 异步HTTP客户端,支持异步请求。
5. 动态渲染处理: 有些网页使用JavaScript进行动态渲染,需要使用浏览器引擎进行处理。
- Selenium: 自动化浏览器操作库,用于处理JavaScript渲染的页面。
6. 反爬虫技术应对: 一些网站采取反爬虫措施,需要一些技术来绕过。
- 代理池: 使用代理IP来避免频繁访问同一IP被封禁。
- User-Agent随机化: 更改User-Agent以模拟不同的浏览器和操作系统。
这只是网络爬虫常用的一些技术和第三方库。根据实际项目需求,您可以选择合适的技术和工具来实现高效、稳定和有用的网络爬虫。
3 简单爬虫示例
创建一个简单的爬虫,例如爬取一个静态网页上的文本信息,并将其输出。
import requests
from bs4 import BeautifulSoup
# 发送GET请求获取网页内容
url = 'https://www.baidu.com'
response = requests.get(url)
response.encoding = 'utf-8' # 指定编码为UTF-8
html_content = response.text
# 使用Beautiful Soup解析HTML内容
soup = BeautifulSoup(html_content, 'html.parser')
# 提取网页标题
title = soup.title.text
# 提取段落内容
paragraphs = soup.find_all('p')
paragraph_texts = [p.text for p in paragraphs]
# 输出结果
print("Title:", title)
print("Paragraphs:")
for idx, paragraph in enumerate(paragraph_texts, start=1):
print(f"{idx}. {paragraph}")
下一篇:【100天精通python】Day42:python网络爬虫开发_HTTP请求库requests 常用语法与实战_LeapMay的博客-CSDN博客在网络爬虫中,HTTP(Hypertext Transfer Protocol)协议起着至关重要的作用,它是用于在客户端和服务器之间传输数据的协议。HTTP请求库requests 实战操作。https://blog.csdn.net/qq_35831906/article/details/132381253?spm=1001.2014.3001.5502
文章出处登录后可见!