传统图像压缩
简述
早期的图像压缩方法直接利用熵编码减少图像的编码冗余来实现压缩,例如,霍夫曼(Huffman)编码,算术编码,上下文自适应二进制算术编码。
在20世纪 60年代后期基于图像变换的压缩方法被提出,这种压缩方法即将图像从空间域转换至频率域在频率域进行编码。变换编码中用到的变换方法主要包括傅里叶变换,Hadamard变换,和离散余弦变换(Discrete Cosine Transform,DCT)
除了通过熵 编码和变换技术来去除数据冗余外,预测和量化技术随后被提出来用于减少图像中的空间冗余和心理视觉冗余。最流行的图像压缩方法JPEG是一个成功的图像压缩方法,其优势包括图像的压缩比及保真度可在较大范围内调节、能够由应用情况进行选择、压缩及还原的实现复杂度适中、并且硬件成本不高等。另一个著名的图像压缩方法JPEG 2000是在JPEG压缩方法上作出的改进,在低码率情况下JPEG 2000相比JPEG会获得 明显的优势,在高码率条件下仅能获得可比的性能。现代视频编解码器,例如HEVC 和VVC,采用帧内预测和循环滤波器进行帧内编码,而这两个组件也应用于图像压缩 方法BPG,为进一步减少空间冗余并提高重建帧的质量。
早期的压缩方法直接通过熵编码或者变换编码来进行压缩,而熵编码和变换编码已被作为图像压缩中必不可少的环节。传统的图像压缩方法由几个基本的模块构成,即变换、量化和熵编码,设计良好的变换编码将图像信号转换为紧凑且不相关的系数,通过量化消除心理视觉冗余,便于熵编码,最后再经过熵编码编码为所要传输或存储的码流。经典的传统图像压缩方法主要包括JPEG、 JPEG2000和BPG,接下来分别对它们和它们的改进做出梳理。
JPEG
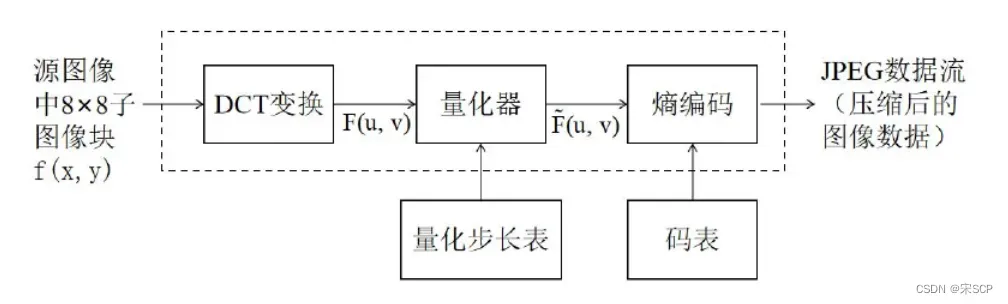
JPEG是最常见的一种图像格式,JPEG压缩标准的压缩流程如图所示,总共分为四个步骤,首先进行数据预处理,将图像由RGB颜色模式改为YUV颜色模式,RGB 和YUV之间的转换并不包含在编解码器中,而是应用程序在编码之前和解码之后根据需要完成。转换完之后还需要进行数据采样,一般采样的比例是2:1:1,由于在执行了此项工作后,每两行数据只保留一行,因此采样后图像数据量将压缩为原来的一半。第二个步骤就是将子块进行二维的离散余弦变换(DCT),DCT变换就是将图像信号在频率域上进行变换,分离出高频和低频信息,然后再对高频信息进行压缩,以达到图像压缩的目的。首先要将图像划分为多个矩阵,然后对于每个矩阵做DCT变换,对其 DC分量应该用差分脉冲编码调制(Differential Pulse Code Modulation,DPCM),从而压缩相邻DCT块之间的DC分量,而不是直接压缩DC值。由于在熵编码过程中使 用的码本都是整数,所以需要对DCT变换后的频域系数进行量化操作,这是压缩的第三个步骤,量化操作将频域系数转换为整数。
量化操作的公式如下所示:
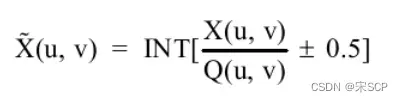
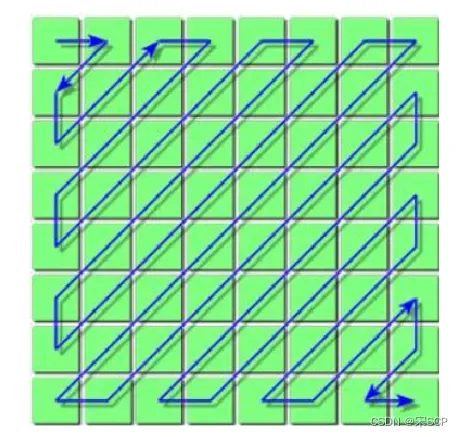
其中,X(u,v)代表的是待量化的图像矩阵,Q(u,v)为量化系数矩阵,±0.5是为了取整。 JPEG压缩标准为了减少视觉冗余,设计了一个特殊的量化系数矩阵,以很好地保留低频信息,并丢弃更多高频(类噪声)细节,因为人们对高频部分的信息丢失不太敏感。JPEG压缩标准提供了两张标准的量化系数矩阵,分别用于处理亮度数据和色度数据。经过量化后,频域系数矩阵的值大部分都会变成0,这非常有利于后面的熵编码,在进入下一个步骤之前,矩阵的量化还有最后一步要做,就是把量化后的二维矩阵转变成一 个一维数组。直流系数即频域系数矩阵左上角的第一个系数,采用前一个系数矩阵的直流系数来预测,对于交流系数,JPEG采用“之”字形的扫描顺序,如图所示。采用这样的扫描顺序是为了让更多的0值聚集在一起,方便后续编码,经过这种顺序变换,最终频域系数矩阵变成了一个整数数组。
第四个步骤就是熵编码,包括哈夫曼编码和自适应二进制算术编码,这两种编码方式都有其对应的码表,码表是在大量实际图像测试结果的基础上生成的,编码时只需要直接查表即可。
JPEG也有其缺点,JPEG压缩不可避免地会引入各种伪影,这是由于在压缩过程中丢失高频信息所造成的的,尤其是高压缩率下,还会产生失真,这会大大地影响体验质量,针对这个问题有很多方法被提出来,例如传统的基于滤波器的方法。还有一 些应用稀疏编码来恢复压缩图像。这些方法通常在压缩输入的情况下生成更清晰的图像,但它们通常速度太慢,结果往往伴随着额外的伪影。所以有许多基于深度学习的方 法用于压缩伪影的去除。
JPEG2000
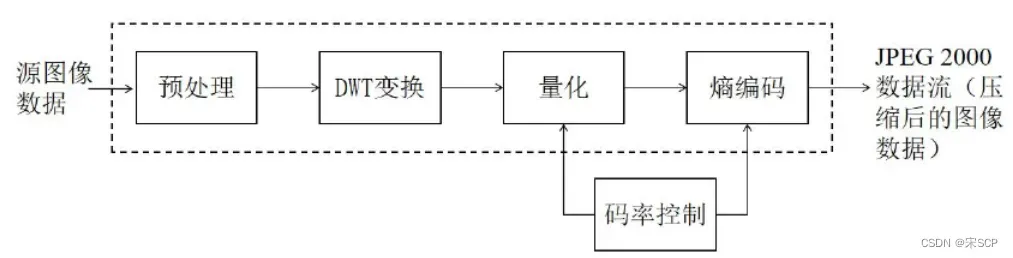
JPEG 2000压缩标准同样也有四个步骤,数据预处理包括对图像的分块,数据偏移归一化处理和颜色变换,将图像分割成若干互不重叠的矩形块,分块的大小任意。数据偏移即将像素值偏移至0对称,归一化是为了方便后续的离散小波变换(Discrete Wavelet Transformation,DWT)。去除分量之间的相关性,提高压缩效率,就需要对图像进行相应的分量变换,颜色变换也即将图像从RGB色域转换至YUV色域。JPEG 2000采用的 是DWT,图像经过DWT变换后,同样需要对系数矩阵进行量化操作,方便熵编码, 从而达到图像压缩的目的,JPEG 2000采用的是均匀标量量化,对量化后的系数矩阵进行熵编码,熵编码采用的是最佳截断嵌入码块编码(embedded block coding with optimized truncation,EBCOT)
JPEG 2000相比JPEG优势明显,作为JPEG的改进,其压缩率能达到比JPEG高约30%, 且JPEG 2000能支持针对感兴趣区域的区别压缩,还能进行渐进传输,先传输图像的轮廓,然后再逐步传输数据,不断提高图像质量,让图像由朦胧到清晰显示。基于感兴趣区域的编码在图像压缩领域是具有重要的指导意义的。不过其缺点就是会带来一定的模糊失真,因为在编码过程中高频量会有一定程度的衰减。另外,JPEG 2000同时支持有损压缩和无损压缩,JPEG 2000的无损压缩可以获得比JPEG更高的压缩率,但是 JPEG 2000的实现操作都是在实数域上的,所以其解码速度要比JPEG慢很多,使其无论是在客户端还是服务器端都不被看好,限制了其的大力推广。
基于深度学习的压缩方法
传统的图像压缩编码经过快速发展,在实际中应用广泛,同时也在性能提升 上面到达了瓶颈期。同时,传统的图像压缩编码是由各个单独的模块进行连接构成,比如变换模块、量化模块、熵编码模块,这些模块是单独手动优化设计的,没有进行整体的联合优化。其次,传统的编码质量评估针对的一般是一些客观的性能指标,对于比较主观的质量指标和语义质量指标比较难以满足其要求,也无法获得图像深层次的语义信息,这方面传统的图像压缩编码已经无法满足现代的要求,深度学习和计算机视觉在不断的发展进步,能作为一种新方式来解决图像压缩编码的问题。端到端的图像压缩能够将图像编码中的各个模块进行联合优化, 能够让数据说话。
基于深度学习的图像压缩的历史发展与现状可以分为两类来阐述,一是基于 不同神经网络图像压缩的框架发展,二是深度学习下的图像压缩中图像变换模块、量化模块、编码模块等核心模块的发展。
基于不同神经网络图像压缩框架发展
根据深度学习采用的不同网络可以将基于深度学习的图像压缩分为三大类, 第一种是基于卷积神经网络的图像压缩,第二种是基于循环神经网络的图像压缩, 最后一种是基于生成对抗网络的图像压缩。下面分别对其进行介绍。
CNN
首先是基于CNN网络的图像压缩。CNN网络在图像处理领域中得到了广泛 的发展和应用,它具有部分感知和权值共享等特点,能够减少网络训练所需参数 量。传统的图像压缩中图像变换、量化、编码等模块研究者通过经验或者实验手动优化,而基于深度学习的图像压缩可以联合调优。但端到端的图像压缩也是困难的,首先需要解决的问题就是图像量化中的不可导问题。传统的图像压缩中往 往采用系数矩阵直接求导再四舍五入的方式对数据进行量化。
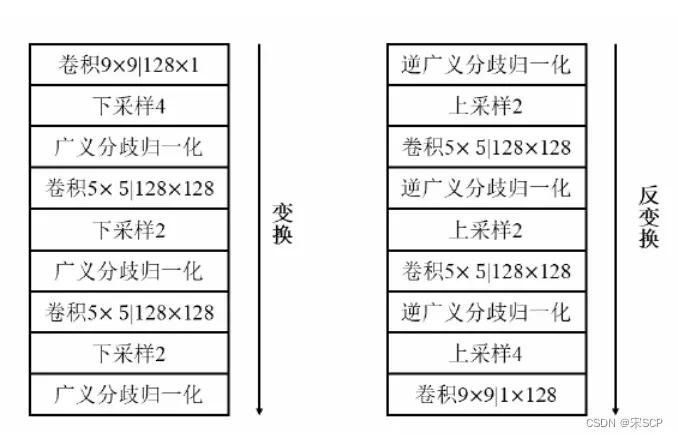
Ballé[1]等研究者通过一种添加均匀分布的噪声来解决这个问题。添加一个噪声让数据变成连续可微,同时也不改变原有的量化结果。他们使用CNN网络对图像进行处理,网络编码网络包括三个大卷积层,每一层的构成为一个卷积层一个下采样和广义分歧归一 化。解码网络与编码网络类似。Ballé等人的研究取得的编码效果与JPEG2000接近,是CNN网络与图像压缩的开创性工作,为后续的基于CNN网络的图像压缩奠定了基础。Ballé提出的基于CNN网络的图像编码框架如下图所示。在这个框架的基础之上,Ballé[2]等人又增加了超先验网络来对潜在数据进行合理估计。图像压缩中的上下文信息对于图像编解码十分重要
Minnen[3]为了弥补上下文信息的缺失,引入了上下文网络对潜在数据更精确的估计,完善了超编码网络,是第 一个在图像峰值信噪比和图像结构化相似度上都优于BPG的深度学习压缩编码研究。
为了提高图像压缩的重建效果,Jiang[4]等研究者提出了一个新的基于CNN的图像压缩框架,在这个框架中,有两个卷积神经网络,分别与编码器和解码器连接,然后对这两个网络统一优化,编码端的神经网络对图像数据提取有效信息,解码端的神经网络对图像进行重建,该研究对图像压缩所产生的块效应有 所缓解,对比JPEG编码效果更优。
Toderici提出的深度学习框架:
RNN
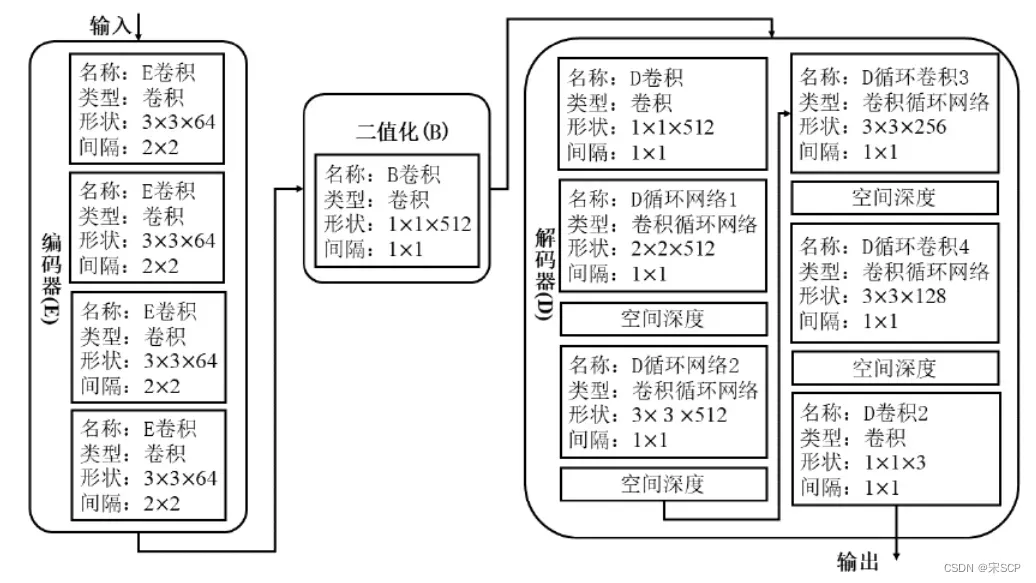
基于RNN的网络的端到端图像压缩编码。RNN网络具有一定的记忆功能,对 于处理前后信号依赖性强的信号有优势,RNN网络的神经元不仅相邻层连接,并且与自身连接。Toderici[5]等人提出的一种基于RNN网络的图像压缩方法。该方法使用迭代式的RNN网络对码率进行控制,同时使用残差网络来提高图像的重建质量,具体来说包括一个编码网络、一个二值化网络、和一个解码网络。重建效果与JPEG2000近似。该工作为后续基于RNN网络的图像压缩做了铺垫。之后的研究者通过引入高效熵编码模块[6]、码率分配模块[7]等,进一步发展壮大了基 于RNN网络的图像压缩。部分网络实现的图像重建效果已经超越了BPG。
Toderici提出的深度学习框架:
GAN
GAN网络的兴起也推动了基于深度学习图像压缩的研究,GAN网络能够通过生成器生成图像,而判别器来判断所生成的图像是否为真。Rippel[8]提出了基 于GAN网络的图像压缩。该方法的特别之处在于使用了生成对抗网络来达到低比特率下生成高质量网络的目的,是第一个将生成对抗网络用于图像压缩的工作。 这个框架在图像的压缩性能和压缩用时方面都取得了较好的结果。
基于深度学习的端到端图像压缩核心模块的发展
端到端的图像压缩框架即为将图像压缩过程视为一个整体网络进行联合调优。Ballé和Toderici等人分别利用CNN和RNN网络完成端到 端的图像压缩工作,而Rippel使用的GAN网络也是一种端到端的图像压缩工作。 所以基于深度学习的端到端图像压缩是一种更为常用的方案,下面将详细介绍在端到端的图像压缩中研究者们所做的工作。
传统的图像压缩过程为图像经过预处理之后,再经过变换模块、量化模块、编 码模块等不同模块。对应的基于深度学习的图像压缩中,也存在变换模块、量化模块、编码模块等。
变换模块发展
传统图像压缩中的变换步骤将图像空域数据变换到频域或者其他空间域中,以达到图像数据能量收敛的效果,对不重要数据舍弃,压缩数据量。在深度学习中,使用级联的卷积层对图像进行变换,Ballé[9]等人提出了一 种基于GDN的非线性变换,该变换包含三个步骤:先卷积、再下采样、最后进行 GDN变换。该方法在与传统的压缩方法的相同的图像压缩误差的情况下减少了使 用的码字。Theis[10]等人受图像超分辨的思路启发提出了一种有损的图像自编码器框架,该框架使用了普通的卷积神经网络来实现图像的变换,首先对图像数据进行预处理,之后再对图像进行卷积和下采样,最后利用残差块处理。为了更加有效地提取到图像中地特征信息,减少数据量,Zhao[11]等人提出了一种FDNN网络对图像特征进行提取。FDNN网络使用了8个卷积层对图像数据进行处理,为了增大感受野,在初始层和末层使用的卷积核大小为9,中间间隔穿插ReLU层来增 加网络的非线性。总之,图像压缩中的变换部分由传统的数学空间运算变换变为了级联的网络卷积完成,最终达到从分散的数据中提取到有效的特征信息的目的。
量化模块发展
传统的图像压缩编码中,经过变换后的数据会再经过量化。 基于深度学习的端到端图像压缩中,量化产生的量化不可导问题是需要重点解决的问题。Toderici[12]等人提出的解决方法是二值量化,这种二值量化的方法首先在连续区间[−1,1]生成一定量的输出,再将实值表达作为输入,得到-1,1的离散输出。二值量化后可以直接序列化,有利于信息传输;可以通过限制位容差来控 制压缩率;可以迫使网络学习图像的有效表示。为了解决二值量化中的0梯度问 题,Rippel[8]等人和Li[13]等人在反向传播中引入代理函数,代理函数具有可导性。Ballé[9]等人提出的添加加性均匀噪声代替原有取整函数,实现量化过程,且保证全局可导。为了解决整数量化的图像重建质量并不高这个问题,Agustsson[14] 提出了一种矢量量化方法,根据给定的标量或向量软赋值以量化到所需量化级别。实验证明了矢量量化比传统的标量量化具有更好的表现能力。
编码模块发展
在传统的图像压缩编码中,通常使用算数编码或者哈夫曼 编码来去除经过量化后数据存在的冗余性。在端到端的图像压缩中,Ballé[1]等人提出构建一个熵模型,对量化后的潜在表达数据所需的比特进行近似估计,为后续熵模型的发展奠定了基础。同时期的Theis[10]等人采用高斯模型作为近似估计, 有效提高了基于深度学习的端到端图像压缩的性能。为了进一步降低潜在表示中 的空间依赖,Ballé[2]等人继续在之前的模型上增加了超先验网络,将压缩的超先验信息作为辅助,同时生成的码流中增加部分比特位信息表示辅助信息,得到更加精准的模型,增强了熵编码。在此基础上,Minnen[3]等研究者扩展了超先验模型,将0均值高斯模型完善到非0均值高斯模型,同时增加上下文模块,弥补了超先验模型缺失上下文信息的不足,结合了上下文模块的超先验网络框架下的图像压缩效果在峰值信噪和多尺度结构相似性上都优于BPG。Lee[15]提出了一种利 用两种类型的上下文网络,包含位消耗上下文和位自由上下文,根据需求选择是否使用额外的比特,这种网络有利于更广义的模型进行潜在表示的估计。Hu[16]等人针对超先验网络和上下文模型中存在的长距离依赖问题,提出了一个多层超先验模型,即在原有的超先验网络上再添加一个网络,对隐层数据进行更深入的分析变换,充分榨取图像空间上冗余度。Qian[17]认为之前的研究注重于局部信息的冗余,对全局信息的冗余研究关注过少,在熵模型之上加入了全局相关的搜索模块,递进式地将熵模型与上下文模块和全局搜索模块结合。Bai[18]等人在原始的 有损超先验图像压缩框架上,构建一种新的残差学习网络,学习构建近无损压缩图像,在无损压缩下达到了最好的性能,同时高码率情况下与有损压缩相比也不逊色。除了利用卷积神经网络之外也有基于Transformer的熵模型,Qian[17]等人提出一种Top-k的过滤机制,和相对位置模块,使网络在预测特征的概率分布方面更加精准。总结,基于深度学习的图像压缩编码中熵编码部分的工作主要是利用对潜在表示进行估计建模的方法完成,尽可能的使估计精准。
自适应码率分配模块发展
除了以上的三大模块之外,基于深度学习的端到端图像压缩框架中,考虑到图像的复杂结构和区域差异,还对图像进行了自适应的码率分配。Li[19]等人提出了一种内容加权的编码网络,该网络被称为重要 性掩码网络,通过该网络能够生成局部自适应的码率分配掩码。Zhong[20]等人认 为之前的基于卷积神经网络的图像压缩将所有的特征通道等同映射是不严谨的, 他们提出了一种可变量化网络,包括学习信道重要性和分配码率两个部分,为重要的信道分配更多的比特。Liu[21]等人使用非局部模块来获取图像的全局相关性, 结合注意力机制对图像特征中的重要信息分配更多码率。Liu[22]等人设计了一种轻量级的通道注意力模块,有效的降低了计算量。Akutsu[23]等人提出了一种基于 卷积自动编码和感兴趣域(Region of Interest,ROI)结合的图像压缩框架,该框架 中的损失函数根据辅助信息改变图像各个区域中的质量参数,该方法相比原始框 架减少了31%,在结构相似性上提高了0.97。Cai[24]等人构建了一个ROI编码网络,该网络能够生成多尺度表示与ROI掩码,为了提高训练效率,还开发了一种 soft-to-hard训练方案。还有研究者Xia[25]等人设计了目标分割网络对图像进行图层分解,对图像的前景和后景采用不同的编码方案,该方法对任意形状的对象都能有效处理,在低比特率图像的压缩下,具有显著的主观性能提升。
参考文献
[1]BalléJ,Laparra V,Simoncelli E P.End-to-end optimized image compression[J].arXiv e-prints, 2016,arXiv:1611.01704.
[2]BalléJ,Minnen D,Singh S,et al.Variational image compression with a scale hyperprior[C].International Conference on Learning Representations,Vancouver,2018,arXiv:1802.01436.
[3]Minnen D,BalléJ,Toderici G.Joint autoregressive and hierarchical priors for learned image com-pression[C].Proceedings of the 32nd International Conference on Neural Information Processing Systems,Red Hook,NY,USA,2018,10794–10803.
[4]Jiang F,Tao W,Liu S,et al.An end-to-end compression framework based on convolutional neural networks[J].IEEE Transactions on Circuits and Systems for Video Technology,2018,28(10):3007-3018.
[5]Toderici G,Vincent D,Johnston N,et al.Full resolution image compression with recurrent neural networks[C].2017 IEEE Conference on Computer Vision and Pattern Recognition,Los Alamitos, CA,USA,2017,5435-5443.
[6]Minnen D,Toderici G,Covell M,et al.Spatially adaptive image compression using a tiled deep network[C].2017 IEEE International Conference on Image Processing,2017,2796-2800.
[7]Johnston N,Vincent D,Minnen D,et al.Improved lossy image compression with priming and spatially adaptive bit rates for recurrent networks[C].2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition,2018,4385-4393.
[8]Rippel O,Bourdev L.Real-time adaptive image compression[C].Proceedings of the 34th Inter-national Conference on Machine Learning,2017,2922-2930.
[9]Ballé J,Laparra V,Simoncelli E P.End-to-end optimization of nonlinear transform codes for perceptual quality[C].2016 Picture Coding Symposium,Nuremberg,Germany,2016,1-5.
[10]Theis L,Shi W,Cunningham A,et al.Lossy image compression with compressive autoen-coders[J].arXiv e-prints,2017,arXiv:1703.00395.
[11]Zhao L,Bai H,Wang A,et al.Learning a virtual vodec based on deep convolutional neural network to compress image[J].arXiv e-prints,2017,arXiv:1712.05969.
[12]Toderici G,O’Malley S M,Hwang S J,et al.Variable rate image compression with recurrent neural networks[J].arXiv e-prints,2015,arXiv:1511.06085.
[13]Li M,Zuo W,Gu S,et al.Learning convolutional networks for content-weighted image com-
pression[J].arXiv e-prints,2017,arXiv:1703.10553.
[14]Agustsson E,Mentzer F,Tschannen M,et al.Soft-to-hard vector quantization for end-to-end learning compressible representations[C].Proceedings of the 31st International Conference on Neural Information Processing Systems,Red Hook,NY,USA,2017,1141–1151.
[15]Lee J,Cho S,Beack S K.Context-adaptive entropy model for end-to-end optimized image com-
pression[J].arXiv preprint arXiv:1809.10452,2018.
[16]Hu Y,Yang W,Liu J.Coarse-to-fine hyper-prior modeling for learned image compression[J].
Proceedings of the AAAI Conference on Artificial Intelligence,2020,34(7):11013-11020.
[17]Qian Y,Tan Z,Sun X,et al.Learning accurate entropy model with global reference for image
compression[J].arXiv e-prints,2020,arXiv:2010.08321.
[18]Bai Y,Liu X,Zuo W,et al.Learning scalableℓ∞-constrained near-lossless image compression
via joint lossy image and residual compression[C].2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition,Nashville,TN,USA,2021,11941-11950.
[19]Li M,Zuo W,Gu S,et al.Learning content-weighted deep image compression[J].IEEE Trans-
actions on Pattern Analysis and Machine Intelligence,2021,43(10):3446-3461.
[20]Zhong Z,Akutsu H,Aizawa K.Channel-level variable quantization network for deep image
compression[J].arXiv e-prints,2020.
[21]Liu H,Chen T,Guo P,et al.Non-local attention optimized deep image compression[J].arXiv
e-prints,2019,arXiv:1904.09757.
[22]Liu J,Lu G,Hu Z,et al.A unified end-to-end framework for efficient deep image compression[J].
arXiv e-prints,2020,arXiv:2002.03370.
[23]Akutsu H,Naruko T.End-to-end deep roi image compression[J].IEICE Transactions on Infor-
mation and Systems,2020,E103.D(5):1031-1038.
[24]Cai C,Chen L,Zhang X,et al.End-to-end optimized roi image compression[J].IEEE Transac-
tions on Image Processing,2020,29:3442-3457.
[25]Xia Q,Liu H,Ma Z.Object-based image coding:A learning-driven revisit[C].2020 IEEE Inter-
national Conference on Multimedia and Expo,2020,1-6.
文章出处登录后可见!