零、写在最前面:
2023.01.11 更新:
新增加onnxruntime的1.13.x版本支持。
由于onnxruntime从1.12升级到1.13之后,GetOutputName()这个API变成了GetOutputNameAllocated(),坑就出现在这里,新版api的返回值是一个unique_ptr指针,这就意味着他使用一次时候就失效了,所以在循环跑模型的时候基本的第二次都报错了。目前能想到的解决方法就是将其使用std::move()转成shared_ptr,这样可以在类生命周期之内都能存在,不会出现跑第一次就挂掉的情况。
2022.12.19更新:
新增onnxruntime推理实例分割模型,支持动态推理和批次推理,避免opencv不支持动态推理的尴尬境地。
2022.11.10更新:
上次的版本更新中,抠图是在最后的mask中抠图,而如果目标多并且目标小的话,特征图中的大部分区域都是无效数据,但是却参与了特征掩码与特征图计算mask图像的过程,在最后的步骤中才抠图去掉多余的无效数据。所以新版本我做了改变,直接从特征图中抠出有效区域进行计算,可以节省一大部分的时间,特别是检测框多,并且检测框都比较小的情况下效果更明显。
2022.10.13更新:
yolov5的实例分割结果mask从原来的整张图片的mask改成检测结果框内mask,节省内存空间和计算的速度,特别是计算crop区域和分割结果大于阈值的速度,这里用整张图的话,图片越大,检测结果越多,速度下降的厉害,也就是作者讲的计算分割结果需要的资源昂贵。贴个领带的mask结果示意图就明显看出来改动了:左边是整张图的mask,可以看到大部分黑色区域都是无效区域。

yolov5-seg分割模型目前已经发布了,而yolov7-mask目前由于opencv无法正确的读取问题,加上这个分支本身需要facebook的第三方库(这个库win下不好弄),所以一直没搞,opencv或者onnxruntime部署还在研究中,先开个贴占坑。
详细信息请移步:
yolov5-seg:https://github.com/ultralytics/yolov5
yolov7-mask:GitHub – WongKinYiu/yolov7 at mask
一、yolov5-seg
需要注意的是,有些人使用的是最新的torch1.12.x版本,在导出onnx的时候需要将do_constant_folding=True,这句换成false,否者dnn读取不了onnx文件,而onnxrutime可以,具体原因未知。
torch.onnx.export(
model.cpu() if dynamic else model, # --dynamic only compatible with cpu
im.cpu() if dynamic else im,
f,
verbose=False,
opset_version=opset,
do_constant_folding=False,
input_names=['images'],
output_names=output_names,
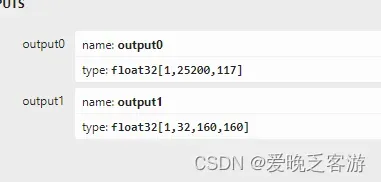
dynamic_axes=dynamic or None)需要运行自己模型的小伙伴,需要跟你你自己的onnx导出情况,修改一些参数,包括,其中_segWidth和_segWidth和_segChannels可以通过https://netron.app/
const int _netWidth = 640; //ONNX图片输入宽度
const int _netHeight = 640; //ONNX图片输入高度
const int _segWidth = 160;
const int _segHeight = 160;
const int _segChannels = 32;
const int _strideSize = 3; //stride size其中,output0为目标检测的输出口+32通道mask的候选特征,与ouput1的mask图像proto叉乘之后得到缩小的mask图,再根据缩放情况进行缩放得到最终的mask图。
最后贴一张结果图:

yolov5的实例分割模型目前已经更新,详细地址在:GitHub – UNeedCryDear/yolov5-seg-opencv-dnn-cpp: 使用opencv-dnn部署yolov5实例分割模型
测试模型可以自己导出或者用我导出的测试,建议跑自己模型的小伙伴先将demo跑通再去修改成自己的模型。
测试模型:https://download.csdn.net/download/qq_34124780/86745135
文章出处登录后可见!