1 前言
在上一篇文章一只猫引出的数据增强[Data Augmentation]中,介绍了十四种常用的深度学习数据增强方法,这些方法能满足日常大部分使用需求。但是在处理一些特殊问题时普通的数据增强方法难以显著的提高学习效果,因此本篇博客将介绍一种高级的数据增强方法:CutMix,并从零开始教大家实现将CutMix移植到自己的网络模型上。
2 CutMix原理讲解
CutMix是由韩国KAIST大学的Sangdoo Yun等人于2019年在CVPR上提出的,它可以增加模型对于图像位置和内容的鲁棒性。
论文链接:[传送门]
官方github:[传送门]
CutMix通过在两张随机选取的图像中剪切并交换一部分来生成新的训练数据。具体来说,它包括以下步骤:
- 1)随机选择两张图片,并从每张图片中随机剪切一个矩形区域。
- 2)将两张图片的剪切区域交换,并将其合并成一张新的图像。
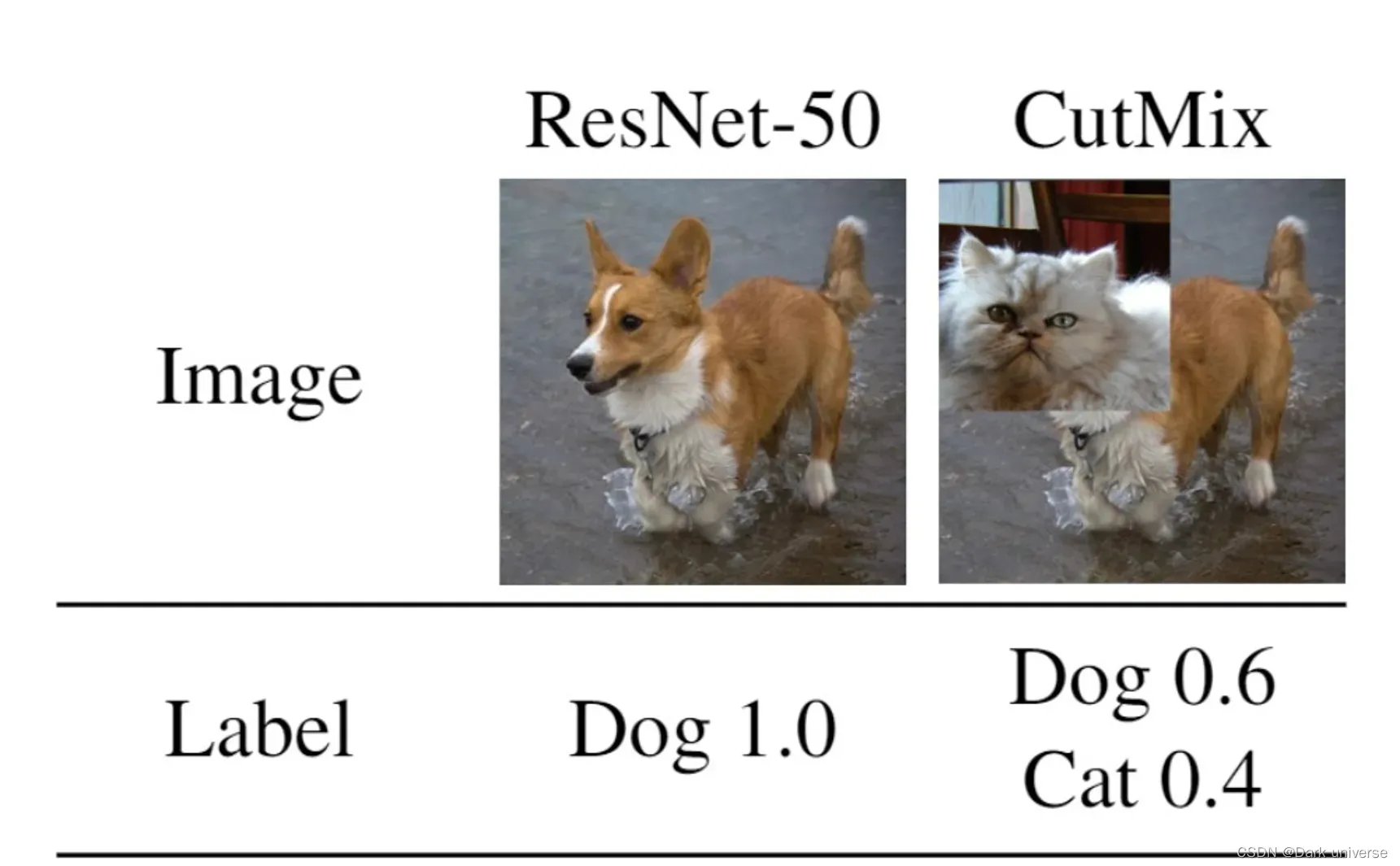
上述过程的具体演示可见下图:

- 3)计算新图像的标签,即将两张原始图像的标签按照剪切区域的面积加权平均来计算。
关于标签的计算可见下图,其中利用CutMix技术增强的图像是一张标签为Dog的图像剪切了左上角的一个矩形区域并把它用一张标签为Cat的图像填充而来的,根据剪切区域面积占比的加权平均,现在生成后的图像中60%的区域由原来的Dog图像提供,40%的区域由原来的Cat图形提供,因此该生成后的图像的标签为{Dog:0.6,Cat:0.4}。
- 4)使用新图像进行训练。
3 Cutmix程序实现
3.1 Cutmix图像处理程序
截至目前,CutMix还没有被收录进常用的数据增强包里(例如:albumentations),不能直接调用。因此要使用这项技术就需要自己实现,然后再嵌入到网络模型中。
下面给出CutMix的实现程序:
def cutmix(data, target, alpha):
"""
CutMix augmentation implementation.
参数:
data: batch of input images, shape (N, C, H, W)
target: batch of target vectors, shape (N,)
alpha: hyperparameter controlling the strength of CutMix regularization
Returns:
data: batch of mixed images, shape (N, C, H, W)
target_a: batch of target vectors type A, shape (N,)
target_b: batch of target vectors type B, shape (N,)
lam: Mixing ratio of types A and B
"""
indices = torch.randperm(data.size(0))
shuffled_data = data[indices]
shuffled_target = target[indices]
lam = np.random.beta(alpha, alpha)
lam = max(lam, 1 - lam)
bbx1, bby1, bbx2, bby2 = rand_bbox(data.size(), lam)
data[:, :, bbx1:bbx2, bby1:bby2] = shuffled_data[:, :, bbx1:bbx2, bby1:bby2]
# Adjust lambda to exactly match pixel ratio
lam = 1 - ((bbx2 - bbx1) * (bby2 - bby1) / (data.size()[-1] * data.size()[-2]))
# Compute output
target_a = target
target_b = shuffled_target
return data, target_a, target_b, lam
def rand_bbox(size, lam):
W = size[2]
H = size[3]
cut_rat = np.sqrt(1. - lam)
cut_w = np.int(W * cut_rat)
cut_h = np.int(H * cut_rat)
# uniform
cx = np.random.randint(W)
cy = np.random.randint(H)
bbx1 = np.clip(cx - cut_w // 2, 0, W)
bby1 = np.clip(cy - cut_h // 2, 0, H)
bbx2 = np.clip(cx + cut_w // 2, 0, W)
bby2 = np.clip(cy + cut_h // 2, 0, H)
return bbx1, bby1, bbx2, bby2
在上述代码中,data是输入图像的张量,target是对应的标签向量,alpha是CutMix超参数,控制混合程度。indices是打乱后的样本索引。
这里对target_a, target_b, lam做详细介绍,在前文的CutMix原理讲解中我们知道,CutMix是将两类图像混合在一起,最后的标签采用one-hot编码记录。例如:现在data中可能存在Dog和Cat两种数据,他们各自的编码为:target_a={Dog:1,Cata:0}和target_b = {Dog:0,Cata:1},现在经过增强获得了最终图像的编码为:target_c = {Dog:0.6,Cata:0.4}。但是函数这里只返回了target_a和target_b,因为最终的target_c可以由两种编码的混合比例lam去计算得知,这里只需要记录是哪两种类型的数据混合的和它们的比例是多少就行了。
3.2 CutMix应用于训练神经网络
上面给出的CutMix程序的数据处理对象是网络中的batch数据,所有在使用时只需将它嵌入到train中的每个batch下就可以了。
具体实现程序:
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.datasets as datasets
import torchvision.transforms as transforms
import numpy as np
# define network for image classification
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
self.conv2 = nn.Conv2d(32, 64, 3, padding=1)
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.fc1 = nn.Linear(128 * 4 * 4, 256)
self.fc2 = nn.Linear(256, 2)
def forward(self, x):
x = nn.functional.relu(self.conv1(x))
x = nn.functional.max_pool2d(x, 2)
x = nn.functional.relu(self.conv2(x))
x = nn.functional.max_pool2d(x, 2)
x = nn.functional.relu(self.conv3(x))
x = nn.functional.max_pool2d(x, 2)
x = x.view(-1, 128 * 4 * 4)
x = nn.functional.relu(self.fc1(x))
x = self.fc2(x)
return x
# define loss function
criterion = nn.BCEWithLogitsLoss()
# define train function
def train(model, device, train_loader, optimizer, criterion, epoch, alpha=1.0):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
# Set Random Use Cutmix
if np.random.rand() > 0.5:
data, target_a, target_b, lam = cutmix(data, target, alpha)
output = model(data)
loss = criterion(output, target_a) * lam + criterion(output, target_b) * (1. - lam)
else:
output = model(data)
loss = criterion(output, target)
optimizer.zero_grad()
loss.backward()
上面程序展示了CutMix嵌入到已经写好的网络模型中。以上面定义的图像二分类网络为例,只需要在train函数训练每一轮batch中嵌入CutMix,让函数去增强batch数据即可。这里有几点需要注意的事项:
- 1)虽然CutMix的原理是随意融合两类图像进行增强,但是可以用于多分类等任意图像分类问题
- 2)在使用是可以通过if语句设置batch数据随机CutMix增强的比例
- 3)增强后的数据有两类标签,所以loss需要分别计算这两中标签的损失并根据lam比例进行相加汇总
4 CutMix优缺点评述
下面是 CutMix 的优缺点总结:
优点:
- 1)可以生成比 Mixup 更具挑战性的训练样本,因为它使用了更难以预测的部分图像来训练模型。
- 2)可以生成更加平滑的决策边界,有助于提高模型的泛化性能。
- 3)可以提高数据增强的多样性,减少过拟合的风险。
- 4)可以在图像分类、目标检测、语义分割等任务中都取得不错的效果,尤其是在处理一些正负样本比例严重失衡的图像分类数据集中
缺点: - 1)可能会对训练过程的稳定性造成一定的影响,因为它会将不同的图像片段组合在一起,可能会导致一些难以训练的情况
- 2)增加计算成本,因为它需要生成新的训练数据并进行相应的前向传播和反向传播。
- 3)CutMix 的实现需要一定的技巧,例如需要选择合适的参数和调整损失函数等。如果实现不当,可能会降低模型的性能。
总的来说,CutMix 是一种非常有效的图像增强方法,可以帮助提高模型的泛化性能和鲁棒性。但是,在使用 CutMix 时需要注意其可能带来的计算成本和稳定性问题,以及需要合理选择参数和调整损失函数等。
5 总结
作为一种相对高级的数据增强方法,CutMix为数据增强提供了一种新的发展思路。但从经验来看,尽量将使用CutMix的优先级置后,当常规的增强手段难以达到效果后再考虑用此种方法。在使用时一定要选择好配套的损失函数并处理好CutMix与其它数据增强的组合逻辑。
文章出处登录后可见!