Pixel-wise Anomaly Detection in Complex Driving Scenes

CVPR2021
Code: https://github.com/giandbt/SynBoost
摘要
最先进的语义分割方法无法检测异常实例,这阻碍了它们在安全关键和复杂应用中的部署,例如自动驾驶。最近的方法集中在利用分割不确定性来识别异常区域或从语义标签图中重新合成图像以发现与输入图像的不同之处。在这项工作中,我们证明了这两种方法包含互补信息,并且可以结合起来为异常分割产生稳健的预测。我们提出了一个像素级异常检测框架,该框架使用不确定性图来改进现有的重新合成方法,以发现输入图像和生成图像之间的差异。我们的方法作为一个围绕已经训练好的分割网络的通用框架,可确保异常检测而不影响分割精度,同时显着优于所有类似方法。在一系列不同异常数据集上的 Top-2 性能显示了我们处理不同异常实例的方法的稳健性。
1. 介绍
通过这项工作,我们关注现有语义分割模型无法定位异常实例,以及这种限制如何阻碍它们在安全关键的野外场景中部署。 考虑使用语义分割模型的自动驾驶汽车的情况。 如果代理遇到异常物体(即马路中间的木箱),模型可能会错误地将这个物体归类为道路的一部分并导致车辆撞车。
为了检测输入中的此类异常,我们将我们的方法建立在两组已建立的方法之上。 第一组使用不确定性估计来检测异常。 他们的直觉是,低置信度的预测很可能是异常情况。 然而,不确定性估计方法本身仍然嘈杂且不准确。 以前的工作 [24, 4] 表明这些模型无法检测到许多意想不到的物体。 示例失败案例如图 1(顶部和底部)所示,其中异常对象被检测到但未分类或未检测到并与背景混合。 在这两种情况下,分割网络对其预测都过于自信,因此估计的不确定性(softmax entropy)很低。

图 1. 异常情况概述。 当分割网络遇到异常实例时,有三种可能的结果。 首先,异常实例被正确分割并分类为训练类之一(即鸟被混淆为人)(顶部)。 其次,异常实例被多个类过度分割(即狗被检测为人、植被和地形类的组合)(中)。 第三,异常实例与背景混合,未检测到(即框与街道分割混合)(底部)。 我们提出的方法对所有场景都产生了鲁棒的预测,而以前的方法至少不能处理其中一个。
第二组侧重于从预测的语义图重新合成输入图像,然后比较两个图像(输入和生成)以发现异常。 这些模型在处理分割过度自信时显示出有希望的结果,但在分割输出未知对象的噪声预测时失败,如图 1(中)所示。 这种失败的原因是合成模型无法重建语义图的噪声块,这使得查找输入图像和合成图像之间的差异变得复杂。
在本文中,我们提出了一种新颖的像素级异常框架,该框架结合了不确定性和重新合成方法,以便对不同的异常场景产生稳健的预测。我们的实验表明,不确定性和重新综合方法是相互补充的,当分割网络遇到异常时,它们一起涵盖了不同的结果。
我们的框架建立在以前的重新合成方法 [24,12,38] 的基础上,将分割未知类的问题重新表述为从预测的语义图中识别输入图像和重新合成图像之间的差异之一。
我们通过集成不同的不确定性度量来改进这些框架,例如 softmax 熵 [10, 21]、softmax 差异 [31] 和感知差异 [16, 8],以帮助差异网络区分输入和生成的图像。
所提出的框架成功地推广到所有异常场景,如图 1 所示,只需最少的额外计算工作,并且无需重新训练网络,这是其他异常检测器的一个常见缺陷 [3 , 26, 27]。除了保持最先进的分割性能外,消除重新训练的需要还降低了向未来分割网络添加异常检测器的复杂性,因为训练这些网络并非易事。
我们在异常检测的公共基准测试中评估我们的框架,在其中我们与类似于我们的不影响分割准确性的方法以及需要完全重新训练的方法进行比较。我们还证明了我们的框架能够推广到不同的分割和合成网络,即使这些模型的性能较低。我们用更轻的架构替换分割和合成模型,以便在自动驾驶等时间关键型场景中优先考虑速度。总之,我们的贡献如下:
– 我们提出了一种新颖的逐像素异常检测框架,该框架利用了现有不确定性和重新合成方法的最佳特征。
– 我们的方法对不同的异常场景具有鲁棒性,在 Fishyscapes 基准上实现最先进的性能,同时保持最先进的分割精度。
– 我们提出的框架能够推广到不同的分割和合成网络,作为现有分割pipline的包装方法。
2. 相关工作
在分布外(OoD)检测和异常分割领域内研究了在语义分割中定位异常实例的任务。
在本节中,我们回顾了可用于逐像素异常检测的方法,并排除了只能应用于图像级 OoD 分类的方法。
2.1. Anomaly Segmentation via Uncertainty Estimation
估计给定输入模型不确定性的方法可能会估计非异常输入的高不确定性,例如由于高输入噪声。无论这种差异和其他差异如何,异常检测都是不确定性估计的常用基准方法,基于异常输入应该具有比任何训练数据更高的不确定性的假设。
早期的方法从预测的 softmax 分布中测量不确定性,并通过使用简单的统计数据将样本分类为 OoD [14、22、23]。虽然这些方法是图像级 OoD 分类的良好基准,但它们通常在异常分割中失败。具体来说,估计的(偶然的)不确定性在对象边界处通常很高,其中没有一个标签可以确定地分配,而不是在异常情况下如所期望的那样。 [31] 通过聚合不同的色散测量(例如,熵和 softmax 概率的差异),然后预测分割中潜在的高误差区域来缓解这一缺点。然后,[28] 证明这些高误差区域可用于通过视觉特征差异来定位异常。
替代方法使用带有 MC dropout 的贝叶斯 NN 来估计像素不确定性 [18、27、21]。 这些方法区分了偶然性(观察中固有的噪声)和认知不确定性(模型中的不确定性),因此减轻了对象边界的问题,但仍然无法准确地检测像素级别的异常。 如 [24] 所示,它们产生了许多false positive预测,以及异常实例和不确定区域之间的不匹配。
2.2. Anomaly Segmentation via Outlier Exposure
异常分割也可以通过训练网络来完成,通过使用异常值的辅助数据集 [15] 来区分异常值和未见过的样本。 [2] 是使用 ImageNet [32] 作为 OoD 数据集使用异常值曝光进行密集预测的首批方法之一。 然后,[3] 通过修改分割网络来预测语义图和异常值图,以此方法为基础。 请注意,这需要将分割网络重新训练为多任务模型,这导致性能下降 [36]。 这些方法的最大缺点是它们从 OoD 样本中进行训练,这可能会损害它们泛化到所有可能异常的能力。
2.3. Anomaly Segmentation via Image Re-synthesis
最近有希望的方法遵循使用生成模型重建输入图像的方法。 这种方法背后的直觉是,生成的图像将相对于存在异常的输入图像产生外观差异,因为模型无法处理这些实例。 该子领域的早期工作使用自动编码器重新合成原始图像 [1, 7]。 然而,这些方法大多生成输入图像的低质量版本 [24]。 最近的方法 [38, 12, 24] 使用生成对抗网络从预测的语义图中重新合成输入图像。 然后通过差异或比较模块将照片般逼真的图像与原始图像进行比较,以定位异常实例。
这些方法受益于不需要重新训练分割网络,因为它们作为包装方法工作。 此外,它们不需要 OoD 样本,这有助于它们泛化到从未见过的异常实例。 然而,这些方法的性能受到差异模块区分输入和生成图像中特征的能力的限制,这对于复杂的驾驶场景可能具有挑战性。 通过我们的工作,我们证明了将场景的不确定性信息提供给差异网络可以显着提高模块检测异常的能力。
方法
我们提出了一个用于分割异常实例的检测框架。 我们的框架受到最近的重新合成方法 [24, 38] 的启发,同时将它们扩展到包括不确定性估计方法的好处 [28, 31]。 我们首先介绍我们的框架及其各自的模块(第 3.1 节)。 接下来,我们将描述如何训练模块以更好地处理不同的异常情况(第 3.2 节)。 最后,我们将框架的输出与计算的不确定性图相结合,形成最终的集成方法,以减少预测中的false positives和过度自信(第 3.3 节)。
3.1. Pixel-wise Anomaly Detection Framework
我们提出的框架遵循与 [24] 和 [12] 相同的基本结构,其中输入图像被分割,从分割图合成重建,并且相异模块通过比较输入图像和合成图像来检测异常。 然而,我们扩展了每个组件来预测和/或使用不确定性测量来改进最终的异常预测。 图 2 显示了我们框架。
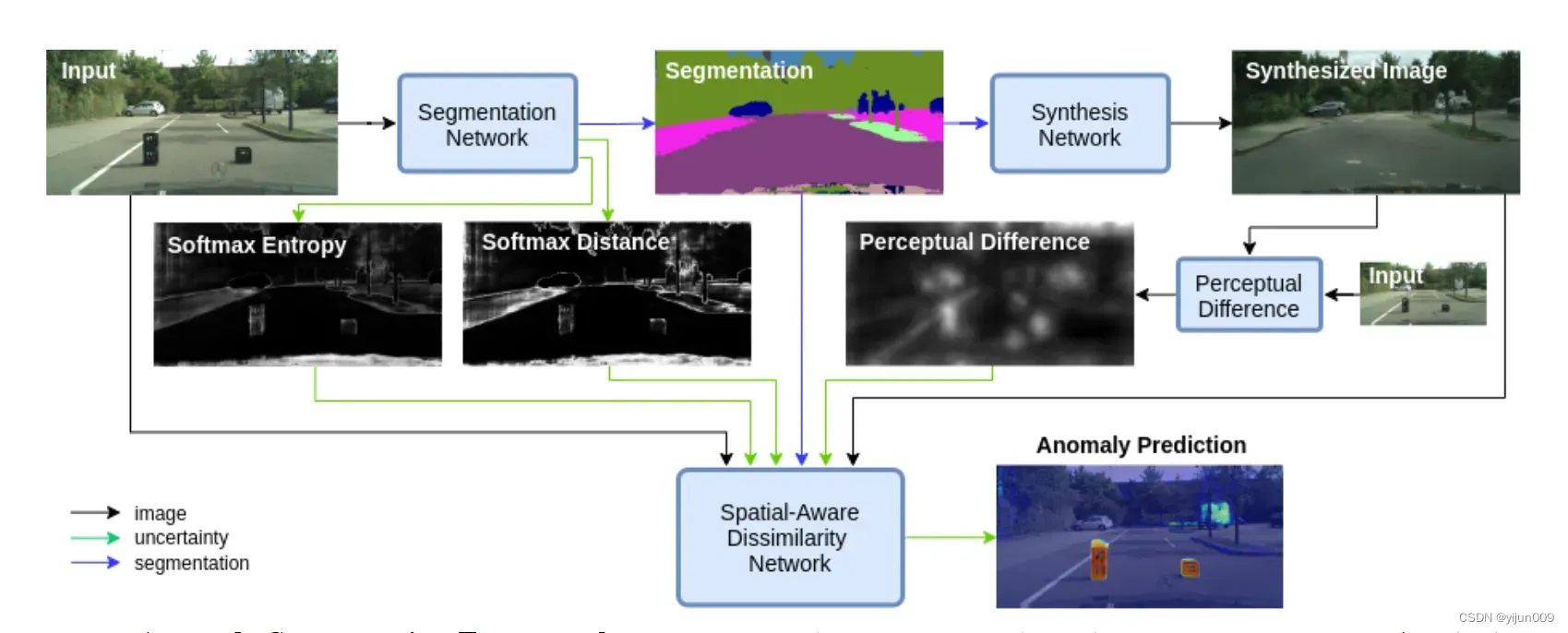
图 2.异常分割框架。 我们首先将输入图像通过一个分割网络,该网络将输出一个语义图和两个不确定性图。 然后由合成网络处理预测的语义图以生成照片般逼真的图像。 然后通过比较输入图像和生成图像之间的特征来计算感知差异。 最后,所有预测图像和输入都被发送到空间感知相异性模块以产生异常预测。
3.1.1 Segmentation Module
分割模块获取输入图像并将其馈送到分割网络,例如 [42] 或 [40],以获得语义图。 除了语义图,我们还计算了两个离散度量来量化语义图预测中的不确定性。 这两个色散测量是 softmax 熵 和 softmax 距离
(即两个最大 softmax 值之间的差异),这已证明有助于理解分割中的错误 [31] . 对于每个像素
,这两个测量值计算如下:
其中 是
类的 softmax 概率。 我们将这两个数量标准化为
。
3.1.2 Synthesis Module
合成模块从给定的语义映射中生成具有像素到像素对应关系的逼真图像。它被训练为条件生成对抗网络(cGAN)[37, 25],以将生成分布拟合到来自语义模型的输入图像的分布。虽然合成模块经过训练可以生成逼真的图像,并且能够很好地生成逼真的汽车、建筑物或行人,但语义图会遗漏颜色或外观等基本信息,以便进行直接的像素值比较。因此,我们计算原始图像和合成图像之间的感知差异 V。这种新颖的特征图的灵感来自 [16] 和 [8] 中提出的感知损失,这通常用于 cGANs 方法。这个想法是使用 ImageNet [32] 预训练的 VGG 作为特征提取器 [33] 来找到具有最不同特征表示的像素。这些表示的差异使我们能够根据对象的图像内容和空间结构来比较对象,而不是像颜色和纹理这样的低级特征。如果未检测到异常对象或错误分类,则合成图像将生成错误的特征表示,因此感知差异应检测与输入图像的这些差异。
对于输入图像的每个像素和合成图像的对应像素
,感知差异计算如下:
其中 表示VGG网络具有 $M_{i}个元素的第
层$ 和N层。 为了保持一致性,这些分散度量也在 [0, 1] 之间进行了归一化。
3.1.3 Dissimilarity Module
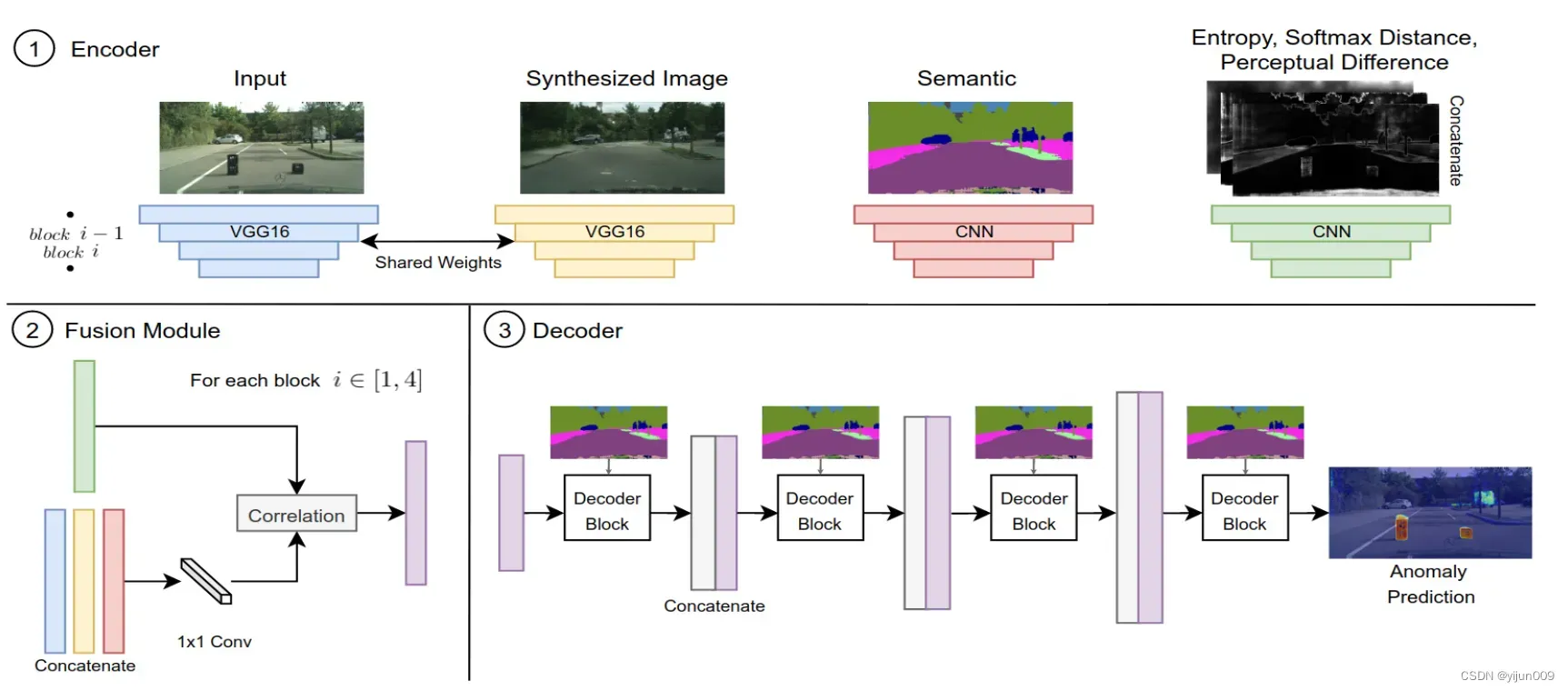
相异性模块将原始图像、生成图像和语义图以及在前面步骤中计算的不确定性图(softmax 熵、softmax 距离、感知差异)作为输入。 然后,网络结合这些特征来预测异常分割图。 如图 3 所示,相异模块分为三个组件(编码器、融合模块和解码器)。实现细节可在附录 A.1 中找到。
编码器。 每个图像都通过一个编码器来提取特征。与 [24] 类似,我们对原始和重新合成的图像使用预训练的 VGG [33] 网络以及简单的 CNN 来处理语义图。我们还添加了另一个简单的 CNN 来编码不确定性图,它们都是连接的。
融合模块。 在特征金字塔的每一层,我们将输入、合成和语义特征图连接起来,并通过一个 1×1 的卷积传递它们。通过这第一步,我们正在训练网络以区分原始图像和生成的图像,因为这在重新合成方法中很常见。此外,我们使用生成的特征图并与不确定性特征图执行逐点相关。这一步引导网络关注特征图中的高不确定性区域。
解码器。 然后我们解码每个特征图并将其与金字塔中相应的更高级别连接起来,直到我们得到我们的异常分割预测。请注意,解码器块使用语义图作为输入,因为它使用了 [29] 中提出的空间感知归一化。这种标准化用于确保语义信息在解码过程中不会被冲走。
3.2. Training Procedure
根据定义,异常实例包括任何不属于训练类的对象。因此,确保所提出的方法能够检测任何异常并且不会过度拟合来自 OoD 数据集的特定对象,这一点至关重要。此外,训练需要通用以涵盖图 1 的所有三个异常场景。
分割和合成模块仅在内部分割数据集上进行训练。因此,这没有对异常的任何假设,并且还确保了分割模块仅针对分割任务进行训练,而无需平衡任何其他因素。
为了训练相异性模块,[24] 通过生成合成数据来模拟存在异常的分割图,解决了没有 OoD 数据集的问题。该方法将gt语义图中的随机选择对象实例类替换为替代随机类。然后,这些改变的语义图被合成(使用已经训练的模块),在真实图像和生成图像之间产生视觉差异。差异网络使用这些差异来训练和检测差异。尽管这种方法不需要在训练期间看到 OoD 对象,但它无法训练完全鲁棒的逐像素异常检测。首先,该训练数据生成器仅涵盖一种异常情况(图 1 – 顶部),但缺少其他两种情况的示例。其次,这种方法使用gt语义图训练相异网络,但在推理过程中,它使用预测图。这种分布变化会对网络检测异常的性能产生负面影响。最后,具体到 Sec3.1 中介绍的方法 ,改变的实例不会与不确定的区域相关联。因此,这些训练示例无法利用来自不确定性地图的信息。
我们通过添加第二个训练数据源来扩展训练数据生成器。 具体来说,我们将gt语义图中 void 类中的对象标记为异常。 void 类通常用于分割数据集 [6] 以覆盖不属于任何训练类的对象,这属于异常的定义。 这种额外的标签来源帮助我们克服了以前数据生成器的挑战。 首先,这些空白区域中的预测语义图将与推理过程中看到的三种异常情况密切匹配(图 1),而不仅仅是一个。 其次,相异性网络将使用预测的语义图进行训练,而不是使用gt进行训练,这会阻止推理过程中的任何域适应。 最后,空白区域通常与高不确定性像素匹配,这些像素引导相异性网络使用不确定性信息。
请注意,通过将这些 void 类对象添加为异常,我们失去了在训练期间不需要 OoD 数据的好处。 然而,通过使用这两种方法,我们提出的方法仍然能够推广到看不见的对象,如 Sec. 4.2.
3.3. Predictions Ensemble
到目前为止,我们已经使用计算出的不确定性映射(即 softmax 熵、softmax 距离和感知差异)作为相异模块中的注意机制。 然而,如 [31] 和 [28] 所示,这些不确定性map本身已经是异常预测。 因此,我们可以利用不确定性估计来补充相异网络的输出,以检测所有异常情况。 通过这个集合,我们减轻了对相异网络的任何可能的过度自信,这是深度学习模型中的一个常见问题,如 [11] 所述。 我们使用加权平均来集成这些预测,其中权重是通过网格搜索选择的。 此外,我们测试了在不同网络的端到端训练中学习集成权重。 这些结果并不令人满意,因为网络仍然会产生过度自信的预测。 有关端到端训练的更多详细信息,请参见附录 A.4。
实验
表格
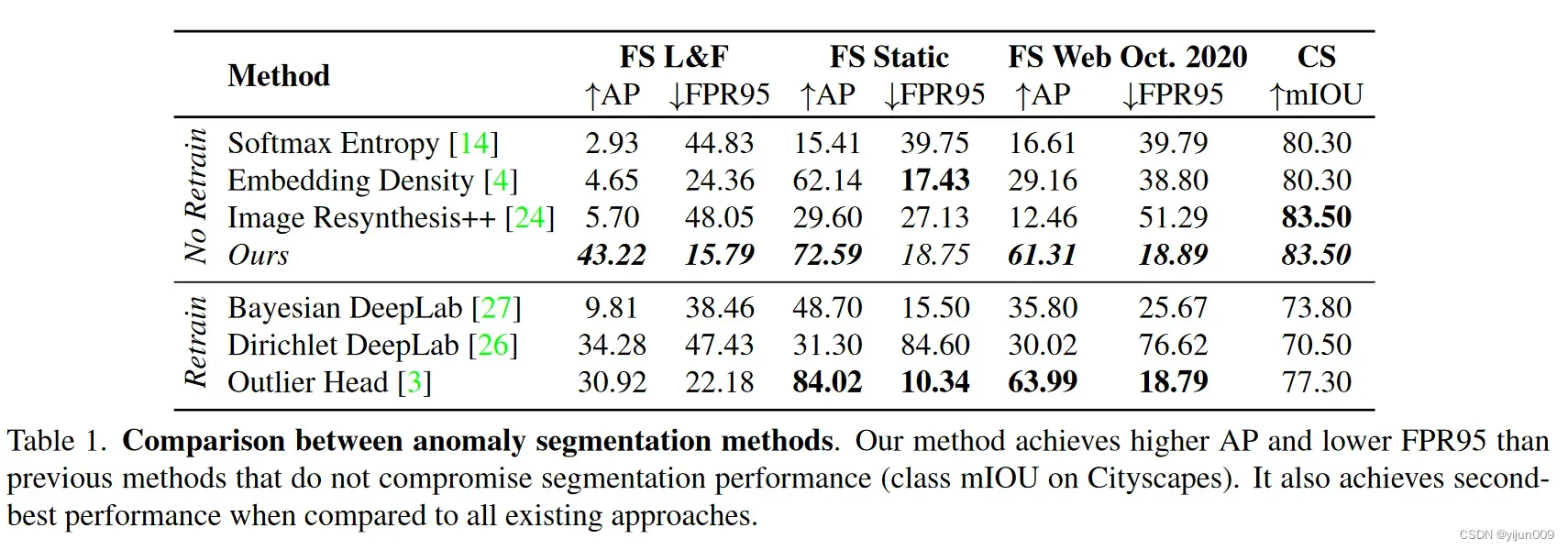
文章出处登录后可见!