博主先前整理并简单介绍了AI绘图工具的部署资源与攻略,觉得其中Stable Diffusion部分不够带劲,故开始试图从论文与代码中一探究竟。前文链接如下:
要点初见:AI绘图工具的部署资源、攻略整理(上篇)_BingLiHanShuang的博客-CSDN博客_ai绘图
要点初见:AI绘图工具的部署资源、攻略整理(下篇)_BingLiHanShuang的博客-CSDN博客
最近Stable Diffusion实在是太火爆了,在B站上看up主分析论文的视频,分P分析到引言部分就戛然而止,后续视频全是各种整合包的分享与实操,单个视频的播放量也直线上升hhh
本文将分为2个部分:
上半部分深入分析Stable Diffusion所对应的论文High-Resolution Image Synthesis with Latent Diffusion Models,即《具有潜在扩散模型的高分辨率图像合成》,论文链接如下:https://arxiv.org/pdf/2112.10752.pdf
下半部分深入Stable Diffusion项目代码,代码主要由Python撰写,分析文本转图像部分的代码(模型核心部分将在下篇进行分析)。
一、Stable Diffusion论文分析
《具有潜在扩散模型的高分辨率图像合成》在概述部分将Stable Diffusion分为2个阶段:
第一个阶段为感知压缩阶段(perceptual compression),训练了一个预训练的自编码器(pretrained autoencoders)用于下采样、上采样,自编码器学习到的是一个潜在的空间(latent space),比像素空间小很多,扩散模型在该潜在空间中训练;
第二阶段是扩散模型,语义压缩阶段,在下采样、上采样之间,引入了一个针对文本、边界框、图像的交叉注意力层(cross-attention layers)。
这样整个模型只需要训练降采样和插值之间的部分即可,大大降低了对算力的要求,降低了训练时间,这个模型也被叫做Latent Diffusion Models。
文章对核心模型的介绍主要分为感知压缩模型、潜在扩散模型、调节机制三部分。
1、感知压缩模型
感知压缩模型由一个通过感知损失和基于补丁的对抗性目标组合训练的自动编码器组成,这确保通过强制执行局部真实性将重建限制在图像流形中,并避免仅依靠像素空间损失(例如L2或L1目标)引入的模糊。
为了避免任意高方差的潜在空间,论文尝试了KL-reg、VQ-reg两种正则化方法:其中KL-reg类似于VAE,对学习潜伏的标准法线施加轻微的KL惩罚;而VQ-reg在解码器中使用矢量量化层,该模型可以解释为量化层被解码器吸收的VQGAN。
2、潜在扩散模型
扩散模型是概率模型,旨在通过逐渐去噪正态分布变量来学习数据分布。
文中的模型可以根据不同图像提供对应的归纳偏差,其中包括主要从2D卷积层构建底层UNet的能力,并使重新加权的边界进一步将目标集中在感知最相关位的目标上。文中模型的核心神经网络被实现为时序UNet,由于前向的过程是固定的,因此可以在训练期间从E中高效地获得zt,并且可以通过D单次将来自数据分布的样本解码到图像空间,如下图。
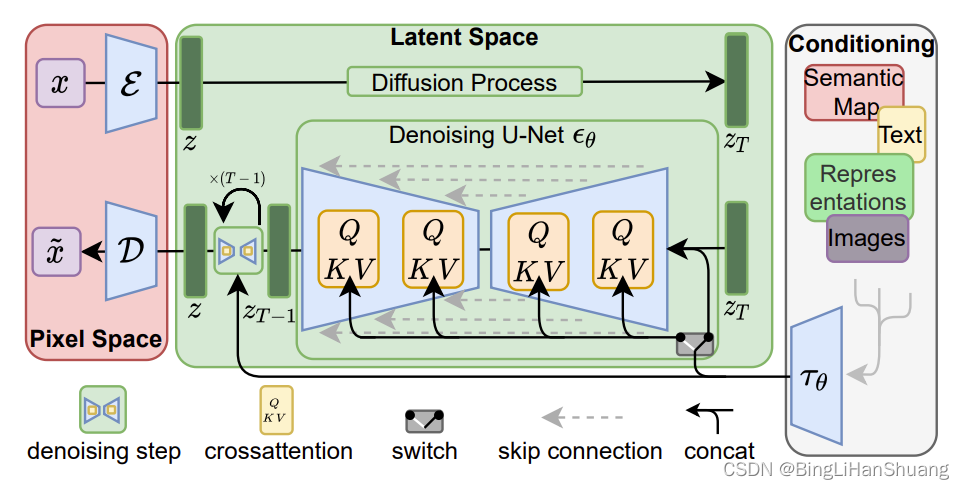
3、调节机制
调节机制方面,通过使用交叉注意机制增强其底层UNet主干,将DM转变为更灵活的条件图像生成器,从而能对于学习各种输入模式的基于注意的模型有效。
文章最后介绍了模型的局限性,一是顺序采样过程仍然比GAN慢,二是在高精度场景的效果可能不如意(虽然目前4倍超分辨率效果很好)。作者接下来将基于GAN的方法,研究结合对抗性训练和基于可能性的目标的两阶段方法在多大程度上歪曲了数据。(如何在确保真实性的基础上确保多样性)
二、Stable Diffusion代码分析
本文暂先分析文本转图像部分的执行代码scripts\txt2img.py:
1、库文件导入
import argparse, os, sys, glob
import cv2
import torch
import numpy as np
from omegaconf import OmegaConf
from PIL import Image
from tqdm import tqdm, trange
from imwatermark import WatermarkEncoder
from itertools import islice
from einops import rearrange
from torchvision.utils import make_grid
import time
from pytorch_lightning import seed_everything
from torch import autocast
from contextlib import contextmanager, nullcontext
from ldm.util import instantiate_from_config
from ldm.models.diffusion.ddim import DDIMSampler
from ldm.models.diffusion.plms import PLMSSampler
from diffusers.pipelines.stable_diffusion.safety_checker import StableDiffusionSafetyChecker
from transformers import AutoFeatureExtractor其中起主导作用的是:
cv2(Python版OpenCV库,一款计算机视觉库);
torch(PyTorch,一款Python机器学习库);
imwatermark(隐形水印添加库,stable diffusion源码中都被添加了“StableDiffusionV1”的隐形水印,不过我看了webui版没有这个);
ldm(Python中的扩散模型库,stable diffusion图像生成的核心);
diffusers(扩散Diffusion模型包);
transformers(PyTorch的最新自然语言处理库);
2、NOT SAFE FOR WORK?
# load safety model
safety_model_id = "CompVis/stable-diffusion-safety-checker"
safety_feature_extractor = AutoFeatureExtractor.from_pretrained(safety_model_id)
safety_checker = StableDiffusionSafetyChecker.from_pretrained(safety_model_id)简称NSFW,简单说就是设定是否生成正经的内容,是否避免生成不宜的内容(;OдO)。Stable Diffusion默认设定为SAFE FOR WORK的,通过下述函数实现:
def check_safety(x_image):
safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt")
x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values)
assert x_checked_image.shape[0] == len(has_nsfw_concept)
for i in range(len(has_nsfw_concept)):
if has_nsfw_concept[i]:
x_checked_image[i] = load_replacement(x_checked_image[i])
return x_checked_image, has_nsfw_concept如果想取消NSFW,请将check_safety函数替换为:
def check_safety(x_image):
# safety_checker_input = safety_feature_extractor(numpy_to_pil(x_image), return_tensors="pt")
# x_checked_image, has_nsfw_concept = safety_checker(images=x_image, clip_input=safety_checker_input.pixel_values)
# assert x_checked_image.shape[0] == len(has_nsfw_concept)
# for i in range(len(has_nsfw_concept)):
# if has_nsfw_concept[i]:
# x_checked_image[i] = load_replacement(x_checked_image[i])
return x_image, False简单说就是将输入的image不经过check safety直接返回给输出,至于第二个参数因在主函数中后续没有被使用,故随便返回一个False即可。
确认了一下,webui版本的NSFW是默认关闭的,因此网上的NovelAI“咒语”大都把nsfw加入negative tag中。肯定有人有大胆的想法……不,你不想( ̄▽ ̄)/
3、命令调用IO设置
parser = argparse.ArgumentParser()
parser.add_argument(
"--prompt",
type=str,
nargs="?",
default="a painting of a virus monster playing guitar",
help="the prompt to render"
)
parser.add_argument(
"--outdir",
type=str,
nargs="?",
help="dir to write results to",
default="outputs/txt2img-samples"
)
parser.add_argument(
"--skip_grid",
action='store_true',
help="do not save a grid, only individual samples. Helpful when evaluating lots of samples",
)
parser.add_argument(
"--skip_save",
action='store_true',
help="do not save individual samples. For speed measurements.",
)
parser.add_argument(
"--ddim_steps",
type=int,
default=50,
help="number of ddim sampling steps",
)
parser.add_argument(
"--plms",
action='store_true',
help="use plms sampling",
)
parser.add_argument(
"--laion400m",
action='store_true',
help="uses the LAION400M model",
)
parser.add_argument(
"--fixed_code",
action='store_true',
help="if enabled, uses the same starting code across samples ",
)
parser.add_argument(
"--ddim_eta",
type=float,
default=0.0,
help="ddim eta (eta=0.0 corresponds to deterministic sampling",
)
parser.add_argument(
"--n_iter",
type=int,
default=2,
help="sample this often",
)
parser.add_argument(
"--H",
type=int,
default=512,
help="image height, in pixel space",
)
parser.add_argument(
"--W",
type=int,
default=512,
help="image width, in pixel space",
)
parser.add_argument(
"--C",
type=int,
default=4,
help="latent channels",
)
parser.add_argument(
"--f",
type=int,
default=8,
help="downsampling factor",
)
parser.add_argument(
"--n_samples",
type=int,
default=3,
help="how many samples to produce for each given prompt. A.k.a. batch size",
)
parser.add_argument(
"--n_rows",
type=int,
default=0,
help="rows in the grid (default: n_samples)",
)
parser.add_argument(
"--scale",
type=float,
default=7.5,
help="unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))",
)
parser.add_argument(
"--from-file",
type=str,
help="if specified, load prompts from this file",
)
parser.add_argument(
"--config",
type=str,
default="configs/stable-diffusion/v1-inference.yaml",
help="path to config which constructs model",
)
parser.add_argument(
"--ckpt",
type=str,
default="models/ldm/stable-diffusion-v1/model.ckpt",
help="path to checkpoint of model",
)
parser.add_argument(
"--seed",
type=int,
default=42,
help="the seed (for reproducible sampling)",
)
parser.add_argument(
"--precision",
type=str,
help="evaluate at this precision",
choices=["full", "autocast"],
default="autocast"
)
opt = parser.parse_args()这一块对应Readme中的:
usage: txt2img.py [-h] [--prompt [PROMPT]] [--outdir [OUTDIR]] [--skip_grid] [--skip_save] [--ddim_steps DDIM_STEPS] [--plms] [--laion400m] [--fixed_code] [--ddim_eta DDIM_ETA]
[--n_iter N_ITER] [--H H] [--W W] [--C C] [--f F] [--n_samples N_SAMPLES] [--n_rows N_ROWS] [--scale SCALE] [--from-file FROM_FILE] [--config CONFIG] [--ckpt CKPT]
[--seed SEED] [--precision {full,autocast}]
optional arguments:
-h, --help show this help message and exit
--prompt [PROMPT] the prompt to render
--outdir [OUTDIR] dir to write results to
--skip_grid do not save a grid, only individual samples. Helpful when evaluating lots of samples
--skip_save do not save individual samples. For speed measurements.
--ddim_steps DDIM_STEPS
number of ddim sampling steps
--plms use plms sampling
--laion400m uses the LAION400M model
--fixed_code if enabled, uses the same starting code across samples
--ddim_eta DDIM_ETA ddim eta (eta=0.0 corresponds to deterministic sampling
--n_iter N_ITER sample this often
--H H image height, in pixel space
--W W image width, in pixel space
--C C latent channels
--f F downsampling factor
--n_samples N_SAMPLES
how many samples to produce for each given prompt. A.k.a. batch size
--n_rows N_ROWS rows in the grid (default: n_samples)
--scale SCALE unconditional guidance scale: eps = eps(x, empty) + scale * (eps(x, cond) - eps(x, empty))
--from-file FROM_FILE
if specified, load prompts from this file
--config CONFIG path to config which constructs model
--ckpt CKPT path to checkpoint of model
--seed SEED the seed (for reproducible sampling)
--precision {full,autocast}
evaluate at this precision即使用txt2img.py脚本的方法,例如官方调用示例:
python scripts/txt2img.py --prompt "a photograph of an astronaut riding a horse" --plms 4、内部参数设置
if opt.laion400m:
print("Falling back to LAION 400M model...")
opt.config = "configs/latent-diffusion/txt2img-1p4B-eval.yaml"
opt.ckpt = "models/ldm/text2img-large/model.ckpt"
opt.outdir = "outputs/txt2img-samples-laion400m"
seed_everything(opt.seed)
config = OmegaConf.load(f"{opt.config}")
model = load_model_from_config(config, f"{opt.ckpt}")
device = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
model = model.to(device)
if opt.plms:
sampler = PLMSSampler(model)
else:
sampler = DDIMSampler(model)
os.makedirs(opt.outdir, exist_ok=True)
outpath = opt.outdir对模型内部参数config、ckpt、outdir、device、model、sampler、outpath等参数的具体设定。
5、隐形水印设置
在这里特别分析一下txt2img.py中的隐形水印这一块:
print("Creating invisible watermark encoder (see https://github.com/ShieldMnt/invisible-watermark)...")
wm = "StableDiffusionV1"
wm_encoder = WatermarkEncoder()
wm_encoder.set_watermark('bytes', wm.encode('utf-8'))wm中的内容即是通过imwatermark添加的隐形水印文本,可以改成自己想添加的隐形水印文本,从而在生成的图片中附带着隐形的水印。
txt2img.py中的隐形水印添加代码:
img = put_watermark(img, wm_encoder)def put_watermark(img, wm_encoder=None):
if wm_encoder is not None:
img = cv2.cvtColor(np.array(img), cv2.COLOR_RGB2BGR)
img = wm_encoder.encode(img, 'dwtDct')
img = Image.fromarray(img[:, :, ::-1])
return img需要关注的是相比于imwatermark对普通png图像的隐形水印添加代码,此处将RGB转为了BGR后才叠加了水印,再通过Image.fromarray(img[:, :, ::-1])转回RGB通道。
若想看一张图是否有imwatermark添加的隐形水印,可以使用python执行下述脚本可以获取水印输出(但需要注意是否要把BGR转成RGB):
#!/usr/bin/env python3
import cv2
from imwatermark import WatermarkDecoder
bgr = cv2.imread('cat_wm.png')
decoder = WatermarkDecoder('bytes', 32)
watermark = decoder.decode(bgr, 'dwtDct')
print(watermark.decode('utf-8'))
6、读取输入的文字描述
batch_size = opt.n_samples
n_rows = opt.n_rows if opt.n_rows > 0 else batch_size
if not opt.from_file:
prompt = opt.prompt
assert prompt is not None
data = [batch_size * [prompt]]
else:
print(f"reading prompts from {opt.from_file}")
with open(opt.from_file, "r") as f:
data = f.read().splitlines()
data = list(chunk(data, batch_size))
sample_path = os.path.join(outpath, "samples")
os.makedirs(sample_path, exist_ok=True)
base_count = len(os.listdir(sample_path))
grid_count = len(os.listdir(outpath)) - 1
start_code = None
if opt.fixed_code:
start_code = torch.randn([opt.n_samples, opt.C, opt.H // opt.f, opt.W // opt.f], device=device)
precision_scope = autocast if opt.precision=="autocast" else nullcontext此段代码将输入的所有batch的prompt(即输入的正面负面tag)打包进data中,末尾通过PyTorch的autocast设置半精度格式(即float16,字节数是通常使用的float(float32)的一半,只有2个char的长度),以大幅节省模型数据的IO时间、训练推理时间。autocast的定义如下:
class torch.autocast(device_type, enabled=True, **kwargs)txt2img.py中通过
with precision_scope("cuda"):调用,即意味着接下来的代码推理采用GPU资源,并使用Float16格式。半精度Float16对GPU运算的性能优化意义非凡,只要变量的minmax值在float16的定义范围内(具体要根据fp16所属库查询),且能接受相对于float32的精度损失,在GPU中使用fp16的性能相对于fp32能提升30%~50%。
模型核心部分将在下篇进行分析,欢迎交流与讨论!

{ {alice}}, alice in wonderland, { { {solo}}},1girl,{ {delicate face}},vely long hair,blunt_bangs,{ { {full body}}},{floating hair}, {looking_at_viewer},open mouth,{looking_at_viewer},open mouth,blue eyes,Blonde_hair,Beautiful eyes,gradient hair,{ {white_frilled_dress}},{ {white pantyhose}}, {long sleeves},{juliet_sleeves},{puffy sleeves},white hair bow, Skirt pleats, blue dress bow, blue_large_bow,{ { {stading}}},{ { {arms behind back}}},sleeves past wrists,sleeves past fingers,{forest}, flowering hedge, scenery,Flowery meadow,clear sky,{delicate grassland},{blooming white roses},flying butterfly,shadow,beautiful sky,cumulonimbus,{ {absurdres}},incredibly_absurdres, huge_filesize, {best quality},{masterpiece},delicate details,refined rendering,original,official_art, 10s,
Negative prompt:
lowres,highres, worst quality,low quality,normal quality,artbook, game_cg, duplicate,grossproportions,deformed,out of frame,60s,70s,80s,90s,00s, ugly,morbid,mutation,death, kaijuu,mutation,no hunmans.monster girl,arthropod girl,arthropod limbs,tentacles,blood,size difference,sketch,blurry,blurry face,blurry background,blurry foreground, disfigured,extra,extra_arms,extra_ears,extra_breasts,extra_legs,extra_penises,extra_mouth,multiple_arms,multiple_legs,mutilated,tranny,trans,trannsexual,out of frame,poorly drawnhands,extra fingers,mutated hands, poorly drawn face, bad anatomy,bad proportions, extralimbs,more than 2 nipples,extra limbs,bad anatomy,malformed limbs,missing arms,miss finglegs,mutated hands,fused fingers,too many fingers,long neck,bad finglegs,cropped, bad feet,bad anatomy disfigured,malformed mutated,missing limb,malformed hands,
Steps: 50, Sampler: DDIM, CFG scale: 7, Size: 1024×1024
文章出处登录后可见!