您或许知道,作者后续分享网络安全的文章会越来越少。但如果您想学习人工智能和安全结合的应用,您就有福利了,作者将重新打造一个《当人工智能遇上安全》系列博客,详细介绍人工智能与安全相关的论文、实践,并分享各种案例,涉及恶意代码检测、恶意请求识别、入侵检测、对抗样本等等。只想更好地帮助初学者,更加成体系的分享新知识。该系列文章会更加聚焦,更加学术,更加深入,也是作者的慢慢成长史。换专业确实挺难的,系统安全也是块硬骨头,但我也试试,看看自己未来四年究竟能将它学到什么程度,漫漫长征路,偏向虎山行。享受过程,一起加油~
前一篇文章介绍安全相关的数据集供大家下载和实验,包括恶意URL、流量分析、域名检测、恶意软件、图像分类、垃圾邮件等。这篇文章将讲解如何学习提取的API序列特征,并构建机器学习算法实现恶意家族分类,这也是安全领域典型的任务或工作。基础性文章,希望对您有所帮助~
文章目录
- 一.恶意软件分析
- 1.静态特征
- 2.动态特征
- 二.基于逻辑回归的恶意家族检测
- 1.数据集
- 2.模型构建
- 三.基于SVM的恶意家族检测
- 1.SVM模型
- 2.代码实现
- 四.基于随机森林的恶意家族检测
- 五.总结
作者作为网络安全的小白,分享一些自学基础教程给大家,主要是在线笔记,希望您们喜欢。同时,更希望您能与我一起操作和进步,后续将深入学习AI安全和系统安全知识并分享相关实验。总之,希望该系列文章对博友有所帮助,写文不易,大神们不喜勿喷,谢谢!如果文章对您有帮助,将是我创作的最大动力,点赞、评论、私聊均可,一起加油喔!
前文推荐:
- [当人工智能遇上安全] 1.人工智能真的安全吗?浙大团队外滩大会分享AI对抗样本技术
- [当人工智能遇上安全] 2.清华张超老师 – GreyOne: Discover Vulnerabilities with Data Flow Sensitive Fuzzing
- [当人工智能遇上安全] 3.安全领域中的机器学习及机器学习恶意请求识别案例分享
- [当人工智能遇上安全] 4.基于机器学习的恶意代码检测技术详解
- [当人工智能遇上安全] 5.基于机器学习算法的主机恶意代码识别研究
- [当人工智能遇上安全] 6.基于机器学习的入侵检测和攻击识别——以KDD CUP99数据集为例
- [当人工智能遇上安全] 7.基于机器学习的安全数据集总结
- [当人工智能遇上安全] 8.基于API序列和机器学习的恶意家族分类实例详解
作者的github资源:
- https://github.com/eastmountyxz/AI-Security-Paper
一.恶意软件分析
恶意软件或恶意代码分析通常包括静态分析和动态分析。特征种类如果按照恶意代码是否在用户环境或仿真环境中运行,可以划分为静态特征和动态特征。
那么,如何提取恶意软件的静态特征或动态特征呢? 因此,第一部分将简要介绍静态特征和动态特征。
1.静态特征
没有真实运行的特征,通常包括:
- 字节码:二进制代码转换成了字节码,比较原始的一种特征,没有进行任何处理
- IAT表:PE结构中比较重要的部分,声明了一些函数及所在位置,便于程序执行时导入,表和功能比较相关
- Android权限表:如果你的APP声明了一些功能用不到的权限,可能存在恶意目的,如手机信息
- 可打印字符:将二进制代码转换为ASCII码,进行相关统计
- IDA反汇编跳转块:IDA工具调试时的跳转块,对其进行处理作为序列数据或图数据
- 常用API函数
- 恶意软件图像化
静态特征提取方式:
- CAPA
– https://github.com/mandiant/capa - IDA Pro
- 安全厂商沙箱
2.动态特征
相当于静态特征更耗时,它要真正去执行代码。通常包括:
– API调用关系:比较明显的特征,调用了哪些API,表述对应的功能
– 控制流图:软件工程中比较常用,机器学习将其表示成向量,从而进行分类
– 数据流图:软件工程中比较常用,机器学习将其表示成向量,从而进行分类
动态特征提取方式:
- Cuckoo
– https://github.com/cuckoosandbox/cuckoo - CAPE
– https://github.com/kevoreilly/CAPEv2
– https://capev2.readthedocs.io/en/latest/ - 安全厂商沙箱
二.基于逻辑回归的恶意家族检测
前面的系列文章详细介绍如何提取恶意软件的静态和动态特征,包括API序列。接下来将构建机器学习模型学习API序列实现分类。基本流程如下:
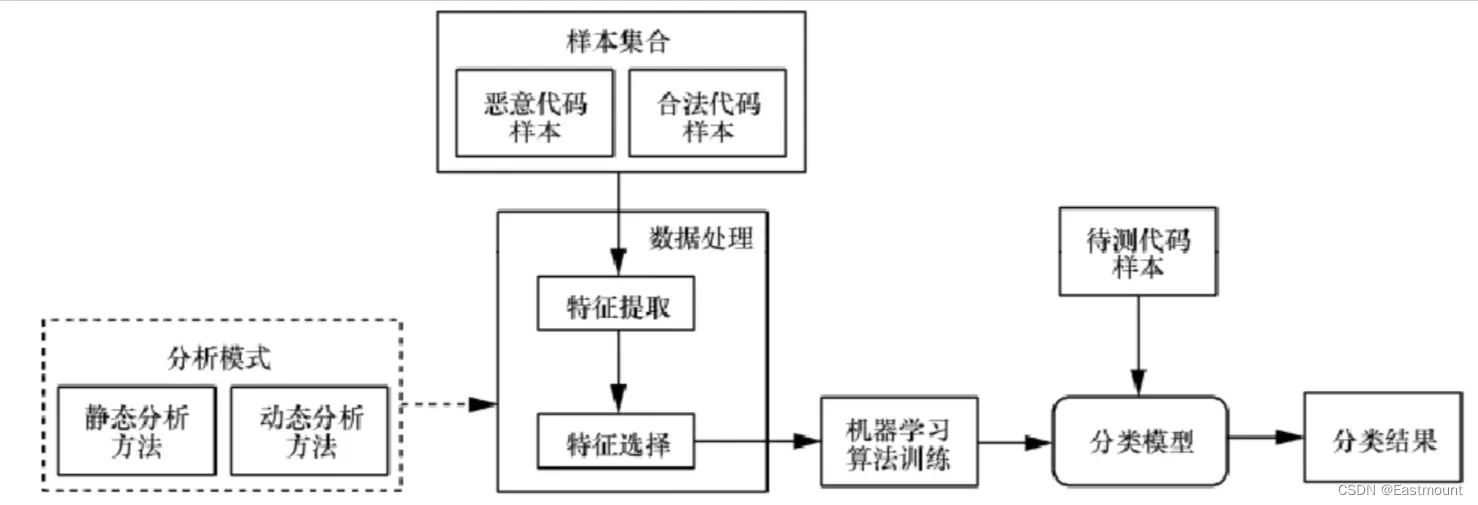
1.数据集
整个数据集包括5类恶意家族的样本,每个样本经过先前的CAPE工具成功提取的动态API序列。数据集分布情况如下所示:(建议读者提取自己数据集的样本,包括BIG2015、BODMAS等)
| 恶意家族 | 类别 | 数量 | 训练集 | 测试集 |
|---|---|---|---|---|
| AAAA | class1 | 352 | 242 | 110 |
| BBBB | class2 | 335 | 235 | 100 |
| CCCC | class3 | 363 | 243 | 120 |
| DDDD | class4 | 293 | 163 | 130 |
| EEEE | class5 | 548 | 358 | 190 |
数据集分为训练集和测试集,如下图所示:
数据集中主要包括四个字段,即序号、恶意家族类别、Md5值、API序列或特征。

需要注意,在特征提取过程中涉及大量数据预处理和清洗的工作,读者需要结合实际需求完成。比如提取特征为空值的过滤代码。
#coding:utf-8
#By:Eastmount CSDN 2023-05-31
import csv
import re
import os
csv.field_size_limit(500 * 1024 * 1024)
filename = "AAAA_result.csv"
writename = "AAAA_result_final.csv"
fw = open(writename, mode="w", newline="")
writer = csv.writer(fw)
writer.writerow(['no', 'type', 'md5', 'api'])
with open(filename,encoding='utf-8') as fr:
reader = csv.reader(fr)
no = 1
for row in reader: #['no','type','md5','api']
tt = row[1]
md5 = row[2]
api = row[3]
#print(no,tt,md5,api)
#api空值的过滤
if api=="" or api=="api":
continue
else:
writer.writerow([str(no),tt,md5,api])
no += 1
fr.close()
2.模型构建
由于机器学习算法比较简单,这里仅给出关键代码。此外,常用特征表征包括TF-IDF和Word2Vec,这里采用TF-IDF计算特征向量,读者可以尝试Word2Vec,最终实现家族分类并取得0.6215的Acc值。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2023-06-01
import os
import csv
import time
import numpy as np
import seaborn as sns
from sklearn import metrics
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
start = time.clock()
csv.field_size_limit(500 * 1024 * 1024)
#---------------------------第一步 加载数据集------------------------
#训练集
file = "train_dataset.csv"
label_train = []
content_train = []
with open(file, "r") as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader)
for row in csv_reader:
label_train.append(row[1])
value = str(row[3])
content_train.append(value)
print(label_train[:2])
print(content_train[:2])
#测试集
file = "test_dataset.csv"
label_test = []
content_test = []
with open(file, "r") as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader)
for row in csv_reader:
label_test.append(row[1])
value = str(row[3])
content_test.append(value)
print(len(label_train),len(label_test))
print(len(content_train),len(content_test)) #1241 650
#---------------------------第二步 向量转换------------------------
contents = content_train + content_test
labels = label_train + label_test
#计算词频 min_df max_df
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(contents)
words = vectorizer.get_feature_names()
print(words[:10])
print("特征词数量:",len(words))
#计算TF-IDF
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
weights = tfidf.toarray()
#---------------------------第三步 编码转换------------------------
le = LabelEncoder()
y = le.fit_transform(labels)
X_train, X_test = weights[:1241], weights[1241:]
y_train, y_test = y[:1241], y[1241:]
#---------------------------第四步 分类检测------------------------
clf = LogisticRegression(solver='liblinear')
clf.fit(X_train, y_train)
pre = clf.predict(X_test)
print(clf)
print(classification_report(y_test, pre, digits=4))
print("accuracy:")
print(metrics.accuracy_score(y_test, pre))
#计算时间
elapsed = (time.clock() - start)
print("Time used:", elapsed)
输出结果如下图所示:
1241 650
1241 650
['__anomaly__', 'accept', 'bind', 'changewindowmessagefilter', 'closesocket', 'clsidfromprogid', 'cocreateinstance', 'cocreateinstanceex', 'cogetclassobject', 'colescript_parsescripttext']
特征词数量: 269
LogisticRegression(solver='liblinear')
precision recall f1-score support
0 0.5398 0.5545 0.5471 110
1 0.6526 0.6200 0.6359 100
2 0.6596 0.5167 0.5794 120
3 0.8235 0.5385 0.6512 130
4 0.5665 0.7842 0.6578 190
accuracy 0.6215 650
macro avg 0.6484 0.6028 0.6143 650
weighted avg 0.6438 0.6215 0.6199 650
accuracy:
0.6215384615384615
Time used: 2.2597622
三.基于SVM的恶意家族检测
1.SVM模型
SVM分类算法的核心思想是通过建立某种核函数,将数据在高维寻找一个满足分类要求的超平面,使训练集中的点距离分类面尽可能的远,即寻找一个分类面使得其两侧的空白区域最大。如图19.16所示,两类样本中离分类面最近的点且平行于最优分类面的超平面上的训练样本就叫做支持向量。
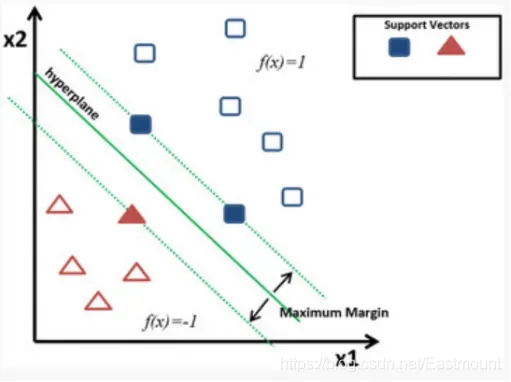
SVM分类算法在Sklearn机器学习包中,实现的类是 svm.SVC,即C-Support Vector Classification,它是基于libsvm实现的。构造方法如下:
SVC(C=1.0,
cache_size=200,
class_weight=None,
coef0=0.0,
decision_function_shape=None,
degree=3,
gamma='auto',
kernel='rbf',
max_iter=-1,
probability=False,
random_state=None,
shrinking=True,
tol=0.001,
verbose=False)
SVC算法主要包括两个步骤:
- 训练:
nbrs.fit(data, target) - 预测:
pre = clf.predict(data)
2.代码实现
下面仅给出SVM实现恶意家族分类的关键代码,该算法也是各类安全任务中的常用模型。需要注意,这里将预测结果保存至文件中,在真实实验中,建议大家多将实验过程数据保存,从而能更好地比较各种性能,体现论文的贡献。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2023-06-01
import os
import csv
import time
import numpy as np
import seaborn as sns
from sklearn import svm
from sklearn import metrics
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import classification_report
start = time.clock()
csv.field_size_limit(500 * 1024 * 1024)
#---------------------------第一步 加载数据集------------------------
#训练集
file = "train_dataset.csv"
label_train = []
content_train = []
with open(file, "r") as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader)
for row in csv_reader:
label_train.append(row[1])
value = str(row[3])
content_train.append(value)
print(label_train[:2])
print(content_train[:2])
#测试集
file = "test_dataset.csv"
label_test = []
content_test = []
with open(file, "r") as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader)
for row in csv_reader:
label_test.append(row[1])
value = str(row[3])
content_test.append(value)
print(len(label_train),len(label_test))
print(len(content_train),len(content_test)) #1241 650
#---------------------------第二步 向量转换------------------------
contents = content_train + content_test
labels = label_train + label_test
#计算词频 min_df max_df
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(contents)
words = vectorizer.get_feature_names()
print(words[:10])
print("特征词数量:",len(words))
#计算TF-IDF
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
weights = tfidf.toarray()
#---------------------------第三步 编码转换------------------------
le = LabelEncoder()
y = le.fit_transform(labels)
X_train, X_test = weights[:1241], weights[1241:]
y_train, y_test = y[:1241], y[1241:]
#---------------------------第四步 分类检测------------------------
clf = svm.LinearSVC()
clf.fit(X_train, y_train)
pre = clf.predict(X_test)
print(clf)
print(classification_report(y_test, pre, digits=4))
print("accuracy:")
print(metrics.accuracy_score(y_test, pre))
#结果存储
f1 = open("svm_test_pre.txt", "w")
for n in pre:
f1.write(str(n) + "\n")
f1.close()
f2 = open("svm_test_y.txt", "w")
for n in y_test:
f2.write(str(n) + "\n")
f2.close()
#计算时间
elapsed = (time.clock() - start)
print("Time used:", elapsed)
实验结果如下图所示:

1241 650
1241 650
['__anomaly__', 'accept', 'bind', 'changewindowmessagefilter', 'closesocket', 'clsidfromprogid', 'cocreateinstance', 'cocreateinstanceex', 'cogetclassobject', 'colescript_parsescripttext']
特征词数量: 269
LinearSVC()
precision recall f1-score support
0 0.6439 0.7727 0.7025 110
1 0.8780 0.7200 0.7912 100
2 0.7315 0.6583 0.6930 120
3 0.9091 0.6154 0.7339 130
4 0.6583 0.8316 0.7349 190
accuracy 0.7292 650
macro avg 0.7642 0.7196 0.7311 650
weighted avg 0.7534 0.7292 0.7301 650
accuracy:
0.7292307692307692
Time used: 2.2672032
四.基于随机森林的恶意家族检测
该部分关键代码如下,并且补充可视化分析代码。
# -*- coding: utf-8 -*-
# By:Eastmount CSDN 2023-06-01
import os
import csv
import time
import numpy as np
import seaborn as sns
from sklearn import svm
from sklearn import metrics
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
from sklearn.model_selection import train_test_split
from sklearn.decomposition import PCA
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_report
import matplotlib.pyplot as plt
from matplotlib.colors import ListedColormap
start = time.clock()
csv.field_size_limit(500 * 1024 * 1024)
#---------------------------第一步 加载数据集------------------------
#训练集
file = "train_dataset.csv"
label_train = []
content_train = []
with open(file, "r") as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader)
for row in csv_reader:
label_train.append(row[1])
value = str(row[3])
content_train.append(value)
print(label_train[:2])
print(content_train[:2])
#测试集
file = "test_dataset.csv"
label_test = []
content_test = []
with open(file, "r") as csv_file:
csv_reader = csv.reader(csv_file)
header = next(csv_reader)
for row in csv_reader:
label_test.append(row[1])
value = str(row[3])
content_test.append(value)
print(len(label_train),len(label_test))
print(len(content_train),len(content_test)) #1241 650
#---------------------------第二步 向量转换------------------------
contents = content_train + content_test
labels = label_train + label_test
#计算词频 min_df max_df
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(contents)
words = vectorizer.get_feature_names()
print(words[:10])
print("特征词数量:",len(words))
#计算TF-IDF
transformer = TfidfTransformer()
tfidf = transformer.fit_transform(X)
weights = tfidf.toarray()
#---------------------------第三步 编码转换------------------------
le = LabelEncoder()
y = le.fit_transform(labels)
X_train, X_test = weights[:1241], weights[1241:]
y_train, y_test = y[:1241], y[1241:]
#---------------------------第四步 分类检测------------------------
clf = RandomForestClassifier(n_estimators=5)
clf.fit(X_train, y_train)
pre = clf.predict(X_test)
print(clf)
print(classification_report(y_test, pre, digits=4))
print("accuracy:")
print(metrics.accuracy_score(y_test, pre))
#结果存储
f1 = open("rf_test_pre.txt", "w")
for n in pre:
f1.write(str(n) + "\n")
f1.close()
f2 = open("rf_test_y.txt", "w")
for n in y_test:
f2.write(str(n) + "\n")
f2.close()
#计算时间
elapsed = (time.clock() - start)
print("Time used:", elapsed)
#---------------------------第五步 可视化分析------------------------
#降维
pca = PCA(n_components=2)
pca = pca.fit(X_test)
xx = pca.transform(X_test)
#画图
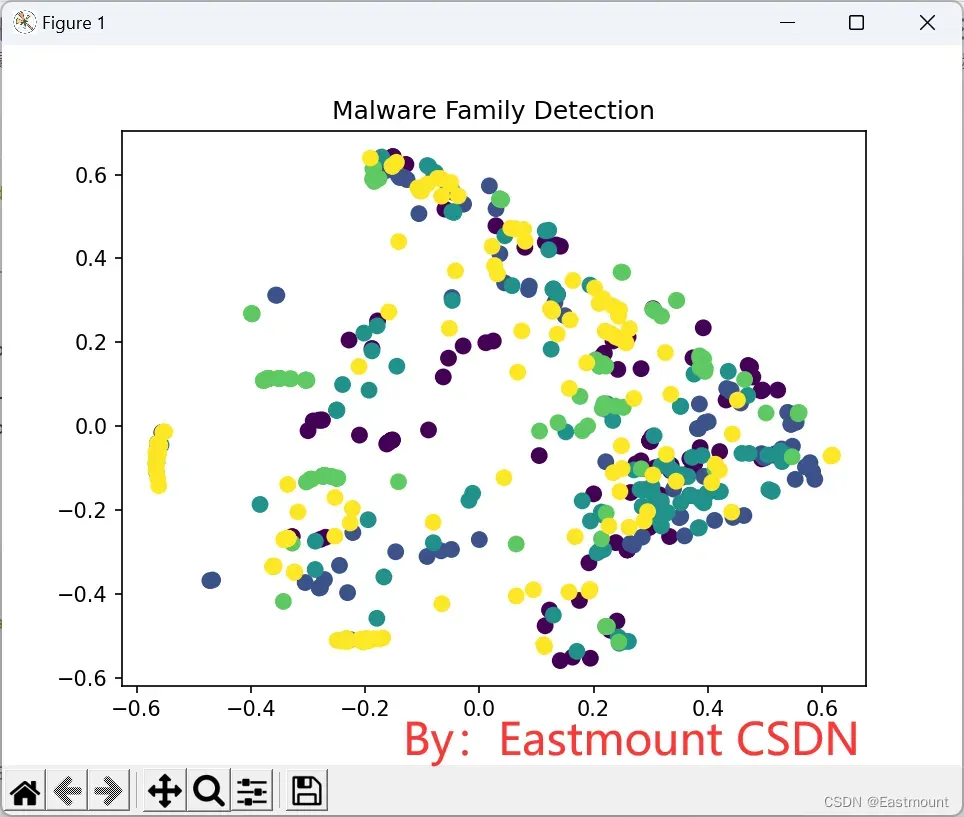
plt.figure()
plt.scatter(xx[:,0],xx[:,1],c=y_test, s=50)
plt.title("Malware Family Detection")
plt.show()
输出结果如下所示,效果达到了0.8092,感觉还不错。
1241 650
1241 650
['__anomaly__', 'accept', 'bind', 'changewindowmessagefilter', 'closesocket', 'clsidfromprogid', 'cocreateinstance', 'cocreateinstanceex', 'cogetclassobject', 'colescript_parsescripttext']
特征词数量: 269
RandomForestClassifier(n_estimators=5)
precision recall f1-score support
0 0.7185 0.8818 0.7918 110
1 0.9000 0.8100 0.8526 100
2 0.7963 0.7167 0.7544 120
3 0.9444 0.7846 0.8571 130
4 0.7656 0.8421 0.8020 190
accuracy 0.8092 650
macro avg 0.8250 0.8070 0.8116 650
weighted avg 0.8197 0.8092 0.8103 650
accuracy:
0.8092307692307692
Time used: 2.1914324
同时,五类恶意家族进行可视化分析。然而,整个效果一般,需要进一步优化代码和维度来区分数据集,或者三维散点图,请读者自行思考。
五.总结
写到这里这篇文章就结束,希望对您有所帮助。忙碌的五月,真的很忙,项目本子论文毕业,等忙完后好好写几篇安全博客,感谢支持和陪伴,尤其是家人的鼓励和支持, 继续加油!
- 一.恶意软件分析
1.静态特征
2.动态特征 - 二.基于逻辑回归的恶意家族检测
1.数据集
2.模型构建 - 三.基于SVM的恶意家族检测
1.SVM模型
2.代码实现 - 四.基于随机森林的恶意家族检测
- 五.总结
作者提问如下,欢迎大家补充:
- 恶意软件或二进制常见的特征包括哪些?各自有哪些优缺点。
- 恶意软件转灰度图是常见的家族分类方法,它与本文提出的方法的优缺点是什么?
- 如何提取恶意软件CFG和ICFG呢?提取后又如何被机器学习模型学习?
- 常见的向量表征方法有哪些,各自有哪些特点?您能否实现Word2Vec的代码呢?
- 机器学习和深度学习的联系及区别是什么?如果构建深度学习模型学习API序列,其恶意家族检测效果如何?
- 恶意软件家族分类或恶意代码检测发展到如今现状如何?工业界和学术界各种有哪些特点及局限,如何更好地关联来促进领域发展?
- 二进制方向是否还有更好的创新或突破性方法?其鲁棒性、语义增强、可解释性如何提升。
- 如何实现未知家族的恶意软件检测,又如何实现高威胁恶意软件的溯源呢?
- 恶意软件检测如何更好地和底层硬件及编译器融合?以及如何对抗变种、混淆及对抗。
- 恶意软件检测能通过chatGPT技术快速生成变种吗?又如何对抗该技术的发展。
人生路是一个个十字路口,一次次博弈,一次次纠结和得失组成。得失得失,有得有失,不同的选择,不一样的精彩。虽然累和忙,但看到小珞珞还是挺满足的,感谢家人的陪伴。
小珞:爸爸,你下班回来了啊
我:你今天和婆婆去超市哭了吗?
小珞:是的,我想自己拿小发糕
我:听说被老爷爷老奶奶笑了啊,以后…
小珞:他们笑有什么用嘛!
是啊,哈哈,有什么用嘛小珞珞长大了,小可爱长成了小调皮。最近舍不得打车,改公交和共享摩托,但又寄托于买彩票,我们的500万话说,17年我咋不跟着女神在我们小区买套房呢?到今年感觉能赚近100万,够我在贵州教十年书。都是博弈,都是选择,都是酸甜,望小珞能开心健康成长,爱你们喔,继续干活,加油

(By:Eastmount 2023-09-06 夜于贵阳 http://blog.csdn.net/eastmount/ )
文章出处登录后可见!