目录
- 前言
- 一、名词解释
- 1-1、Stable Diffusion介绍
- 1-2、ControlNet介绍
- 1-2-1、ControlNet介绍&工作原理
- 1-2-2、ControlNet控制方法介绍
- 1-3、案例分析
- 1-3-1、室内装修设计
- 1-3-2、品牌创意海报
- 1-4、stable-diffusion-webui 的参数解释
- 二、生成方法
- 2-1、图像到图像
- 2-1-1、二维码生成
- 2-1-2、选择云端平台来启动Stable Diffusion的Web UI
- 2-1-3、使用Stable Diffusion来修饰二维码
- 2-2、使用控制网络将文本转图像
- 2-2-1、二维码生成
- 2-2-2、安装插件——After Detailer
- 2-2-3、安装QR Code Monster 模型
- 2-2-4、模型参数设置
- 2-2-5、出图
- 三、附录
- 3-1、ControlNet模型
- 3-1-1、Controlnet QR Pattern (QR Codes)
- 3-1-2、monster-labs/control_v1p_sd15_qrcode_monster
- 3-1-2、ioclab/ioc-controlnet
- 总结
前言
详细介绍ControlNet的各个部分,相关案例,以及使用二维码作为ControlNet模型的输入的Stable Diffusion生成的图像,使二维码转变为艺术图像
一、名词解释
1-1、Stable Diffusion介绍
Stable Diffusion:是StabilityAI于2022年8月22日发布的文本到图像模型。它类似于OpenAI的DALL·E 2和Midjourney等其他图像生成模型,但有一个很大的不同:它是开源的,在发布后的短短几周内,围绕Stable Diffusion模型和相关工具的创新出现了爆炸式增长。Stable Diffusion在速度上的突破也意味着,模型第一次可以在消费类gpu上运行,而不是在超级计算机上。这对于Stable Diffusion影响力的快速增长带来了巨大意义! Stable Diffusion的技术细节如下:
Stable Diffusion是一种扩散模型(diffusion model)的变体,叫做“潜在扩散模型”(latent diffusion model; LDM)。扩散模型是在2015年推出的,其目的是消除对训练图像的连续应用高斯噪声,可以将其视为一系列去噪自编码器。Stable Diffusion由3个部分组成:变分自编码器(VAE)、U-Net和一个文本编码器。与其学习去噪图像数据(在“像素空间”中),而是训练VAE将图像转换为低维潜在空间(英语)。添加和去除高斯噪声的过程被应用于这个潜在表示,然后将最终的去噪输出解码到像素空间中。在前向扩散过程中,高斯噪声被迭代地应用于压缩的潜在表征。每个去噪步骤都由一个包含残差神经网络(粤语)(ResNet)中间的U-Net架构完成,通过从前向扩散往反方向去噪而获得潜在表征。最后,VAE解码器通过将表征转换回像素空间来生成输出图像。研究人员指出,降低训练和生成的计算要求是LDM的一个优势。去噪步骤可以以文本串、图像或一些其他数据为条件。调节数据的编码通过交叉注意机制(cross-attention mechanism)暴露给去噪U-Net的架构。为了对文本进行调节,一个预训练的固定CLIP ViT-L/14文本编码器被用来将提示词转化为嵌入空间。
简单来说:Stable Diffusion是一种深度学习算法,它使用文本作为输入来生成渲染图像。它的工作原理是一个扩散过程,在这个过程中,图像通过一系列步骤逐渐从随机噪声变成连贯图像。该模型经过训练,可以根据提供的文本提示来指导此过程,
以下是stablediffusion官方仓库:https://github.com/Stability-AI/StableDiffusion
1-2、ControlNet介绍
1-2-1、ControlNet介绍&工作原理
ControlNet: ControlNet是一种通过添加附加条件来控制扩散模型(例如Stable Diffusion)的神经网络结构。一般的使用方法是结合Stable Diffusion来做到精准控图。
简单工作原理:在带有ControlNet的图像训练过程中,一共有2种条件会作用到生成图像上,其一是提示词(prompt),另一个就是由ControlNet引入的各种自定义条件(Condition)。
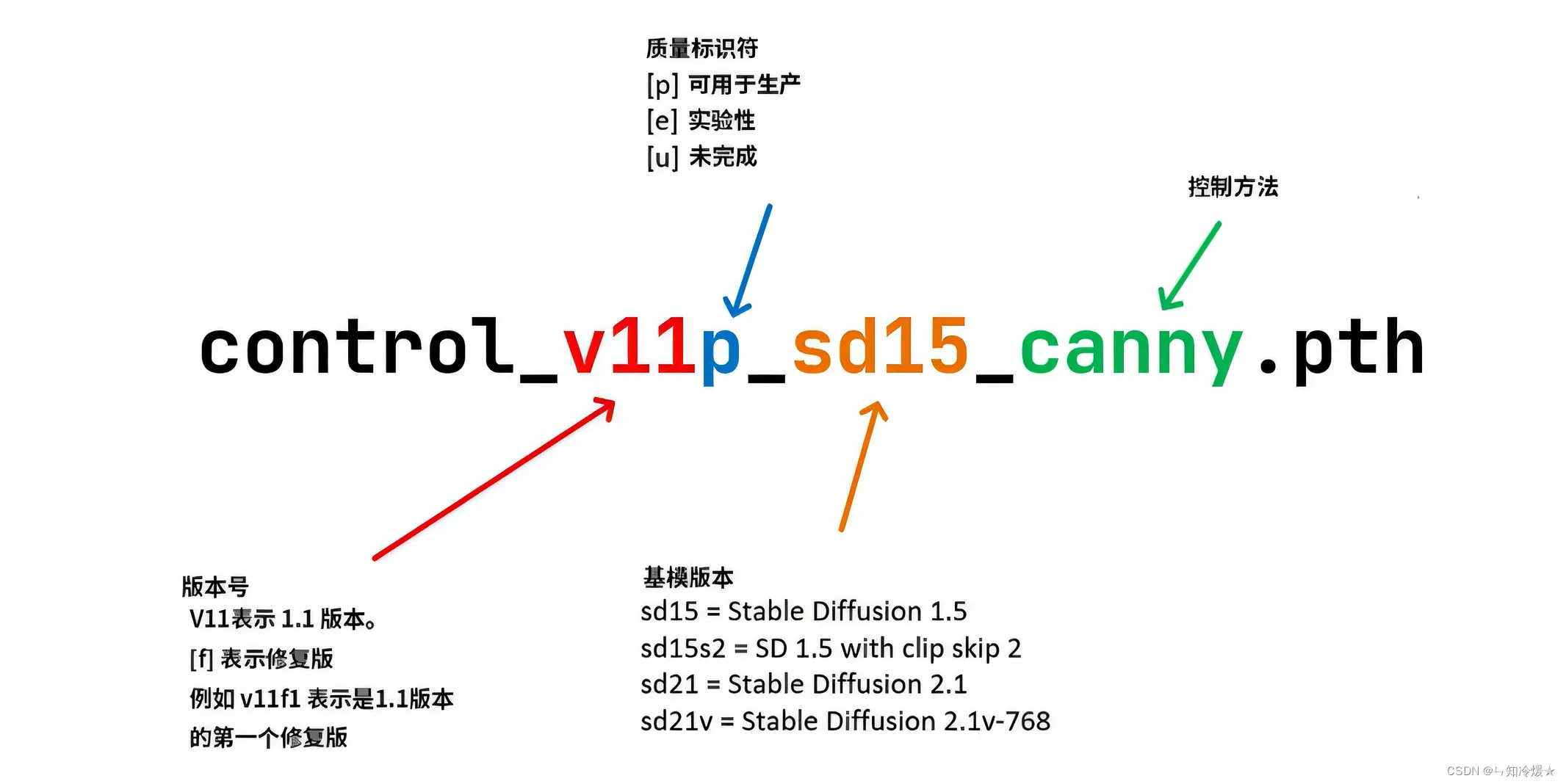
以下是ControlNet对应模型的一个命名规则:需要注意的是是否是p,即可用于生成以及控制方法。
1-2-2、ControlNet控制方法介绍
Invert
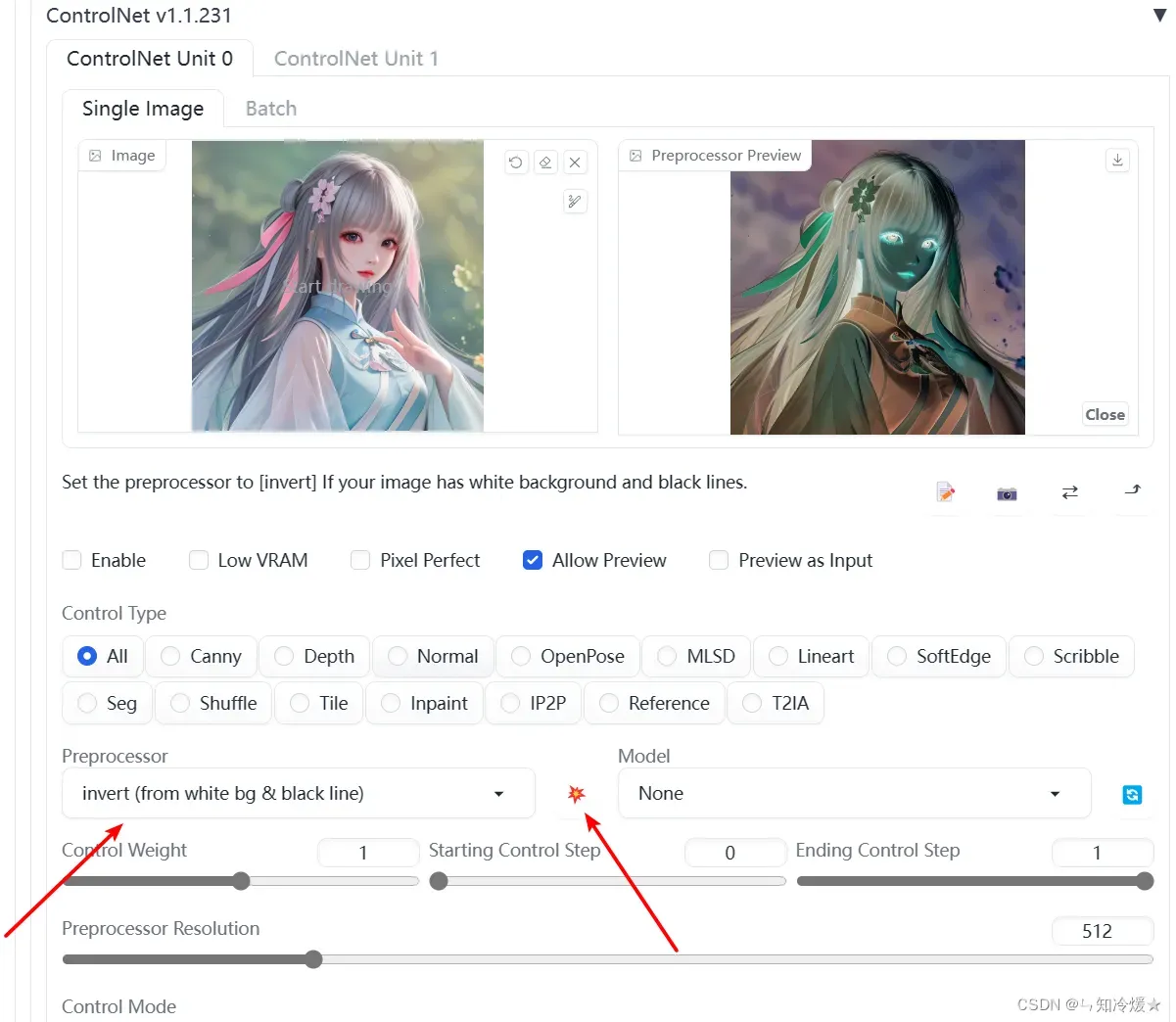
Invert 用于检测用户上传的图像。预处理器和模型通常需要在黑色图像上使用白线来检测(也就是灰度图)。但如果你的图是白色图像上的黑线,就必须使用这个工具来切换颜色了,不然controlNet模型会无法正确识别输入图中的信息。注意这种情况在涂鸦模式和线稿填色场景中非常常见。
对应模型:无
测试如下:点击中间的按钮可以预览预处理后的轮廓线,左侧是原图,右侧是预处理后的图。
Canny
Canny 通过使用边缘检测器提取图像中的所有重要轮廓线。通过调节阈值,可以使线条捕捉到非常详细的信息,但也会因此让图像背景中固有的干扰信息影响你的目标物体,所以在必要时可通过设置边缘检测阈值达到过滤出特定边缘信息的目的。注意,对于一些细节丰富的训练图可能并不适合使用Canny提取边缘。
对应模型:control_v11p_sd15_canny
测试如下:点击中间的按钮可以预览。
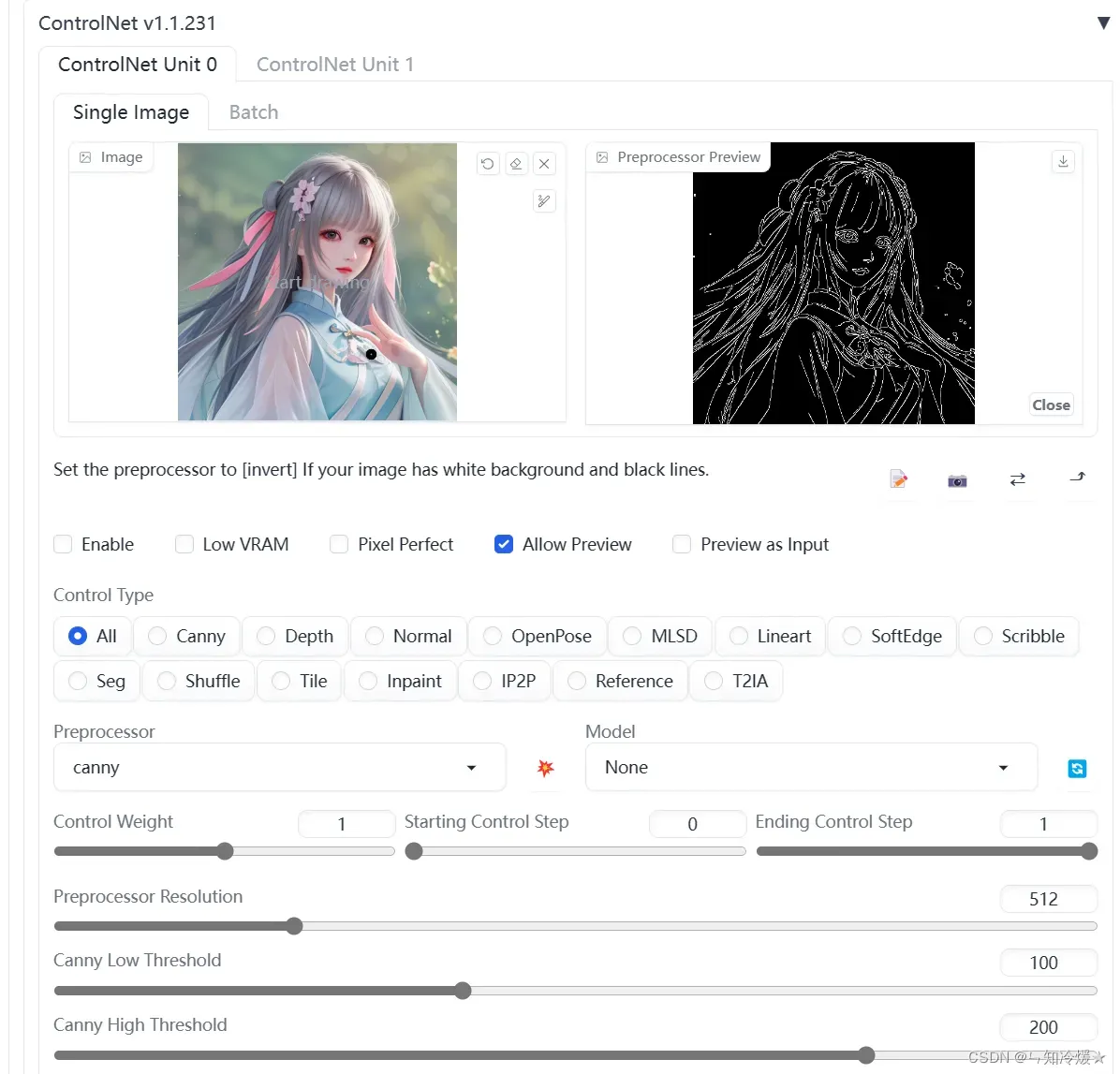
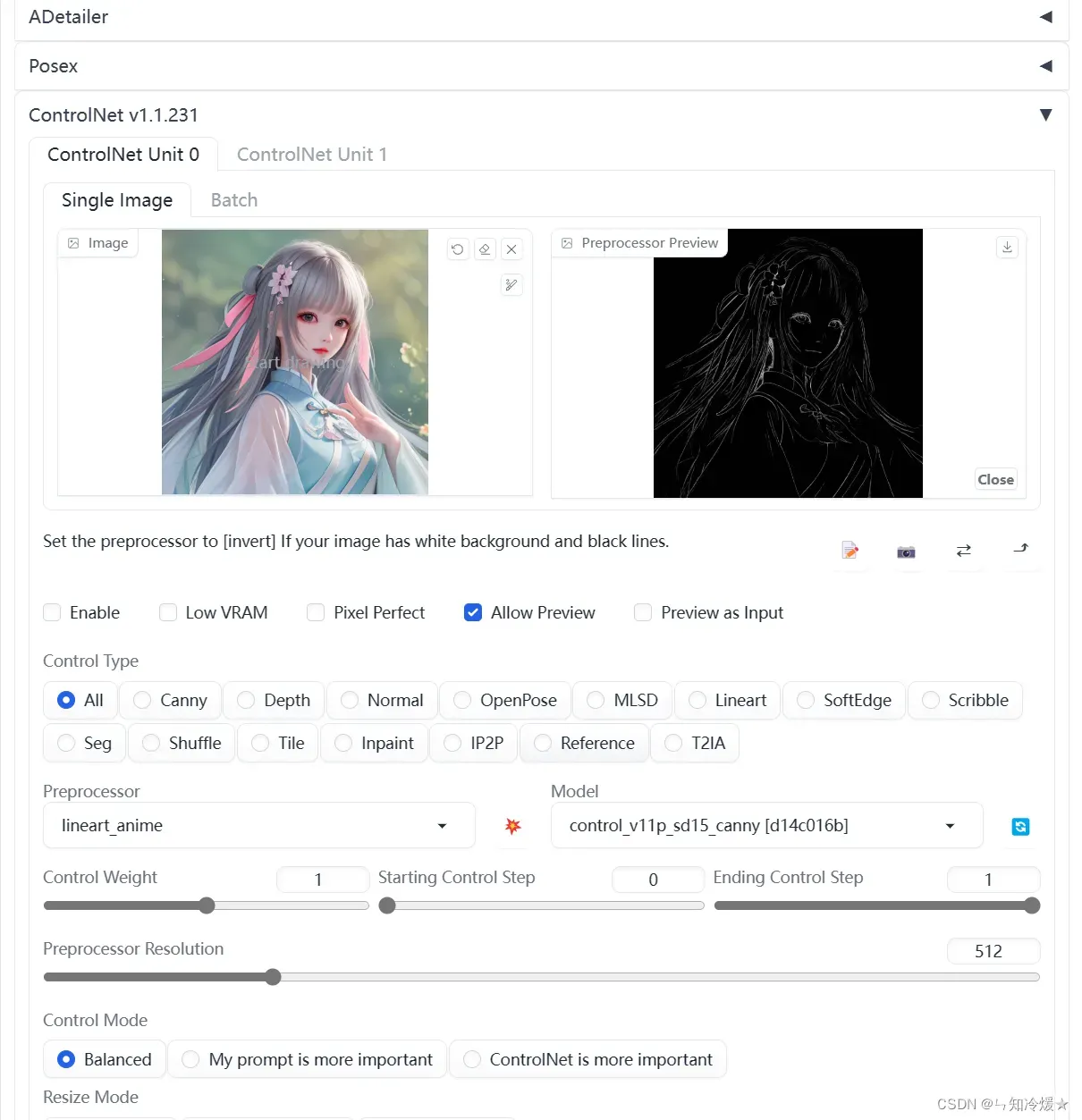
Lineart
是Canny的替代者,但是能够比canny更加精准的提取二次元(使用anime后缀),或真实照片(使用realistic后缀)图片的线稿。具体效果参考下方图示。
对应模型:control_v11p_sd15_lineart
测试如下:点击中间的按钮可以预览。
拓展:使用线条图生成不一样风格的二次元少女,小例子, 我这里没有加提示词,使用国风模型,随机生成。
Softedge
对应了以前的HED(Holistically-nested Edge Detection),既软边缘检测,它可以在物体周围创建清晰和精细的边界,输出类似于Canny,但减少了噪声和更柔软的边缘。它的有效性在于能够从复杂的细节中捕捉(过滤出)需要的轮廓信息,同时也保留了一定量的细节特征(面部表情、头发、手指等)。同Canny,我们一般用此预处理器保留原图线条轮廓,修改风格和颜色。
对应模型: control_v11p_sd15_softedge
测试如下:点击中间的按钮可以预览。
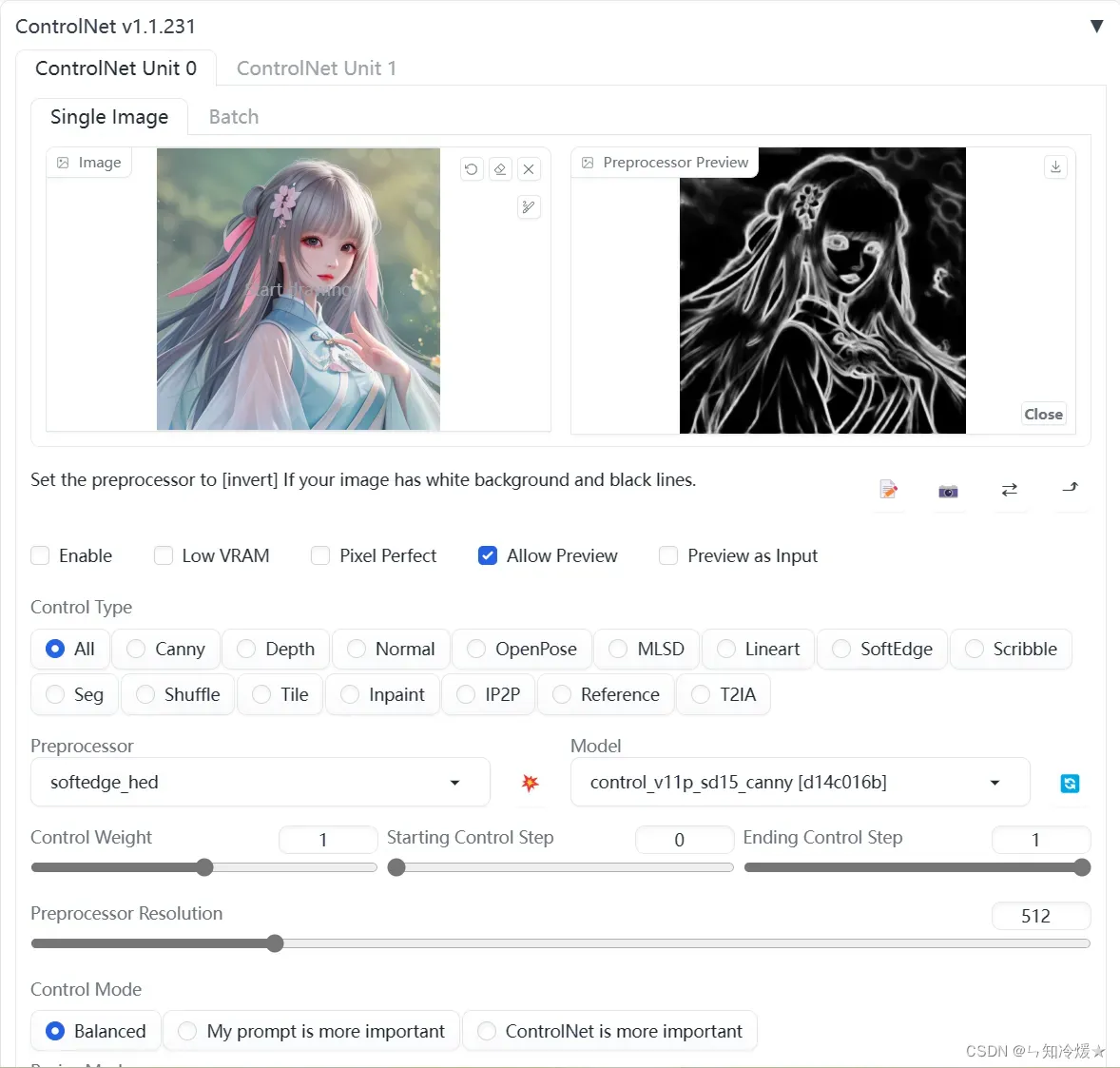
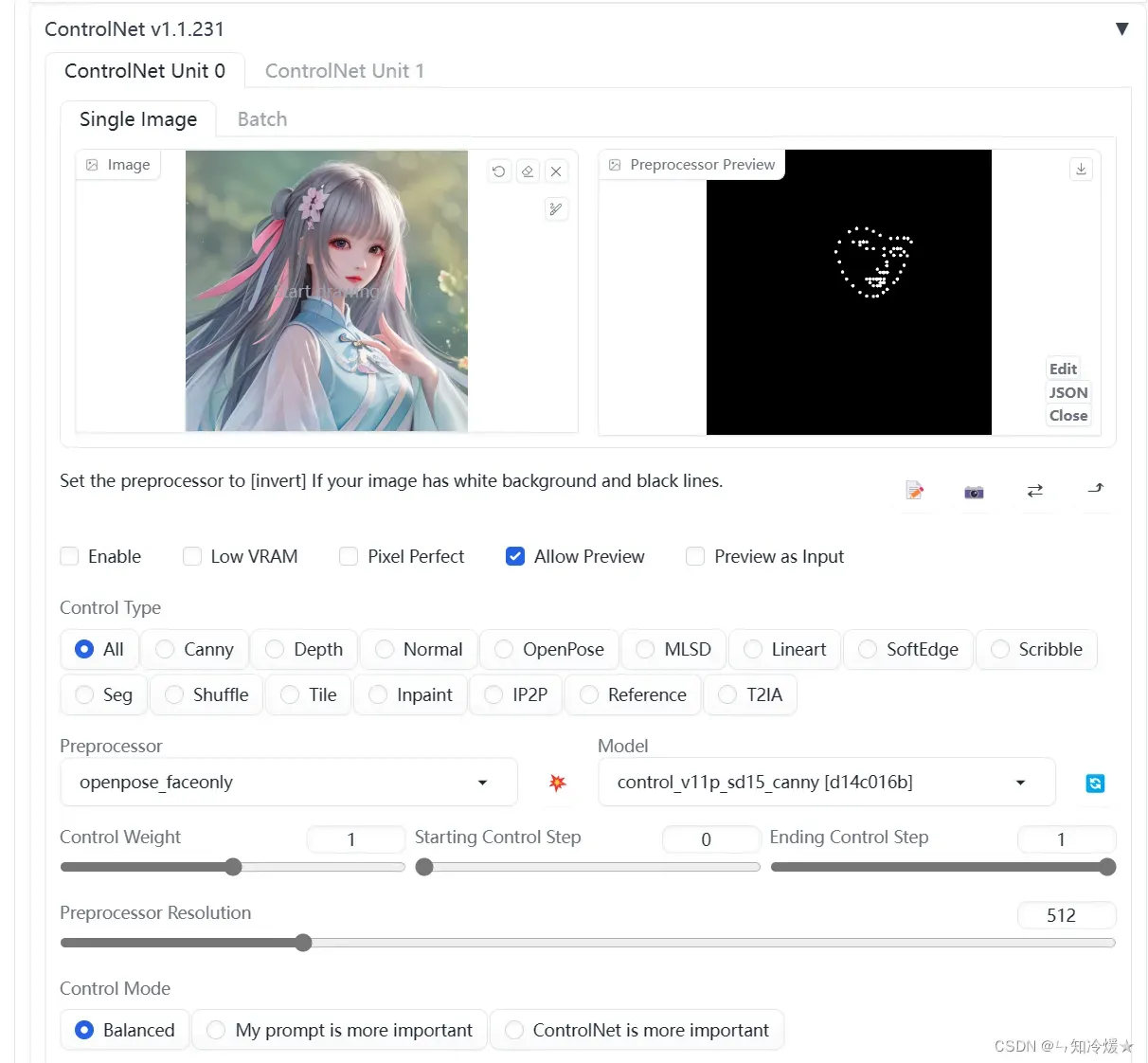
Openpose
这个预处理器的基础款用于生成了一个基于节点和连线的骨骼火柴人的形象。相较于其他固定角色姿势的controlnet方案来说,这种技术的优势是支持多个 OpenPose 骨架组合成一个图像,达到精确控制多角色同屏的效果。此外由于还支持通过插件手动调节骨骼节点,也就便利了喜欢自已定义动作的同学。所有这些辅助骨骼信息会形成ControlNet的输入条件(condition)从而影响和引导稳定扩散模型的生成过程,获得符合预设姿势的生成图。
对应模型:control_v11p_sd15_openpose
测试如下:点击中间的按钮可以预览,这里我们使用faceonly去预处理。
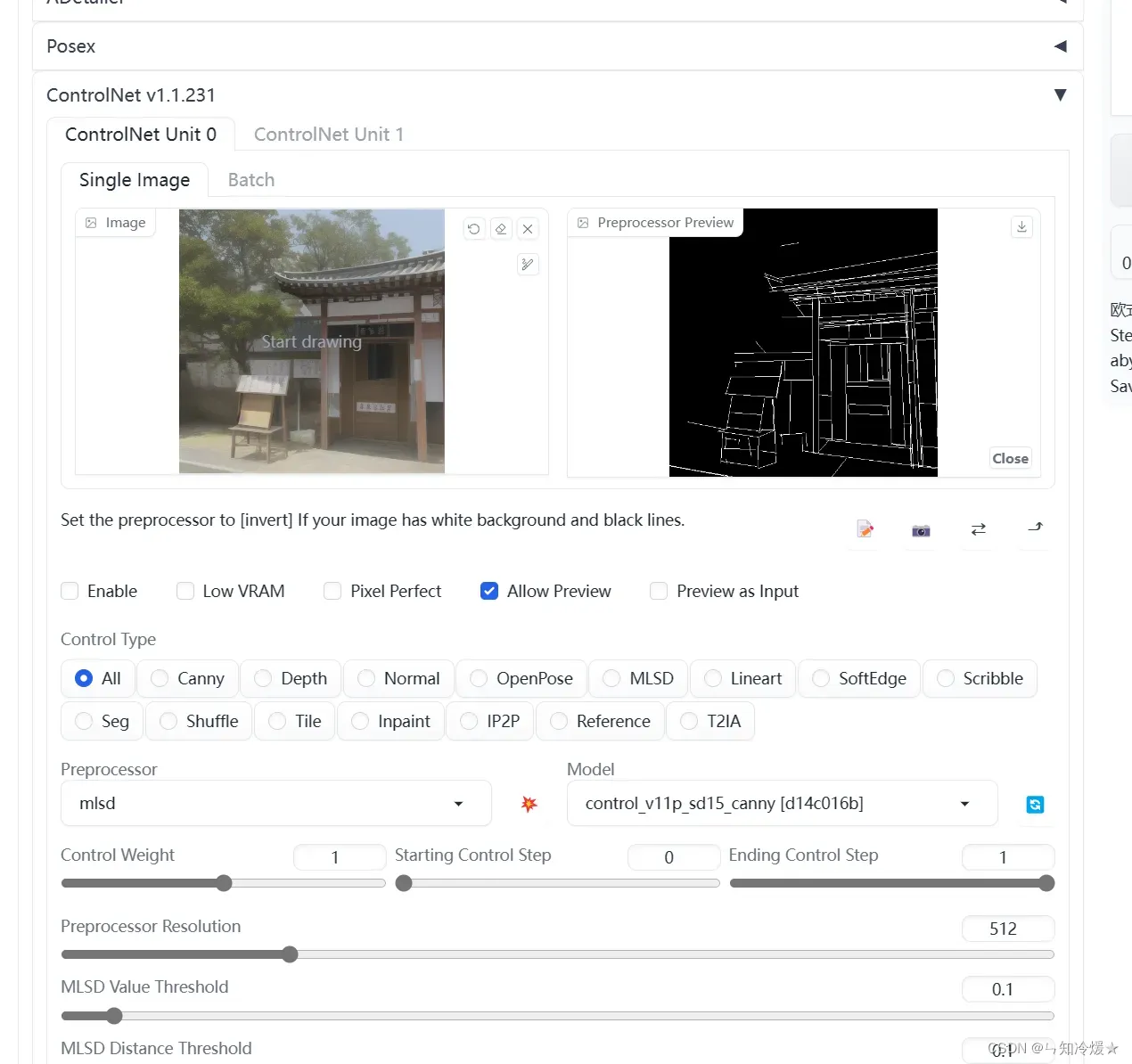
MLSD:
最适合生成各种朝向的直线条,经MLSD输出的线条能较好的贴合物体上的各种直线轮廓,尤其适合勾勒建筑物和其他规则的几何造型物品。但是另一方面,MLSD不适用于提取图像中的各种弯曲线条。基于上述特性,该模型常用于生成室内外渲染图,或者具有简约直线条风格的艺术/工艺作品。通过简单横竖线条固定下场景的基调,由稳定扩散模型填充/创作具体细节,以达到同设计替换风格的效果。
对应模型:control_v11f1p_sd15_mlsd
测试如下:点击中间的按钮可以预览。
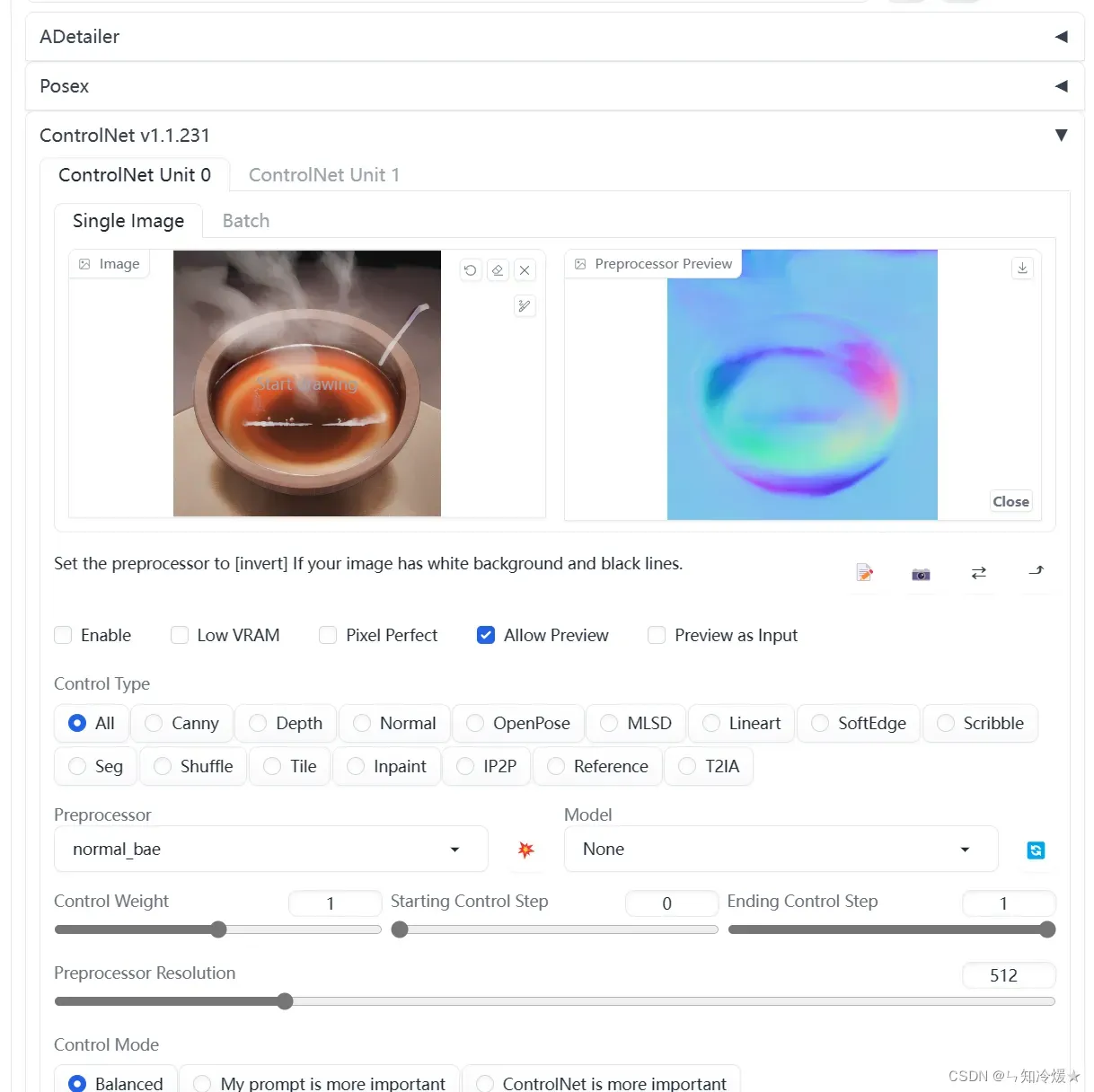
Normal:
Normal: 法线图使用三种颜色通道来表示一个垂直于像素点表面的朝向(法向)信息。法线图能很好的还原大块物体面的朝向,这有利于光照,形状和体积(透视/景深)的还原。同时得益于细节的保留,使用法线图也可以间接反应物体表面的粗糙度和光滑程度。
对应模型:control_v11f1p_sd15_normalbae
测试如下:点击中间的按钮可以预览。
Tile:
Normal: 法线图使用三种颜色通道来表示一个垂直于像素点表面的朝向(法向)信息。法线图能很好的还原大块物体面的朝向,这有利于光照,形状和体积(透视/景深)的还原。同时得益于细节的保留,使用法线图也可以间接反应物体表面的粗糙度和光滑程度。
对应模型:control_v11f1p_sd15_normalbae
1-3、案例分析
1-3-1、室内装修设计
概述:毛胚房装修。大模型直接用Deliberate,如下图所示:

- 使用MLSD功能勾勒出毛胚房的直线
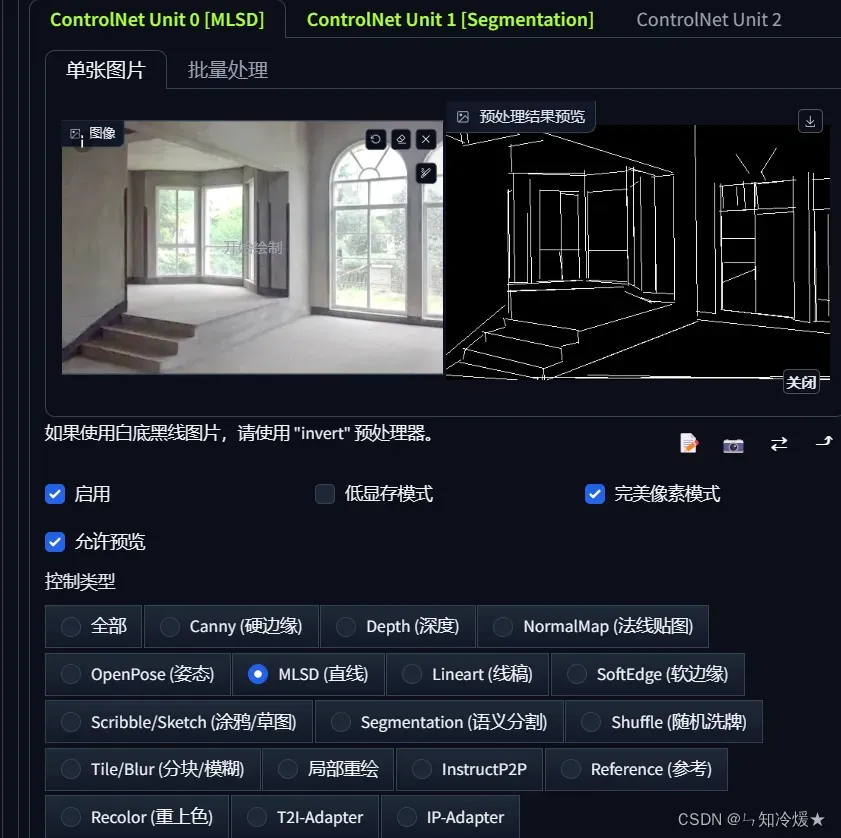
- 使用seg,语义分割来区分不同区域
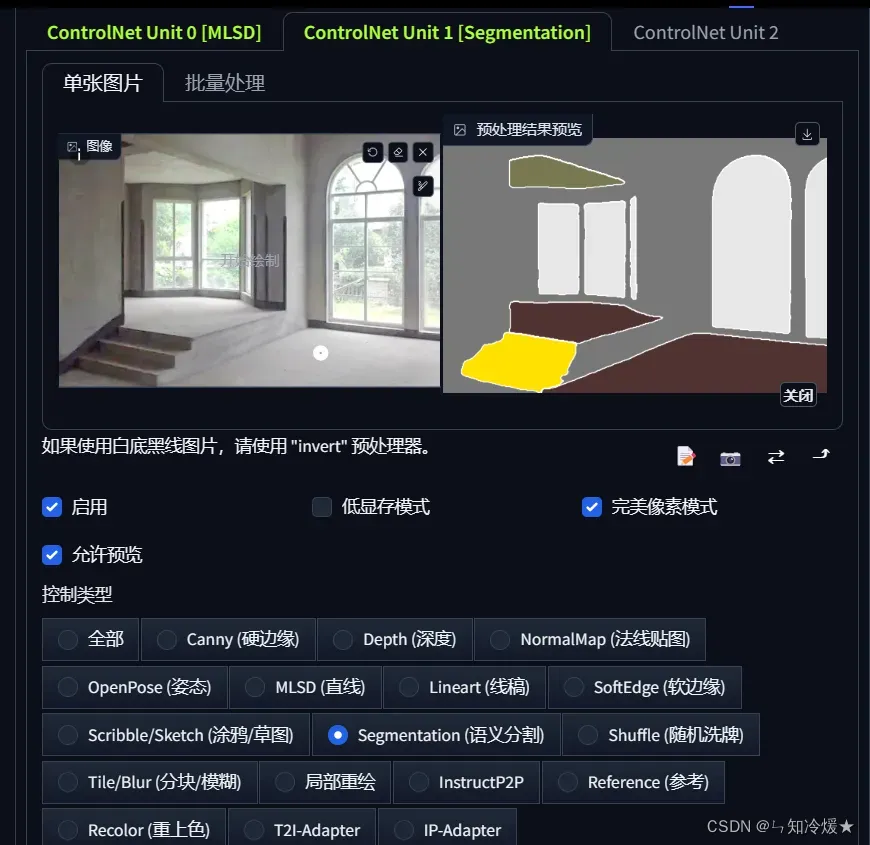
- 提示词如下所示:
Prompt:
Nayuta Nordic Modern Interior Design, ray tracing, best shadow, (realistic, photorealistic:1.5), professional lighting, photon mapping, radiosity, physically-based rendering, sunlight, large window, no humans, indoors, scenery, wooden floor, smooth wall, bedroom, bed, pillow, floor lamp, couch, table, chair, curtain, carpet, potted plant, flower, vase, clock, book, white ceiling, white wall, award-winning contemporary design <lora:Nordic Modern Interior Style:0.65>,, (best quality),((masterpiece)),(highres), original, extremely detailed 8K wallpaper,(an extremely delicate and beautiful),
Negative prompt
Negative prompt: bad_prompt_version2-neg, negative_hand-neg, ng_deepnegative_v1,
Steps: 30, Sampler: Euler a, CFG scale: 7, Seed: 3145605567, Size: 496x336, Model hash: 9aba26abdf, Model: deliberate_v2, Denoising strength: 0.35, ControlNet 0: "preprocessor: mlsd, model: control_v11p_sd15_mlsd [aca30ff0], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (512, 0.1, 0.1)", ControlNet 1: "preprocessor: seg_ofade20k, model: control_v11p_sd15_seg [e1f51eb9], weight: 1, starting/ending: (0, 1), resize mode: Crop and Resize, pixel perfect: True, control mode: Balanced, preprocessor params: (512, 64, 64)", Hires upscale: 2, Hires upscaler: BSRGAN
效果图:

1-3-2、品牌创意海报
概述:品牌Logo海报设计,模型使用ReV Animated,这里以抖音logo为例。
-
使用Lineart勾勒出线稿,ControlNet中的设置如下所示。
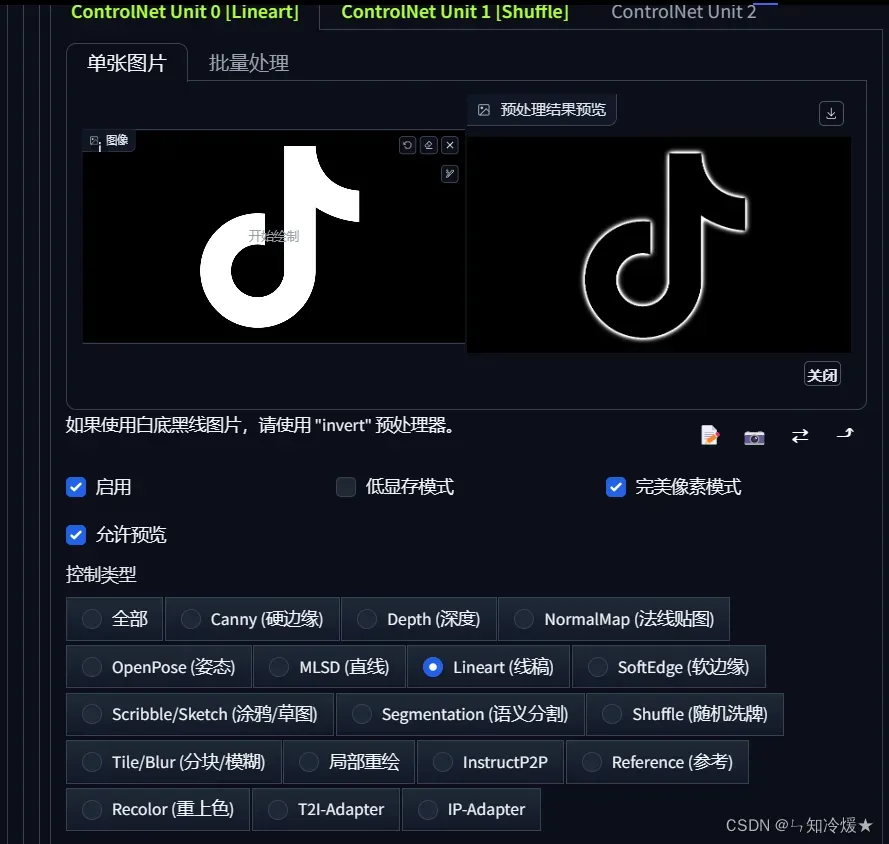
-
接下来需要找一个风格图片,与logo混合。

-
启用第二个ControlNet,调用Shuffle工具,将图片风格与Logo混合。
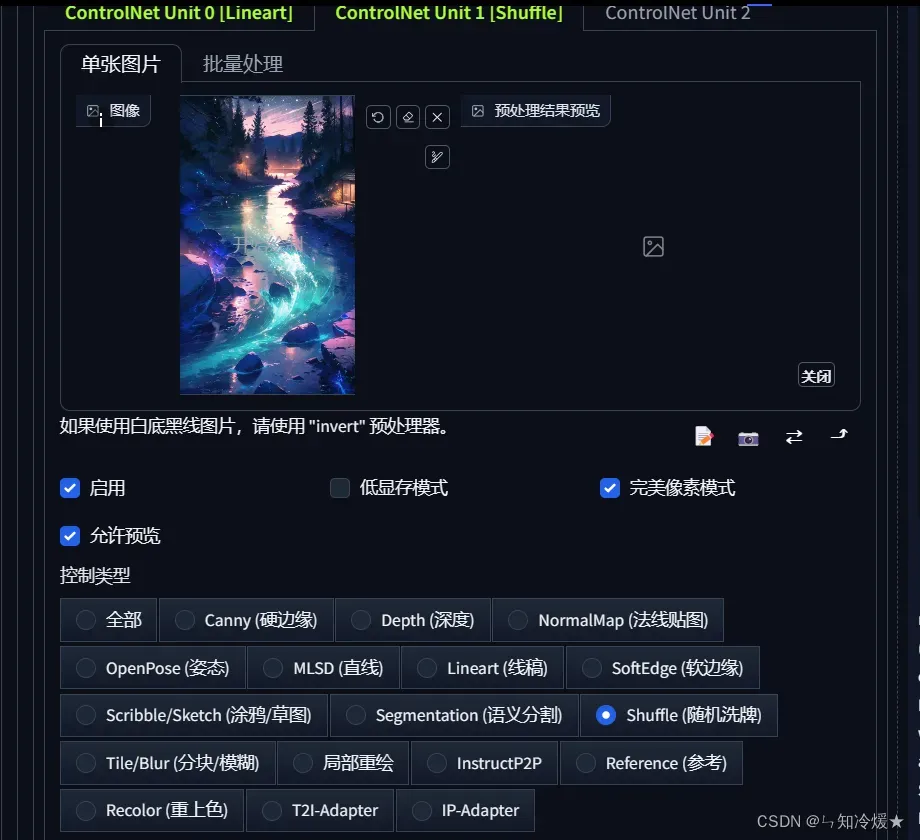
- 提示词如下所示:
Prompt:
neon lights, science fiction, cyberpunk, masterpiece, best quality, ray tracing, (best quality), ((masterpiece)), (highres), original, extremely detailed 8K wallpaper, (an extremely delicate and beautiful), incredibly_absurdres, colorful, intricate detail, artbook <lora:LowRA:0.6>, <lora:FilmVelvia3:0.4>,
Negative prompt
lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, EasyNegative, animal
出图效果:第三张、第四张图为第一个ControlNet单元的效果改为深度Depth后的出图效果。




1-4、stable-diffusion-webui 的参数解释
- Prompt: 提示词(正向)
- Negative prompt: 消极的提示词(反向)
- Width & Height: 要生成的图片尺寸。尺寸越大,越耗性能,耗时越久。(注意,最好保持默认)
- CFG scale: AI 对描述参数(Prompt)的倾向程度。值越小生成的图片越偏离你的描述,但越符合逻辑;值越大则生成的图片越符合你的描述,但可能不符合逻辑。
- Sampling method: 采样方法。有很多种,但只是采样算法上有差别,没有好坏之分,选用适合的即可。(多尝试)
- Sampling steps: 采样步长。太小的话采样的随机性会很高,太大的话采样的效率会很低,拒绝概率高(可以理解为没有采样到,采样的结果被舍弃了)。
- Seed: 随机数种子。生成每张图片时的随机种子,这个种子是用来作为确定扩散初始状态的基础。默认-1,即随机生成。(主要是设置固定的种子,以后可以复现相同的结果)
二、生成方法
2-1、图像到图像
图像到图像:想象一下,我们可以把一个带有QR码的图片放进计算机,然后让计算机以一种稳定而有序的方式重新绘制QR码里的每个小方块。这一过程不需要任何额外的特殊指令,就像是我们把一张图放在计算机上,它会自动帮我们重新把图上的QR码绘制出来,而且这个过程会很平稳,不会出现什么混乱,这个过程并不需要使用到ControlNet。
Stable Diffusion中的图生图介绍:
Stable Diffusion包括另一个取样脚本,称为”img2img”,它接受一个提示词、现有图像的文件路径和0.0到1.0之间的去噪强度,并在原始图像的基础上产生一个新的图像,该图像也具有提示词中提供的元素;去噪强度表示添加到输出图像的噪声量,值越大,图像变化越多,但在语义上可能与提供的提示不一致。图像升频是img2img的一个潜在用例,除此之外。
2-1-1、二维码生成
为了增加二维码的识别成功率,二维码的生成需要遵循以下准则:
- 在二维码的周围要留白
- 用黑白图案填充最基本的正方形
这里我们使用https://34qr.com/en/网站来生成二维码。
第一步:选择类型
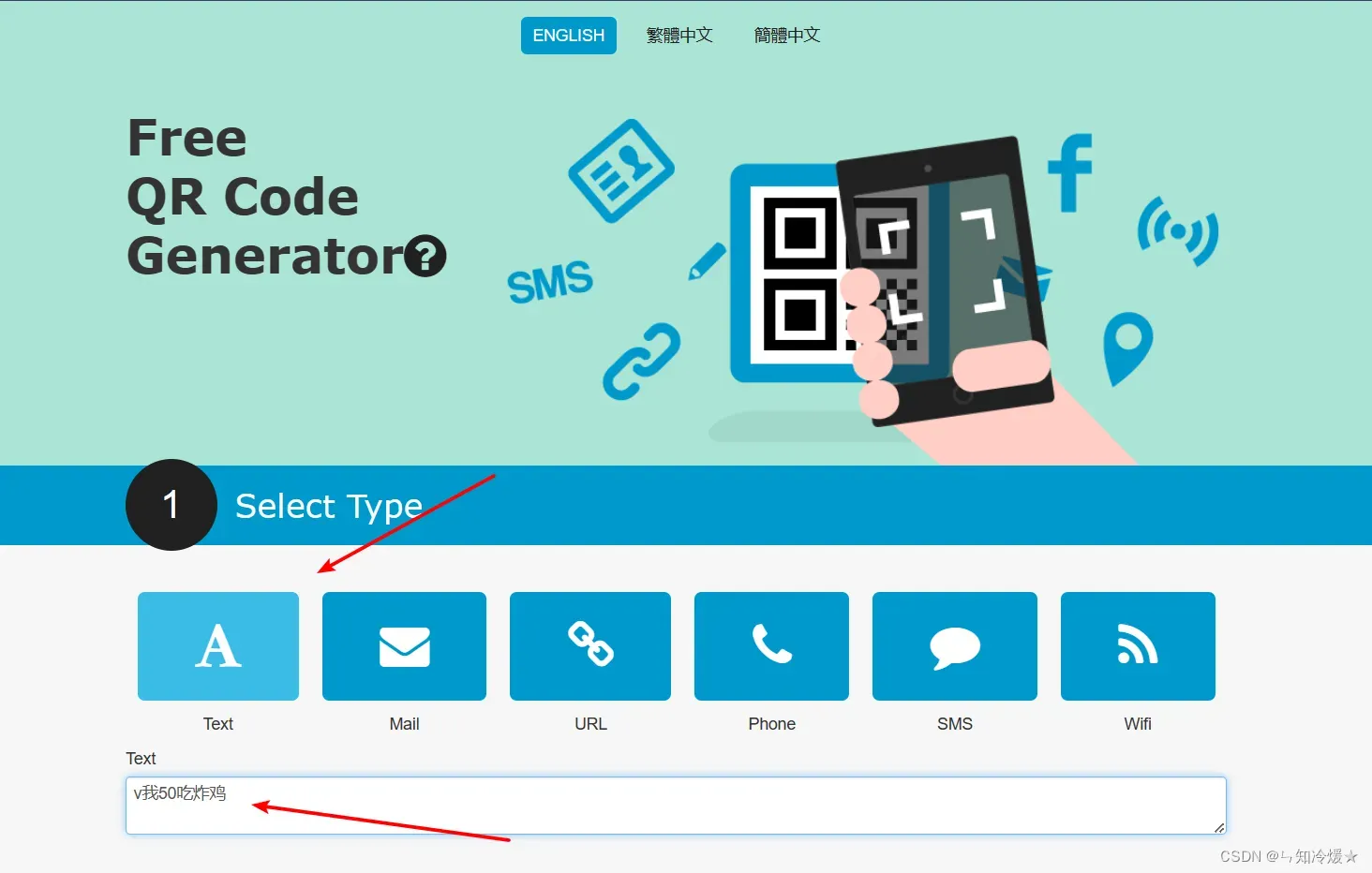
第二步:留出空白并点击生成
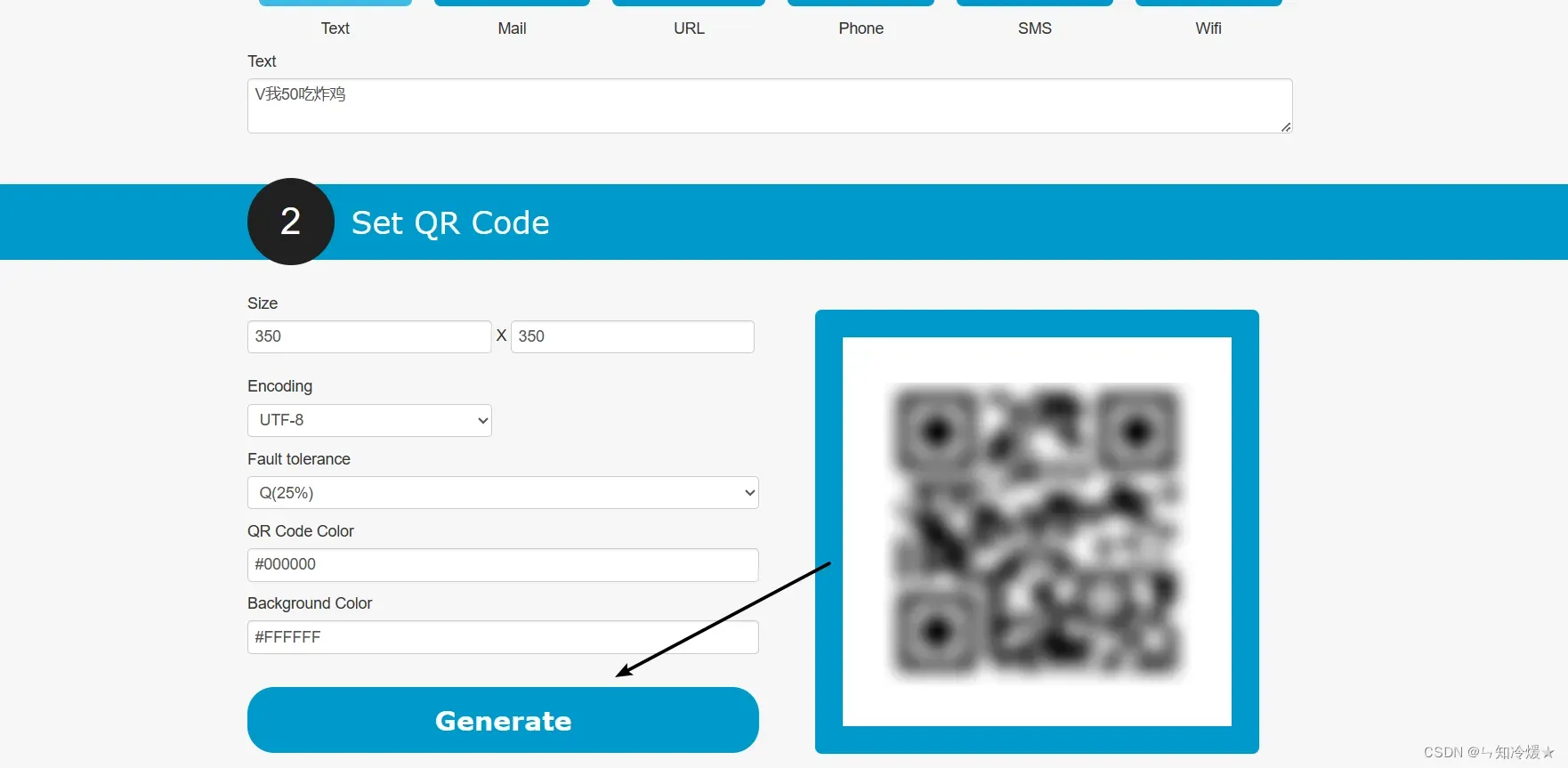
第三步:下载生成的二维码
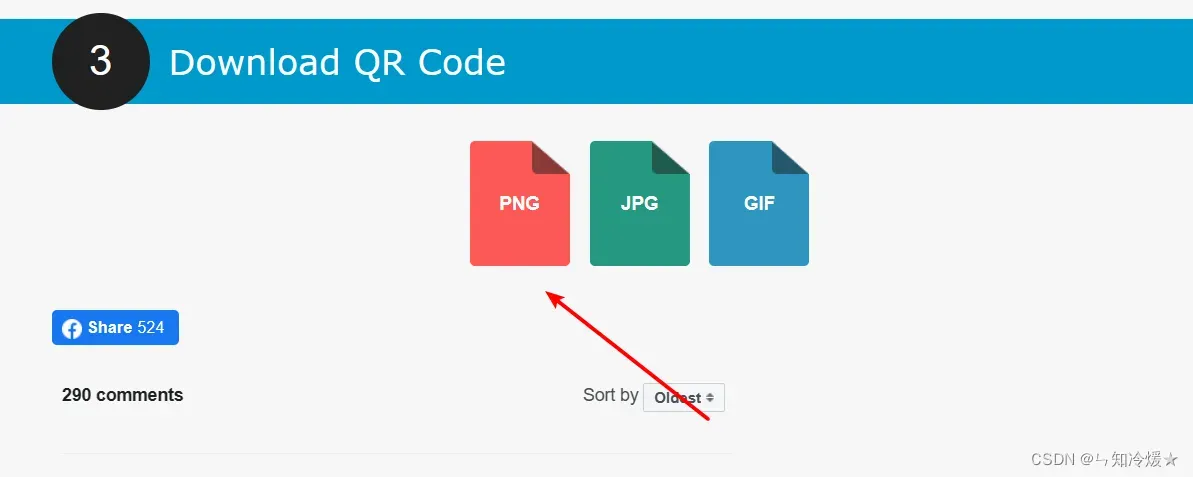
注意:直接截图个人二维码也是可以的,只不过识别通过率会降低一些。
2-1-2、选择云端平台来启动Stable Diffusion的Web UI
Web UI启动:使用云端平台方便、简洁,这里我们选择使用云端平台揽睿星舟-GPU算力平台,注册账号之后去寻找应用市场。现已上线以下功能:
正式发布-StableDiffusion1.6+SDXL全插件版,【内置全网最全插件】,已受到诸多用户好评:
①基础版所有插件
②ebsynth_utility
③sd-webui-animatediff
④sd-webui-EasyPhoto(官方合作,可炼模特LoRA,一键换脸)
⑤sd-webui-inpaint-anything(轻松点选确定蒙版区域,一键换脸,一键换背景)
⑥Stable-Diffusion-WebUI-TensorRT
网盘功能大更新【当你需要传自己的LoRA时】
①支持百度网盘直接传输,尊贵的VIP会员平均30MB/s速度,模型/插件传输不再焦虑等待
②支持URL直接传输,只需有下载地址,任何文件皆直接传输,不占用本地网速&空间。自带学术加速,支持C站直接拉取模型
秋葉炼丹镜像上线【当你需要更精细化的炼自己的LoRA时】
由秋葉亲手制作的丹炉镜像上线,配合4090,10分钟一炉丹!
具体操作步骤:
- 在我的应用里点击Stable-Diffusion
- 选择新建实例
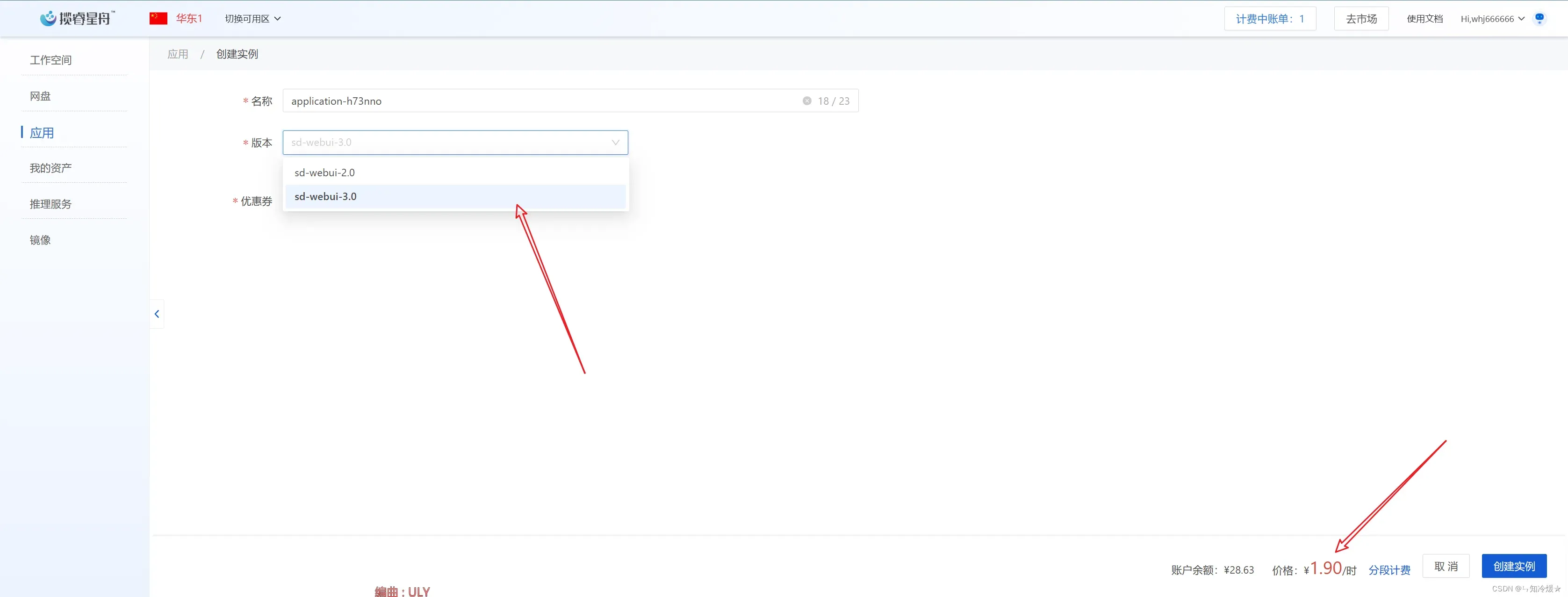
- 选择web3.0,这里默认使用3090,为1.9/h,点击创建实例。
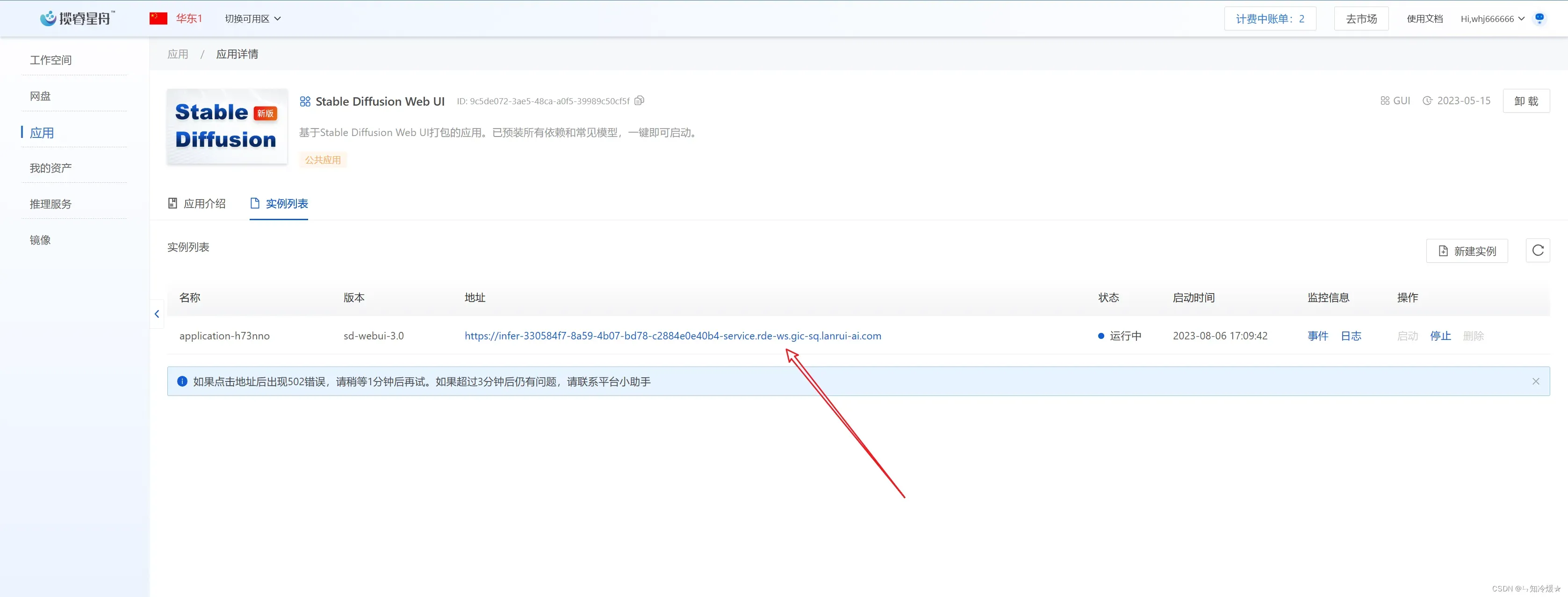
- 点击地址,即可进行体验。
2-1-3、使用Stable Diffusion来修饰二维码
打开网址后的界面如下:
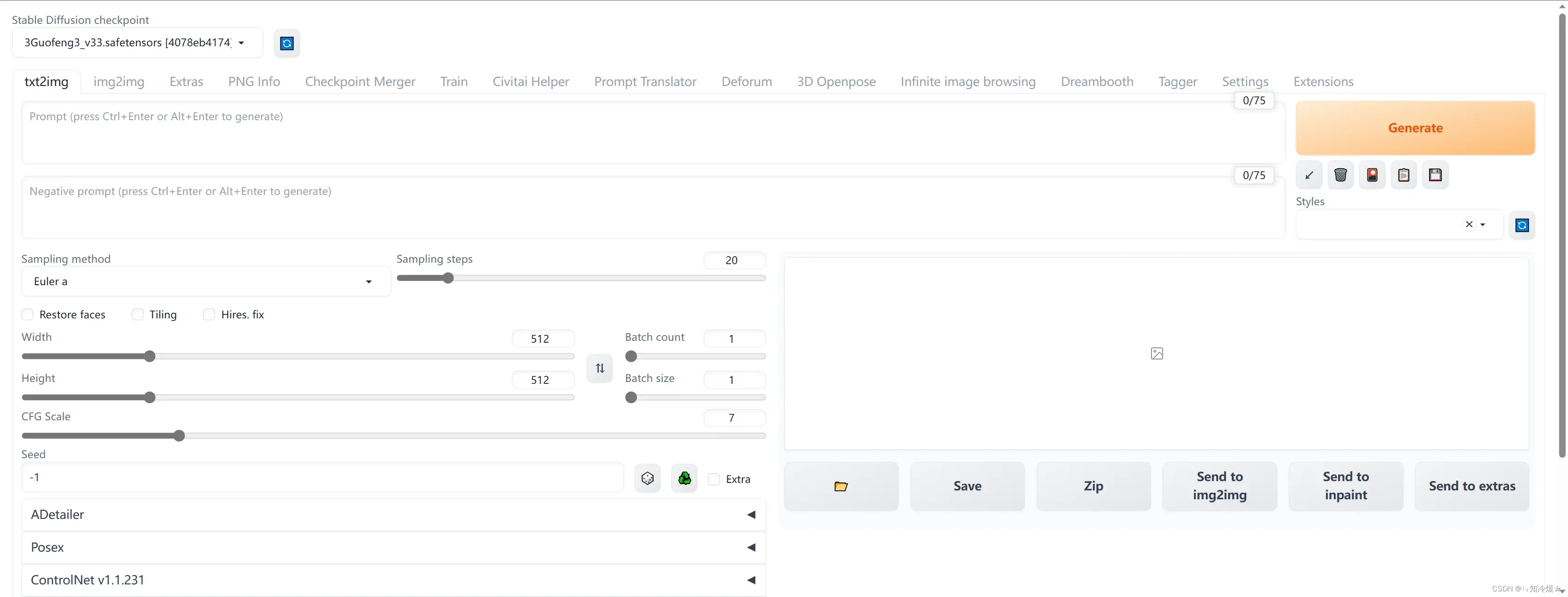
- 第一步:选择img2img并且上传二维码,调整好相关参数。
Resize mode: Just resize
Sampling method: DPM++2M Karras
Sampling step: 50
Width: 768
Height: 768
CFG Scale: 7
Denoising strength: 0.75
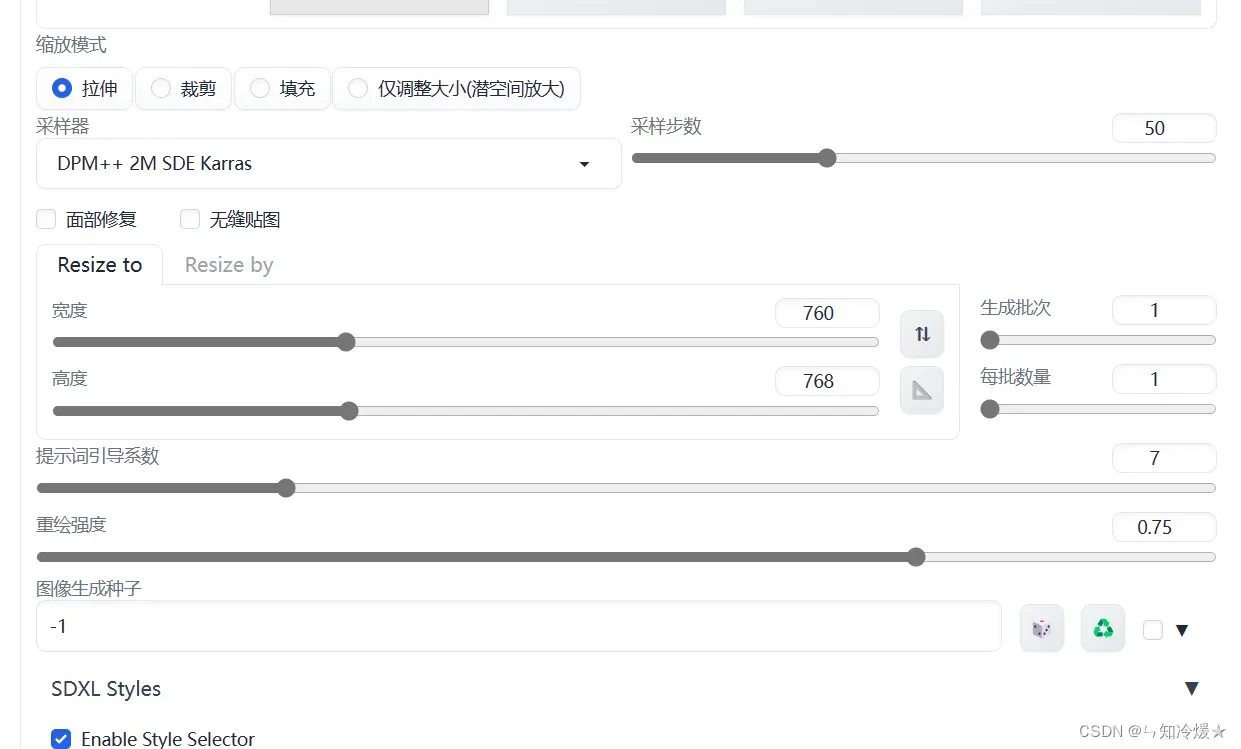
- 第二步:上传二维码到ControlNet,调整好相关参数后选择模型(我这里选的是国风3,可以尝试其他模型),点击生成即可。
Enable: Yes
Control Type: Tile
Preprocessor: tile_resample
Model: control_xxx_tile
Control Weight: 0.87
Starting Control Step: 0.23
Ending Control Step: 0.9
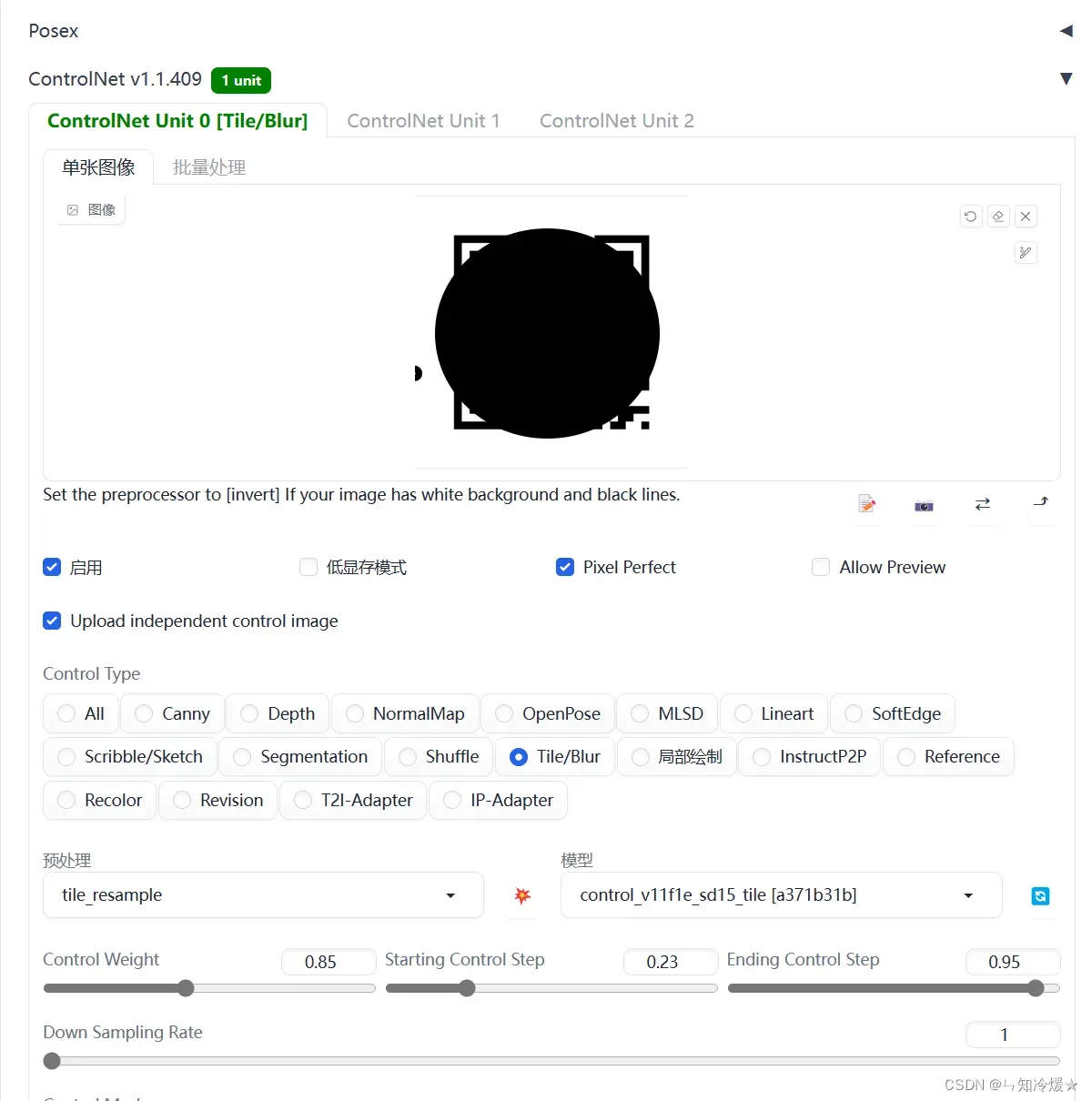
Prompt:
cloud, 1girl, sky, water, ocean, cloudy sky, blue eyes, blue sky, halo, window, solo, white hair, horizon, planet, constellation, day
Negative prompt:
ng_deepnegative_v1_75t, (low quality, worst quality:1.4), (bad anatomy), (inaccurate limb:1.2), bad composition, inaccurate eyes, extra digit, fewer digits, (extra arms:1.2)
- 完整界面如下:不是每一次都可以识别到二维码的,可以进行多次尝试。
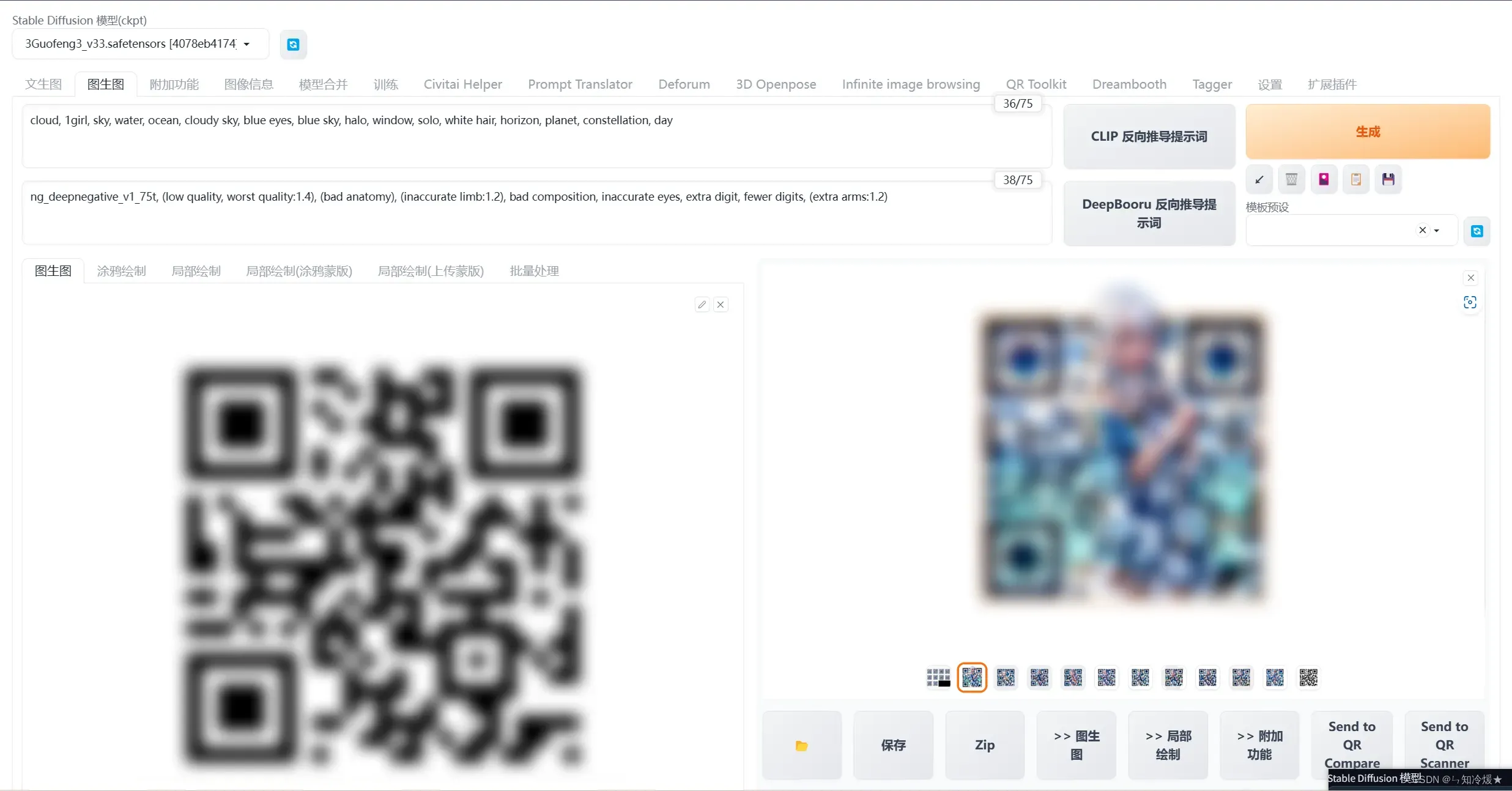
其他生成图片:



2-2、使用控制网络将文本转图像
文本转图像: 我们可以创造出带有提示的图像,就像给计算机一些关键信息让它完成绘画一样。而且我们还能够通过在图像制作过程中使用带有QR码输入的ControlNet,就像是给计算机一些特殊指令,来对图像生成过程进行精细调整和干预,确保最终的图像符合我们的预期。这就像是在制作一幅画时,不仅告诉计算机要画什么,还能在每一步告诉它怎么画,从而得到更理想的结果。相比于图像到图像,文本转图像会有更好的效果。
Stable Diffusion中的文生图介绍:
Stable Diffusion中的文生图采样脚本,称为”txt2img”,接受一个提示词,以及包括采样器(sampling type),图像尺寸,和随机种子的各种选项参数,并根据模型对提示的解释生成一个图像文件。生成的图像带有不可见的数字水印标签,以允许用户识别由Stable Diffusion生成的图像,尽管如果图像被调整大小或旋转,该水印将失去其有效性。 Stable Diffusion模型是在由512×512分辨率图像组成的数据集上训练出来的,这意味着txt2img生成图像的最佳配置也是以512×512的分辨率生成的,偏离这个大小会导致生成输出质量差。Stable Diffusion 2.0版本后来引入了以768×768分辨率图像生成的能力。每一个txt2img的生成过程都会涉及到一个影响到生成图像的随机种子;用户可以选择随机化种子以探索不同生成结果,或者使用相同的种子来获得与之前生成的图像相同的结果。 用户还可以调整采样迭代步数(inference steps);较高的值需要较长的运行时间,但较小的值可能会导致视觉缺陷。另一个可配置的选项,即无分类指导比例值,允许用户调整提示词的相关性(classifier-free guidance scale value);更具实验性或创造性的用例可以选择较低的值,而旨在获得更具体输出的用例可以使用较高的值。反向提示词(negative prompt)是包含在Stable Diffusion的一些用户界面软件中的一个功能(包括StabilityAI自己的“Dreamstudio”云端软件即服务模式订阅制服务),它允许用户指定模型在图像生成过程中应该避免的提示,适用于由于用户提供的普通提示词,或者由于模型最初的训练,造成图像输出中出现不良的图像特征,例如畸形手脚。与使用强调符(emphasis marker)相比,使用反向提示词在降低生成不良的图像的频率方面具有高度统计显著的效果;强调符是另一种为提示的部分增加权重的方法,被一些Stable Diffusion的开源实现所利用,在关键词中加入括号以增加或减少强调。
参数:
- Control weight: 权重越高,ControlNet对输出的影响越大。
- Start control step: ControlNet开始生效时生成进程的百分比。
- End control step: ControlNet停止生效时生成进程的百分比。

2-2-1、二维码生成
推荐使用QR Toolkit来生成二维码,网站界面如下:
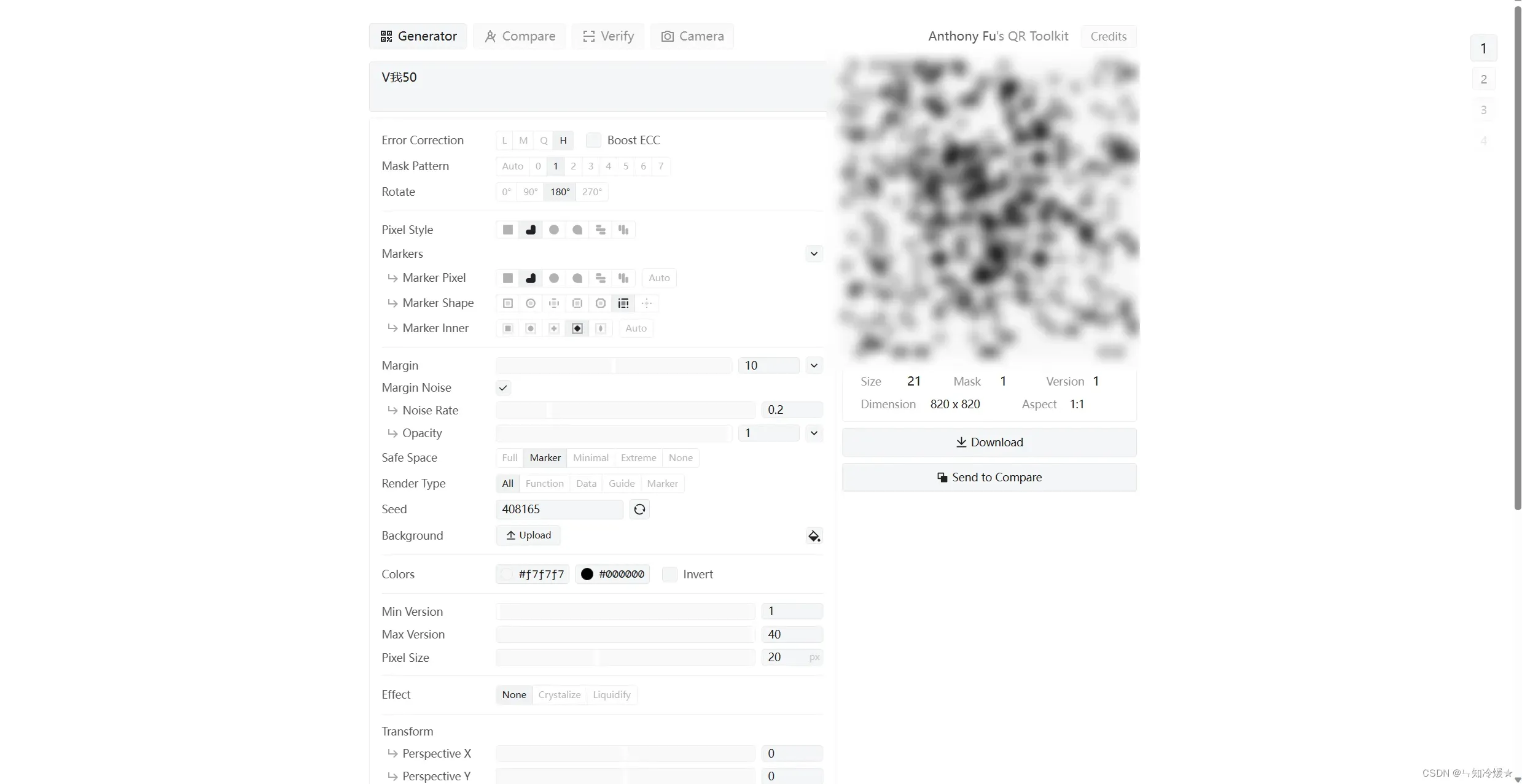
参数介绍:整体的一个构造思想——将二维码和你要绘制的图片融合在一起,使得整体看起来不违和,可以多次尝试。
- 文本框:填写你想制作成二维码的链接或者是文字。
- Error Correction: 容错率,数值越高,抗损毁能力越强,在二维码部分被损害的情况下也可以识别,这里建议选择最高。
- Boost ECC: 加强容错率,直接选。
- Mask Patten: 二维码样式,可以去尝试选择一个分布均匀的,这样与图片融合会更加自然。
- Markers: 二维码内部的一些样式,可以多去尝试,在能识别的情况下,尽可能让二维码变得均匀。
- Margin: 空白,在二维码边缘添加噪声,让二维码形式弱化。
- Transform:旋转,以x、y等方向旋转二维码。
2-2-2、安装插件——After Detailer
插件地址:https://github.com/Bing-su/adetailer
安装方式:
- 打开webui
- 打开 扩展栏-Extensions
- 打开 Install from URL栏
- 输入git地址并点击install,重新启动UI即可看到。
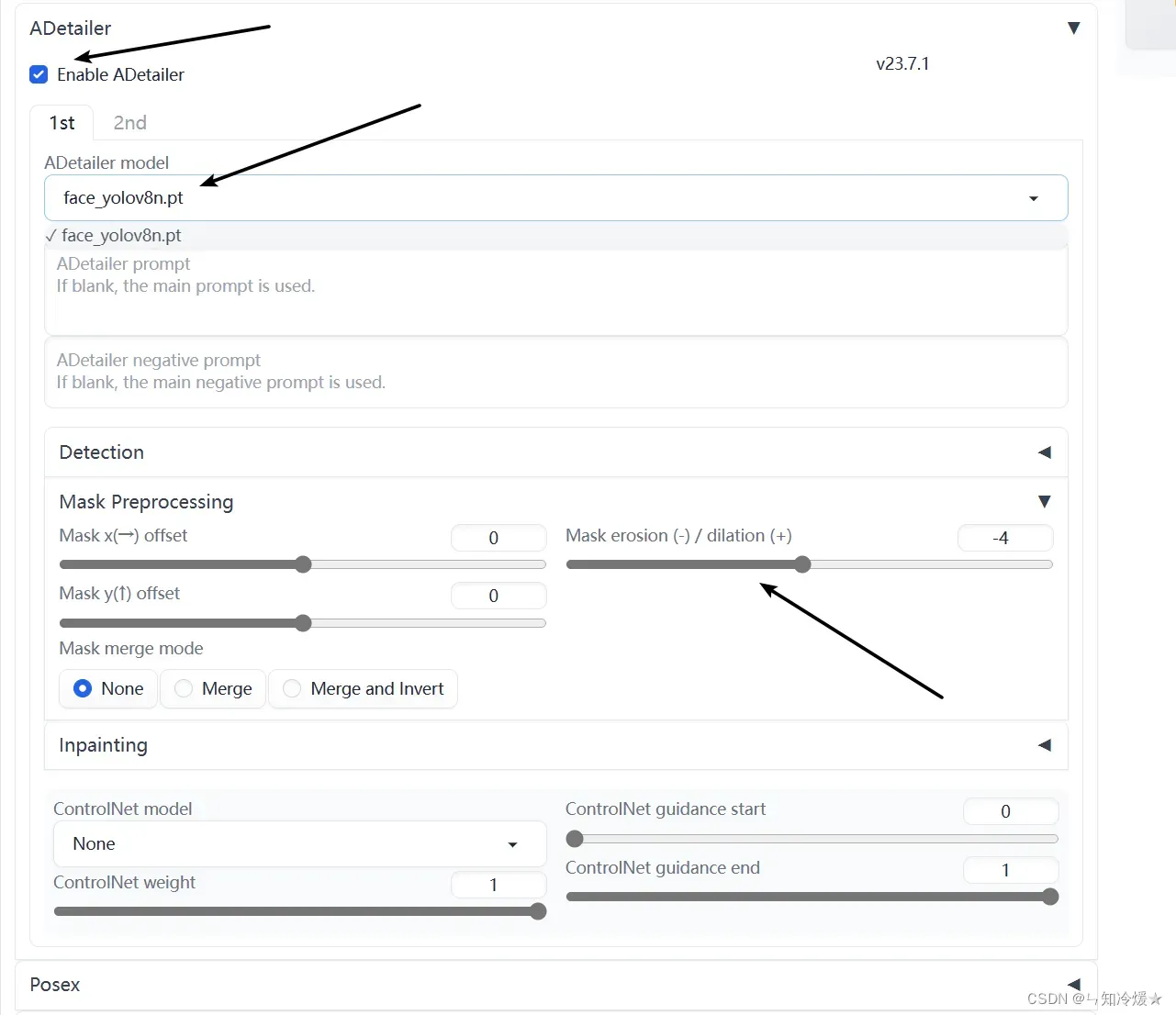
- 参数设置如下图所示:点击启用,选择模型,调整参数,其他不变
2-2-3、安装QR Code Monster 模型
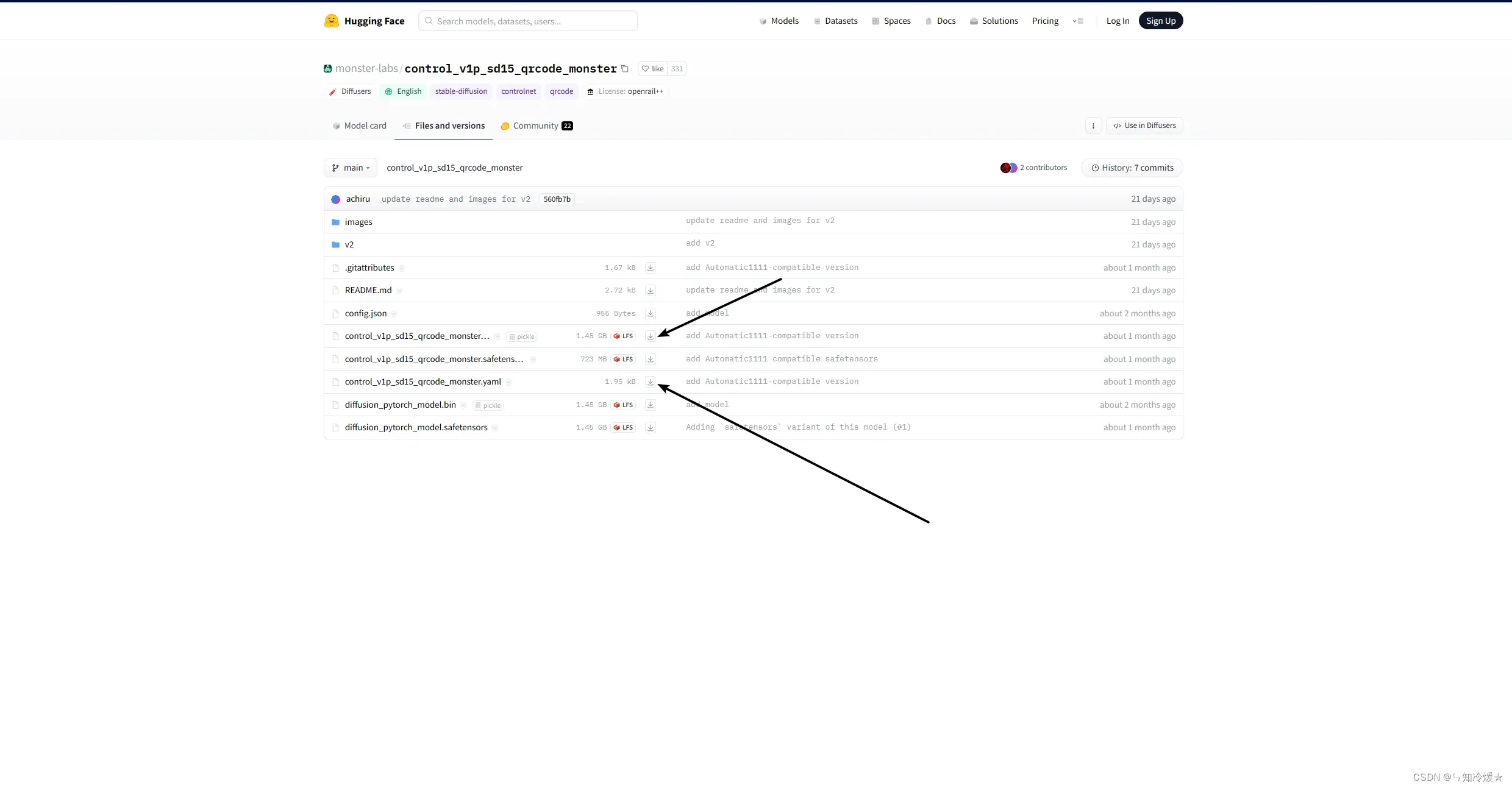
步骤:
- 打开https://huggingface.co/monster-labs/control_v1p_sd15_qrcode_monster,我们需要下载的是一个模型文件和一个配置文件
- 下载后将模型和配置文件放到Controlnet->models文件夹内。(模型文件和配置文件缺一不可!)
- 安装好后重启UI可以在ControlNet界面选择模型。
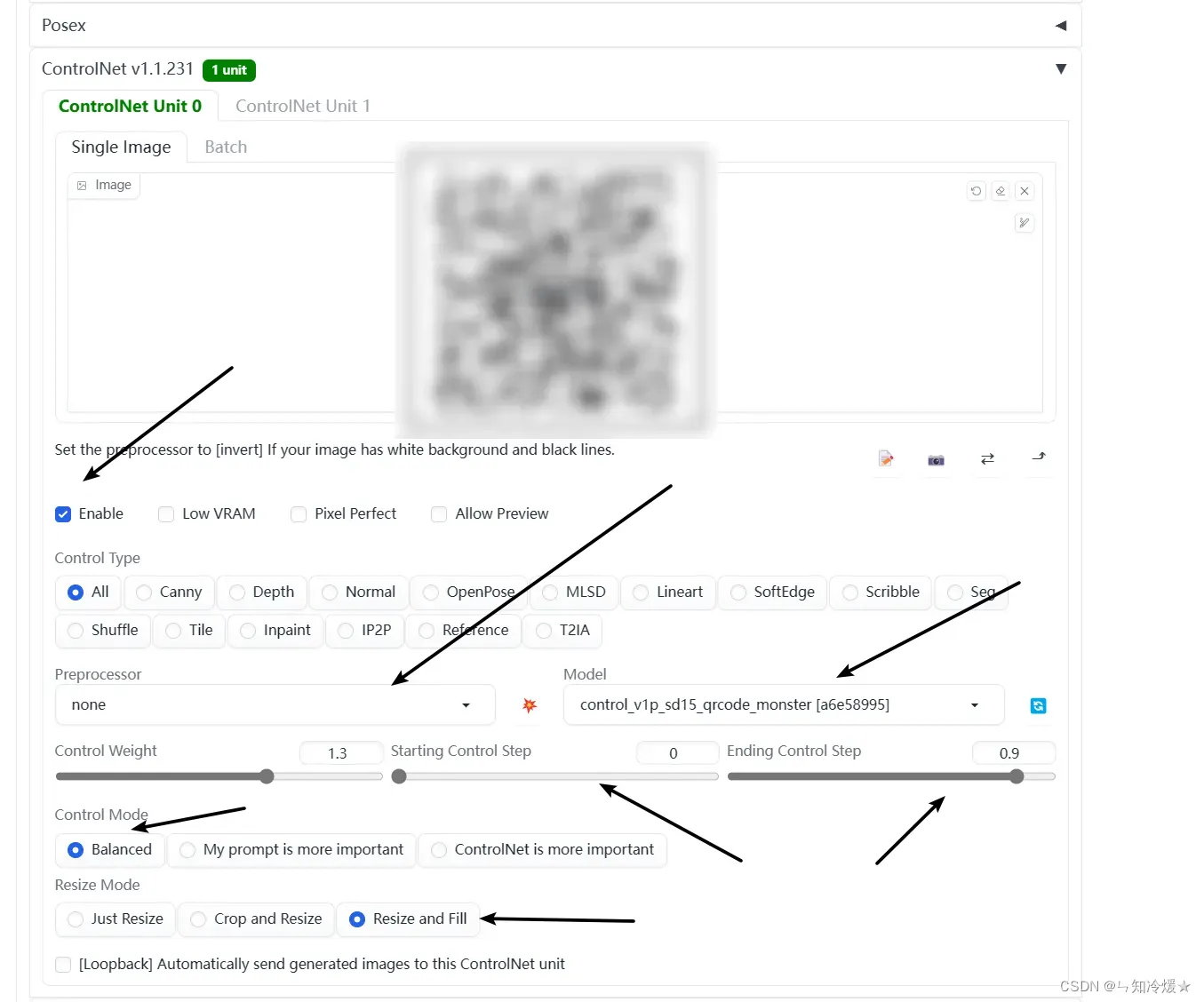
- 在ControlNet界面,启用该插件,预处理Preprocessor设置为None,即不进行预处理,模型设置为刚下载的模型,开始控制设置为0-0.1,终止控制设置为0.8-1,可以之后自行调参,控制模式设置为平衡,Resize Mode设置为 Resize and Fill。
2-2-4、模型参数设置
模型选择:我这里选择国风3,
步数:50
采样器:DPM++ 2M SDE Karras
CFG:7
尺寸:512*512 px
Hire.fix:是否开启高清修复,选择。
Prompts:
masterpiece, top quality, best quality, 1 girl, full body, flowers
Negative Prompts:
(nsfw)), (worst quality, low quality:2) , ng_deepnegative_v1_75t, EasyNegative, badhandv4
Prompts:
(masterpiece, high quality, highres,illustration),blurry background,[(white background:1.2)::5],cowboy shot,
spring (season),(no light:1.1),(temptation:1.2),elegance,
(1loli:1.1),(very long hair:1.1),(blush:0.7),floating hair,ahoge,deep sky,star (sky),
(summer (Floral:1.2) dress:1.1),outline,(see-through:0.85),shining,low twintails,
(polychromatic peony:1.15),Movie poster,(colorful:1.1),ornament,petals,(pantyhose:1.1),
ribbon,
Negative Prompts:
sketch, duplicate, ugly, huge eyes, text, logo, worst face, (bad and mutated hands:1.3), (worst quality:2.0), (low quality:2.0), (blurry:2.0), horror, geometry, bad_prompt, (bad hands), (missing fingers), multiple limbs, bad anatomy, (interlocked fingers:1.2), Ugly Fingers, (extra digit and hands and fingers and legs and arms:1.4), ((2girl)), (deformed fingers:1.2), (long fingers:1.2),(bad-artist-anime), bad-artist, bad hand, extra legs, nipples,nsfw,
参数界面:
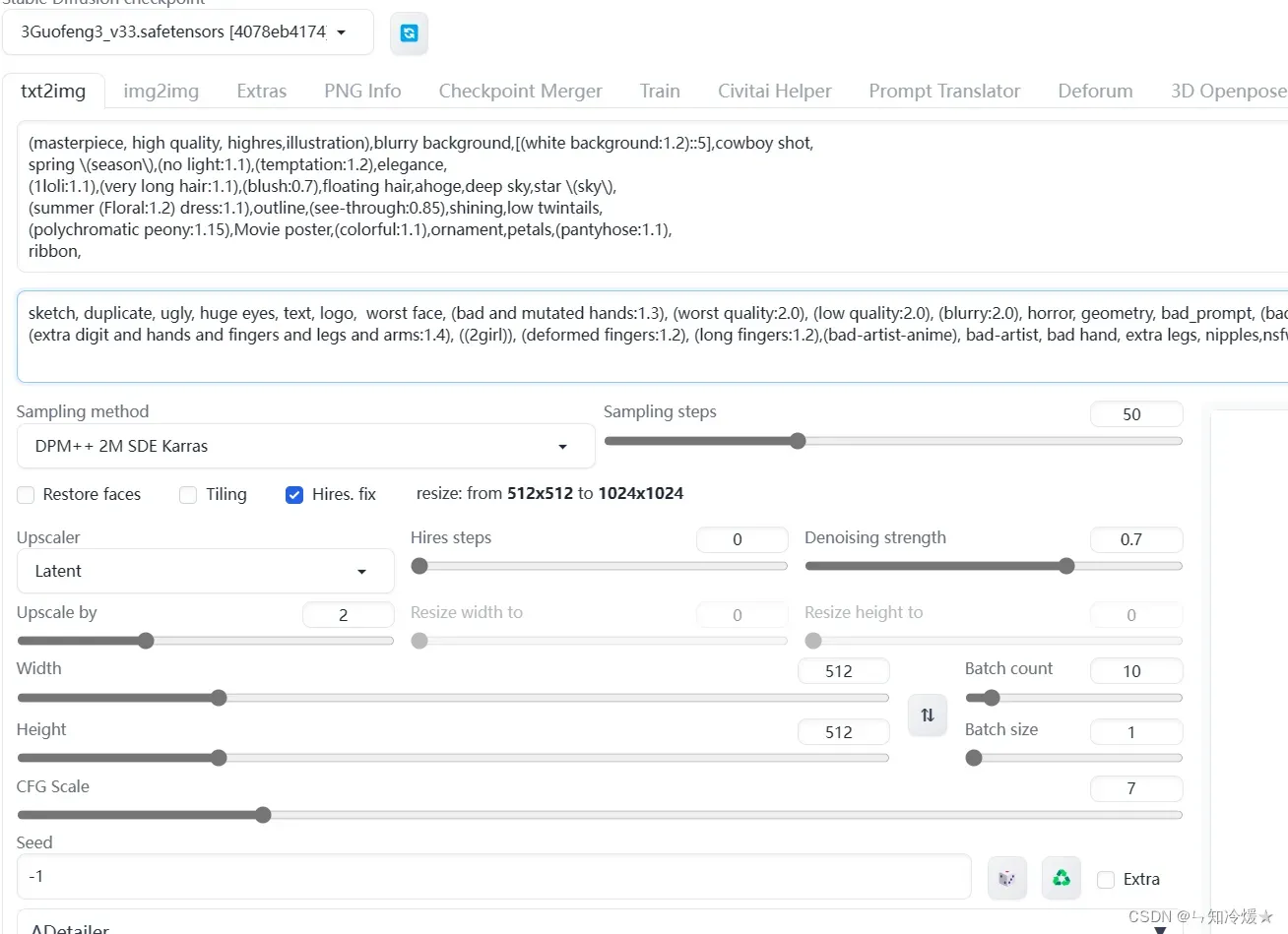
2-2-5、出图


三、附录
3-1、ControlNet模型
3-1-1、Controlnet QR Pattern (QR Codes)
Controlnet QR Pattern (QR Codes)链接:https://civitai.com/models/90940/controlnet-qr-pattern-qr-codes
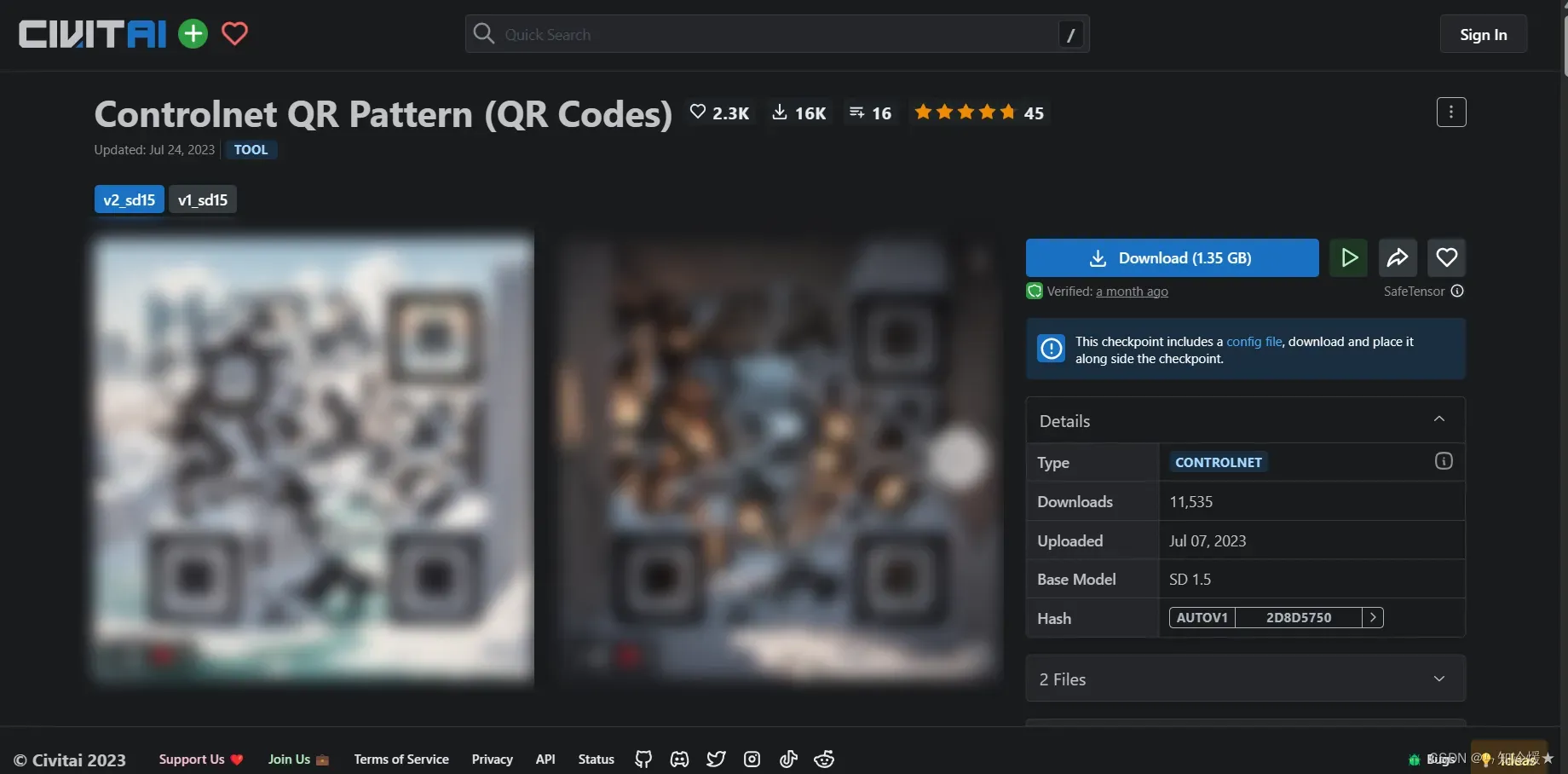
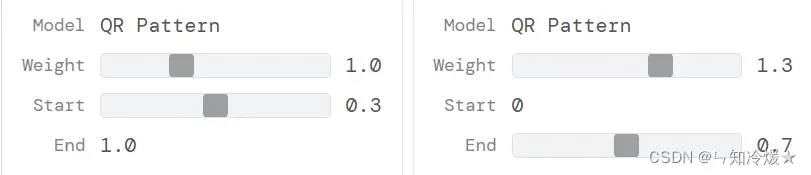
测试的可以识别到的最低参数权重:
3-1-2、monster-labs/control_v1p_sd15_qrcode_monster
monster-labs/control_v1p_sd15_qrcode_monster链接:https://huggingface.co/monster-labs/control_v1p_sd15_qrcode_monster
3-1-2、ioclab/ioc-controlnet
ioclab/ioc-controlnet链接:https://huggingface.co/ioclab/ioc-controlnet/tree/main/models
特别鸣谢以下参考文章的作者:
Stable Diffusion QR Code 101.
Stable Diffusion Knowledge Hub.
The Ultimate Stable Diffusion LoRA Guide (Downloading, Usage, Training).
ControlNet-GitHub.
How to make a QR code with Stable Diffusion.
AI – AI绘画的精准控图(ControlNet).
AIGC—— StableDiffusion中的ControlNet.
ControlNet v1.1: A complete guide
How does Stable Diffusion work?
Stable Diffusion Prompt 运用技巧
Prompt 工具網站
Stylistic QR Code with Stable Diffusion
Stable Diffusion丨模型管理插件Civitai Helper
保姆级教程!如何用AI快速生成超好看的艺术二维码?
QR Toolkit 插件 git 网址
After Detailer 插件
二维码融合技术2.0 简单实用AI教程 没想到一周不到就要把教程从头到尾推翻升级
总结
越来越有意思了😍
文章出处登录后可见!