- 写在前面,作为BraTS2019分割挑战赛的第一名,其内容比较新颖,目前来看,是脑肿瘤分割方法在nnUnet出来前的集大成者,能看到多阶段,深度监督等思想的体现,同样本文是一个workshop,写作上更加直接
Abstract
- 介绍本文的工作
- 在本文中,我们设计了一种新颖的两级级联U网来从粗略到精细地分割脑肿瘤的亚结构。【这里主要说的是两级级联的策略,也是一种常规的策略,即第一阶段进行粗分割,第二阶段执行细分割与调整粗分割结果】
- 该网络在多模式脑瘤分割挑战赛(BRATS)2019年的训练数据集上进行了端到端的训练。【这里应该设计了的是端到端的两阶段模型,比传统的分开训练的两阶段模型来说,可能速度上更有优势,那么这里是不是会设计一个深度监督的思想,在第一阶段模型的输出进行监督训练】
- 介绍本文的实验结果
- 在测试集上的实验结果表明,对于增强的肿瘤、整个肿瘤和肿瘤核心,该方法的平均DICE得分分别为0.83267、0.88796和0.83697,豪斯道夫距离(95%)分别为2.65056、4.61809和4.13071。
- 该方法在Brats 2019挑战细分任务中获得第一名,参与挑战的团队超过70支。
- Keywords: Deep learning · Brain tumor segmentation · U-Net
1 Introduction
- 简单介绍一下工作背景,即脑胶质瘤分割的意义
- 胶质瘤是最常见的原发性脑肿瘤类型。自动 3D 脑肿瘤分割可以节省医生的时间,并为额外的肿瘤分析和监测提供合适的方法。
- 最近,深度学习方法一直优于传统的脑肿瘤分割方法。 [目前,深度学习在脑肿瘤分割方面优于传统分割方法。也就是说,其他人都在做,我也在做深度学习,但我可能是深度学习中更好的方法]
- 介绍挑战赛的情况和挑战赛提供的数据集
- 多模式脑瘤分割挑战(BraTS)旨在评估最先进的脑瘤分割方法。【这基本是挑战赛的目的所在,基本写挑战赛的小短文的时候都能套用】
- BraTS 2019训练数据集包括259例高级别胶质瘤(HGG)和76例低级别胶质瘤(LGG)。训练数据集包括259例高级别胶质瘤(HGG)和76例低级别胶质瘤(LGG),由临床医生和委员会认证的放射科医生手工注释。【这里注意一下这个LGG,其实LGG里面可能有的数据标签与HGG不一致,也是目前挑战赛里面SOTA里面进行强行舍弃一部分ET的原因】
- 数据如下
- 对于每个患者,提供了自然平扫(T1)、增强后T1加权(T1Gd)、T2加权(T2)和T2液体衰减反转恢复(T2-FLAIR)。【这里其实就是T1w,T1CE,T2,FLAIR】
- 图 1 显示了一个示例图像集。每个肿瘤被分割为增强肿瘤、瘤周水肿以及坏死和非增强肿瘤核心。多项指标(Dice 得分、Hausdorff 距离 (95%)、敏感性和特异性)被用来衡量参与者提出的算法的分割性能。
- 介绍往年挑战赛或者数据集上别人开发算法的情况(其实就是Realted work)
- 在Brats 2017年,Kamnitsas等人是该挑战的第一名获胜者,他提出了多个模型和架构的集成(EMMA)来实现稳健的分割,这是通过结合包括DeepMedic、3D U-Net和3D FCN在内的几种网络架构来实现的,这些网络通过不同的损失函数,如骰子损失和交叉熵损失,用不同的优化过程进行训练。【这里其实主要是想凸显自身端到端的优越性】
- 在BraTS 2018中,在测试数据集上取得最佳性能的Myronenko[15]使用了一个不对称的U形网络,带有一个更大的编码器来提取图像特征,以及一个更小的解码器来重建标签。他将一个非常大的面片大小(160×192×128个体素)输入到网络中,还添加了一个变分自动编码器(VAE)分支,以便对共享编码器进行正则化。
- 介绍本文的工作
- 在这项工作中,受级联策略[19,22,25,26]的启发,我们提出了一种新的两级级联U网络。在第一阶段,我们使用U-Net的一个变体作为网络训练的第一阶段进行粗预测。
- 在第二阶段,我们增加网络的宽度并使用两个解码器来提高性能。第二阶段是通过将初步预测图与原始输入连接以利用自动上下文来细化预测图。我们不使用任何额外的训练数据,只在测试阶段参与分割任务
2. Method
- 介绍第一阶段模型的由来
- Myronenko[15]提出了一种具有可变自动编码器分支的非对称U网络[5,11]。在本文中,我们采用这种方法的一种变体作为基本的分割架构。我们进一步提出了一种两级级联U型网络。具体说明如下
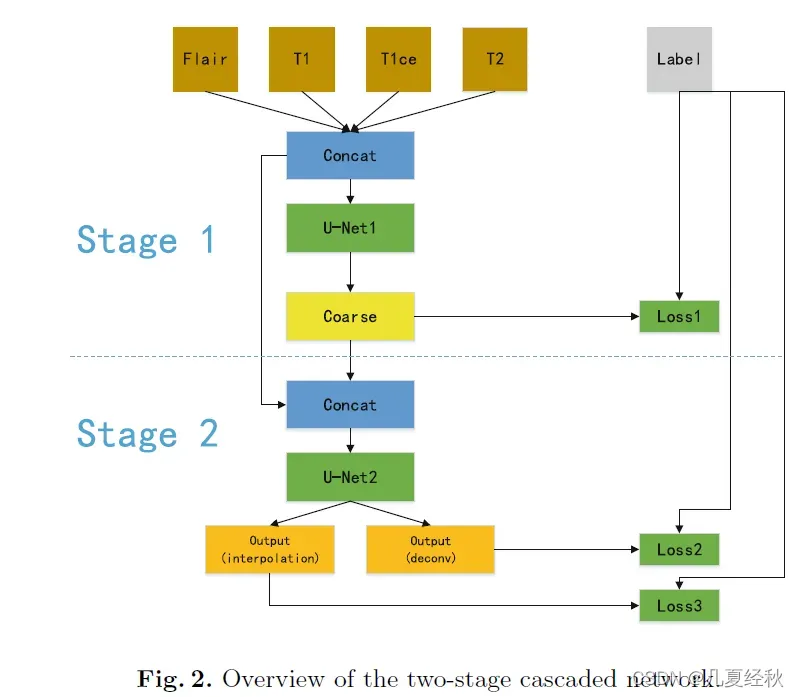
2.1 Model Cascsde
- 引入模型级联规则
- 如图2所示,在第一阶段中,多模态磁共振图像(4×128×128×128)被传递到第一阶段的U网络中,并粗略预测分割图。粗分割图与原始图像一起送入第二级U网。第二阶段可以用更多的网络参数提供更精确的分割图。两级级联网络以端到端的方式进行训练。
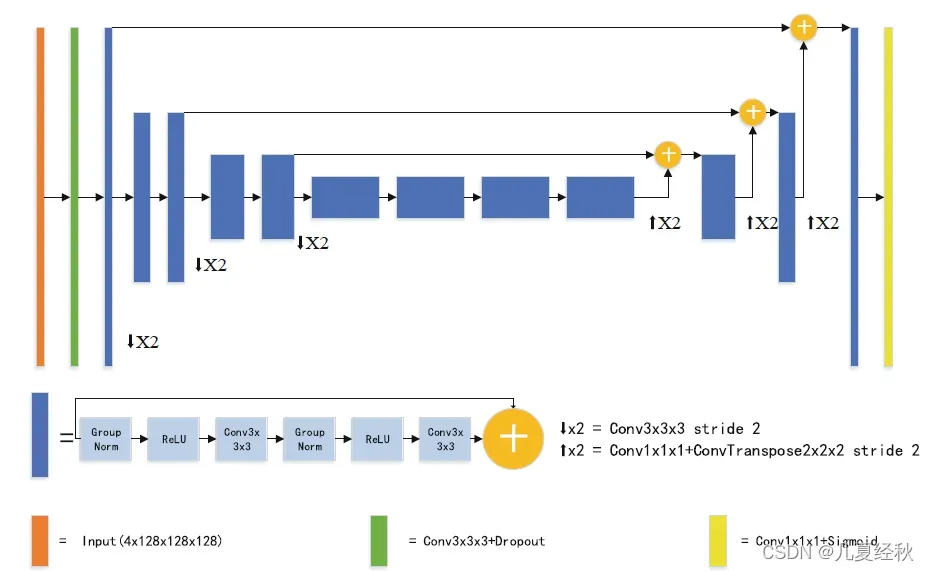
2.2 The First Stage Network Architecture
- 介绍一阶段模型设计的一些原因
- 由于 GPU 内存的限制,我们的网络被设计为采用大小为 128×128×128 体素的输入块,并使用一个批量大小。【128是一个常用的输入大小,如果再大一点的话对于显存需求就太高了,同时batchsize 设置为1,这也是为啥会用到GN的原因】
- 网络架构包括一个较大的编码路径,用于提取复杂的语义特征,以及一个较小的解码路径,用于恢复具有相同输入大小的分割图。第一阶段网络的架构如图 3 所示。
- 介绍编码器设计的一些细节
- 3D U-Net有一个编码器和一个解码器路径,每个路径都有四个空间级别。在编码器开始时,从脑肿瘤图像中提取具有四个通道的128×128×128体素块作为输入,然后使用16个滤波器进行初始3×3×3三维卷积。
- 我们还使用了初始编码器卷积后速率为0.2的丢失。编码器部分使用预激活的残差块。每个块由两个3×3×3卷积组成,组归一化,组大小为8,校正线性单元(ReLU)激活,然后是加性标识跳过连接。在每个空间级别内,预激活的剩余块的数量为1、2、2和4。
- 此外,使用一个带有3×3×3滤波器和2步长的卷积层,将特征地图的分辨率降低2,同时将特征通道的数量增加2。【目前比较普遍的是用卷积带步长为2的形式进行下采样,主要是考虑到这种卷积是可学习的,在少量增加参数的前提下进行一定的性能提升】【所谓的预激活模块,其实就是先做非线性变换和归一化之后再进行卷积,是否有成熟理论支撑本人还未进行相关资料查阅】
- 解码器设计简介
- 与编码器不同,解码器结构对每个空间级别使用单个预激活的剩余块。在上采样之前,我们使用1×1×1卷积将特征数减少2倍。与[15]相比,我们使用核大小为2×2×2的反卷积和2的步长,而不是三线性插值,以便将空间维度的大小增加一倍。【这种上采样方法也是目前主流的上采样策略,而不再是使用插值】
- 该网络的特点是编码器和解码器中具有相同分辨率的相应层之间通过元素求和进行快速连接。【这里应该对应的是cat操作,将编码器中的特征图与同一分辨率的解码层的特征图相加】
- 在解码器的末尾,使用1×1×1卷积将输出通道数减少到三个,然后是一个sigmoid函数。结构细节如表1所示。【softmax和sigmoid到底怎么选择,等待继续学习】
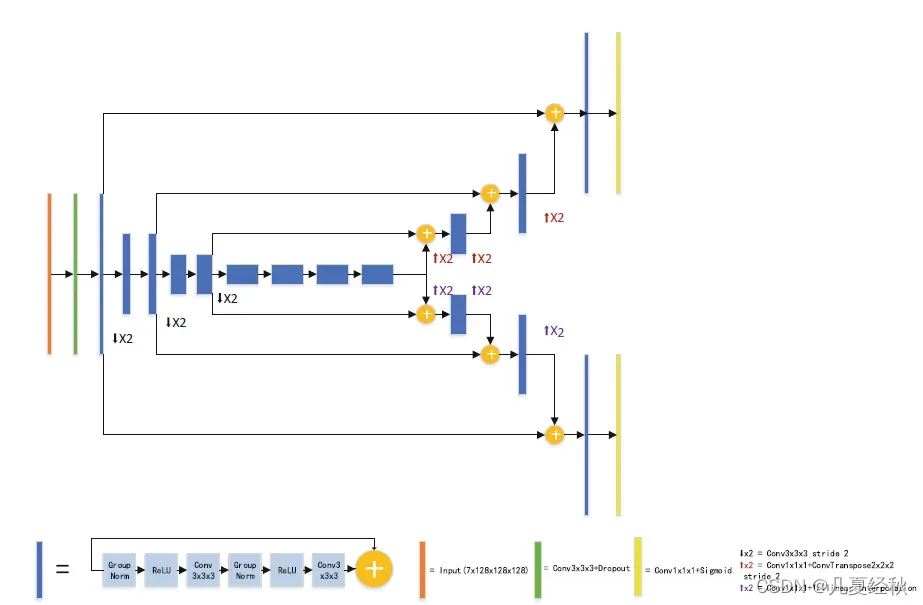
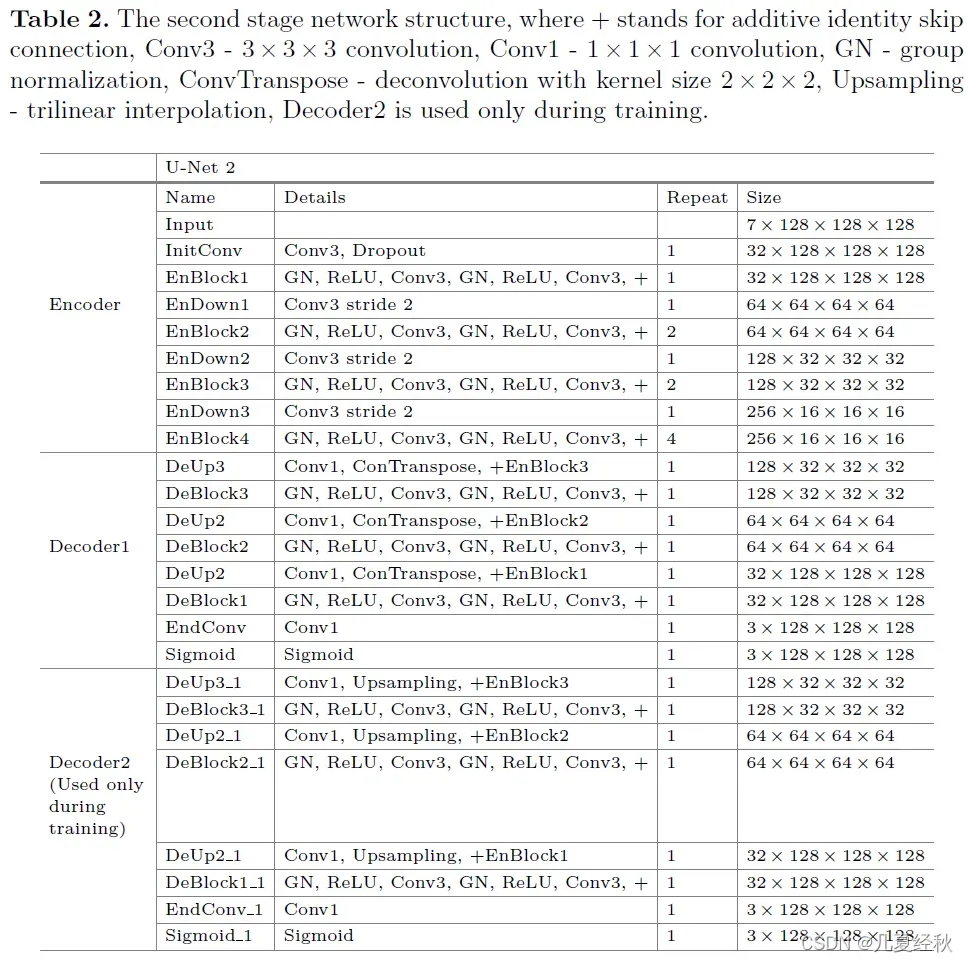
2.3 The Second Stage Network Architecture
- 介绍第二阶段模型设计
- 与第一阶段的网络不同,我们在初始3D卷积中增加了两倍的滤波器数量,以增加网络宽度。【估计是这种设计可以增加模型的宽度实现了精度的提升】
- 此外,我们还使用了两个解码器。这两个解码器具有相同的结构,只是一个使用反卷积,另一个使用三线性插值。 【其实我也不是很明白为什么会这样设计?有理论依据吗?】
- 三线性插值只在训练期间使用。因为使用反卷积的解码器的性能优于使用三线插值的解码器,而增加一个使用三线插值的解码器来规范共享编码器的性能可以在我们的实验中提高了性能。第二级网络的结构如图4所示,结构的细节见表2。【这种设计有点类似不足反卷积的信息,通过两个解码器的训练损失对整体进行修正,但是不确定其具体训练是否采用的是两个路径的损失函数进行反向传播更新】
2.4 LOSS
- 引入损失函数
- 骰子相似系数(DSC)衡量预测地图和地面事实之间的重叠程度。DSC按公式计算。1,其中S是网络的输出,R是地面真值标签,|·|表示区域的体积。
其中soft dice 的公式如下:【分母变成平方和了】 - 我们没有学习标签(例如增强肿瘤、水肿、坏死和非增强),而是直接用 dice loss 优化三个重叠区域(整个肿瘤、肿瘤核心和增强肿瘤),然后简单地为每个区域添加 dice loss 函数向上。我们还将每个阶段的损失相加得到最终损失。
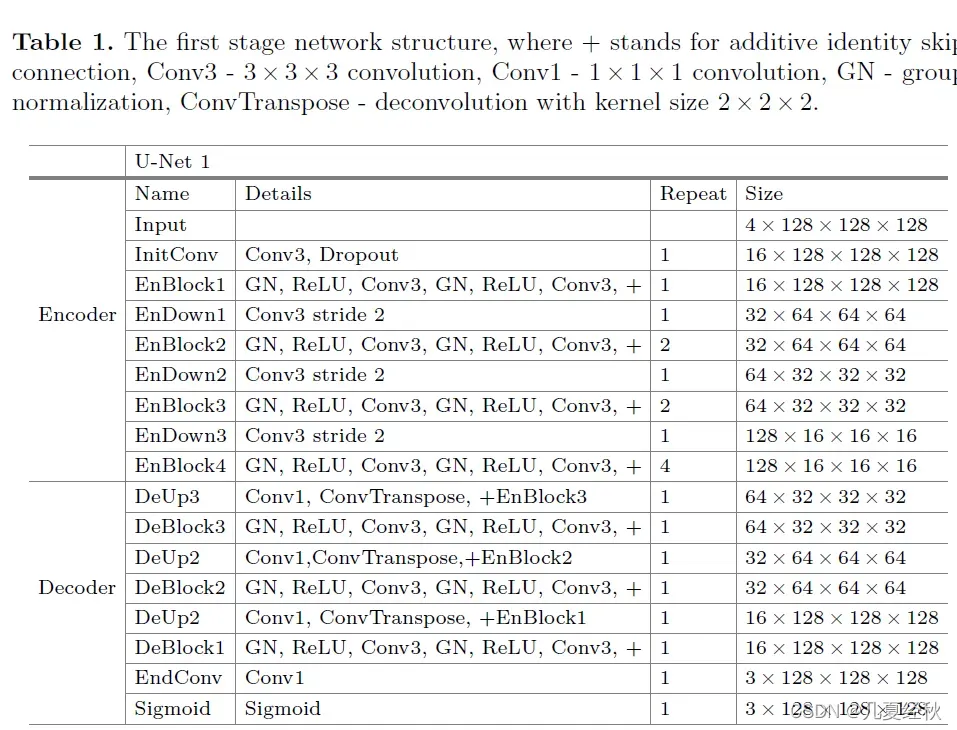
- 第一阶段结构表【TransBTS的CNN结构就类似此结构,但是他的结果不可复现】
- 第二阶段结构表
3 Experiments
3.1 Data Pre-processing and Augmentation
- 数据预处理和数据增强是必不可少的步骤
- 在将数据输入深度学习网络之前,使用预处理方法对输入数据进行处理。由于MRI强度值是非标准化的,我们通过减去平均值并仅除以大脑区域的标准偏差,对每位患者的每种MRI模式分别应用强度标准化。【基本操作是通过一个mask获得脑区部分,然后减去均值除以标准差的方式进行归一化】
- 此外,为了防止出现过度拟合问题,我们实现了三种类型的数据扩充。首先,我们在两个图像之间应用每个通道标准偏差的随机强度偏移[−0.1−0.1],以及刻度之间输入的随机刻度强度[0.9]−1.1].
- 其次,由于内存限制,我们通过将240×240×155个体素的MRI数据随机裁剪到128×128×128个体素来训练我们的网络。
- 最后,我们使用沿每个3D轴随机翻转,概率为50%。【我测试过,添加随机翻转之后,时间耗费会多很多】
3.2 Training Details
- 主要讲一些实现细节,比如什么框架,优化器,学习率变化等等。
- 我们的网络实现基于PyTorch 1.1.0。训练迭代的最大次数被设置为具有5个线性预热epoch的405个epoch。
- 我们使用ADAM优化器来更新网络的权重,最初的批大小为1,初始学习率为α₀=1e-4,并将其衰减如下:
- 其中,e是epoch计数器,而分母ne是epoch。我们使用1e−5的L2权重衰减进行正则化。
- 训练在具有12 GB内存的NVIDIA Titan V图形处理器上执行。然而,在我们的实验中,我们的方法需要略多于12 GB的内存。我们利用PyTorch的梯度检查点来减少内存消耗。【checkpoint技术?】
3.3 Augmentation for Inference
- 介绍推理时增强,也就是所谓的TTA
- 在测试时,我们一次分割了整个大脑区域,而不是使用滑动窗口。
- 在推理阶段不使用插值解码器。为了获得更稳健的预测,我们在最后一次训练过程中保留了模型的八个权重进行预测。对于每个快照,输入图像在输入到网络之前都会进行不同的翻转。最后,我们平均八个分割概率图的输出。 [这有点类似于取平均值]
3.4 Post-processing
- 这个后处理操作都是为了来涨分的,应该也就是LGG没标注ET部分
- 当预测的增强肿瘤的体积小于阈值时,我们用坏死来替换增强肿瘤,以对我们的分割结果进行后处理(阈值是为每个实验单独选择的,取决于BRATS 2019验证数据集的性能)。
4. Results
- 展示实验结果
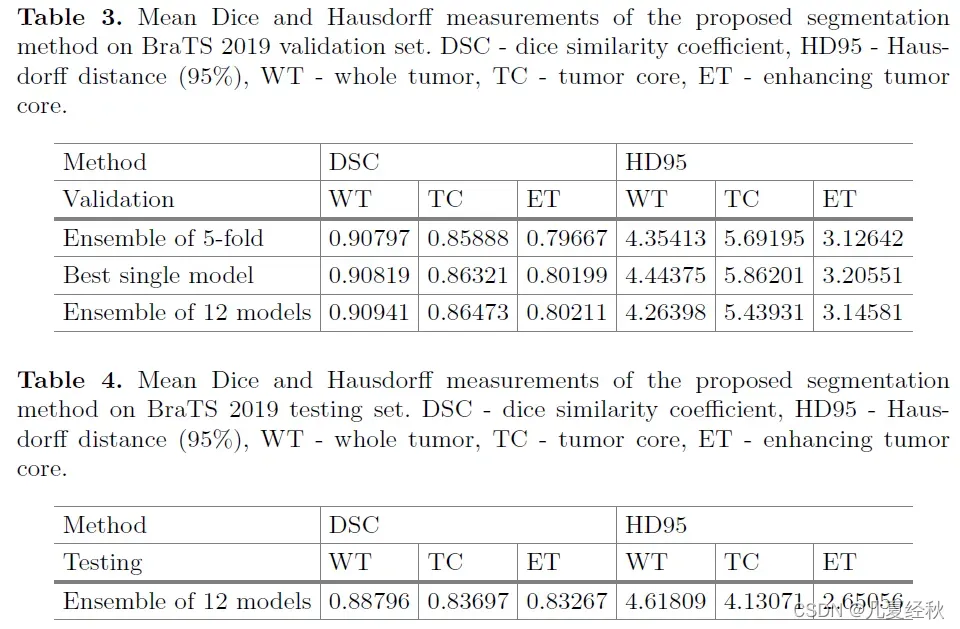
- 单一模型的可变性可能相当高。我们使用5次交叉验证中的总共五个网络作为集成来预测BRATS 2019验证数据集的分割。此外,我们使用了一个由12个模型组成的集合,这些模型是使用整个训练数据集从头开始训练的。从12款模型中选出最好的一款。
- 我们在BraTS 2019验证数据集上报告了我们的方法的结果,该数据集包含125例未知胶质瘤分级和未知分割的病例。
所有报告值均通过在线评估平台(https://ipp.cbica.upenn.edu)计算,以评估Dice评分、敏感性、特异性和Hausdorff距离(95%)。验证集结果见表3。最佳单一模型的性能略好于5倍交叉验证的整体。与最好的单一模型相比,12个模型的集成结果略有改善。 - 测试集结果如表4所示。我们的算法在70多个参赛团队中获得第一名
5 Conclusion
- 总结本文的工作和贡献
- 本文提出了一种两级级联U型网络。我们的方法通过一个渐进的级联网络来改进预测。
- 在BraTS 2019验证集上的实验表明,即使使用单一模型,我们的方法也可以获得非常有竞争力的分割。
- 测试结果表明,我们提出的方法能够获得优异的性能,在70多个参与团队中赢得了BraTS 2019挑战分割任务的第一名。
- 简单总结
- 文章为啥能取得如此好的效果主要在于model的设计,即两阶段思想的设计,首先完成粗分割然后进行精细的微调,实际上作为一个两阶段的端到端的模型,在效率上可能并不一定占优,但是取得的精度确实证明模型的设计非常的strong和rubust
- 文章里面用的relu,GN等其实都是做的取舍,是显存效率与精度之间的取舍。(个人看法)
即两阶段思想的设计,首先完成粗分割然后进行精细的微调,实际上作为一个两阶段的端到端的模型,在效率上可能并不一定占优,但是取得的精度确实证明模型的设计非常的strong和rubust - 文章里面用的relu,GN等其实都是做的取舍,是显存效率与精度之间的取舍。(个人看法)
- 稍后更新
文章出处登录后可见!
已经登录?立即刷新