- 标题:Human-level control through deep reinforcement learning
- 文章链接: Human-level control through deep reinforcement learning
- 发表:Nature 2015
- 领域:off-policy 强化学习经典
- 摘要:强化学习理论对于 “agent 如何优化其对环境的控制” 提供了一个规范的解释,这个解释是牢固地建立在动物行为心理学和神经科学观点之上的。然而,为了在接近现实世界复杂性的情况下成功地使用强化学习,agent 面临着一项艰巨的任务:他们必须从高维感官输入中获得环境的有效表示,并使用这些将过去的经验推广到新的情况。值得注意的是,人类和其他动物似乎通过强化学习和分层感觉处理系统的和谐结合来解决这个问题,大量神经数据揭示了多巴胺能神经元发出的相位信号与时间差异强化学习算法之间的显着相似性。虽然强化学习 agent 在多个领域取得了一些成功,但它们的适用性以前仅限于可以手工制作有用特征的领域,或具有完全可观察的低维状态空间的领域。在这里,我们利用深度神经网络的最新进展来开发一种称为 Deep Q-network 的新型人工 agent,它可以使用端到端强化学习直接从高维感官输入中学习成功的策略。我们在 Atari 2600 游戏这一有挑战性的领域测试了该 agent,并且证明:仅接收画面像素和游戏分数作为输入的 Deep Q-network agent 的性能超越了所有先前算法,并在使用相同的算法、网络架构和超参数的情况下,在 49 款游戏中达到与专业人类游戏测试员相当的水平。这项工作弥合了高维感官输入和动作之间的鸿沟,从而产生了第一个能够学习在各种具有挑战性的任务中表现出色的人工代理。
文章目录 - 1. 本文方法
- 1.1 思想
- 1.2 Deep Q Network(DQN)
- 1.3 经验重放
- 1.4 Target Q-network
- 1.5 Clip the error
- 1.6 伪代码
- 2. 实验
- 2.1 实现细节
- 2.2 效果
- 3 总结
1. 本文方法
1.1 思想
- 本文关注的核心是如何将 RL 算法扩展到连续的、高维的状态空间中(动作空间还是离散的)。过去的表格型方法(如 Q-learning 等),使用 Q-Table 存储所有
或
的价值,这在离散、低维的状态空间中没什么问题,但当状态空间非常复杂时,表格的大小会快速上升到无法接受的程度
- 这里有两个关键问题
- 状态空间的维数太高,不能直接用原始状态向量作为状态的表示
(离散空间)
- 针对这两个问题,笔者采用以下方法解决
- 对状态空间进行降维,由于测试环境都是 Atria 的 2D 游戏,作者使用了擅长提取图像特征的 CNN 卷积神经网络作为嵌入函数,降低 agent observation 的维度
- 使用参数逼近法减少待估计参数数量,即用一个具有参数
的参数化价值函数来代替 Q-Table,这样就能把要估计的参数数量减少到
具体实现上,作者设计了一个三卷积层 + 两全连接层的端到端神经网络同时达成上述两个目标,对于某一个状态,输入游戏图像,输出各个动作的价值。注意,本文方法 DQN 仅适用与离散动作空间
1.2 Deep Q Network(DQN)
- 使用神经网络参数化 Q 价值时,早期的一些工作将 history-action pair(其实就是

- 在本文中,作者使用了一个更加巧妙的结构,网络的输入是状态表示,每个可能的动作都有一个单独的输出单元给出其预测 Q 价值。这样我们就能通过一次前向传递计算出给的状态下的所有可行动作价值
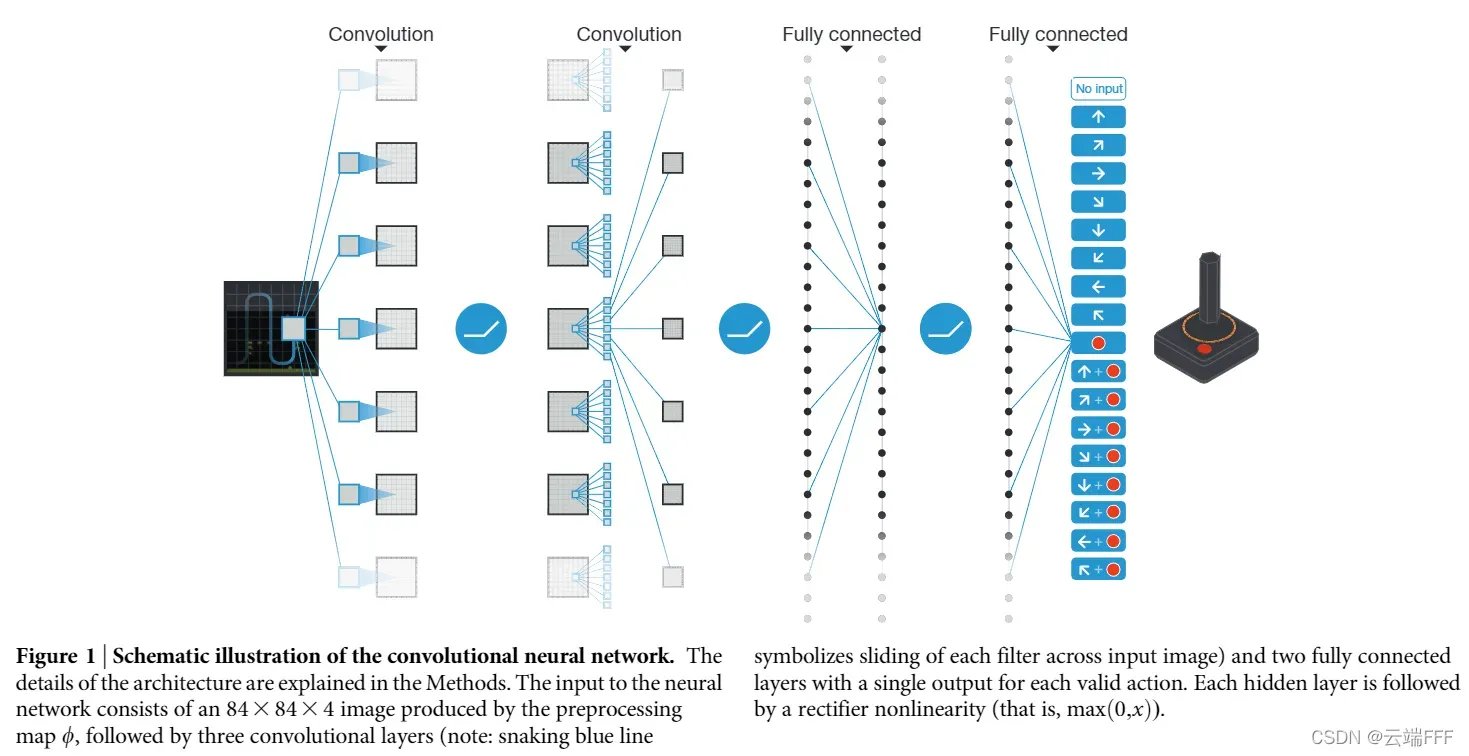
- 这个网络称为深度Q网络 Deep Q Network (DQN),是本文的核心,本文算法也由此得名
1.3 经验重放
- 如果 online 地使当前交互得到的 transition 样本去更新网络参数,即使用 on-policy 框架,这会导致以下问题
- 训练不稳定:要良好地估计价值函数,需要无限次地访问所有
-greedy 策略,这不但增加了不稳定性,且无法直接得到最优策略。更重要的是,on-policy 算法的探索是直接建立在其价值估计上的,而价值估计又来自探索经验,二者循环依赖,这会导致更强的风险寻求行为(比如某状态位置价值估计高了,就会进一步倾向于试探这附近的位置,有点正反馈的意味),使得训练不稳定
- 数据相关性强:由于我们使用轨迹中连续的 transition 作为训练样本,短期数据相关性是很强的(比如玩电子游戏,连续两帧画面之间非常相似),这违反了机器学习常见的 i.i.d 原则,在做梯度下降时,最近一段时间内的梯度方向总是相似,会导致更多震荡
- 数据利用率低:on-policy 要求必须使用当下行为策略采集的 transition 更新策略,因此过去的经验 transition 无法重用,所有数据用一次就扔掉了,有些当前不重要但后期重要的 transition 无法发挥最大作用,数据浪费严重
- 一个自然的想法是使用 off-policy 框架,并把过去的经验 transition 保存下来重用,这样就能一举缓解上述三个问题,这个 trick 称为 experience replay,其中保存过去 transition 的经验池称为 replay buffer。agent 与环境交互的过程中不断将最新的 transition 加入经验池,并在其中均匀采样历史 transition 样本来更新网络,交互流程图示如下
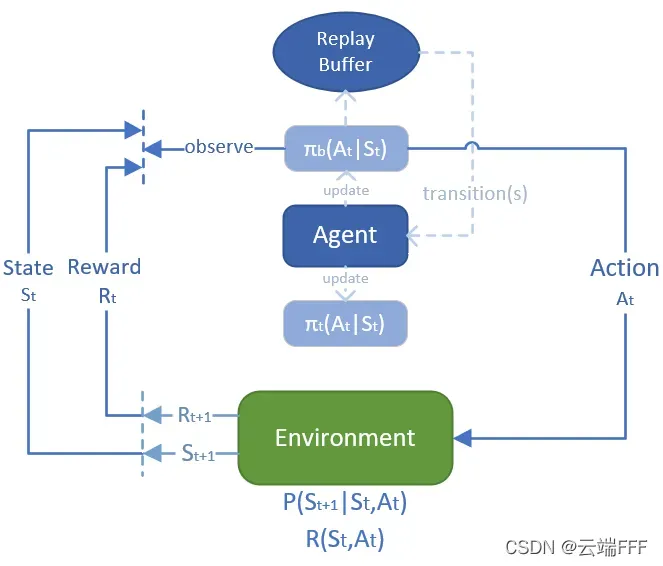
1.4 Target Q-network
- 在表格型 Q-learning 中,我们根据 Bellman Optimal Equation,通过 bootstrap 方式更新网络参数,即
引入
参数化的神经网络作为价值函数逼近器,自然的想法是如下基于 TD error 设计 L2 损失
其中
后一项
是
的方差的期望,与参数
注:这里的推导可以先从原来的展开式推导出来,再根据期望-方差关系公式,有。在原文中,这里的第二项是加号。我感觉我写错了。欢迎与我讨论这个问题。
- 但这引入了两个问题
- 我们依据基于
的优化目标来优化
- Bellman Optimal Equation 中有最大化
操作,这会导致价值函数的高估,而且高估会被 bootstrap 机制不断加剧
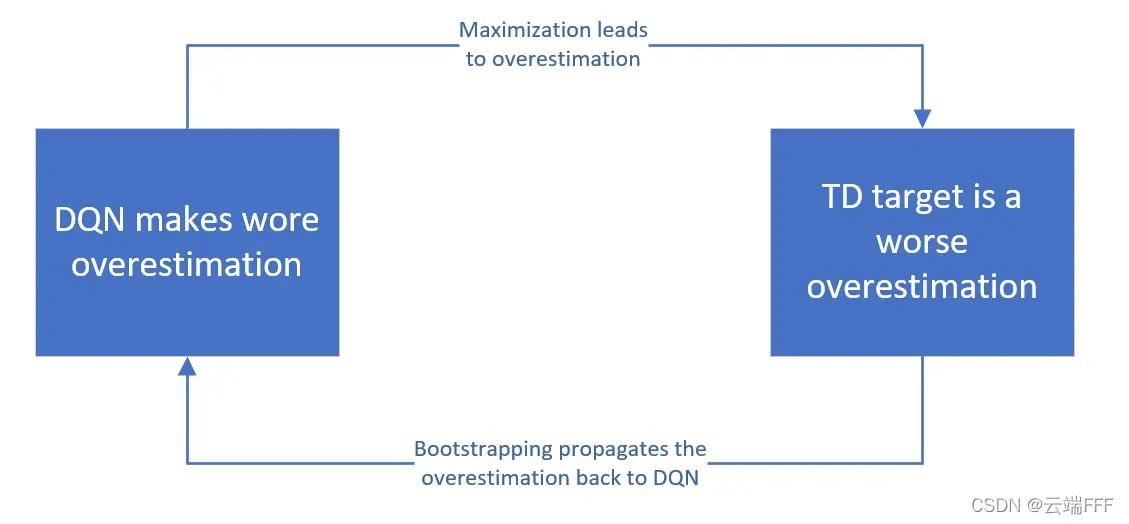
最终我们得到的是真实的有偏估计。其实高估本身没什么,但关键是高估是不均匀的,如果某个
- 在本文中,作者通过引入一个由
参数化的独立的目标网络 target network来解决上述问题,该网络的结构、输入输出等和 DQN 完全一致,每隔一段时间,就把其网络参数
梯度是
工程中,使用随机梯度下降 SGD 来完成优化,另外当令
时,退化为原始的 Q-Learning 更新形式
- 引入目标网络带来两个好处
- 每一段更新间隔内得到稳定的优化目标 TD target,使得训练更稳定
- 目标网络打断了 DQN 自身的 Bootstrapping 操作,一定程度上缓解了 Q 价值高估问题

- 不过事实上,作者这里并没有完全解决高估问题,因为选择动作时的最大化操作仍然会导致高估,另外目标网络的参数依然是来自 DQN 的,无法完全避免 Bootstrapping。本文发表一年后,即 2016 年在 AAAI 发表的 Deep Reinforcement Learning with Double Q-Learning 提出了 DDQN 方法,模仿 Double Q-learning 的思路进一步处理了高估问题,它做的改动其实非常小,观察 TD target 公式
它可以看作选择最优动作
和计算 TD target
- 原始方法中,两步都用 DQN 完成,即
- 本文方法 DQN 中,两步都用目标网络完成,即
- DDQN 中,第一步用 DQN 完成,第二步用目标网络完成,即
由于目标网络中的最大化操作,显然我们有(左边来自 DDQN,右边来自 DQN)
因此 DDQN 得到的估计值比 DQN 更小一些。总的来看,DDQN 不但缓解了最大化导致的偏差,还和 DQN 一样部分缓解了 Bootstrapping 导致的偏差,因此其价值估计最准确
- 这有点跑题了。其实这篇文章的作者根本没有分析高估的相关问题,只是说引入目标网络可以让训练更稳定
1.5 Clip the error
- 看前面计算的梯度
裁剪到 (-1,1) 之间,从而消除极端的梯度值
- 这里其实有点歧义,原文是这样写的

看前面是说裁剪了 TD error,但是后面又说相当于使用绝对值损失(相当于把整个梯度值裁剪到 (-1,1),即使用 Huber 损失),所以这里导致了不同的看法,在 stackoverflow 上也有人在讨论Loss clipping in tensor flow (on DeepMind’s DQN)
- 好像有人看过开源代码应该是前者,但是两种方法的效果应该差不多
1.6 伪代码

2. 实验
2.1 实现细节
- 网络输入:原始游戏画面为 210×160 像素 128 色,首先对邻近帧对应位置像素取最大值以去除闪烁,其次提取 RGB 帧的亮度通道,缩放到 84×84 像素尺寸,最后取最近的
帧画面,组成 84x84x4 的输入张量。其他输入还有游戏分数、可选动作数量、生命计数
- 网络结构:第一个隐藏层使用 32 个 8×8 卷积进行步长为 4 的卷积操作,接 Relu 激活函数;第二个隐藏层使用 64 个 4×4 卷积核进行步长为 2 的卷积操作,接 Relu 激活函数;第三个卷积层使用 64 个 3×3 卷积核进行步长为 1 的卷积操作,接 Relu 激活函数;最后一个隐藏层是 512 个 Relu 单元组成的全连接层;输出层是一个线性全连接层,每个有效动作都对应一个输出
- 训练细节:作者在 49 款 Atria 游戏上进行训练,全部使用相同的网络架构、算法和超参数设置,考虑到不同游戏的奖励数量级相差很大,作者将所有游戏的正/负面奖励裁剪为 +1/-1,这使得训练更容易,但是丢失了相对奖励大小这一信息
- 优化方法:使用 RMSProp 优化方法进行优化,可参考深度学习优化算法解析(Momentum, RMSProp, Adam)
- 行为策略:使用
-greedy 作为行为策略,
- 跳帧技术:为了提升训练效率,作者使用了 frame-skipping 技术,agent 每 k 个帧选择一次动作,并且在两次选择之间重复执行上次选择的动作。由于模拟器运行一步的时间消耗远远小于选择动作的时间消耗,这种技术允许 agent 多玩大约 k 倍的游戏,而不会显著增加运行时间。作者在这里设定
- 超参数选择:作者在 Pong, Breakout, Seaquest, Space Invaders, Beam Rider 等几款游戏上进行了非正式的超参数搜索,并且在所有游戏中使用选出的超参数
2.2 效果
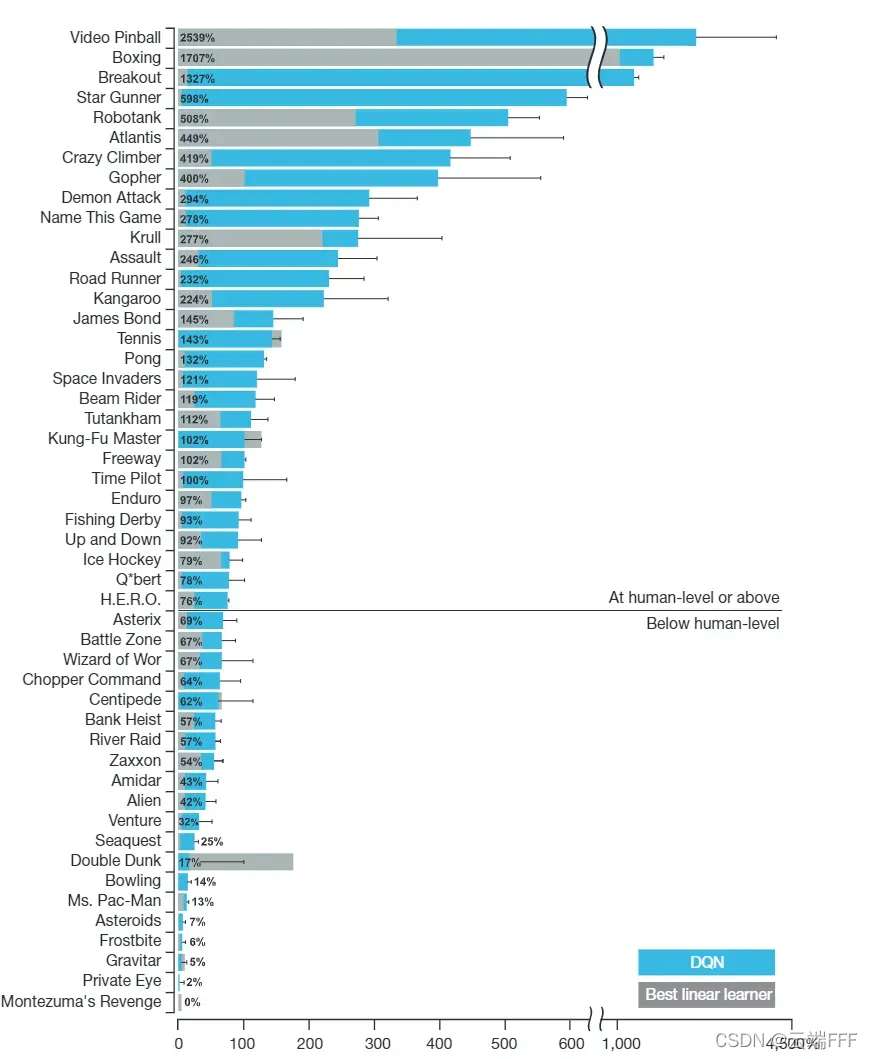
- 作者在 49 款 Atria 游戏上进行测试,大多数达到了人类水平,并且有 43 款达到了 SOTA 。下图中 100% 和 0% 分别代表人类水平和随机策略水平
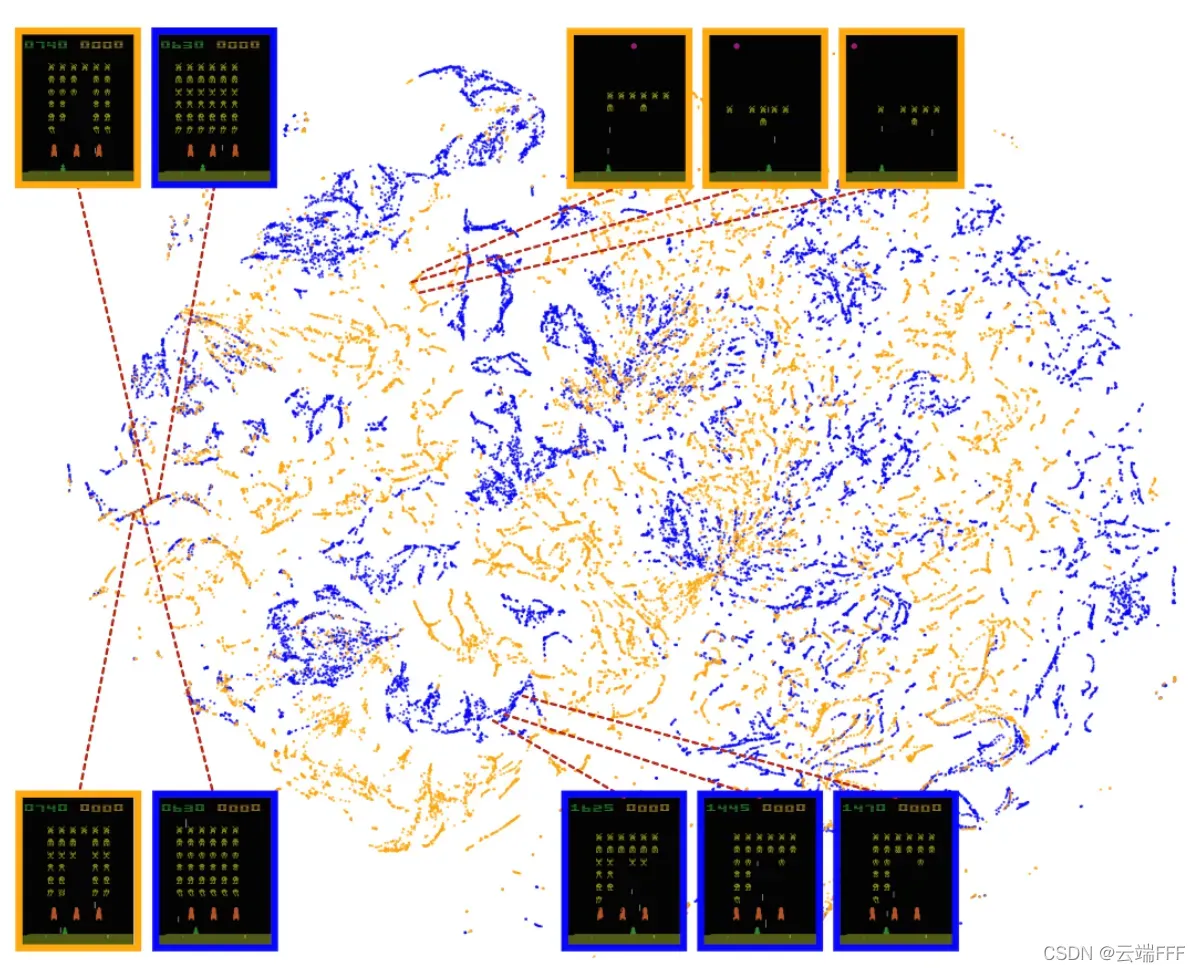
- 作者还使用 t-SNE 嵌入方法可视化了 CNN 对于状态(游戏画面)的抽象表示,并将其与人类玩家游戏时的画面分布相比较,发现有类似的二维嵌入结构,说明了用 CNN 提取特征的有效性(橘黄色是人类的,蓝色是DQN agent 的)
3 总结
- DQN 这篇文章拉开了深度强化学习的序幕,深度神经网络的强大性能也给 RL 领域带来了像当年 CV 领域一样巨大的性能提升。除了本文提到的 DDQN 外,后续围绕着 DQN 还有非常多的优化工作,占据 DRL 领域的半壁江山,所以我把 DQN 作为 “RL经典” 系列的第一篇文章,以后的再慢慢写吧
文章出处登录后可见!
已经登录?立即刷新