将强化学习应用于实践中的量化投资(神经网络模块开发)
1.前言
在本节内容中,将详细介绍神经网络模块中包含的几个神经网络类的属性和功能,并详细讲解基于 Python和Pytorch 实现的源码。本节内容的神经网络模块包括基本的深度神经网络 DNN、LSTM和卷积神经网络 CNN。
主要特性和功能
属性
- shared_network:一个神经网络的顶部,可以被多个神经网络共享(例如在A2C中,价值和策略神经网络共享一个神经网络的顶部,对于价值预测和概率只有底部不同预言)
- activation:神经网络输出层激活函数的名称(“linear”、“sigmoid”等)
- loss:神经网络的损失函数 lr:神经网络的学习率
- model:使用 pytorch 库构建的最终神经网络模型
功能
- predict():通过神经网络计算每个投资行为的价值或概率
- train_on_batch():为批量训练生成数据
- save_model():将训练好的神经网络保存到文件中
- load_model():加载保存为文件的神经网络
- get_shared_network():创建神经网络共享类函数
2 父类Network类
源代码
import threading
import abc
import numpy as np
import torch
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
class Network:
lock = threading.Lock()
def __init__(self, input_dim=0, output_dim=0, lr=0.001,
shared_network=None, activation='sigmoid', loss='mse'):
self.input_dim = input_dim
self.output_dim = output_dim
self.lr = lr
self.shared_network = shared_network
self.activation = activation
self.loss = loss
inp = None
if hasattr(self, 'num_steps'):
inp = (self.num_steps, input_dim)
else:
inp = (self.input_dim,)
# 共享神经网络
self.head = None
if self.shared_network is None:
self.head = self.get_network_head(inp, self.output_dim)
else:
self.head = self.shared_network
# 未使用共享神经网络
# self.head = self.get_network_head(inp, self.output_dim)
self.model = torch.nn.Sequential(self.head)
if self.activation == 'linear':
pass
elif self.activation == 'relu':
self.model.add_module('activation', torch.nn.ReLU())
elif self.activation == 'leaky_relu':
self.model.add_module('activation', torch.nn.LeakyReLU())
elif self.activation == 'sigmoid':
self.model.add_module('activation', torch.nn.Sigmoid())
elif self.activation == 'tanh':
self.model.add_module('activation', torch.nn.Tanh())
elif self.activation == 'softmax':
self.model.add_module('activation', torch.nn.Softmax(dim=1))
self.model.apply(Network.init_weights)
self.model.to(device)
self.optimizer = torch.optim.RMSprop(self.model.parameters(), lr=self.lr)
# self.optimizer = torch.optim.NAdam(self.model.parameters(), lr=self.lr)
self.criterion = None
if loss == 'mse':
self.criterion = torch.nn.MSELoss()
elif loss == 'binary_crossentropy':
self.criterion = torch.nn.BCELoss()
def predict(self, sample):
with self.lock:
self.model.eval()
with torch.no_grad():
x = torch.from_numpy(sample).float().to(device)
pred = self.model(x).detach().cpu().numpy()
pred = pred.flatten()
return pred
def train_on_batch(self, x, y):
loss = 0.
with self.lock:
self.model.train()
x = torch.from_numpy(x).float().to(device)
y = torch.from_numpy(y).float().to(device)
y_pred = self.model(x)
_loss = self.criterion(y_pred, y)
self.optimizer.zero_grad()
_loss.backward()
self.optimizer.step()
loss += _loss.item()
return loss
@classmethod
def get_shared_network(cls, net='dnn', num_steps=1, input_dim=0, output_dim=0):
if net == 'dnn':
return DNN.get_network_head((input_dim,), output_dim)
elif net == 'lstm':
return LSTMNetwork.get_network_head((num_steps, input_dim), output_dim)
elif net == 'cnn':
return CNN.get_network_head((num_steps, input_dim), output_dim)
@abc.abstractmethod
def get_network_head(inp, output_dim):
pass
@staticmethod
def init_weights(m):
if isinstance(m, torch.nn.Linear) or isinstance(m, torch.nn.Conv1d):
torch.nn.init.normal_(m.weight, std=0.01)
elif isinstance(m, torch.nn.LSTM):
for weights in m.all_weights:
for weight in weights:
torch.nn.init.normal_(weight, std=0.01)
def save_model(self, model_path):
if model_path is not None and self.model is not None:
torch.save(self.model, model_path)
def load_model(self, model_path):
if model_path is not None:
self.model = torch.load(model_path)
网络类是定义神经网络在 RLTrader 中共有的属性和函数的父类。本文中没有单独使用它,而是 DNN、LSTM 和 CNN 从 Network 类继承公共属性类和函数。
predict()函数预测样本上某个动作的值或概率
train_on_batch()函数通过将训练数据和标签 x 和 y 作为输入来训练模型。在 A3C 中,由于多个线程可以并行使用神经网络,防止线程同时使用,防止冲突。
此外,Network 类具有将模型保存到文件的save_model()功能和从文件中读取模型的功能load_model()。学习一个神经网络会消耗大量的时间和计算资源,因此将学习到的神经网络保存起来并在需要时使用是非常必要的。
您可以使用当前数据训练神经网络,将其保存到文件中,然后加载并使用保存的神经网络模型进行未来投资。您还可以通过对加载的神经网络执行额外的训练来创建改进的神经网络。
get_shared_network()函数是创建 DNN、LSTM 和 CNN 神经网络的共享神经网络的类函数。Network 类的每个子类都有一个get_network_head()类函数。根据神经网络的类型,您可以通过调用DNN、LSTMNetwork 或 CNN 类的类函数来get_network_head()获得共享的神经网络模型。
3. DNN
神经网络是基于感知机的扩展,而DNN可以理解为有很多隐藏层的神经网络。多层神经网络和深度神经网络DNN其实也是指的一个东西,DNN有时也叫做多层感知机(Multi-Layer perceptron,MLP)。
从DNN按不同层的位置划分,DNN内部的神经网络层可以分为三类,输入层,隐藏层和输出层,如下图示例,一般来说第一层是输入层,最后一层是输出层,而中间的层数都是隐藏层。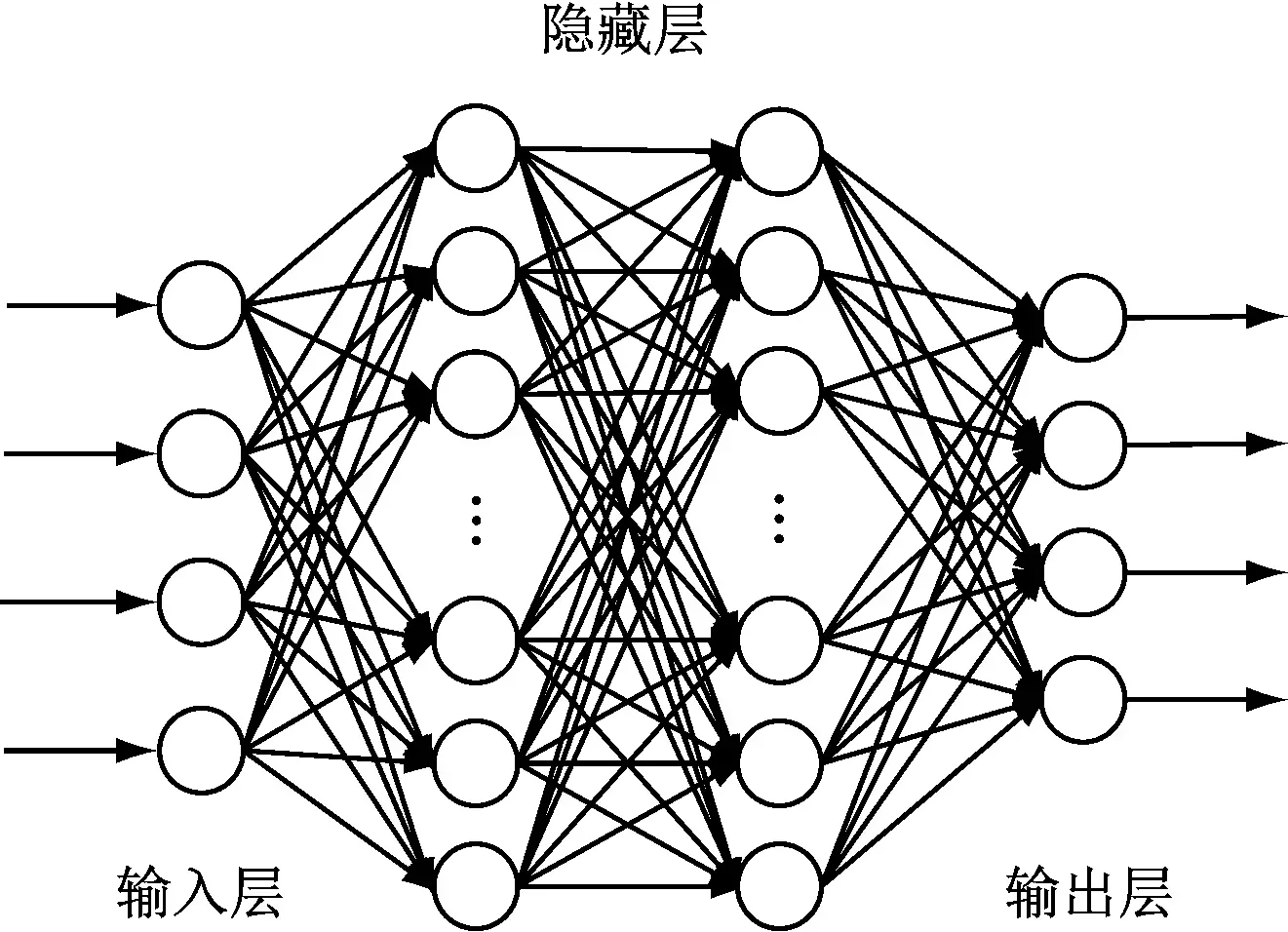
基于Network父类实现DNN类源代码
class DNN(Network):
@staticmethod
def get_network_head(inp, output_dim):
return torch.nn.Sequential(
torch.nn.BatchNorm1d(inp[0]),
torch.nn.Linear(inp[0], 256),
torch.nn.BatchNorm1d(256),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(256, 128),
torch.nn.BatchNorm1d(128),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(128, 64),
torch.nn.BatchNorm1d(64),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(64, 32),
torch.nn.BatchNorm1d(32),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(32, output_dim),
)
def train_on_batch(self, x, y):
x = np.array(x).reshape((-1, self.input_dim))
return super().train_on_batch(x, y)
def predict(self, sample):
sample = np.array(sample).reshape((1, self.input_dim))
return super().predict(sample)
在这里,通过 dropout 部分避免了过度拟合,并通过批量归一化来稳定训练。批量正则化是一种通过对隐藏层的输入进行归一化来加速学习的方法。
隐藏层的激活函数设置为 Sigmoid。在这里你可以自由修改层数、每层的维度、激活函数、dropout 比等等。get_network_head() 类函数包含我们稍后将介绍的所有其他神经网络类。
train_on_batch()函数和predict()函数适当地改变训练数据或样本的形状,并按原样调用上层类的函数。DNN 具有形状(批量大小、特征向量维度)。Model 类中的函数predict()一次获取多个样本并返回神经网络的输出。即使我们只想获得一个样本的结果,我们也必须将输入构造为一个样本数组,因此我们将其重新组织为一个二维数组。
4.LSTM
长短期记忆网络(LSTM,Long Short-Term Memory)是一种时间循环神经网络,是为了解决一般的RNN(循环神经网络)存在的长期依赖问题而专门设计出来的,所有的RNN都具有一种重复神经网络模块的链式形式。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个tanh层。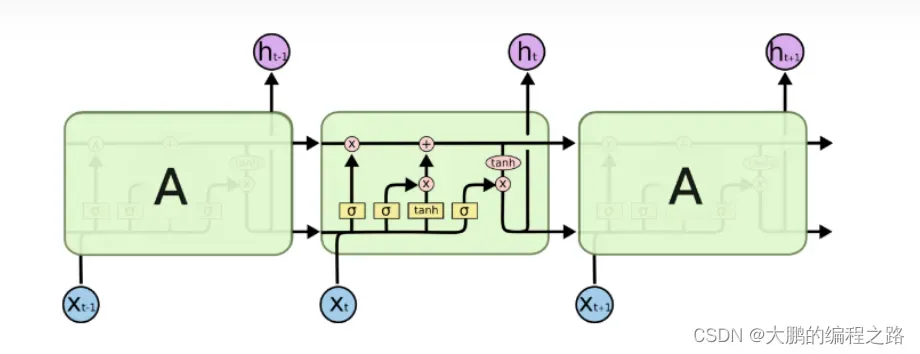
基于Network父类实现LSTM类源代码
class LSTMNetwork(Network):
def __init__(self, *args, num_steps=1, **kwargs):
self.num_steps = num_steps
super().__init__(*args, **kwargs)
@staticmethod
def get_network_head(inp, output_dim):
return torch.nn.Sequential(
torch.nn.BatchNorm1d(inp[0]),
LSTMModule(inp[1], 128, batch_first=True, use_last_only=True),
torch.nn.BatchNorm1d(128),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(128, 64),
torch.nn.BatchNorm1d(64),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(64, 32),
torch.nn.BatchNorm1d(32),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(32, output_dim),
)
def train_on_batch(self, x, y):
x = np.array(x).reshape((-1, self.num_steps, self.input_dim))
return super().train_on_batch(x, y)
def predict(self, sample):
sample = np.array(sample).reshape((-1, self.num_steps, self.input_dim))
return super().predict(sample)
5.CNN
卷积神经网络(Convolutional Neural Networks, CNN)是一类包含卷积计算且具有深度结构的前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一。
卷积神经网络仿造生物的视知觉(visual perception)机制构建,可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)。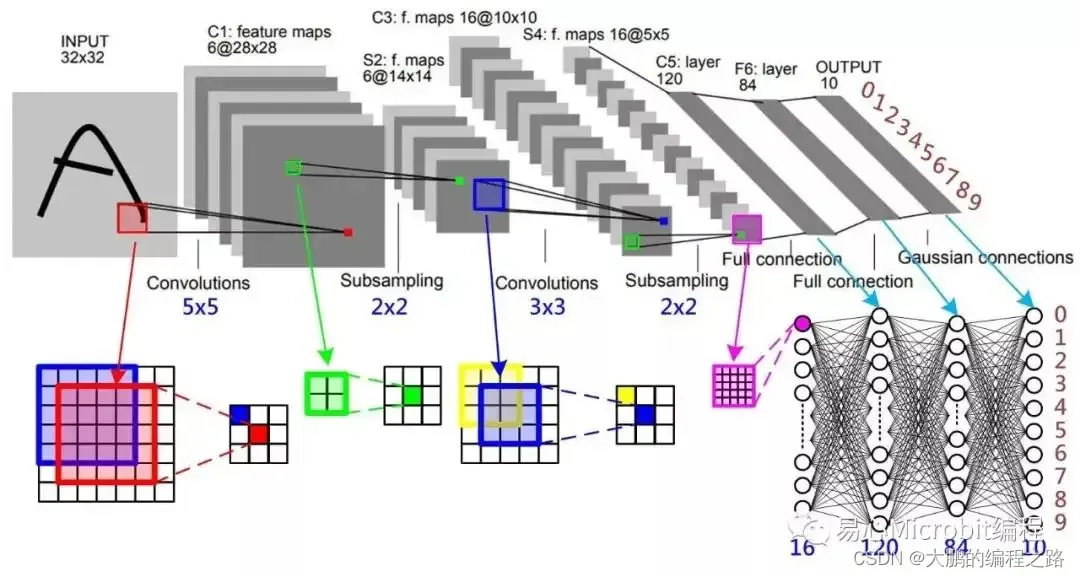
基于Network父类实现CNN源代码
class CNN(Network):
def __init__(self, *args, num_steps=1, **kwargs):
self.num_steps = num_steps
super().__init__(*args, **kwargs)
@staticmethod
def get_network_head(inp, output_dim):
kernel_size = 2
return torch.nn.Sequential(
torch.nn.BatchNorm1d(inp[0]),
torch.nn.Conv1d(inp[0], 1, kernel_size),
torch.nn.BatchNorm1d(1),
torch.nn.Flatten(),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(inp[1] - (kernel_size - 1), 128),
torch.nn.BatchNorm1d(128),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(128, 64),
torch.nn.BatchNorm1d(64),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(64, 32),
torch.nn.BatchNorm1d(32),
torch.nn.Dropout(p=0.1),
torch.nn.Linear(32, output_dim),
)
def train_on_batch(self, x, y):
x = np.array(x).reshape((-1, self.num_steps, self.input_dim))
return super().train_on_batch(x, y)
def predict(self, sample):
sample = np.array(sample).reshape((1, self.num_steps, self.input_dim))
return super().predict(sample)
文章出处登录后可见!