1.计算机视觉的应用算法
计算机视觉有许多算法任务:图像分类,图片相似搜索。图像分割,关键点检测,目标检测,目标跟踪,视频分类,深度估计,人脸检测等。
这些算法,又有很多各种各样的网络结构,复杂又抽象,我们只知道把数据输入到模型,得到结果,这网络里面怎么处理的数据,处理的过程又是怎么样的,太抽象了。
因此我写这篇文章,是想尽可能把这样抽象过程,描述成小白都能理解的形式。
2.图像的特征与视频特征
再说算法,我们先谈一下,图像的特征和视频的特征,从这些算法任务中,不难看出,算法模型用到的数据,不外乎图片和视频。
所以首先我们要知道图像和视频在机器代码角度下,有哪些有价值的特征。
2.1 图像特征

比如我们大幂幂,我们人的视角,看到的,是五官,衣服,头发这类(宏观一点的),但在机器角度,看到的要更微观很多,微观到每一个像素点(学ps的就知道,做p图,其实是对每个像素块做处理,一张图片也又几千个不同颜色像素块组成)。算法处理图像的最小单位也就是像素块。
基于这样的像素块,机器看到是什么呢:
- 颜色:每个像素块都有自己的颜色
- 形状:基于相似颜色的像素块,可以区分不同的形状
- 纹理:有些像素块上还有条纹,类似于一块木地板
- 序列:有些像素块之间是有关联的,比如文本,下一章会详细说明
前三者,融合起来就是我们人视角看到的特征:
比如:皮肤的纹理,皮肤的颜色,皮肤形状(就是我们看到的杨幂的脸)
了解“风格迁移”算法的或许更能明白,这些特征的使用。
2.2 视频特征
视频特征,视频其实就是由连续帧的图片,按照时间顺序,组合成的。因此,视频特征里有图像的特征,
除此之外,视频特征由于有连续几张图片的特征,因此会有二张图片或者多张图片对比下的一些特定的特征,比如位置和速度二个特征,这二者其实也就是序列特征
3.算法通俗理解
接下来,我将用图像的特征和视频的特征来介绍,这些不同算法,在训练和预测过程,算法的网络是怎么处理的。
先介绍图像分类,图像分类是其他算法开发基础,理解了图像分类,就明白后续的计算机视觉算法如何处理的
3.1 图像分类
训练
图像分类,我们数据有图像和图像的label,我们将图像加入到模型,模型根据图像的特征(纹理、颜色、形状),这些特征通过模型组合形成更抽象的五官,模型记住了这个label类别下人的五官,知道了他长什么样了。
婴儿:父母告诉婴儿这个是爸爸,那个是妈妈,婴儿也是根据脸部的特征,五官记住了,这个人是爸爸。
预测
同样预测,我们向模型加入预测的图像,模型同理分解除图像的特征,再组合成更抽象的特征(五官),再与模型之前训练后记住的特征(五官)进行对比,判断。
3.2 目标检测

目标检测有点像图像分类
训练
我们数据,是经过标注后的数据,类似于上图这张,我们通过边框和label标注,让模型,只针对边框内的图像,做处理(这里就跟图像分类训练很像了),相当于做抠图,抠下来做图像分类训练。
预测
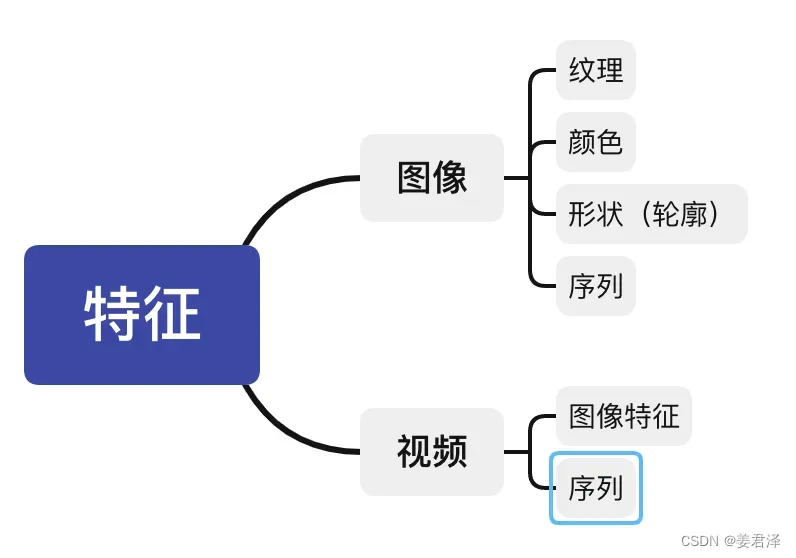
模型预测的时候,模型先对预测的图片按一定规则在图片上产生一系列的候选区域,如下图所示:
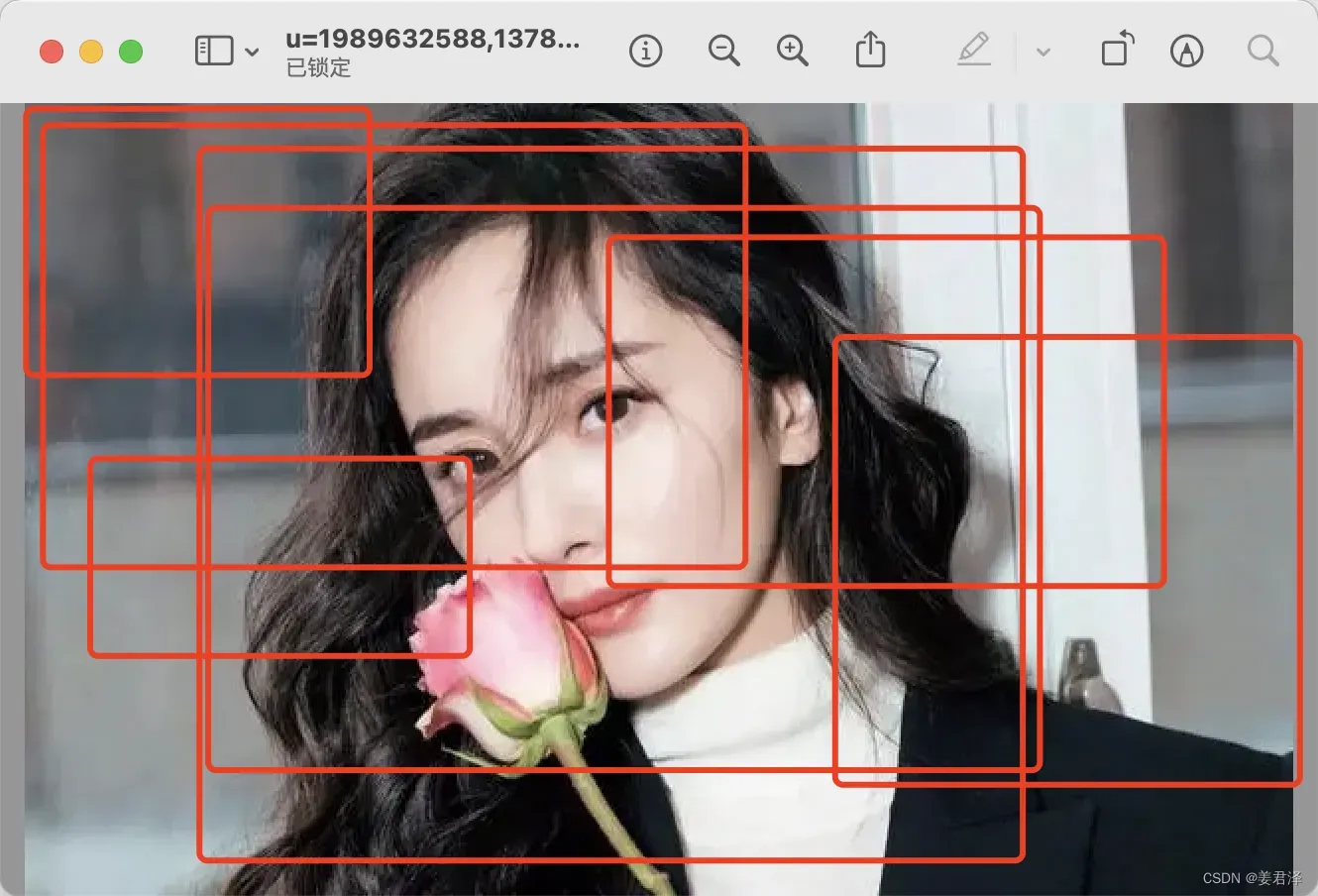
然后模型对每个框做,一个图像分类预测处理,来判断属于的类别,并给出一个类别阈值,找出类别为杨幂的阈值也高的图片,这里可能会出现多个框有重合,如下图所示:
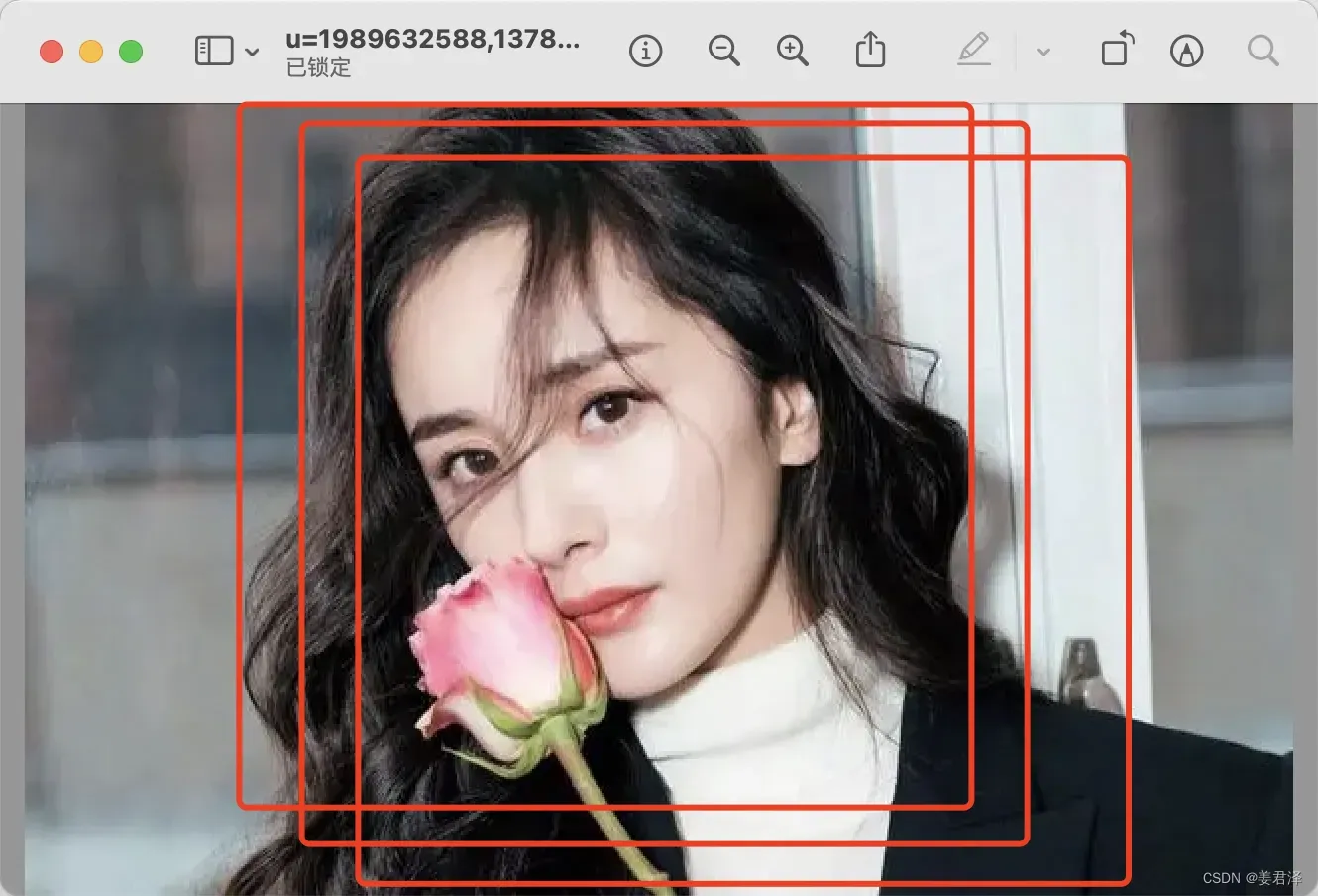
这里就需要对这几个框做一个去重处理,就OK了。
3.3 语义分割
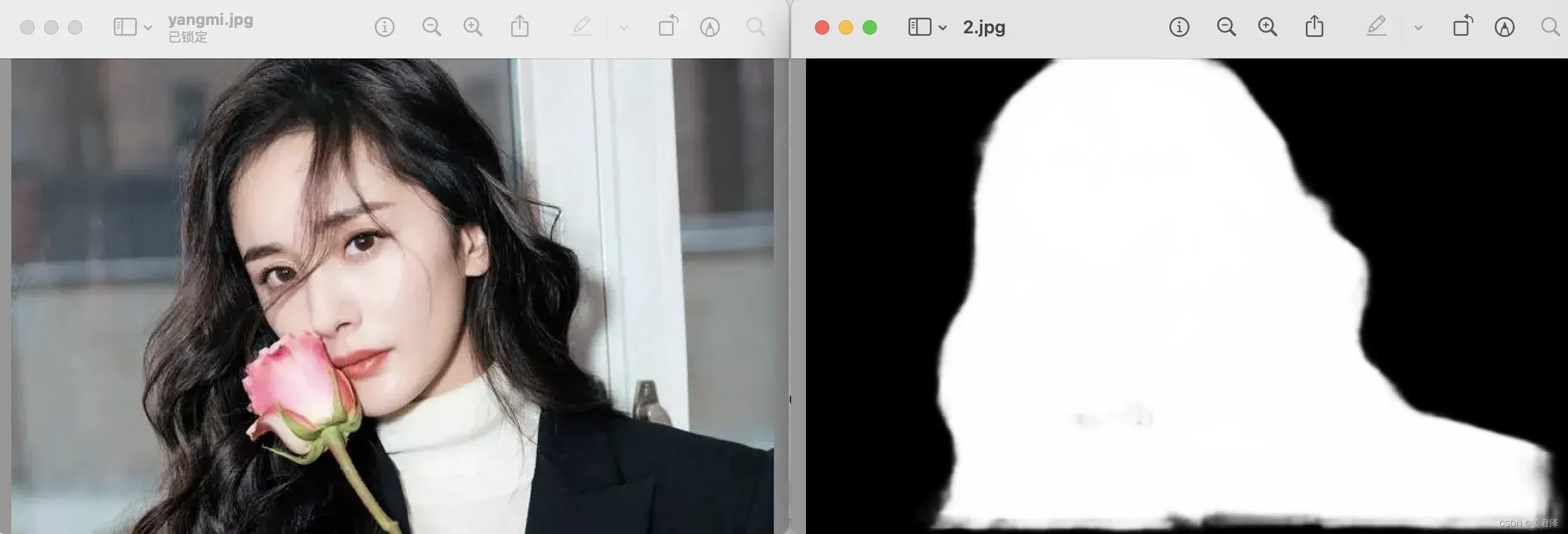
语义分割通俗来说就是有label标签的分割,对每个分割出的区域,都会告诉这个区域是什么类别。
计算机视觉领域还有2个与语义分割相似的重要问题,即图像分割(image segmentation)和实例分割(instance segmentation)。 我们在这里将它们同语义分割简单区分一下。
- 图像分割:图像分割将图像划分为若干组成区域,这类问题的方法通常利用图像中像素之间的相关性,也就是图像的颜色,形状,纹理之间的相关性,将同一类的事物。划分成一个区域。但这种预测不需要有关图像像素的标签信息,在预测时也无法保证分割出的区域具有我们希望得到的语义。
- 实例分割:也叫同时检测并分割(simultaneous detection and segmentation),它研究如何识别图像中各个目标实例的像素级区域。与语义分割不同,实例分割不仅需要区分语义,还要区分不同的目标实例。例如,如果图像中有两条狗,则实例分割需要区分像素属于的两条狗中的哪一条。是不是就是目标检测+图像分割,再分下来就是:画框+图像分类+图像分割
至于分割出来不同区域的颜色,其实是指定的
到这里从图像分类,目标检测,图像分割是不是看起来像是一层一层算法叠加的。
3.4 关键点检测
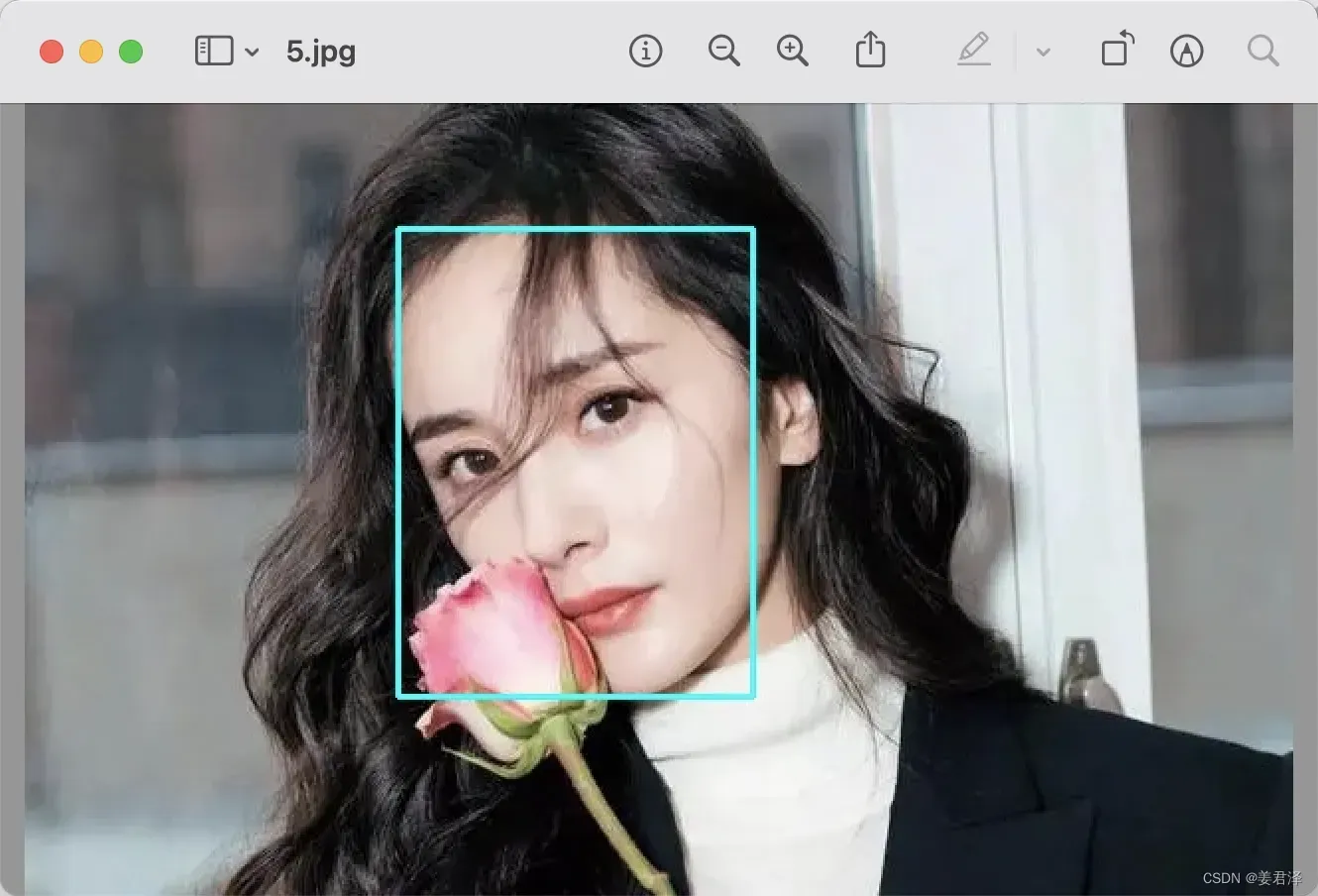
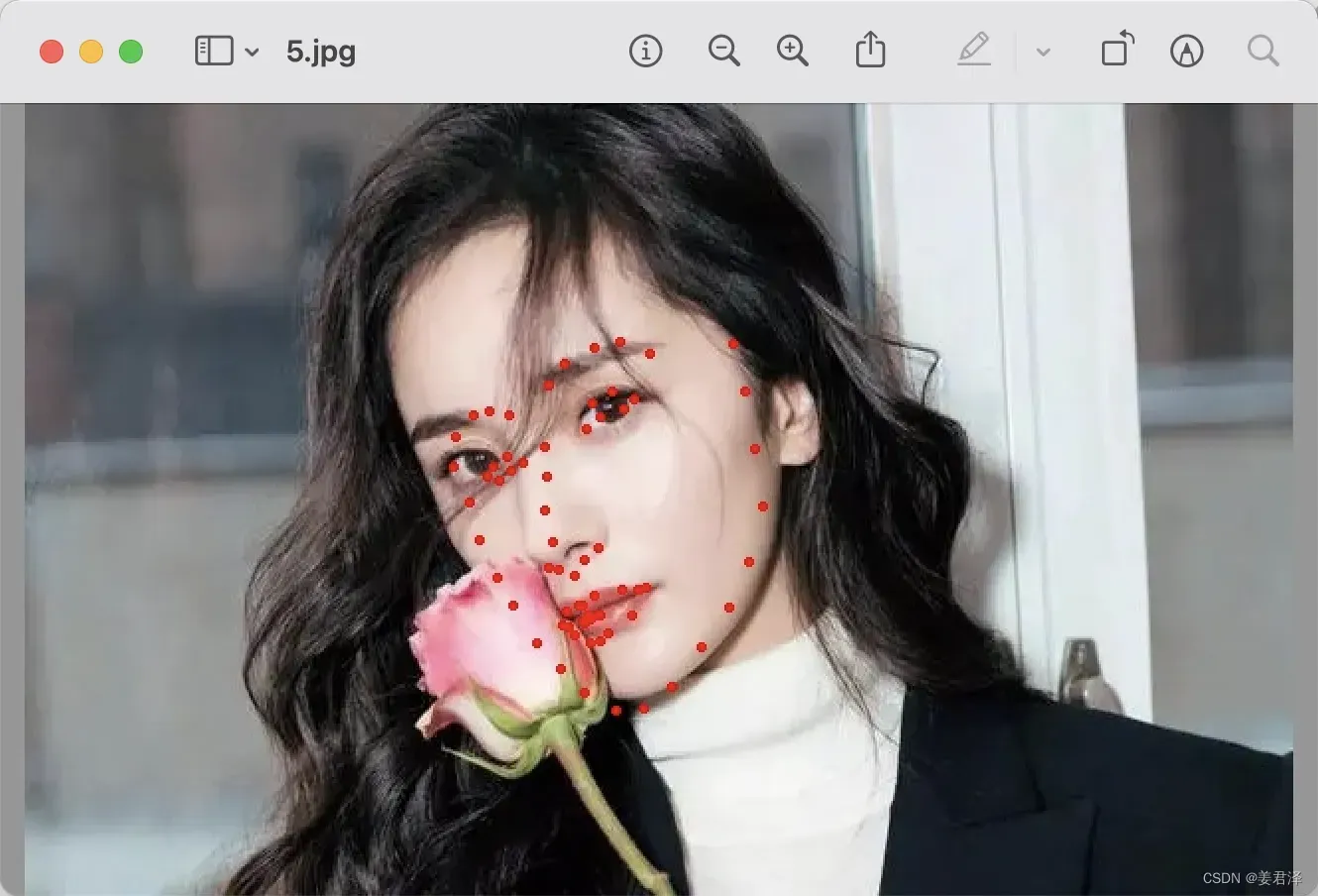
哎呀这精致的脸庞。
关键点本质上是一种特征。它是对一个固定区域或者空间物理关系的抽象描述,描述的是一定邻域范围内的组合或上下文关系,可以说是图像中纹理、颜色、形状的高维聚合。
前面说图像分类的时候,杨幂的五官通过纹理、颜色、形状可以找出来,那人体的形状也同样可以找出来。
关键点检测方法总体上可以分成两个类型,一个种是用坐标回归的方式来解决,另一种是将关键点建模成热力图,通过像素分类任务,回归热力图分布得到关键点位置
文章出处登录后可见!